Frågor måste cachelagras i varje tungt laddad databas, det finns helt enkelt inget sätt för en databas att hantera all trafik med rimlig prestanda. Det finns olika mekanismer där en frågecache kan implementeras. Från och med MySQL-frågecachen, som brukade fungera utmärkt för mestadels skrivskyddad, låg samtidiga arbetsbelastningar och som inte har någon plats i höga samtidiga arbetsbelastningar (i den utsträckning som Oracle tog bort den i MySQL 8.0), till externa nyckel-värde-lager som Redis, memcached eller CouchBase.
Det största problemet med att använda ett externt dedikerat datalager (eftersom vi inte skulle rekommendera att använda MySQL-frågecache till någon) är att detta är ännu ett datalager att hantera. Det är ännu en miljö att underhålla, skalningsproblem att hantera, buggar att felsöka och så vidare.
Så varför inte slå två flugor i en smäll genom att utnyttja din proxy? Antagandet här är att du använder en proxy i din produktionsmiljö, eftersom den hjälper belastningsbalansfrågor över instanser och maskerar den underliggande databastopologin genom att tillhandahålla en enkel slutpunkt till applikationer. ProxySQL är ett utmärkt verktyg för jobbet, eftersom det dessutom kan fungera som ett cachinglager. I det här blogginlägget visar vi dig hur du cachelagrar frågor i ProxySQL med ClusterControl.
Hur fungerar frågecache i ProxySQL?
Först och främst lite bakgrund. ProxySQL hanterar trafik genom frågeregler och det kan utföra frågecache med samma mekanism. ProxySQL lagrar cachade frågor i en minnesstruktur. Cachad data vräkas med inställningen time-to-live (TTL). TTL kan definieras för varje frågeregel individuellt så det är upp till användaren att bestämma om frågeregler ska definieras för varje enskild fråga, med distinkt TTL eller om hon bara behöver skapa ett par regler som matchar majoriteten av trafiken.
Det finns två konfigurationsinställningar som definierar hur en frågecache ska användas. Först, mysql-query_cache_size_MB som definierar en mjuk gräns för frågans cachestorlek. Det är ingen hård gräns så ProxySQL kan använda något mer minne än så, men det räcker för att hålla minnesutnyttjandet under kontroll. Den andra inställningen du kan justera är mysql-query_cache_stores_empty_result . Den definierar om en tom resultatuppsättning cachelagras eller inte.
ProxySQL-frågecache är utformad som ett nyckel-värdelager. Värdet är resultatet av en fråga och nyckeln är sammansatt av sammanlänkade värden som:användare, schema och frågetext. Sedan skapas en hash av den strängen och den hash används som nyckel.
Konfigurera ProxySQL som en frågecache med ClusterControl
Som den initiala installationen har vi ett replikeringskluster med en master och en slav. Vi har också en enda ProxySQL.
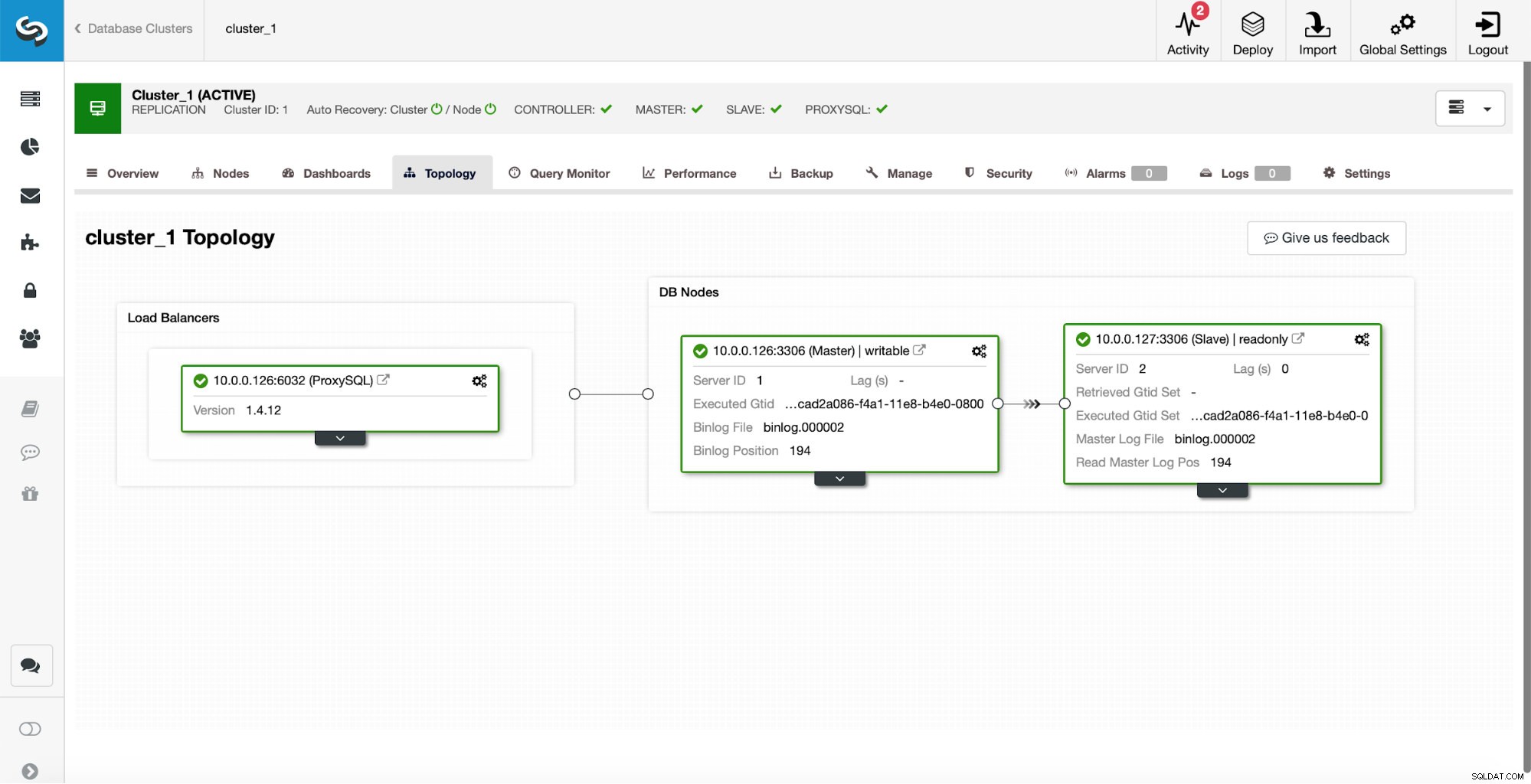
Detta är inte på något sätt en installation av produktionsklass eftersom vi skulle behöva implementera någon form av hög tillgänglighet för proxylagret (till exempel genom att distribuera mer än en ProxySQL-instans och sedan hålla liv ovanpå dem för flytande virtuell IP), men det kommer att vara mer än tillräckligt för våra tester.
Först ska vi verifiera ProxySQL-konfigurationen för att säkerställa att inställningarna för frågecache är vad vi vill att de ska vara.
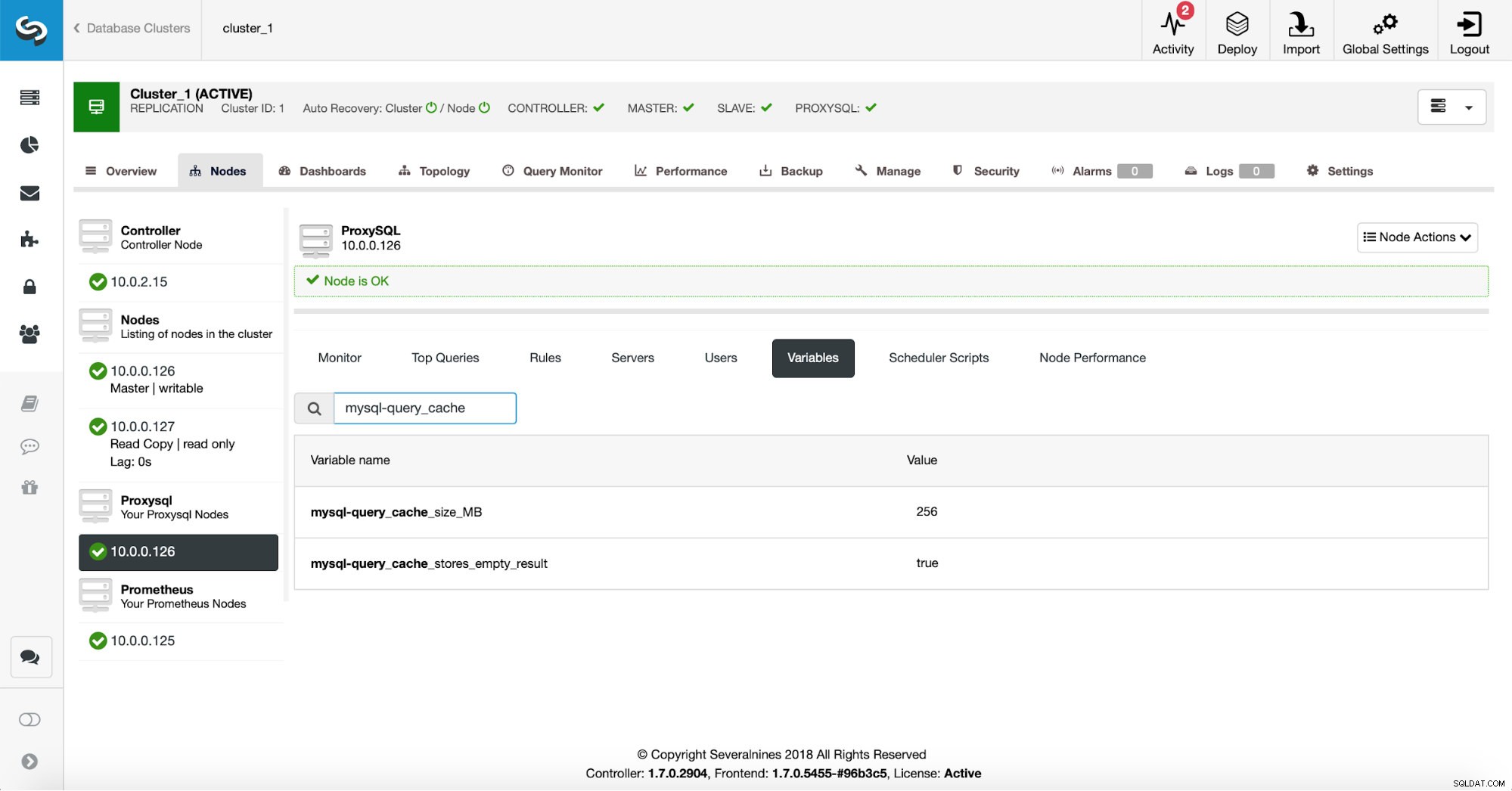
256 MB frågecache bör vara ungefär rätt och vi vill cachelagra även de tomma resultatuppsättningarna - ibland behöver en fråga som inte returnerar några data fortfarande göra mycket arbete för att verifiera att det inte finns något att returnera.
Nästa steg är att skapa frågeregler som matchar de frågor du vill cache. Det finns två sätt att göra det i ClusterControl.
Lägga till frågeregler manuellt
Första sättet kräver lite mer manuella åtgärder. Med ClusterControl kan du enkelt skapa vilken frågeregel du vill, inklusive frågeregler som gör cachningen. Låt oss först ta en titt på listan över reglerna:
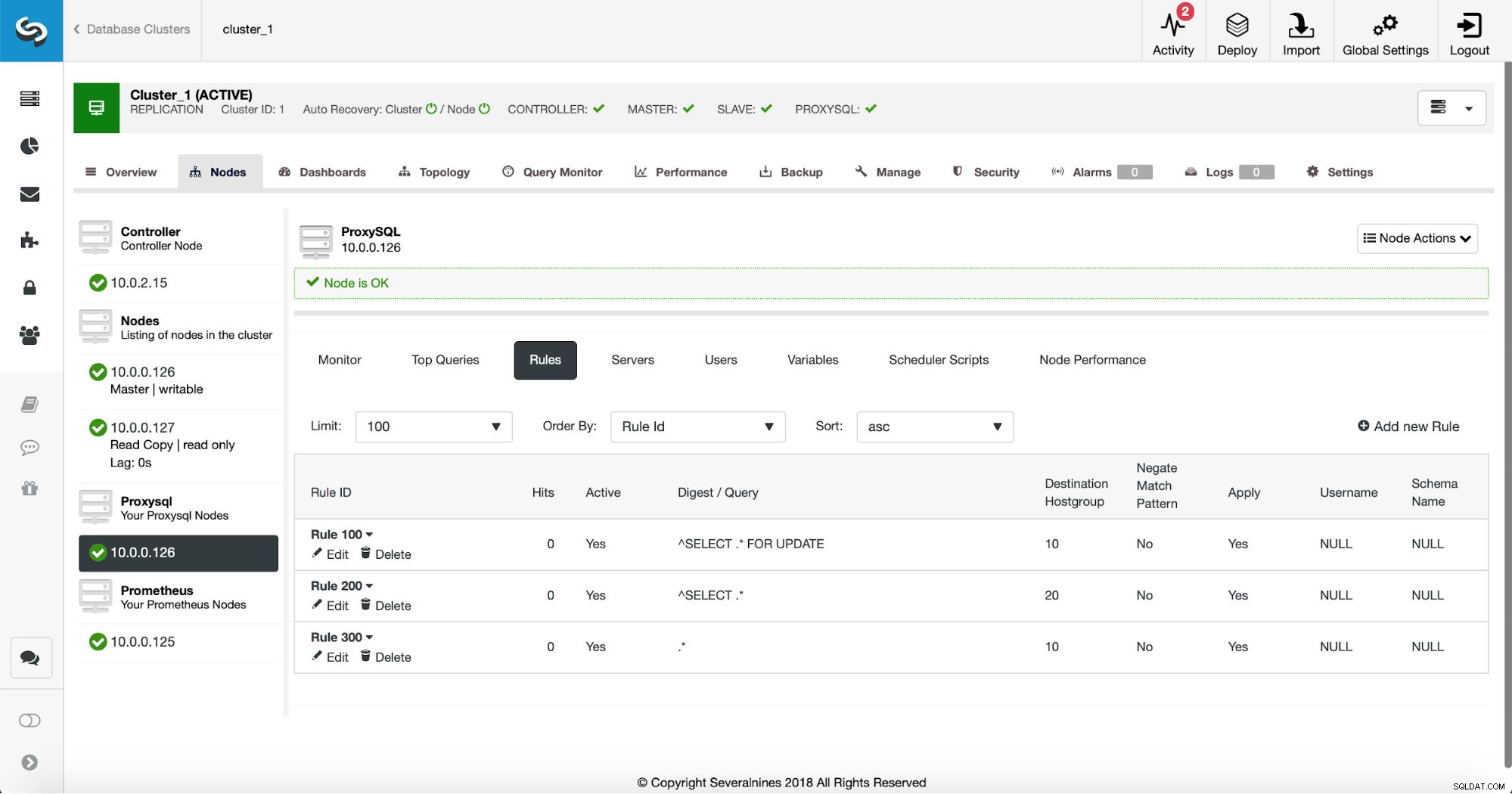
Vid det här laget har vi en uppsättning frågeregler för att utföra läs/skrivdelningen. Den första regeln har ett ID på 100. Vår nya frågeregel måste bearbetas före den så vi kommer att använda lägre regel-ID. Låt oss skapa en frågeregel som gör cachelagring av frågor som liknar denna:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c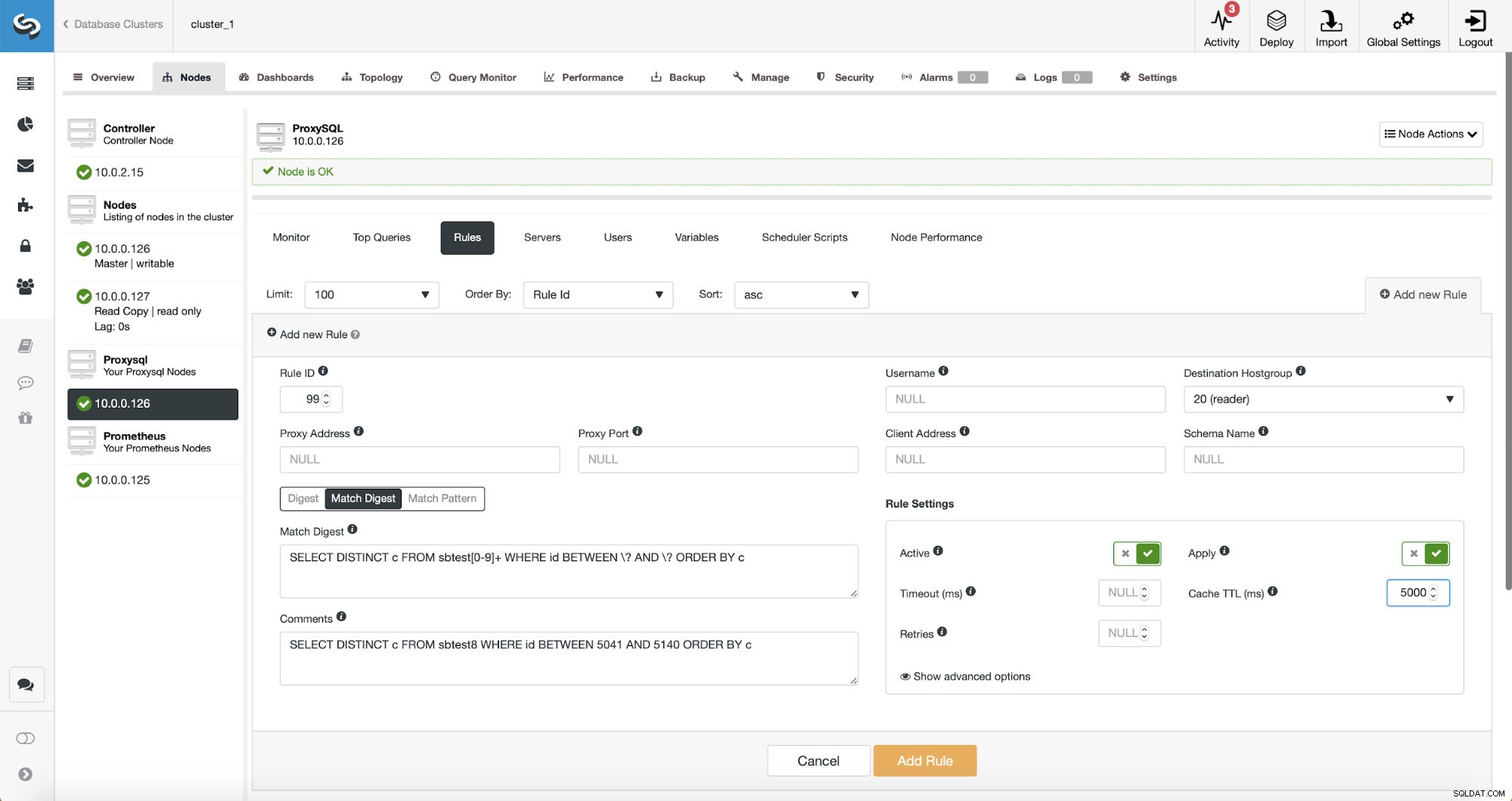
Det finns tre sätt att matcha frågan:Sammanfattning, Matchsammanfattning och Matchmönster. Låt oss prata lite om dem här. Först, Match Digest. Vi kan här ställa in ett reguljärt uttryck som matchar en generaliserad frågesträng som representerar någon frågetyp. Till exempel för vår fråga:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cDen generiska representationen kommer att vara:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cSom du kan se tog den bort argumenten till WHERE-satsen, därför representeras alla frågor av denna typ som en enda sträng. Det här alternativet är ganska trevligt att använda eftersom det matchar hela frågetypen och, vad som är ännu viktigare, det har tagit bort alla blanksteg. Detta gör det så mycket lättare att skriva ett reguljärt uttryck eftersom du inte behöver ta hänsyn till konstiga radbrytningar, blanksteg i början eller slutet av strängen och så vidare.
Digest är i grunden en hash som ProxySQL beräknar över Match Digest-formuläret.
Slutligen matchar Matchmönster mot fullständig frågetext, eftersom den skickades av klienten. I vårt fall kommer frågan ha formen av:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cVi kommer att använda Match Digest eftersom vi vill att alla dessa frågor ska omfattas av frågeregeln. Om vi vill cachelagra just den specifika frågan, skulle ett bra alternativ vara att använda Matchningsmönster.
Det reguljära uttrycket som vi använder är:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN \? AND \? ORDER BY cVi matchar bokstavligen den exakta generaliserade frågesträngen med ett undantag - vi vet att den här frågan träffade flera tabeller och därför la vi till ett reguljärt uttryck för att matcha dem alla.
När detta är gjort kan vi se om frågeregeln är i kraft eller inte.
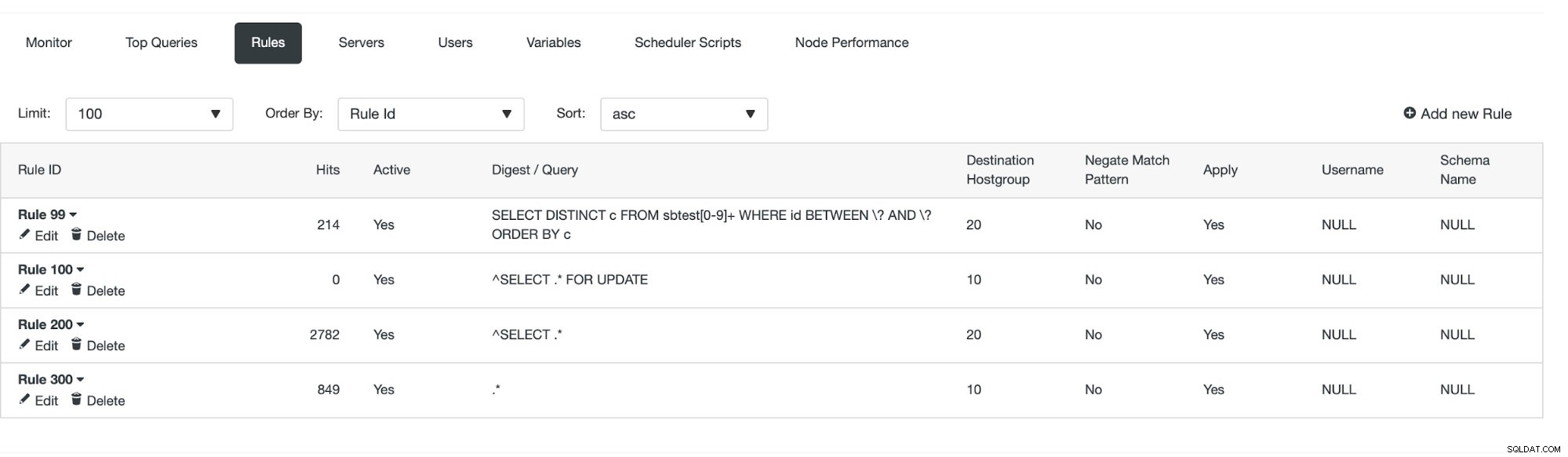
Vi kan se att "träffar" ökar vilket betyder att vår frågeregel används. Därefter ska vi titta på ett annat sätt att skapa en frågeregel.
Använda ClusterControl för att skapa frågeregler
ProxySQL har en användbar funktionalitet för att samla in statistik över de frågor den dirigerat. Du kan spåra data som exekveringstid, hur många gånger en viss fråga utfördes och så vidare. Dessa data finns också i ClusterControl:
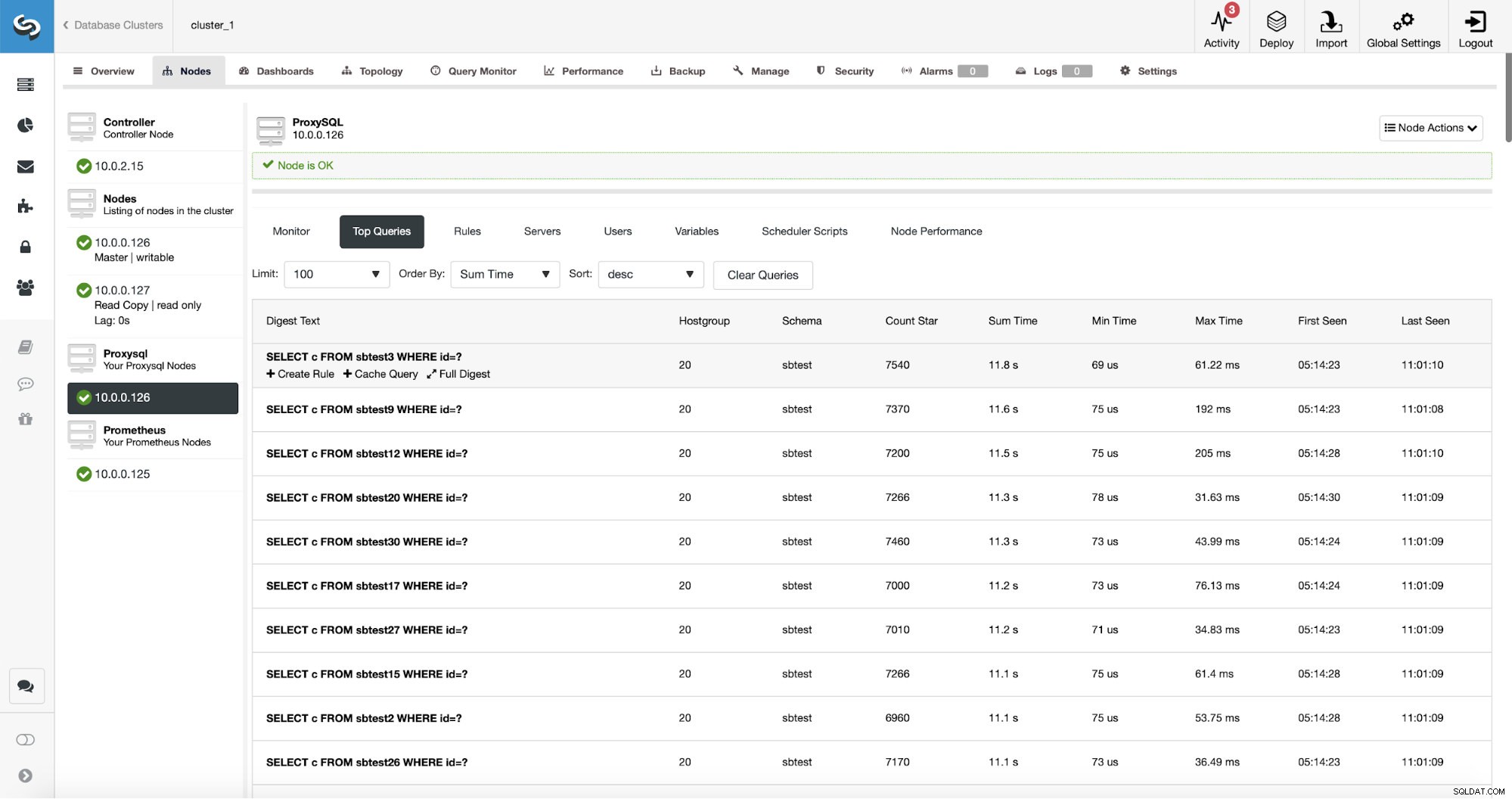
Vad som är ännu bättre, om du pekar på en viss frågetyp kan du skapa en frågeregel relaterad till den. Du kan också enkelt cachelagra just den här frågetypen.
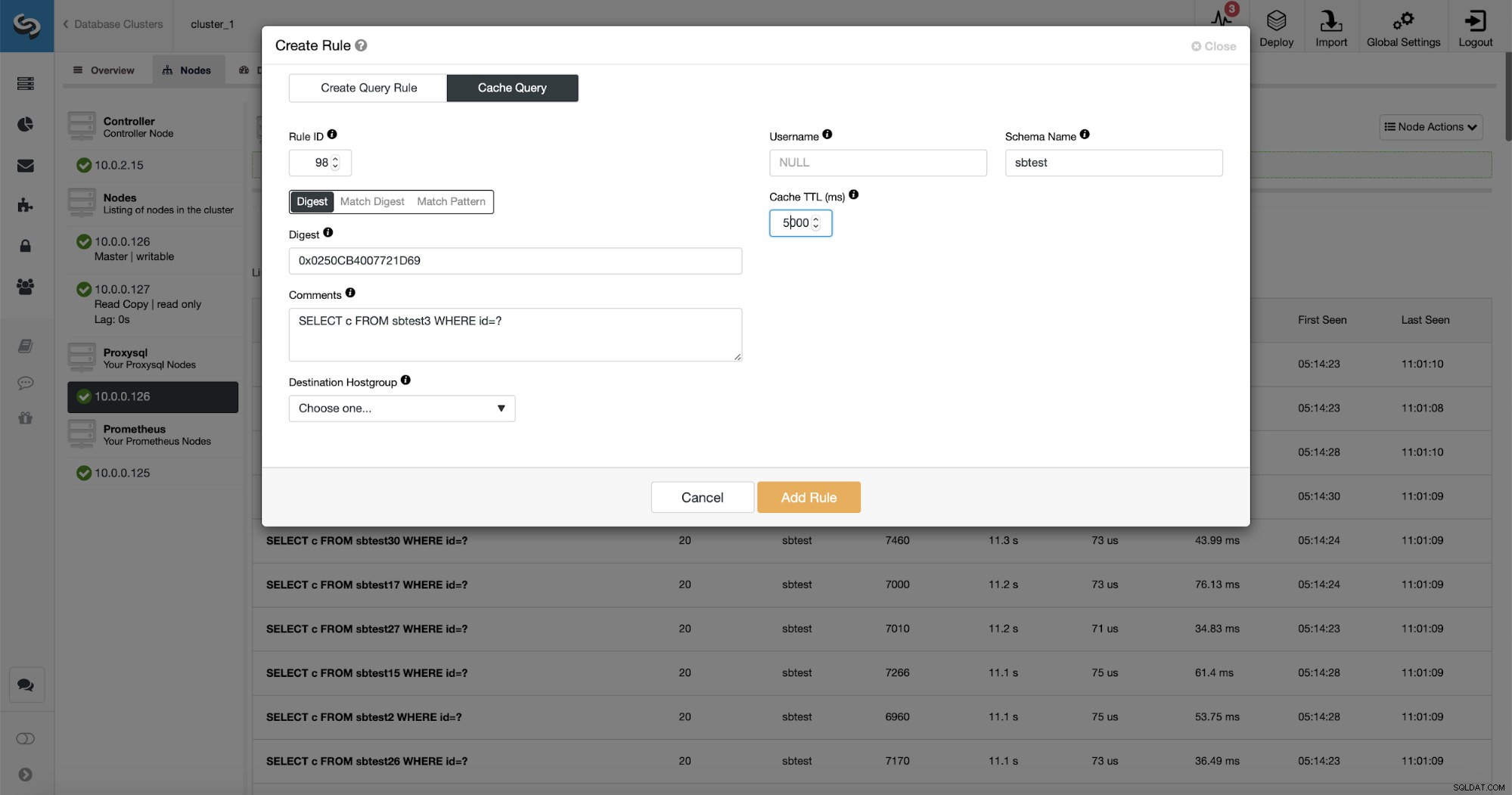
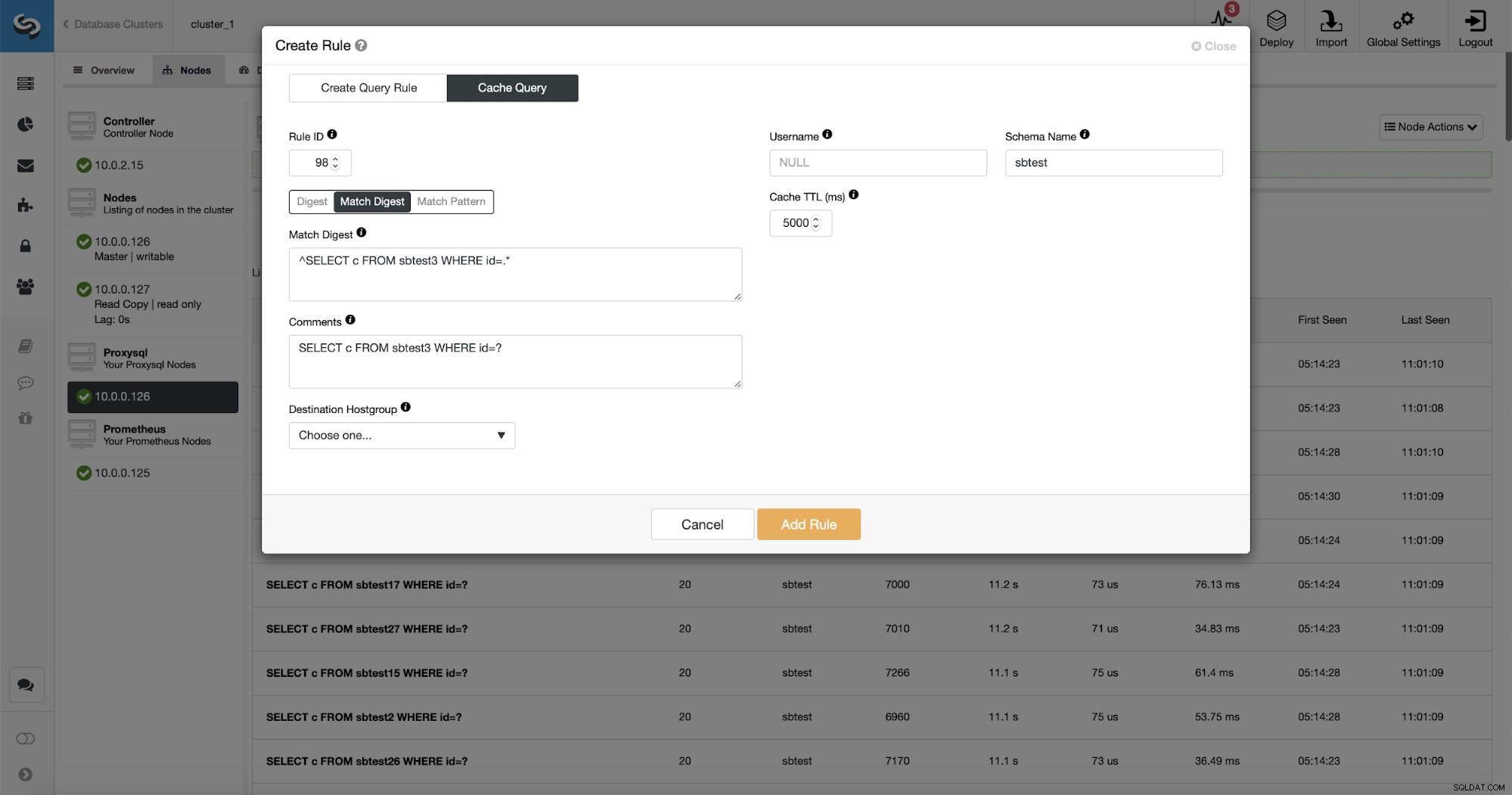
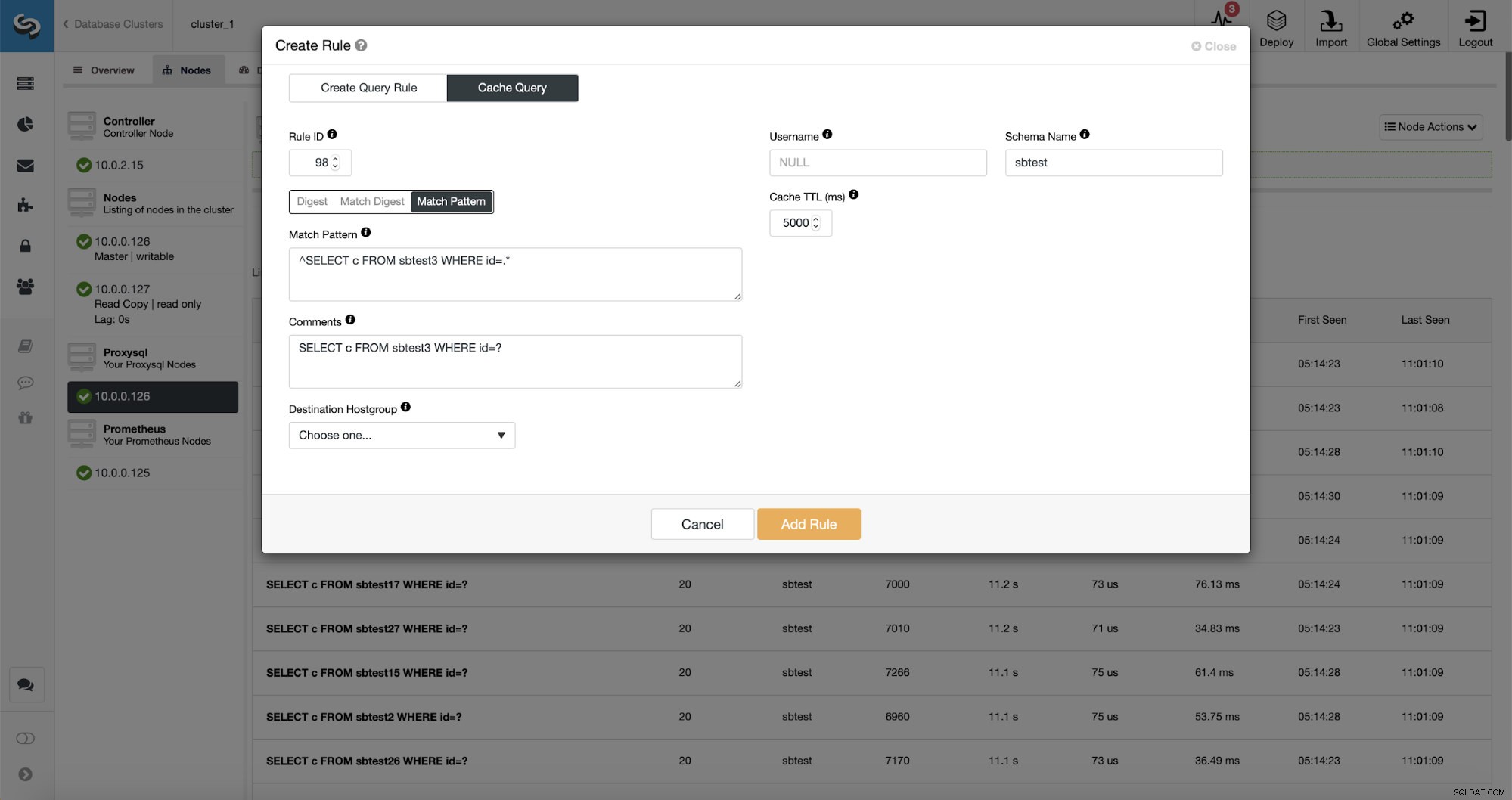
Som du kan se är en del av data som Regel IP, Cache TTL eller Schema Name redan ifyllda. ClusterControl kommer också att fylla data baserat på vilken matchningsmekanism du valde att använda. Vi kan enkelt använda antingen hash för en given frågetyp eller så kan vi använda Match Digest eller Match Pattern om vi skulle vilja finjustera det reguljära uttrycket (till exempel göra samma sak som vi gjorde tidigare och utöka det reguljära uttrycket så att det matchar alla tabeller i sbtest-schema).
Detta är allt du behöver för att enkelt skapa query cache-regler i ProxySQL. Ladda ner ClusterControl för att prova det idag.