Innan du försöker utföra några schemaändringar på dina produktionsdatabaser bör du se till att du har en stenhård återställningsplan; och att ditt ändringsförfarande har testats och validerats framgångsrikt i en separat miljö. Samtidigt är det ditt ansvar att se till att förändringen inte orsakar någon eller minsta möjliga påverkan som är acceptabel för verksamheten. Det är definitivt ingen lätt uppgift.
I den här artikeln kommer vi att ta en titt på hur man utför databasändringar på MySQL och MariaDB på ett kontrollerat sätt. Vi kommer att prata om några goda vanor i ditt dagliga DBA-arbete. Vi kommer att fokusera på förhandskrav och uppgifter under de faktiska operationerna och problemen som du kan möta när du hanterar databasschemaändringar. Vi kommer också att prata om verktyg med öppen källkod som kan hjälpa dig i processen.
Testa och återställa scenarier
Säkerhetskopiering
Det finns många sätt att förlora din data. Schemauppgraderingsfel är en av dem. Till skillnad från programkod kan du inte släppa ett paket med filer och deklarera att en ny version har implementerats. Du kan inte heller bara lägga tillbaka en äldre uppsättning filer för att återställa dina ändringar. Naturligtvis kan du köra ett annat SQL-skript för att ändra databasen igen, men det finns fall då det enda korrekta sättet att återställa ändringar är genom att återställa hela databasen från backup.
Men vad händer om du inte har råd att återställa din databas till den senaste säkerhetskopian, eller om ditt underhållsfönster inte är tillräckligt stort (med tanke på systemprestanda), så att du inte kan utföra en fullständig säkerhetskopiering av din databas före ändringen?
Man kan ha en sofistikerad, redundant miljö, men så länge data modifieras på både primära och standby-platser finns det inte mycket att göra åt det. Många skript kan bara köras en gång, eller så är ändringarna omöjliga att ångra. Det mesta av SQL-ändringskoden delas in i två grupper:
- Kör en gång – du kan inte lägga till samma kolumn i tabellen två gånger.
- Omöjligt att ångra – när du har släppt den kolumnen är den borta. Du kan utan tvekan återställa din databas, men det är inte precis en ångra.
Du kan ta itu med detta problem på minst två möjliga sätt. En skulle vara att aktivera den binära loggen och ta en säkerhetskopia, som är kompatibel med PITR. Sådan säkerhetskopiering måste vara fullständig, komplett och konsekvent. För xtrabackup, så länge den innehåller en fullständig datauppsättning, kommer den att vara PITR-kompatibel. För mysqldump finns det ett alternativ att göra det PITR-kompatibelt också. För mindre ändringar skulle en variant av mysqldump backup vara att bara ta en delmängd av data för att ändra. Detta kan göras med alternativet --where. Säkerhetskopieringen bör vara en del av det planerade underhållet.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlEn annan möjlighet är att använda CREATE TABLE AS SELECT.
Du kan lagra data eller enkla strukturändringar i form av en fast temporär tabell. Med detta tillvägagångssätt får du en källa om du behöver återställa dina ändringar. Det kan vara ganska praktiskt om du inte ändrar mycket data. Återställningen kan göras genom att ta ut data från den. Om några misslyckanden inträffar när data kopieras till tabellen tas den automatiskt bort och skapas inte, så se till att ditt uttalande skapar en kopia som du behöver.
Uppenbarligen finns det vissa begränsningar också.
Eftersom ordningen av raderna i de underliggande SELECT-satserna inte alltid kan fastställas, flaggas CREATE TABLE ... IGNORE SELECT och CREATE TABLE ... REPLACE SELECT som osäkra för satsbaserad replikering. Sådana satser ger en varning i felloggen när satsbaserat läge används och skrivs till den binära loggen med det radbaserade formatet när MIXED-läge används.
Ett mycket enkelt exempel på en sådan metod kan vara:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Ett annat intressant alternativ kan vara MariaDB flashback-databas. När en felaktig uppdatering eller radering inträffar och du vill återgå till ett tillstånd för databasen (eller bara en tabell) vid en viss tidpunkt, kan du använda flashback-funktionen.
Tidpunktsåterställning gör det möjligt för DBA:er att återställa data snabbare genom att återställa transaktioner till en tidigare tidpunkt i stället för att utföra en återställning från en säkerhetskopia. Baserat på ROW-baserade DML-händelser kan flashback transformera den binära loggen och vända syften. Det betyder att det kan hjälpa till att snabbt ångra givna radändringar. Till exempel kan den ändra DELETE-händelser till INSERTs och vice versa, och den kommer att byta WHERE och SET delar av UPDATE-händelserna. Denna enkla idé kan dramatiskt påskynda återhämtningen från vissa typer av misstag eller katastrofer. För dem som är bekanta med Oracle-databasen är det en välkänd funktion. Begränsningen för MariaDB flashback är bristen på DDL-stöd.
Skapa en fördröjd replikeringsslav
Sedan version 5.6 har MySQL stöd för fördröjd replikering. En slavserver kan släpa efter mastern med åtminstone en viss tid. Standardfördröjningen är 0 sekunder. Använd alternativet MASTER_DELAY för CHANGE MASTER TO för att ställa in fördröjningen till N sekunder:
CHANGE MASTER TO MASTER_DELAY = N;Det skulle vara ett bra alternativ om du inte hade tid att förbereda ett korrekt återställningsscenario. Du måste ha tillräckligt med fördröjning för att märka den problematiska förändringen. Fördelen med detta tillvägagångssätt är att du inte behöver återställa din databas för att ta ut data som behövs för att fixa din ändring. Standby DB är igång, redo att hämta data vilket minimerar tiden som behövs.
Skapa en asynkron slav som inte är en del av klustret
När det gäller Galera-klustret är det inte lätt att testa förändringar. Alla noder kör samma data, och hög belastning kan skada flödeskontrollen. Så du behöver inte bara kontrollera om ändringarna har tillämpats framgångsrikt, utan också vad påverkan på klustertillståndet var. För att göra din testprocedur så nära produktionsbelastningen som möjligt, kanske du vill lägga till en asynkron slav till ditt kluster och köra ditt test där. Testet kommer inte att påverka synkroniseringen mellan klusternoder, eftersom det tekniskt sett inte är en del av klustret, men du kommer att ha ett alternativ att kontrollera det med riktiga data. Sådan slav kan enkelt läggas till från ClusterControl.
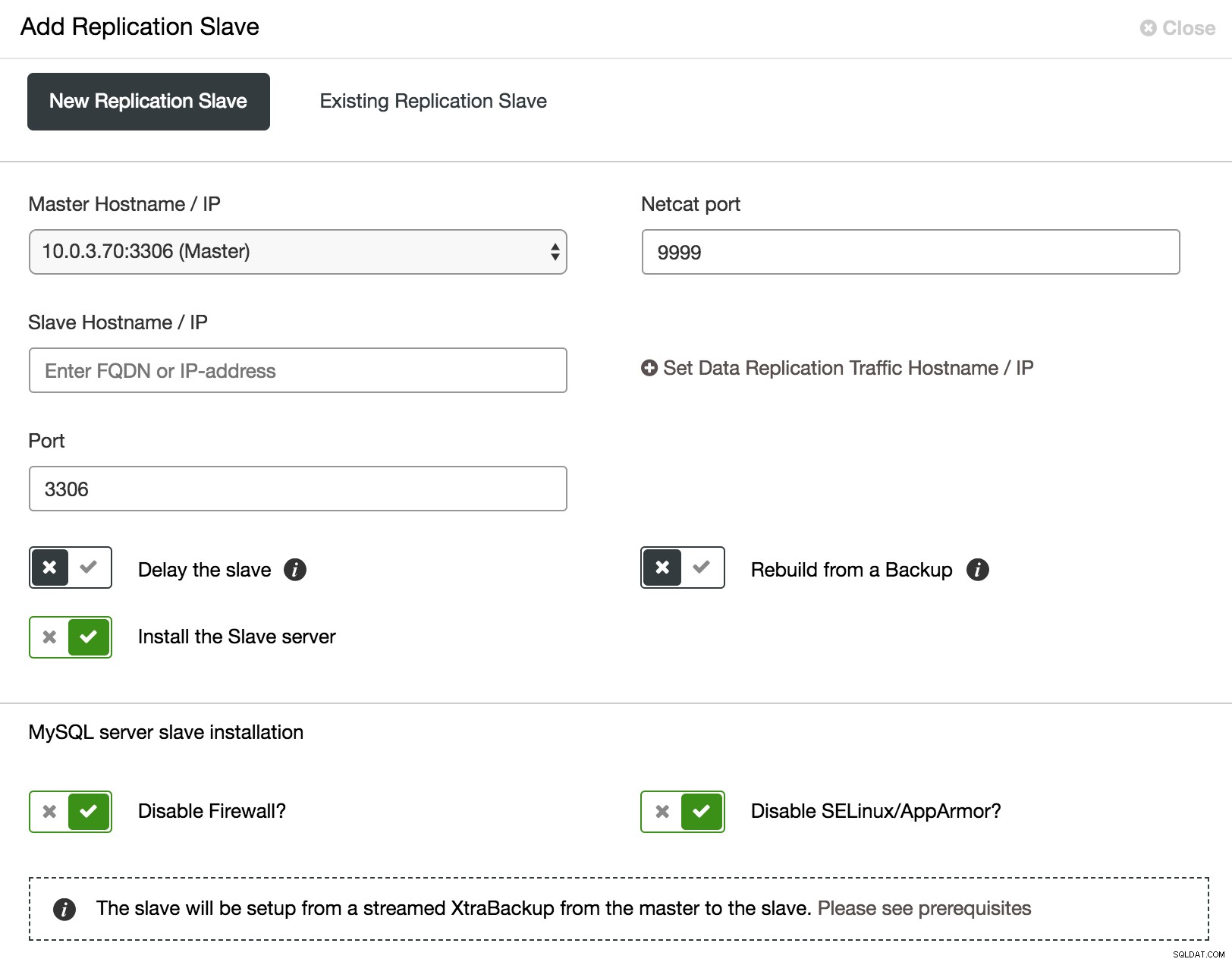 ClusterControl lägg till asynkron slav
ClusterControl lägg till asynkron slav Som visas i skärmdumpen ovan kan ClusterControl automatisera processen att lägga till en asynkron slav på några sätt. Du kan lägga till noden i klustret, fördröja slaven. För att minska påverkan på mastern kan du använda en befintlig säkerhetskopia istället för mastern som datakälla när du bygger slaven.
Klona databas och mäta tid
Ett bra test bör ligga så nära produktionsbytet som möjligt. Det bästa sättet att göra detta är att klona din befintliga miljö.
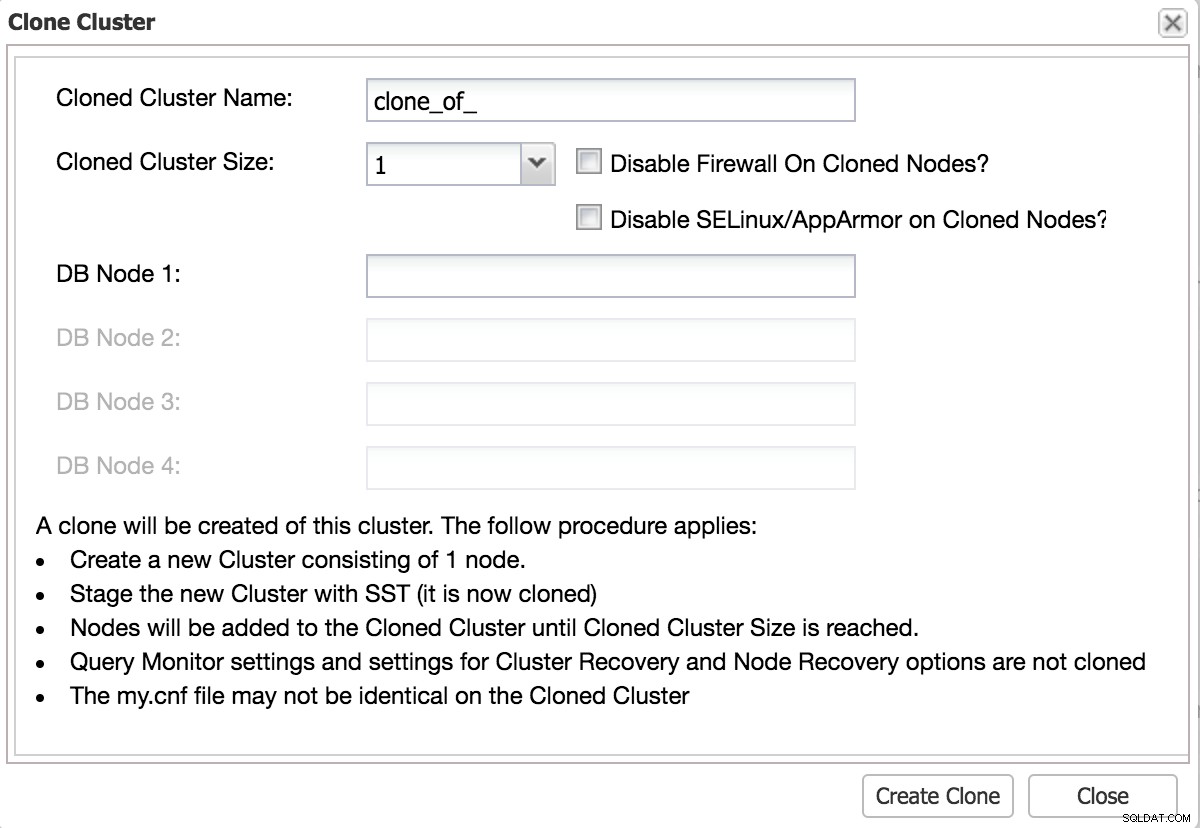 ClusterControl Clone Cluster för test
ClusterControl Clone Cluster för test Utför ändringar via replikering
För att få bättre kontroll över dina ändringar kan du tillämpa dem på en slavserver i förväg och sedan göra omställningen. För satsbaserad replikering fungerar detta bra, men för radbaserad replikering kan detta fungera upp till en viss grad. Radbaserad replikering gör det möjligt för extra kolumner att finnas i slutet av tabellen, så så länge den kan skriva de första kolumnerna går det bra. Tillämpa först dessa inställningar på alla slavar, sedan failover till en av slavarna och implementera sedan ändringen på mastern och anslut den som en slav. Om din ändring innebär att du infogar eller tar bort en kolumn i mitten av tabellen kommer den att fungera med radbaserad replikering.
Användning
Under underhållsfönstret vill vi inte ha programtrafik på databasen. Ibland är det svårt att stänga ner alla applikationer spridda över hela företaget. Alternativt vill vi tillåta endast vissa specifika värdar att komma åt MySQL från fjärrkontrollen (till exempel övervakningssystemet eller backupservern). För detta ändamål kan vi använda Linux-paketfiltrering. För att se vilka paketfiltreringsregler som är tillgängliga kan vi köra följande kommando:
iptables -L INPUT -vFör att stänga MySQL-porten på alla gränssnitt vi använder:
iptables -A INPUT -p tcp --dport mysql -j DROPoch för att öppna MySQL-porten igen efter underhållsfönstret:
iptables -D INPUT -p tcp --dport mysql -j DROPFör de utan root-åtkomst kan du ändra max_connection till 1 eller "hoppa över nätverk".
Loggning
För att få igång loggningsprocessen, använd tee-kommandot vid MySQL-klientprompten, så här:
mysql> tee /tmp/my.out;Det kommandot säger åt MySQL att logga både indata och utdata från din nuvarande MySQL-inloggningssession till en fil som heter /tmp/my.out. Kör sedan din skriptfil med källkommandot.
För att få en bättre uppfattning om dina körtider kan du kombinera den med profileringsfunktionen. Starta profileraren med
SET profiling = 1;Kör sedan din fråga med
SHOW PROFILES;du ser en lista med frågor som profileraren har statistik för. Så till sist väljer du vilken fråga du vill undersöka med
SHOW PROFILE FOR QUERY 1;Verktyg för schemamigrering
Många gånger är en rak ALTER på mastern inte möjlig - i de flesta fall orsakar det fördröjning på slaven, och detta kanske inte är acceptabelt för applikationerna. Vad som dock kan göras är att utföra ändringen i ett rullande läge. Du kan börja med slavar och, när ändringen har tillämpats på slaven, migrera en av slavarna som en ny master, degradera den gamla mastern till en slav och verkställa förändringen på den.
Ett verktyg som kan hjälpa till med en sådan uppgift är Perconas pt-online-schema-change. Pt-online-schema-change är enkelt - det skapar en tillfällig tabell med det önskade nya schemat (till exempel om vi lade till ett index eller tog bort en kolumn från en tabell). Sedan skapar det triggers på det gamla bordet. Dessa triggers är till för att spegla ändringar som sker på det ursprungliga bordet till det nya bordet. Ändringar speglas under schemaändringsprocessen. Om en rad läggs till i den ursprungliga tabellen läggs den också till i den nya. Det emulerar hur MySQL ändrar tabeller internt, men det fungerar på en kopia av tabellen du vill ändra. Det betyder att den ursprungliga tabellen inte är låst, och klienter kan fortsätta att läsa och ändra data i den.
På samma sätt, om en rad ändras eller tas bort i den gamla tabellen, tillämpas den också i den nya tabellen. Sedan börjar en bakgrundsprocess för att kopiera data (med LOW_PRIORITY INSERT) mellan gammal och ny tabell. När data har kopierats exekveras RENAME TABLE.
Ett annat intressant verktyg är gh-ost. Gh-ost skapar en tillfällig tabell med det ändrade schemat, precis som pt-online-schema-change gör. Den kör INSERT-frågor, som använder följande mönster för att kopiera data från gammal till ny tabell. Ändå använder den inte triggers. Tyvärr kan triggers vara källan till många begränsningar. gh-ost använder den binära loggströmmen för att fånga tabelländringar och applicerar dem asynkront på spöktabellen. När vi väl har verifierat att gh-ost kan utföra vår schemaändring korrekt, är det dags att faktiskt köra det. Tänk på att du kan behöva manuellt släppa gamla tabeller som skapades av gh-ost under processen att testa migreringen. Du kan också använda flaggorna --initially-drop-ghost-table och --initially-drop-old-table för att be gh-ost att göra det åt dig. Det sista kommandot att köra är exakt detsamma som vi använde för att testa vår ändring, vi lade bara till --execute till den.
pt-online-schema-change och gh-ost är mycket populära bland Galera-användare. Galera har dock några ytterligare alternativ. De två metoderna Total Order Isolation (TOI) och Rolling Schema Upgrade (RSU) har både sina för- och nackdelar.
TOI - Detta är standard DDL-replikeringsmetoden. Noden som skapar skrivuppsättningen upptäcker DDL vid analystidpunkten och skickar ut en replikeringshändelse för SQL-satsen innan DDL-bearbetningen ens påbörjas. Schemauppgraderingar körs på alla klusternoder i samma totala ordersekvens, vilket förhindrar att andra transaktioner genomförs under operationens varaktighet. Den här metoden är bra när du vill att dina onlineschemauppgraderingar ska replikera genom klustret och inte har något emot att låsa hela tabellen (liknande hur standardschemaändringar skedde i MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU - utför schemauppgraderingarna lokalt. I den här metoden påverkar dina skrivningar endast noden där de körs. Ändringarna replikerar inte till resten av klustret. Den här metoden är bra för icke-konfliktoperationer och den kommer inte att sakta ner klustret.
SET GLOBAL wsrep_OSU_method='RSU';Medan noden bearbetar schemauppgraderingen avsynkroniseras den med klustret. När den är klar med bearbetningen av schemauppgraderingen tillämpar den fördröjda replikeringshändelser och synkroniserar sig själv med klustret. Detta kan vara ett bra alternativ för att köra tunga indexskapelser.
Slutsats
Vi presenterade här flera olika metoder som kan hjälpa dig att planera dina schemaändringar. Det beror naturligtvis på din applikation och affärskrav. Du kan utforma din förändringsplan, utföra nödvändiga tester, men det finns fortfarande en liten chans att något går fel. Enligt Murphys lag - "kommer saker att gå fel i varje given situation, om du ger dem en chans". Så se till att du provar olika sätt att utföra dessa ändringar och välj det som du är mest bekväm med.