Länge borta är de dagar då en databas distribuerades som en enda nod eller instans - en kraftfull, fristående server som hade i uppdrag att hantera alla förfrågningar till databasen. Vertikal skalning var vägen att gå - ersätt servern med en annan, ännu kraftfullare. Under dessa tider behövde man egentligen inte besväras av nätverksprestanda. Så länge förfrågningarna kom in var allt bra.
Men nuförtiden byggs databaser som kluster med noder sammankopplade över ett nätverk. Det är inte alltid ett snabbt, lokalt nätverk. Med företag som når global skala måste databasinfrastrukturen också sträcka sig över hela världen, för att hålla sig nära kunderna och för att minska latensen. Det kommer med ytterligare utmaningar som vi måste möta när vi designar en högtillgänglig databasmiljö. I det här blogginlägget kommer vi att undersöka nätverksproblem som du kan möta och ge några förslag på hur du ska hantera dem.
Två huvudalternativ för MySQL eller MariaDB HA
Vi täckte detta ämne ganska utförligt i ett av whitepapers, men låt oss titta på de två huvudsakliga sätten att bygga hög tillgänglighet för MySQL och MariaDB.
Galera-kluster
Galera Cluster är delad-ingenting, praktiskt taget synkron klusterteknologi för MySQL. Det gör det möjligt att bygga inställningar för flera skrivare som kan sträcka sig över hela världen. Galera trivs i miljöer med låg latens men den kan också konfigureras för att fungera med långa WAN-anslutningar. Galera har en inbyggd kvorummekanism som säkerställer att data inte äventyras i händelse av nätverkspartitionering av några av noderna.
MySQL-replikering
MySQL-replikering kan vara antingen asynkron eller semisynkron. Båda är designade för att bygga storskaliga replikeringskluster. Som i alla andra master-slave eller primär-sekundära replikeringsinställningar kan det bara finnas en writer, mastern. Andra noder, slavar, används för failover-ändamål eftersom de innehåller kopian av datamängden från masern. Slavar kan också användas för att läsa data och avlasta en del av arbetsbelastningen från mastern.
Båda lösningarna har sina egna gränser och funktioner, båda lider av olika problem. Båda kan påverkas av instabila nätverksanslutningar. Låt oss ta en titt på dessa begränsningar och hur vi kan designa miljön för att minimera påverkan av en instabil nätverksinfrastruktur.
Galera Cluster - Nätverksproblem
Låt oss först ta en titt på Galera Cluster. Som vi diskuterade fungerar det bäst i en miljö med låg latens. Ett av de största latensrelaterade problemen i Galera är hur Galera hanterar skrivningarna. Vi kommer inte att gå in på alla detaljer i den här bloggen, utan vidare läsa i vår Galera Cluster för MySQL-handledning. Summan av kardemumman är att, på grund av certifieringsprocessen för skrivningar, där alla noder i klustret måste komma överens om huruvida skrivningen kan tillämpas eller inte, är din skrivprestanda för en rad strikt begränsad av nätverkets tur och returtid mellan skribenten noden och den mest avlägsna noden. Så länge latensen är acceptabel och så länge du inte har för många hot spots i din data, kan WAN-inställningar fungera alldeles utmärkt. Problemet börjar när nätverkslatens spikar då och då. Skrivningar kommer då att ta 3 eller 4 gånger längre tid än vanligt och som ett resultat kan databaser börja överbelastas med långvariga skrivningar.
En av de stora egenskaperna hos Galera Cluster är dess förmåga att upptäcka klustertillståndet och reagera på nätverkspartitionering. Om en nod i klustret inte kan nås kommer den att vräkas från klustret och den kommer inte att kunna utföra några skrivningar. Detta är avgörande för att upprätthålla dataintegriteten under den tid då klustret delas - endast majoriteten av klustret kommer att acceptera skrivningar. Minoriteten kommer att klaga. För att hantera detta introducerar Galera ett stort antal kontroller och konfigurerbara timeouts för att undvika falska varningar om mycket övergående nätverksproblem. Tyvärr, om nätverket är opålitligt, kommer Galera Cluster inte att kunna fungera korrekt - noder kommer att börja lämna klustret, gå med i det senare. Det kommer att vara särskilt problematiskt när vi har Galera Cluster som spänner över WAN - separerade delar av klustret kan försvinna slumpmässigt om det sammankopplade nätverket inte fungerar korrekt.
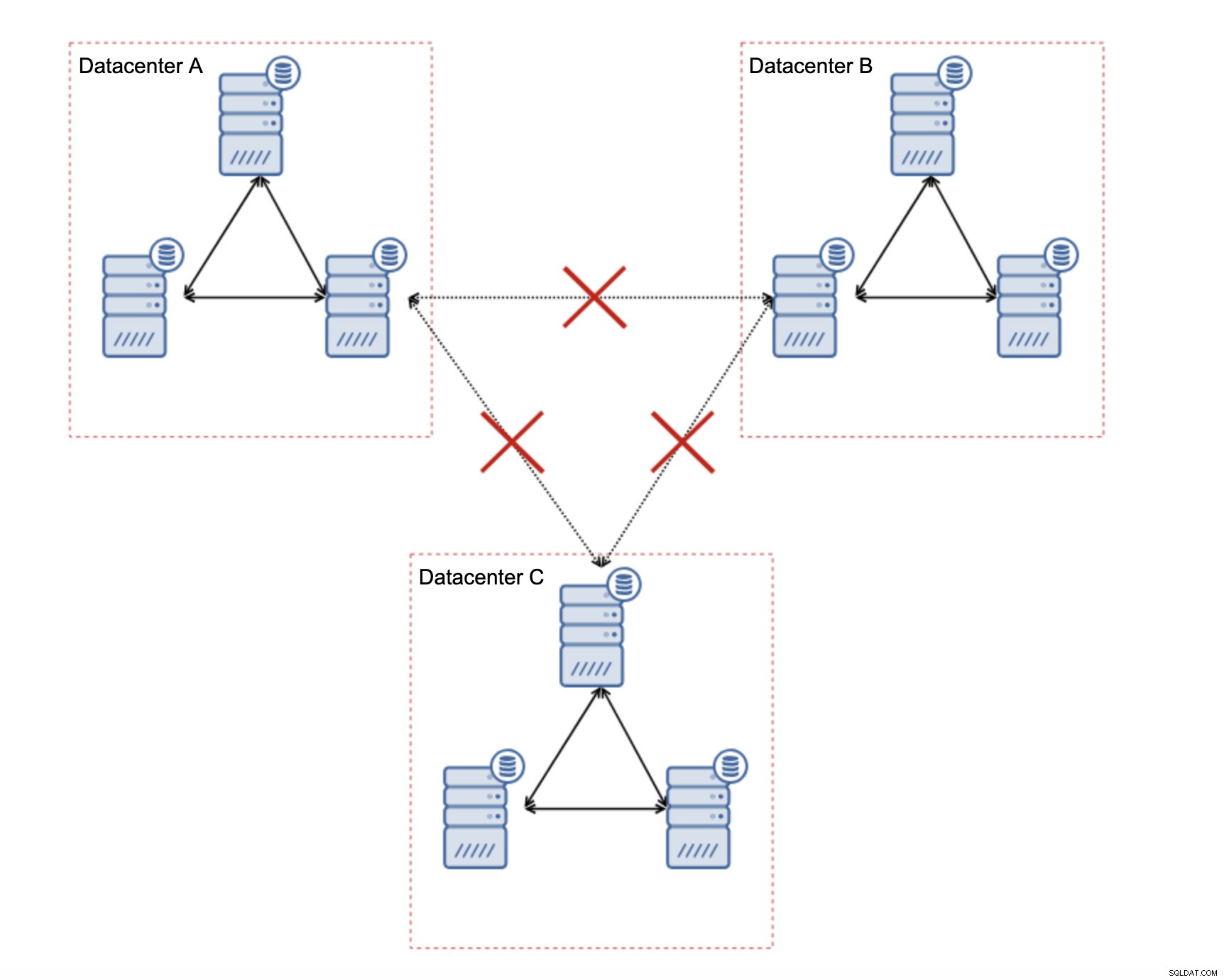
Hur designar man Galera Cluster för ett instabilt nätverk?
Först och främst, om du har nätverksproblem inom det enda datacentret, finns det inte mycket du kan göra om du inte kommer att kunna lösa dessa problem på något sätt. Otillförlitligt lokalt nätverk är en no go för Galera Cluster, du måste överväga att använda någon annan lösning (även om, för att vara ärlig, opålitligt nätverk alltid kommer att vara ett problem). Å andra sidan, om problemen endast är relaterade till WAN-anslutningar (och detta är ett av de mest typiska fallen), kan det vara möjligt att ersätta WAN Galera-länkar med vanlig asynkron replikering (om Galera WAN-inställningen inte hjälpte).
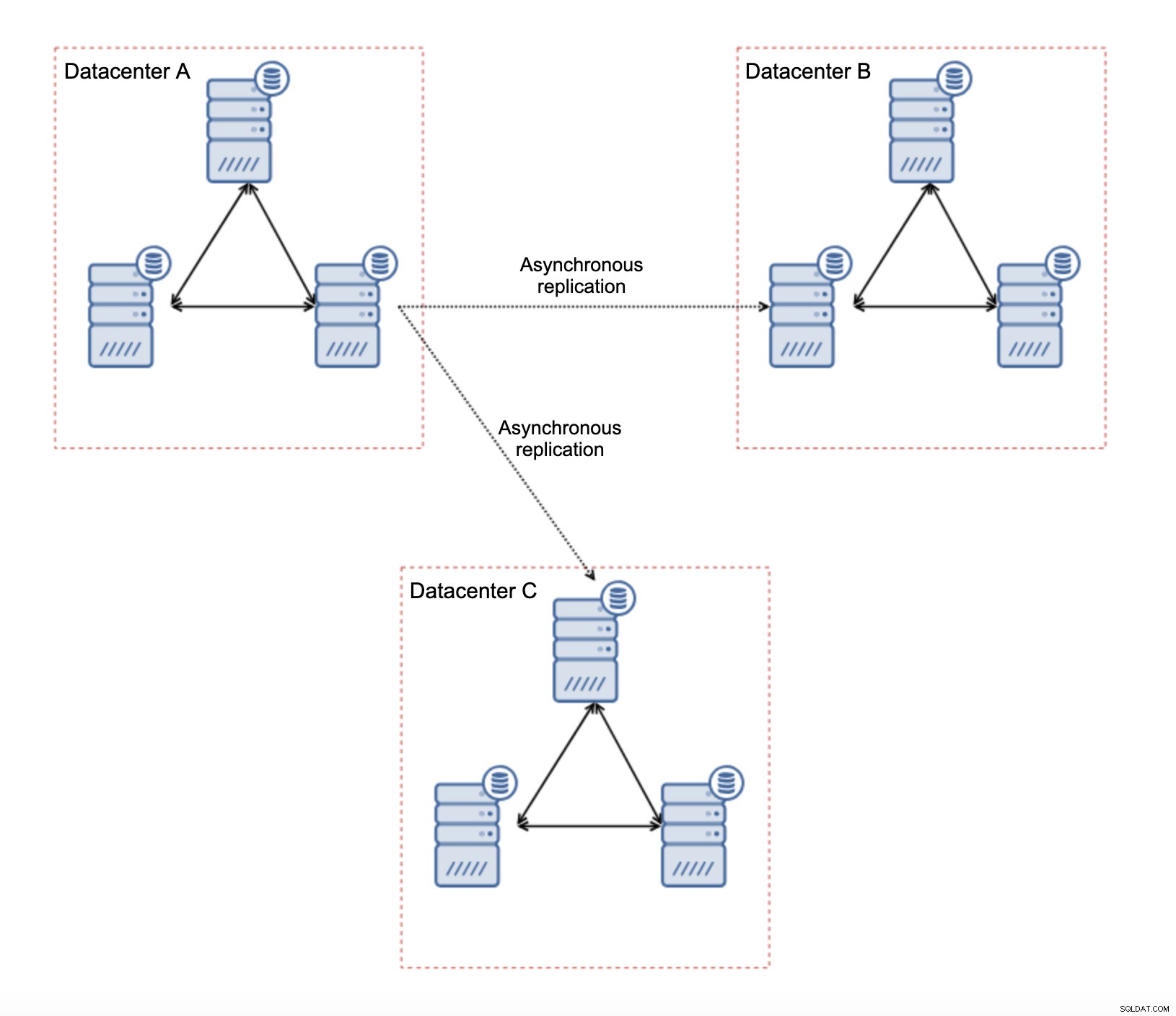
Det finns flera inneboende begränsningar i den här installationen - huvudproblemet är att skrivningarna brukade ske lokalt. Nu måste alla skrivningar gå till "master" datacenter (DC A i vårt fall). Det här är inte så illa som det låter. Vänligen kom ihåg att i en hel-Galera-miljö kommer skrivningar att saktas ner av latensen mellan noder i olika datacenter. Även lokala skrifter kommer att påverkas. Det kommer att vara mer eller mindre samma avmattning som med asynkron installation där du skulle skicka skrivningarna över WAN till "master"-datacentret.
Att använda asynkron replikering kommer med alla de problem som är typiska för asynkron replikering. Replikeringsfördröjning kan bli ett problem - inte för att Galera skulle vara mer presterande, det är bara att Galera skulle sakta ner trafiken via flödeskontroll medan replikering inte har någon mekanism för att strypa trafiken på mastern.
Ett annat problem är failover:om "master" Galera-noden (den som fungerar som master för slavarna i andra datacenter) skulle misslyckas, måste någon mekanism skapas för att peka om slavar till en annan fungerande masternod. Det kan vara något slags skript, det är också möjligt att prova något med VIP där "slaven" Galera-klustret slavar av Virtual IP som alltid är tilldelad den levande Galera-noden i "master"-klustret.
Den största fördelen med en sådan installation är att vi tar bort WAN Galera-länken, vilket innebär att vårt "master"-kluster inte kommer att bromsas av det faktum att några av noderna är separerade geografiskt. Som vi nämnde förlorar vi förmågan att skriva i alla datacenter, men latensmässig skrivning över WAN är detsamma som att skriva lokalt till Galera-klustret som sträcker sig över WAN. Som ett resultat bör den övergripande latensen förbättras. Asynkron replikering är också mindre sårbar för de instabila nätverken. I värsta fall kommer replikeringslänken att bryta och den kommer att återskapas när nätverken konvergerar.
Hur designar man MySQL-replikering för ett instabilt nätverk?
I det föregående avsnittet täckte vi Galera-klustret och en lösning var att använda asynkron replikering. Hur ser det ut i en vanlig asynkron replikeringsinställning? Låt oss titta på hur ett instabilt nätverk kan orsaka de största störningarna i replikeringsinställningarna.
Först av allt, latens - en av de viktigaste smärtpunkterna för Galera Cluster. Vid replikering är det nästan en icke-fråga. Om du inte använder semi-synkron replikering det vill säga - i sådana fall kommer ökad latens att sakta ner skrivningar. Vid asynkron replikering har latens ingen inverkan på skrivprestandan. Det kan dock ha viss inverkan på replikeringsfördröjningen. Det är inte något så betydande som det var för Galera, men du kan förvänta dig fler fördröjningsspikar och totalt sett mindre stabil replikeringsprestanda om nätverket mellan noder lider av hög latens. Detta beror mest på det faktum att mastern lika gärna kan tjäna flera skrivningar innan dataöverföring till slaven kan initieras på nätverk med hög latens.
Nätverksinstabiliteten kan definitivt påverka replikeringslänkarna men det är återigen inte så kritiskt. MySQL-slavar kommer att försöka återansluta till sina masters och replikering kommer att påbörjas.
Huvudproblemet med MySQL-replikering är faktiskt något som Galera Cluster löser internt - nätverkspartitionering. Vi talar om nätverkspartitionering som tillståndet där segment av nätverket är separerade från varandra. MySQL-replikering använder en enda skrivarnod - master. Oavsett hur du designar din miljö, måste du skicka dina texter till mästaren. Om mastern inte är tillgänglig (av någon anledning) kan programmet inte göra sitt jobb om det inte körs i något slags skrivskyddat läge. Därför finns det ett behov av att välja den nya mastern så snart som möjligt. Det är här problemen dyker upp.
Först, hur man berättar vilken värd som är en mästare och vilken som inte är det. Ett av de vanliga sätten är att använda variabeln "read_only" för att skilja slavar från mastern. Om noden har read_only aktiverad (set read_only=1) är den en slav (eftersom slavar inte ska hantera några direktskrivningar). Om noden har read_only inaktiverad (set read_only=0) är den en master. För att göra saker säkrare är ett vanligt tillvägagångssätt att ställa in read_only=1 i MySQL-konfigurationen - vid en omstart är det säkrare om noden dyker upp som en slav. Sådant "språk" kan förstås av proxyservrar som ProxySQL eller MaxScale.
Låt oss ta en titt på ett exempel.
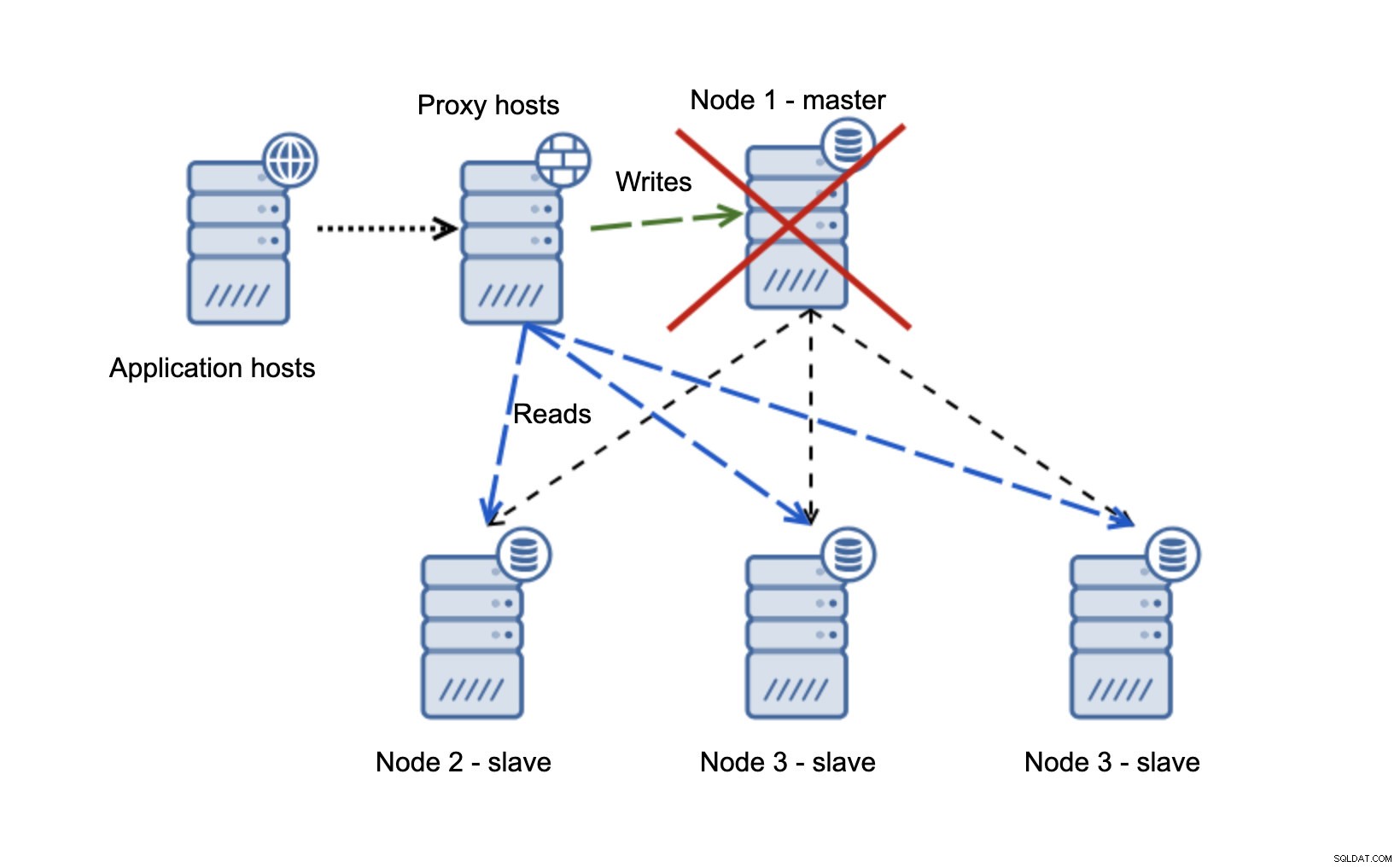
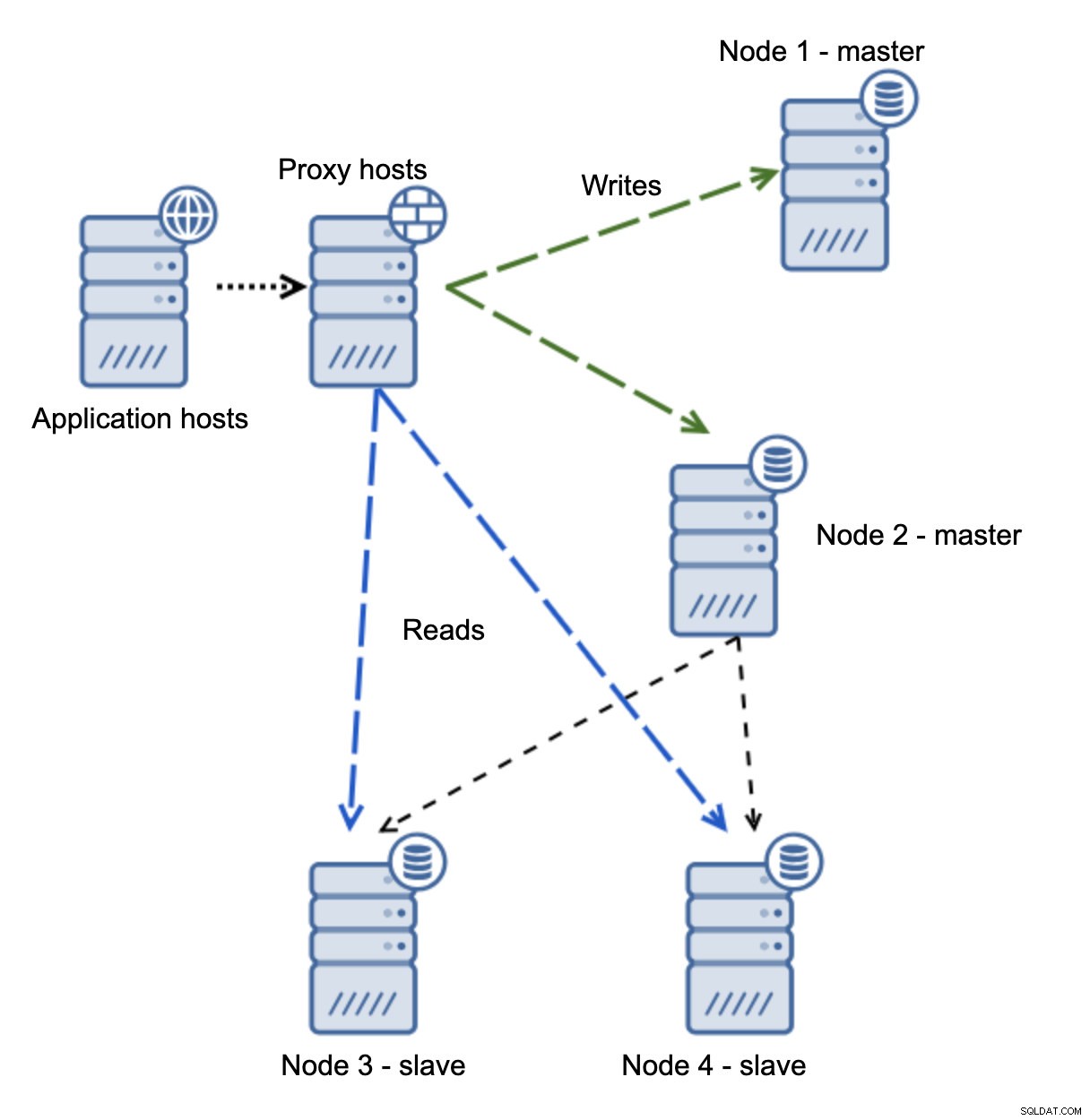
Vi har applikationsvärdar som ansluter till proxylagret. Proxies utför läs/skrivdelning och skickar SELECT till slavar och skriver till master. Om master är nere, failover utförs, ny master befordras, proxylager upptäcker det och börjar skicka skrivningar till en annan nod.
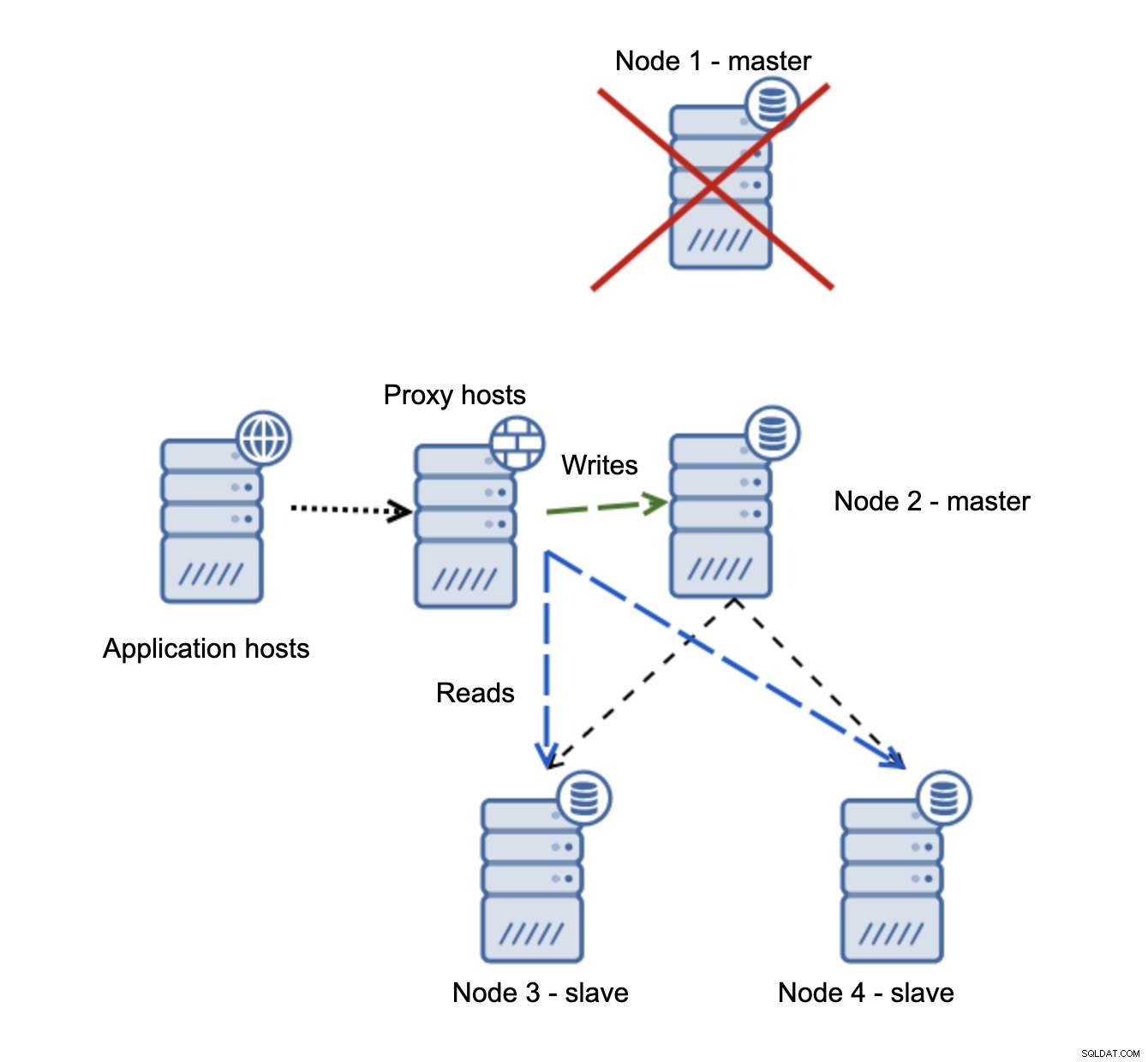
Om nod1 startar om kommer den att visa read_only=1 och den kommer att upptäckas som en slav. Det är inte idealiskt eftersom det inte replikerar men det är acceptabelt. Helst bör den gamla mästaren inte dyka upp alls förrän den är ombyggd och slavad från den nya mästaren.
En mycket mer problematisk situation är om vi måste hantera nätverkspartitionering. Låt oss överväga samma inställning:programnivå, proxynivå och databaser.
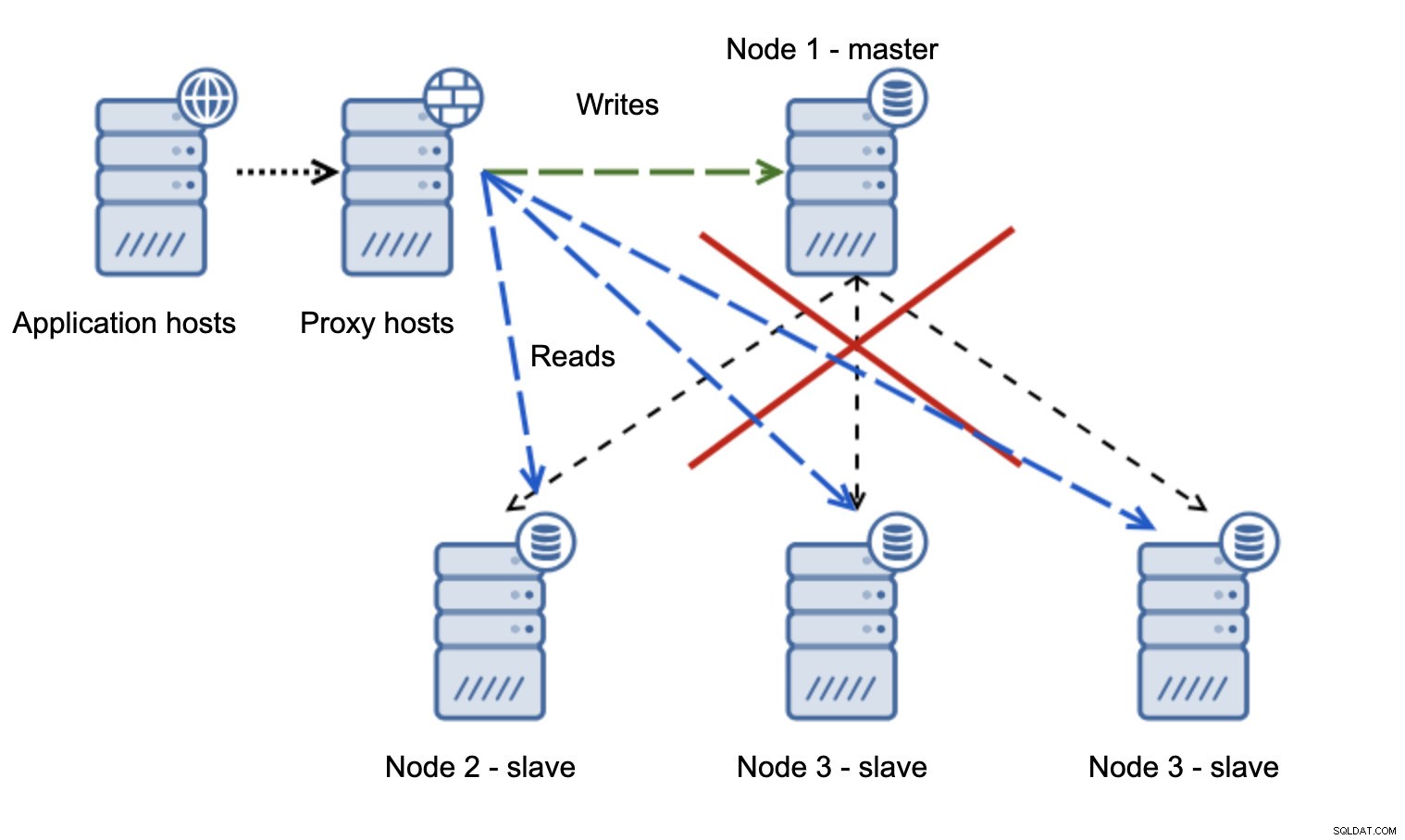
När nätverket gör att mastern inte kan nås är applikationen inte användbar eftersom inga skrivningar gör det till sin destination. Ny mästare befordras, skrivningar omdirigeras till den. Vad händer då om nätverksproblemen upphör och den gamla mastern blir nåbar? Den har inte stoppats, därför använder den fortfarande read_only=0:
Du har nu hamnat i en delad hjärna, när skrivningar riktades till två noder. Den här situationen är ganska dålig eftersom det kan ta ett tag att slå samman olika datauppsättningar och det är en ganska komplex process.
Vad kan göras för att undvika detta problem? Det finns ingen silverkula men vissa åtgärder kan vidtas för att minimera sannolikheten för att en delad hjärna ska hända.
Först och främst kan du vara smartare när det gäller att upptäcka masterns tillstånd. Hur ser slavarna på det? Kan de replikera från det? Kanske kan några av slavarna fortfarande ansluta till mastern, vilket betyder att mastern är igång eller åtminstone gör det möjligt att stoppa den om det skulle behövas. Hur är det med proxy-lagret? Ser alla proxynoder mastern som otillgänglig? Om några fortfarande kan ansluta, kan du försöka använda dessa noder för att ssh in i mastern och stoppa den före failover?
Programvaran för failover-hantering kan också vara smartare för att upptäcka nätverkets tillstånd. Kanske använder den RAFT eller något annat klusterprotokoll för att bygga ett kvorummedvetet kluster. Om en failover-hanteringsprogramvara kan upptäcka den delade hjärnan, kan den också vidta vissa åtgärder baserat på detta, som till exempel att ställa in alla noder i det partitionerade segmentet till read_only för att säkerställa att den gamla mastern inte kommer att visas som skrivbar när nätverken konvergerar.
Du kan också inkludera verktyg som Consul eller Etcd för att lagra klustrets tillstånd. Proxylagret kan konfigureras för att använda data från Consul, inte statusen för variabeln read_only. Det kommer sedan att vara upp till failover-hanteringsmjukvaran att göra nödvändiga ändringar i Consul så att alla proxyservrar skickar trafiken till en korrekt, ny master.
Några av dessa tips kan till och med kombineras för att göra feldetekteringen ännu mer tillförlitlig. Sammantaget är det möjligt att minimera chanserna att replikeringsklustret kommer att drabbas av opålitliga nätverk.
Som du kan se, oavsett om vi pratar om Galera eller MySQL-replikering, kan instabila nätverk bli ett allvarligt problem. Å andra sidan, om du designar miljön rätt kan du fortfarande få den att fungera. Vi hoppas att det här blogginlägget hjälper dig att skapa miljöer som fungerar stabila även om nätverken inte är det.