Då och då kanske du märker att en eller flera anslutningar i en exekveringsplan är kommenterade med en StarJoinInfo strukturera. Det officiella showplan-schemat har följande att säga om detta planelement (klicka för att förstora):
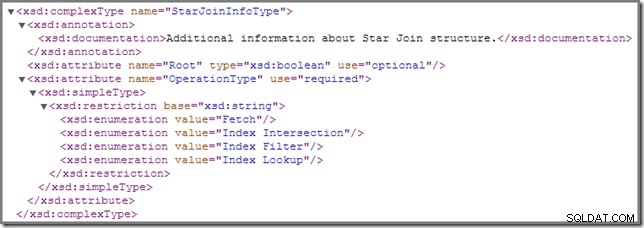
Den direktanslutna dokumentationen som visas där ("ytterligare information om Star Join-strukturen ") är inte så upplysande, även om de andra detaljerna är ganska spännande – vi kommer att titta på dessa i detalj.
Om du konsulterar din favoritsökmotor för mer information med hjälp av termer som "SQL Server star join optimization", kommer du sannolikt att se resultat som beskriver optimerade bitmappsfilter. Detta är en separat Enterprise-only-funktion som introduceras i SQL Server 2008 och inte relaterad till StarJoinInfo struktur överhuvudtaget.
Optimeringar för selektiva stjärnfrågor
Förekomsten av StarJoinInfo indikerar att SQL Server tillämpade en av en uppsättning optimeringar som är inriktade på selektiva stjärnschema-frågor. Dessa optimeringar är tillgängliga från SQL Server 2005, i alla utgåvor (inte bara Enterprise). Observera att selektiv här hänvisar till antalet rader som hämtas från faktatabellen. Kombinationen av dimensionella predikat i en fråga kan fortfarande vara selektiv även när dess individuella predikat kvalificerar ett stort antal rader.
Vanlig indexkorsning
Frågeoptimeraren kan överväga att kombinera flera icke-klustrade index där ett lämpligt enda index inte finns, vilket följande AdventureWorks-fråga visar:
SELECT COUNT_BIG(*) FROM Sales.SalesOrderHeader WHERE SalesPersonID = 276 AND CustomerID = 29522;
Optimeraren avgör att kombinera två icke-klustrade index (ett på SalesPersonID och den andra på CustomerID ) är det billigaste sättet att tillfredsställa denna fråga (det finns inget index på båda kolumnerna):
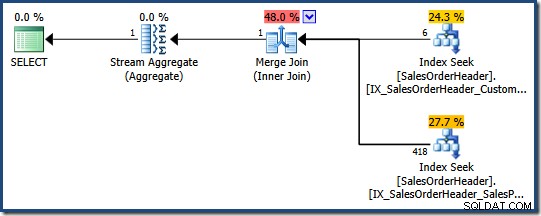
Varje indexsökning returnerar den klustrade indexnyckeln för rader som passerar predikatet. Sammanfogningen matchar de returnerade nycklarna för att säkerställa att endast rader som matchar båda predikat förs vidare.
Om tabellen var en hög skulle varje sökning returnera högradidentifierare (RID) istället för klustrade indexnycklar, men den övergripande strategin är densamma:hitta radidentifierare för varje predikat och matcha dem sedan.
Manuell Star Join Index Intersection
Samma idé kan utökas till frågor som väljer rader från en faktatabell med hjälp av predikat som tillämpas på dimensionstabeller. För att se hur detta fungerar, överväg följande fråga (med hjälp av Contoso BI-exempeldatabasen) för att hitta det totala försäljningsbeloppet för MP3-spelare som säljs i Contoso-butiker med exakt 50 anställda:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; För jämförelse med senare försök, producerar denna (mycket selektiva) fråga en frågeplan som följande (klicka för att expandera):
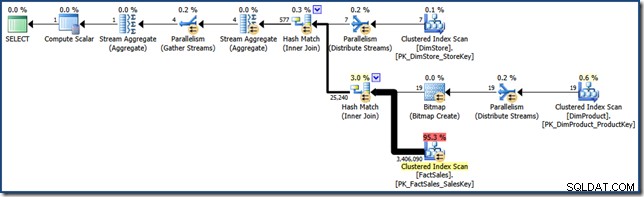
Den utförandeplanen har en beräknad kostnad på drygt 15,6 enheter . Den har parallell körning med en fullständig genomsökning av faktatabellen (om än med ett bitmappsfilter tillämpat).
Faktatabellerna i denna exempeldatabas inkluderar inte som standard icke-klustrade index på faktatabellens främmande nycklar, så vi måste lägga till ett par:
CREATE INDEX ix_ProductKey ON dbo.FactSales (ProductKey); CREATE INDEX ix_StoreKey ON dbo.FactSales (StoreKey);
Med dessa index på plats kan vi börja se hur indexskärning kan användas för att förbättra effektiviteten. Det första steget är att hitta identifierare för faktatabellrader för varje separat predikat. Följande frågor tillämpar ett enstaka dimensionspredikat och går sedan tillbaka till faktatabellen för att hitta radidentifierare (faktatabellklustrade indexnycklar):
-- Product dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%';
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50; Frågeplanerna visar en genomsökning av tabellen med små dimensioner, följt av uppslagningar med hjälp av faktatabellens icke-klustrade index för att hitta radidentifierare (kom ihåg att icke-klustrade index alltid inkluderar bastabellens klustringsnyckel eller heap RID):
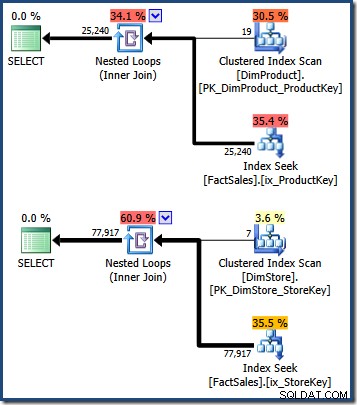
Skärningspunkten mellan dessa två uppsättningar av faktatabellklustrade indexnycklar identifierar raderna som ska returneras av den ursprungliga frågan. När vi har dessa radidentifierare behöver vi bara slå upp försäljningsbeloppet i varje faktatabellsrad och beräkna summan.
Manuell Index Intersection Query
Att sätta ihop allt detta i en fråga ger följande:
SELECT SUM(FS.SalesAmount)
FROM
(
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
WHERE DP.ProductName LIKE N'%MP3%'
INTERSECT
-- Store dimension predicate
SELECT FS.SalesKey
FROM dbo.FactSales AS FS
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount = 50
) AS Keys
JOIN dbo.FactSales AS FS WITH (FORCESEEK)
ON FS.SalesKey = Keys.SalesKey
OPTION (MAXDOP 1);
FORCESEEK ledtråd finns för att säkerställa att vi får punktuppslag till faktatabellen. Utan detta väljer optimeraren att skanna faktatabellen, vilket är precis vad vi är ute efter att undvika. MAXDOP 1 tips hjälper bara till att hålla den slutliga planen till en ganska rimlig storlek för visningsändamål (klicka för att se den i full storlek):
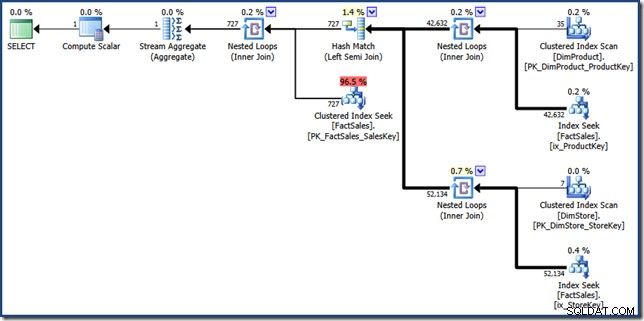
Komponenterna i den manuella indexkorsningsplanen är ganska lätta att identifiera. De två icke-klustrade faktatabellernas indexuppslagningar på höger sida producerar de två uppsättningarna av faktatabellradidentifierare. Hash-kopplingen hittar skärningspunkten mellan dessa två uppsättningar. Den klustrade indexsökningen i faktatabellen hittar försäljningsbeloppen för dessa radidentifierare. Slutligen beräknar Stream Aggregate det totala beloppet.
Den här frågeplanen gör relativt få sökningar i faktatabellen icke-klustrade och klustrade index. Om frågan är tillräckligt selektiv kan detta mycket väl vara en billigare exekveringsstrategi än att skanna faktatabellen helt. Contoso BI-exempeldatabasen är relativt liten, med endast 3,4 miljoner rader i försäljningsfaktatabellen. För större faktatabeller kan skillnaden mellan en fullständig genomsökning och några hundra uppslag vara mycket betydande. Tyvärr introducerar den manuella omskrivningen några allvarliga kardinalitetsfel, vilket resulterar i en plan med en uppskattad kostnad på 46,5 enheter .
Automatisk Star Join Index Intersection with Lookups
Lyckligtvis behöver vi inte bestämma om frågan vi skriver är tillräckligt selektiv för att motivera denna manuella omskrivning. Stjärnanslutningsoptimeringarna för selektiva frågor innebär att frågeoptimeraren kan utforska det här alternativet åt oss med hjälp av den mer användarvänliga ursprungliga frågesyntaxen:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Optimeraren producerar följande exekveringsplan med en uppskattad kostnad på 1,64 enheter (klicka för att förstora):
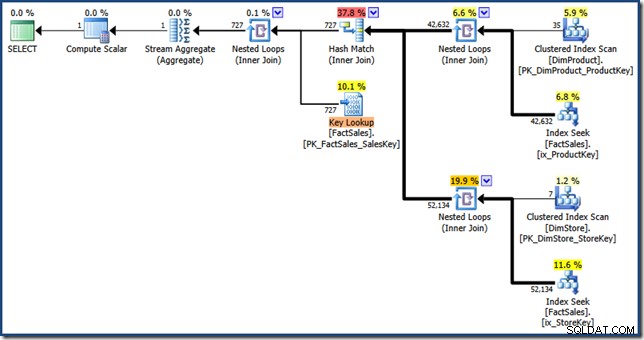
Skillnaderna mellan denna plan och den manuella versionen är:indexkorsningen är en inre sammanfogning istället för en semi-fog; och den klustrade indexsökningen visas som en nyckelsökning istället för en klustrad indexsökning. Om faktatabellen vore en hög, skulle nyckeluppslagningen vara en RID-uppslagning, med risk för att det skulle vara svårt.
StarJoinInfo-egenskaperna
Joinerna i denna plan har alla en StarJoinInfo strukturera. För att se det, klicka på en join-iterator och titta i fönstret SSMS-egenskaper. Klicka på pilen till vänster om StarJoinInfo element för att expandera noden.
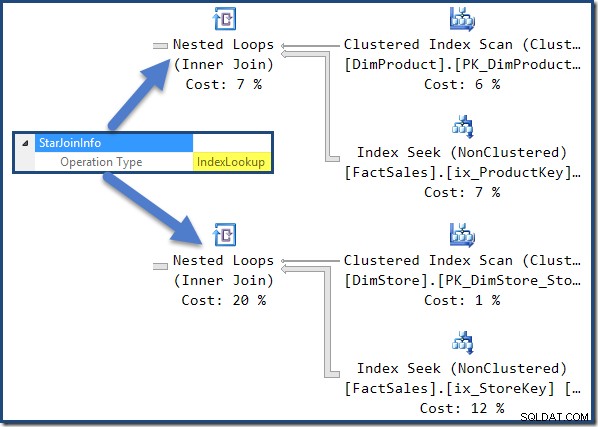
Den icke-klustrade faktatabellen ansluter till höger om planen är Index Lookups byggda av optimeraren:
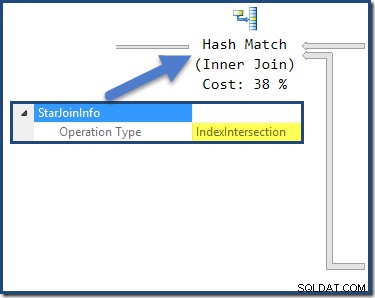
Hash-join har en StarJoinInfo struktur som visar att den utför en Index Intersection (återigen, tillverkad av optimeraren):
StarJoinInfo för kopplingen längst till vänster om Nested Loops visar att den genererades för att hämta faktatabellsrader efter radidentifierare. Det är i roten av det optimeringsgenererade stjärnanslutningsunderträdet:
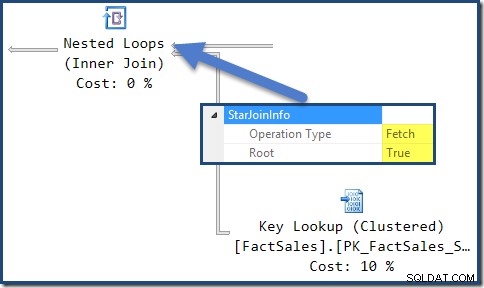
Kartesiska produkter och indexsökning med flera kolumner
Indexkorsningsplanerna som betraktas som en del av stjärnanslutningsoptimeringarna är användbara för selektiva faktatabellsfrågor där enkolumns icke-klustrade index finns på faktatabellens främmande nycklar (en vanlig designpraxis).
Ibland är det också meningsfullt att skapa index med flera kolumner på främmande nycklar för faktatabeller, för ofta frågade kombinationer. De inbyggda selektiva stjärnfrågeoptimeringarna innehåller också en omskrivning för detta scenario. För att se hur detta fungerar, lägg till följande flerkolumnindex i faktatabellen:
CREATE INDEX ix_ProductKey_StoreKey ON dbo.FactSales (ProductKey, StoreKey);
Kompilera testfrågan igen:
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'; Frågeplanen har inte längre indexkorsning (klicka för att förstora):
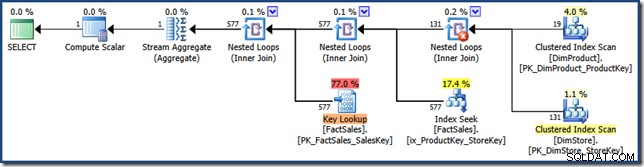
Strategin som väljs här är att tillämpa varje predikat på dimensionstabellerna, ta den kartesiska produkten av resultaten och använda den för att söka in i båda nycklarna i flerkolumnindexet. Frågeplanen utför sedan en nyckelsökning i faktatabellen med hjälp av radidentifierare exakt som tidigare.
Frågeplanen är särskilt intressant eftersom den kombinerar tre funktioner som ofta betraktas som dåliga saker (fullständiga skanningar, kartesiska produkter och nyckelsökningar) i en prestandaoptimering . Detta är en giltig strategi när produkten av de två dimensionerna förväntas vara mycket liten.
Det finns ingen StarJoinInfo för den kartesiska produkten, men de andra kopplingarna har information (klicka för att förstora):
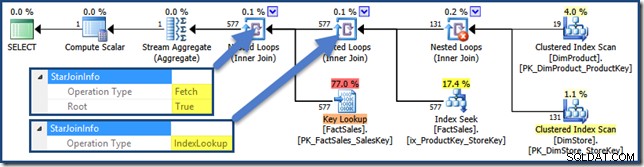
Indexfilter
Med hänvisning till showplan-schemat finns det en annan StarJoinInfo operation vi behöver täcka:
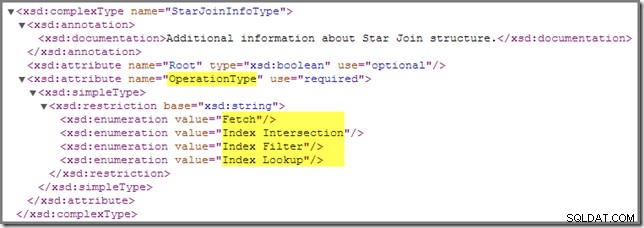
Index Filter värde ses med kopplingar som anses vara tillräckligt selektiva för att vara värda att utföra innan faktatabellens hämtning. Joins som inte är tillräckligt selektiva kommer att utföras efter hämtningen och kommer inte att ha en StarJoinInfo struktur.
För att se ett indexfilter med vår testfråga måste vi lägga till en tredje sammanfogningstabell till mixen, ta bort de icke-klustrade faktatabellindexen som skapats hittills och lägga till en ny:
CREATE INDEX ix_ProductKey_StoreKey_PromotionKey
ON dbo.FactSales (ProductKey, StoreKey, PromotionKey);
SELECT
SUM(FS.SalesAmount)
FROM dbo.FactSales AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
JOIN dbo.DimPromotion AS DPR
ON DPR.PromotionKey = FS.PromotionKey
WHERE
DS.EmployeeCount = 50
AND DP.ProductName LIKE N'%MP3%'
AND DPR.DiscountPercent <= 0.1; Frågeplanen är nu (klicka för att förstora):
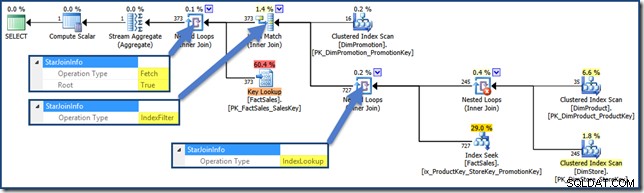
En Heap Index Intersection Query Plan
För fullständighetens skull är här ett skript för att skapa en högkopia av faktatabellen med de två icke-klustrade index som behövs för att möjliggöra omskrivning av indexkorsningsoptimeraren:
SELECT * INTO FS FROM dbo.FactSales;
CREATE INDEX i1 ON dbo.FS (ProductKey);
CREATE INDEX i2 ON dbo.FS (StoreKey);
SELECT SUM(FS.SalesAmount)
FROM FS AS FS
JOIN dbo.DimProduct AS DP
ON DP.ProductKey = FS.ProductKey
JOIN dbo.DimStore AS DS
ON DS.StoreKey = FS.StoreKey
WHERE DS.EmployeeCount <= 10
AND DP.ProductName LIKE N'%MP3%'; Exekveringsplanen för den här frågan har samma funktioner som tidigare, men indexskärningen utförs med RID istället för faktatabellsklustrade indexnycklar, och den sista hämtningen är en RID Lookup (klicka för att expandera):
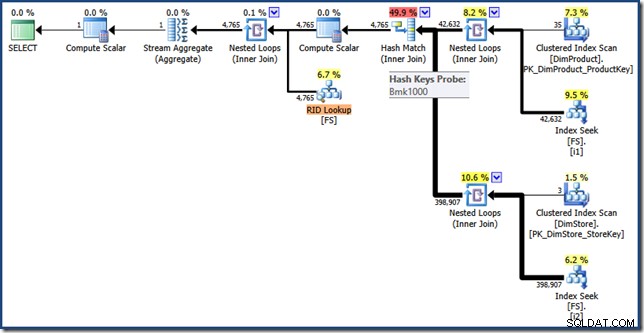
Sluta tankar
Optimeringsomskrivningarna som visas här är inriktade på frågor som returnerar ett relativt litet antal rader från en stor faktatabell. Dessa omskrivningar har varit tillgängliga i alla utgåvor av SQL Server sedan 2005.
Även om den är avsedd att påskynda selektiva stjärn- (och snöflinga)-schemafrågor i datalagring, kan optimeraren tillämpa dessa tekniker varhelst den upptäcker en lämplig uppsättning tabeller och kopplingar. Heuristiken som används för att upptäcka stjärnfrågor är ganska bred, så du kan stöta på planformer med StarJoinInfo strukturer i nästan vilken typ av databas som helst. Alla tabeller av rimlig storlek (säg 100 sidor eller mer) med referenser till mindre (dimensionsliknande) tabeller är en potentiell kandidat för dessa optimeringar (observera att explicita främmande nycklar är inte krävs).
För er som gillar sådana saker kallas optimerarregeln som är ansvarig för att generera selektiva stjärnkopplingsmönster från en logisk n-tabellkoppling StarJoinToIdxStrategy (stjärnanslutning till indexstrategi).