Galera-replikering är relativt nytt om man jämför med MySQL-replikering, som stöds inbyggt sedan MySQL v3.23. Även om MySQL-replikering är designad för enkelriktad master-slav-replikering, kan den konfigureras som en aktiv master-master-uppställning med dubbelriktad replikering. Även om det är lätt att installera och vissa användningsfall kan dra nytta av detta "hack", finns det ett antal varningar. Å andra sidan är Galera kluster en annan typ av teknik att lära sig och hantera. Är det värt det?
I det här blogginlägget kommer vi att jämföra master-master-replikering med Galera-kluster.
replikeringskoncept
Innan vi går in i jämförelsen, låt oss förklara de grundläggande koncepten bakom dessa två replikeringsmekanismer.
I allmänhet genererar varje modifiering av MySQL-databasen en händelse i binärt format. Den här händelsen transporteras till de andra noderna beroende på vilken replikeringsmetod som valts - MySQL-replikering (native) eller Galera-replikering (patchad med wsrep API).
MySQL-replikering
Följande diagram illustrerar dataflödet för en lyckad transaktion från en nod till en annan när du använder MySQL-replikering:
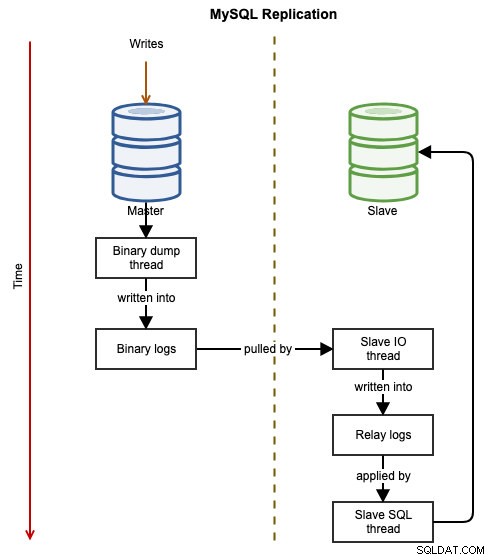
Den binära händelsen skrivs in i masterns binära logg. Slaven/slavarna via slave_IO_tråd kommer att dra de binära händelserna från masterns binära logg och replikera dem till dess relälogg. slave_SQL_tråden kommer då att tillämpa händelsen från reläloggen asynkront. På grund av replikeringens asynkrona karaktär är det inte garanterat att slavservern har data när mastern utför ändringen.
Helst kommer MySQL-replikering att ha slaven att konfigureras som en skrivskyddad server genom att ställa in read_only=ON eller super_read_only=ON. Detta är en försiktighetsåtgärd för att skydda slaven från oavsiktliga skrivningar som kan leda till datainkonsekvens eller fel under master-failover (t.ex. felaktiga transaktioner). Men i en master-master aktiv-aktiv replikeringsinställning måste skrivskyddat vara inaktiverat på den andra mastern för att tillåta att skrivningar bearbetas samtidigt. Den primära mastern måste konfigureras för att replikera från den sekundära mastern genom att använda CHANGE MASTER-satsen för att aktivera cirkulär replikering.
Galera-replikering
Följande diagram illustrerar datareplikeringsflödet för en framgångsrik transaktion från en nod till en annan för Galera Cluster:
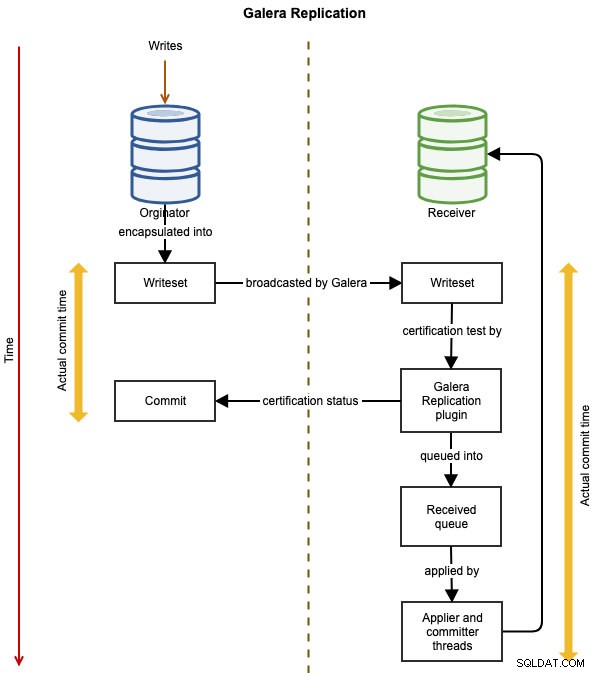
Händelsen är inkapslad i en skrivuppsättning och sänds från ursprungsnoden till de andra noderna i klustret med hjälp av Galera-replikering. Skrivuppsättningen genomgår certifiering på varje Galera-nod och om den godkänns kommer appliärtrådarna att tillämpa skrivuppsättningen asynkront. Detta innebär att slavservern så småningom kommer att bli konsekvent, efter överenskommelse av alla deltagande noder i global total ordning. Det är logiskt synkront, men själva skrivningen och commiting till tabellutrymmet sker oberoende, och därmed asynkront på varje nod med en garanti för att förändringen sprider sig på alla noder.
Undvika kollision med primär nyckel
För att kunna distribuera MySQL-replikering i master-master-setup, måste man justera det automatiska inkrementvärdet för att undvika primärnyckelkollision för INSERT mellan två eller flera replikerande masters. Detta tillåter primärnyckelvärdet på masters att interfoliera varandra och förhindra att samma autoinkrementnummer används två gånger på någon av noderna. Detta beteende måste konfigureras manuellt, beroende på antalet masters i replikeringsinställningen. Värdet för auto_increment_increment är lika med antalet replikerande masters och auto_increment_offset måste vara unika mellan dem. Till exempel bör följande rader finnas i motsvarande my.cnf:
Master1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Master2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2På samma sätt använder Galera Cluster samma trick för att undvika kollisioner med primärnyckel genom att kontrollera det automatiska ökningsvärdet och förskjuta automatiskt med wsrep_auto_increment_control variabel. Om den är inställd på 1 (standard), justeras automatiskt auto_increment_increment och auto_increment_offset variabler beroende på storleken på klustret och när klustrets storlek ändras. Detta undviker replikeringskonflikter på grund av auto_increment. I en master-slave-miljö kan denna variabel ställas in på OFF.
Konsekvensen av denna konfiguration är att värdet för automatisk ökning inte kommer att vara i sekventiell ordning, som visas i följande tabell för ett Galera-kluster med tre noder:
| Nod | auto_increment_increment | auto_increment_offset | Automatisk ökningsvärde |
|---|---|---|---|
| Nod 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Nod 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Nod 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Om ett program utför infogningsoperationer på följande noder i följande ordning:
- Nod1, Nod3, Nod2, Node3, Nod3, Nod1, Nod3 ..
Då kommer det primära nyckelvärdet som kommer att lagras i tabellen att vara:
- 1, 6, 8, 9, 12, 13, 15 ..
Enkelt sagt, när du använder master-master-replikering (MySQL-replikering eller Galera), måste din applikation kunna tolerera icke-sekventiella automatiska inkrementvärden i sin datauppsättning.
För ClusterControl-användare, notera att det stöder distribution av MySQL master-master-replikering med en gräns på två masters per replikeringskluster, endast för aktiv-passiv installation. Därför konfigurerar ClusterControl inte medvetet masterna med auto_increment_increment och auto_increment_offset variabler.
Datakonsistens
Galera Cluster kommer med sin flödeskontrollmekanism, där varje nod i klustret måste hänga med vid replikering, annars måste alla andra noder sakta ner för att den långsammaste noden ska hinna ikapp. Detta minimerar i princip sannolikheten för slavfördröjning, även om det fortfarande kan hända men inte lika signifikant som i MySQL-replikering. Som standard tillåter Galera att noder ligger minst 16 transaktioner efter när de ansöker via variabeln gcs.fc_limit . Om du vill göra kritiska läsningar (en SELECT som måste returnera den mest uppdaterade informationen), vill du förmodligen använda sessionsvariabeln, wsrep_sync_wait .
Galera Cluster å andra sidan kommer med ett skydd mot datainkonsekvens där en nod kommer att kastas från klustret om den misslyckas med att tillämpa någon skrivuppsättning av någon anledning. Till exempel, när en Galera-nod misslyckas med att tillämpa skrivuppsättning på grund av internt fel av den underliggande lagringsmotorn (MySQL/MariaDB), kommer noden att dra sig själv från klustret med följande fel:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..För att fixa datakonsistensen måste den felande noden synkroniseras om innan den tillåts gå med i klustret. Detta kan göras manuellt eller genom att radera datakatalogen för att utlösa överföring av ögonblicksbildstillstånd (full synkronisering från en givare).
MySQL master-master replikering upprätthåller inte datakonsistensskydd och en slav tillåts divergera t.ex. replikera en delmängd av data eller släpa efter, vilket gör slaven inkonsekvent med mastern. Den är designad för att replikera data i ett flöde - från master ner till slavar. Datakonsistenskontroller måste utföras manuellt eller via externa verktyg som Percona Toolkit pt-table-checksum eller mysql-replikeringskontroll.
Konfliktlösning
Generellt tillåter master-master (eller multi-master, eller dubbelriktad) replikering mer än en medlem i klustret att bearbeta skrivningar. Med MySQL-replikering, i händelse av replikeringskonflikt, slutar slavens SQL-tråd helt enkelt att tillämpa nästa fråga tills konflikten är löst, antingen genom att manuellt hoppa över replikeringshändelsen, fixa de felande raderna eller synkronisera slaven. Enkelt sagt, det finns inget stöd för automatisk konfliktlösning för MySQL-replikering.
Galera Cluster ger ett bättre alternativ genom att försöka igen med den felande transaktionen under replikering. Genom att använda wsrep_retry_autocommit variabel, kan man instruera Galera att automatiskt försöka igen en misslyckad transaktion på grund av klusteromfattande konflikter, innan ett fel returneras till klienten. Om inställt på 0, kommer inga återförsök att göras, medan ett värde på 1 (standard) eller mer anger antalet återförsök. Detta kan vara användbart för att hjälpa applikationer som använder autocommit för att undvika dödlägen.
Nodkonsensus och failover
Galera använder Group Communication System (GCS) för att kontrollera nodkonsensus och tillgänglighet mellan klustermedlemmar. Om en nod är ohälsosam kommer den automatiskt att vräkas från klustret efter gmcast.peer_timeout värde, standard till 3 sekunder. En hälsosam Galera-nod i "Synced"-tillstånd anses vara en pålitlig nod för läsning och skrivning, medan andra inte är det. Denna design förenklar avsevärt hälsokontrollprocedurer från de övre nivåerna (lastbalanserare eller applikation).
I MySQL-replikering bryr sig en master inte om sina slav(ar), medan en slav endast har konsensus med sin enda master via slave_IO_thread process vid replikering av de binära händelserna från masterns binära logg. Om en master går ner kommer detta att bryta replikeringen och ett försök att återupprätta länken kommer att göras varje slave_net_timeout (standard till 60 sekunder). Ur applikations- eller lastbalanserarens perspektiv måste hälsokontrollprocedurerna för replikeringsslaven åtminstone innefatta kontroll av följande tillstånd:
- Seconds_Behind_Master
- Slav_IO_kör
- Slav_SQL_kör
- skrivskyddad variabel
- super_read_only variabel (MySQL 5.7.8 och senare)
När det gäller failover är master-master-replikering och Galera-noder i allmänhet lika. De har samma datamängd (även om du kan replikera en delmängd av data i MySQL-replikering, men det är ovanligt för master-master) och delar samma roll som masters, som kan hantera läsningar och skrivningar samtidigt. Därför finns det faktiskt ingen failover från databasens synvinkel på grund av denna jämvikt. Endast från applikationssidan som skulle kräva failover för att hoppa över de ooperativa noderna. Tänk på att eftersom MySQL-replikering är asynkron är det möjligt att inte alla ändringar som gjorts på mastern kommer att ha spridits till den andra mastern.
Nodprovisionering
Processen att bringa en nod i synkronisering med klustret innan replikering startar, kallas provisionering. I MySQL-replikering är provisionering av en ny nod en manuell process. Man måste ta en säkerhetskopia av mastern och återställa den till den nya noden innan du ställer in replikeringslänken. För en befintlig replikeringsnod, om masterns binära loggar har roterats (baserat på expire_logs_days , standard till 0 betyder ingen automatisk borttagning), kan du behöva omprovisionera noden med den här proceduren. Det finns också externa verktyg som Percona Toolkit pt-table-sync och ClusterControl för att hjälpa dig med detta. ClusterControl stöder omsynkronisering av en slav med bara två klick. Du har alternativ att synkronisera om genom att ta en säkerhetskopia från den aktiva mastern eller en befintlig säkerhetskopia.
I Galera finns det två sätt att göra detta - inkrementell tillståndsöverföring (IST) eller överföring av tillståndsbild (SST). IST-processen är den föredragna metoden där endast de saknade transaktionerna överförs från en givares cache. SST-processen liknar att ta en fullständig säkerhetskopia från givaren, det är vanligtvis ganska resurskrävande. Galera kommer automatiskt att avgöra vilken synkroniseringsprocess som ska utlösas baserat på anslutningens tillstånd. I de flesta fall, om en nod inte går med i ett kluster, raderar du helt enkelt MySQL-datafilen för den problematiska noden och startar MySQL-tjänsten. Galera-provisioneringsprocessen är mycket enklare, den är väldigt praktisk när du skalar ut ditt kluster eller återinför en problematisk nod i klustret.
Llöst kopplade vs tätt kopplade
MySQL-replikering fungerar mycket bra även över långsammare anslutningar och med anslutningar som inte är kontinuerliga. Den kan också användas över olika hårdvara, miljöer och operativsystem. De flesta lagringsmotorer stöder det, inklusive MyISAM, Aria, MEMORY och ARCHIVE. Denna löst kopplade installation gör att MySQL master-master replikering fungerar bra i en blandad miljö med mindre begränsningar.
Galera-noder är tätt kopplade, där replikeringsprestandan är lika snabb som den långsammaste noden. Galera använder en flödeskontrollmekanism för att kontrollera replikeringsflödet mellan medlemmar och eliminera eventuell slavfördröjning. Replikeringen kan vara snabb eller långsam på varje nod och justeras automatiskt av Galera. Därför rekommenderas det att använda enhetliga hårdvaruspecifikationer för alla Galera-noder, särskilt med avseende på CPU, RAM, diskundersystem, nätverkskort och nätverkslatens mellan noder i klustret.
Slutsatser
Sammanfattningsvis är Galera Cluster överlägsen jämfört med MySQL master-master-replikering på grund av dess synkrona replikeringsstöd med stark konsistens, plus mer avancerade funktioner som automatisk medlemskontroll, automatisk nodprovisionering och flertrådiga slavar. I slutändan beror detta på hur applikationen interagerar med databasservern. Vissa äldre applikationer byggda för en fristående databasserver kanske inte fungerar bra på en klustrad installation.
För att förenkla våra punkter ovan motiverar följande skäl när man ska använda MySQL master-master replikering:
- Saker som inte stöds av Galera:
- Replikering för icke-InnoDB/XtraDB-tabeller som MyISAM, Aria, MEMORY eller ARCHIVE.
- XA-transaktioner.
- Statusbaserad replikering mellan masters (t.ex. när bandbredden är mycket dyr).
- Förlitar sig på explicit låsning som LOCK TABLES-satsen.
- Den allmänna frågeloggen och den långsamma frågeloggen måste dirigeras till en tabell istället för en fil.
- Llöst kopplad installation där hårdvaruspecifikationerna, mjukvaruversionen och anslutningshastigheten är avsevärt olika på varje master.
- När du redan har en MySQL-replikeringskedja och du vill lägga till ytterligare en aktiv master/backup-master för redundans för att påskynda failover och återställningstid om en av masterna inte är tillgänglig.
- Om din applikation inte kan modifieras för att kringgå Galera Cluster-begränsningar och att ha en MySQL-medveten belastningsbalanserare som ProxySQL eller MaxScale är inte ett alternativ.
Skäl att välja Galera Cluster framför MySQL master-master replikering:
- Förmåga att säkert skriva till flera masters.
- Datakonsistens hanteras (och garanteras) automatiskt över databaser.
- Nya databasnoder lätt att introducera och synkronisera.
- Fel eller inkonsekvenser upptäcks automatiskt.
- I allmänhet mer avancerade och robusta funktioner för hög tillgänglighet.