Vi får lite trevlig feedback angående vår produkt ClusterControl, speciellt hur lätt det är att installera och komma igång. Att installera ny programvara är en sak, men att använda den på rätt sätt är en annan.
Det är inte ovanligt att man är otålig på att testa ny programvara och man leker hellre med en ny spännande applikation än att läsa dokumentation innan man sätter igång. Det är lite olyckligt eftersom du kan missa viktiga funktioner eller missförstå hur du använder dem.
Den här bloggserien täcker alla grundläggande funktioner för ClusterControl för MySQL, MongoDB &PostgreSQL med exempel på hur du får ut det mesta av din installation. Den ger dig en djupdykning i olika ämnen för att spara tid.
Dessa är de ämnen som tas upp i den här serien:
- Distribuera de första klustren
- Lägga till din befintliga infrastruktur
- Prestanda och hälsoövervakning
- Gör dina komponenter till HA
- Arbetsflödeshantering
- Skydda dina data
- Skydda din data
- Ingående användningsfall
I dagens inlägg kommer vi att täcka installationen av ClusterControl och distribuera dina första kluster.
Förberedelser
I den här serien kommer vi att använda en uppsättning Vagrant-lådor men du kan använda din egen infrastruktur om du vill. Om du vill testa det med Vagrant, gjorde vi en exempelinställning tillgänglig från följande Github-förråd:https://github.com/severalnines/vagrant
Klona repet till din egen maskin:
$ git clone example@sqldat.com:severalnines/vagrant.gitTopologin för vagrantnoderna är som följer:
- vm1:klusterkontroll
- vm2:databasnod1
- vm3:databasnod2
- vm4:databasnod3
Du kan enkelt lägga till ytterligare noder om du vill genom att ändra följande rad:
4.times do |n|Vagrant-filen är konfigurerad för att automatiskt installera ClusterControl på den första noden och vidarebefordra användargränssnittet för ClusterControl till port 8080 på din värd som kör Vagrant. Så om din värds IP-adress är 192.168.1.10 hittar du ClusterControl UI här:https://192.168.1.10:8080/clustercontrol/
Installera ClusterControl
Du kan hoppa över detta om du väljer att använda Vagrant-filen och få den automatiska installationen. Men installationen av ClusterControl är enkel och tar mindre än fem minuter.
Med paketinstallationen är allt du behöver göra att utfärda följande tre kommandon på ClusterControl-noden för att få den installerad:
$ wget https://www.severalnines.com/downloads/cmon/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userDet är det:det kan inte bli enklare än så här. Om installationsskriptet inte har stött på några problem bör ClusterControl vara installerat och igång. Du kan nu logga in på ClusterControl på följande URL:https://192.168.1.210/clustercontrol
När du har skapat ett administratörskonto och loggat in kommer du att uppmanas att lägga till ditt första kluster.
Distribuera ett Galera-kluster
Du kommer att uppmanas att skapa en ny databasserver/-kluster eller importera en befintlig (d.v.s. redan distribuerad) server eller kluster:
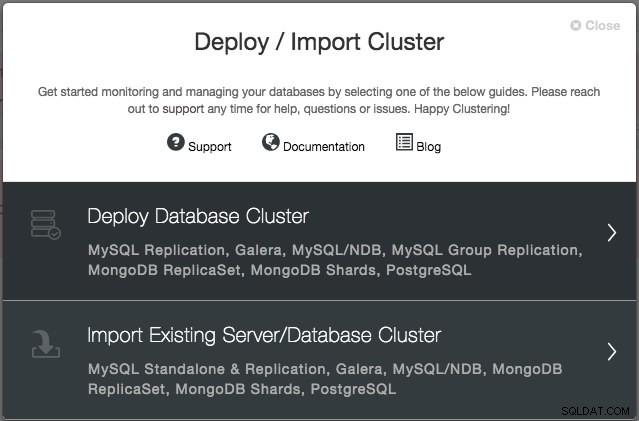
Vi kommer att distribuera ett Galera-kluster. Det finns två avsnitt som måste fyllas i. Den första fliken är relaterad till SSH och allmänna inställningar:
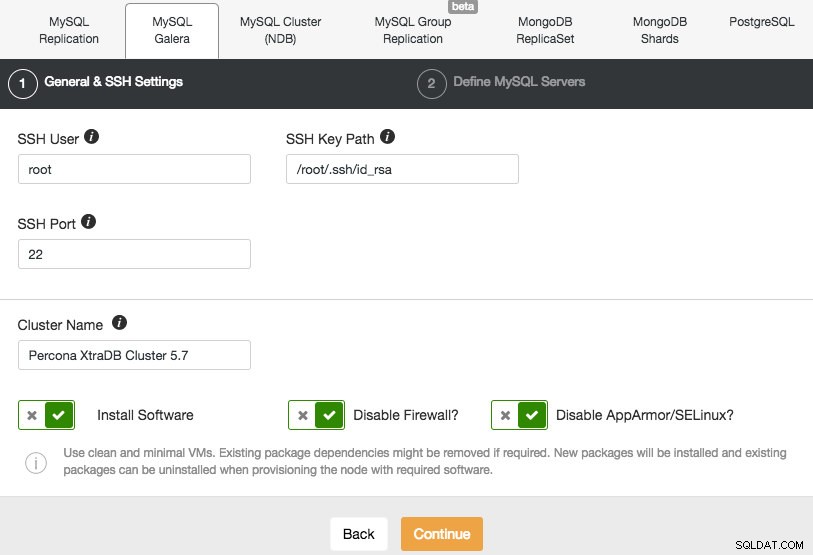
För att tillåta ClusterControl att installera Galera-noderna använder vi root-användaren som fick SSH-åtkomst av Vagrant-bootstrap-skripten. Om du väljer att använda din egen infrastruktur måste du ange en användare här som får göra lösenordslös SSH till de noder som ClusterControl kommer att kontrollera. Tänk bara på att du måste ställa in lösenordslös SSH från ClusterControl till alla databasnoder själv i förväg.
Se också till att du inaktiverar AppArmor/SELinux. Se varför.
Fortsätt sedan till det andra steget och ange den databasrelaterade informationen och målvärdarna:
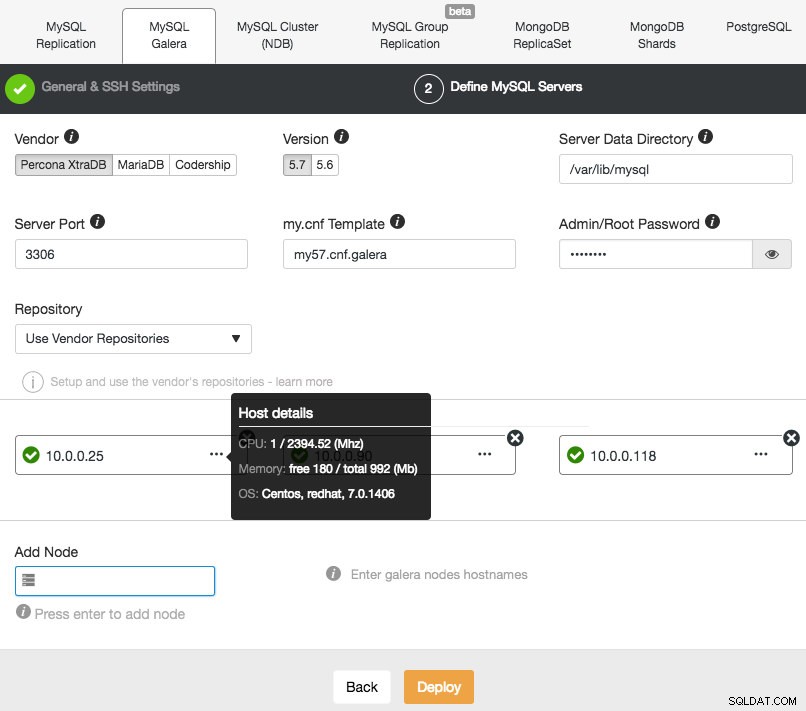
ClusterControl kommer omedelbart att utföra vissa förnuftskontroller varje gång du trycker på Enter när du lägger till en nod. Du kan se värdsammanfattningen genom att hålla muspekaren över varje definierad nod. När allt är grönt betyder det att ClusterControl har anslutning till alla noder, du kan klicka på Deploy. Ett jobb kommer att skapas för att bygga det nya klustret. Det fina är att du kan hålla reda på det här jobbets framsteg genom att klicka på Aktivitet -> Jobb -> Skapa kluster -> Fullständiga jobbdetaljer :
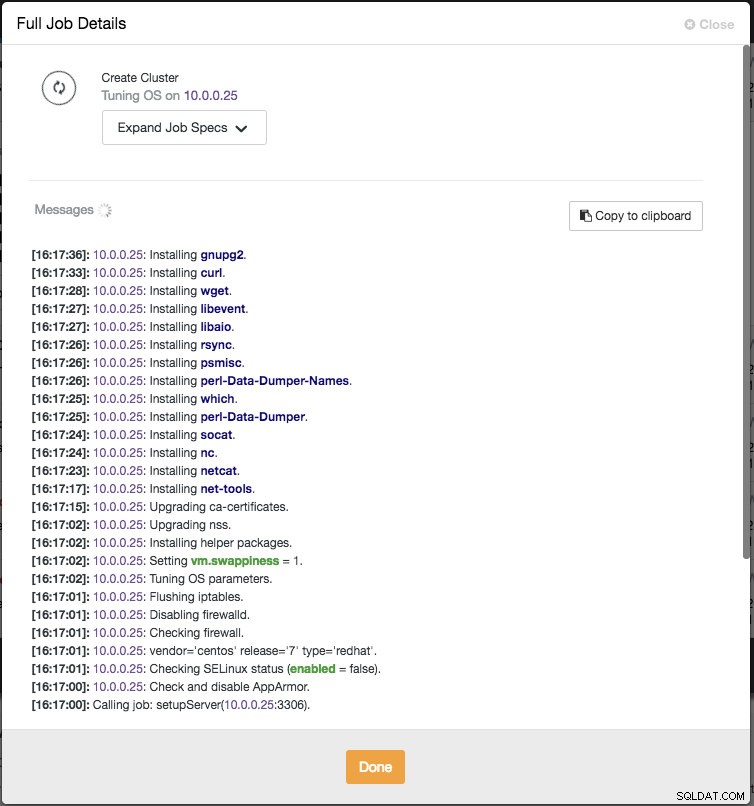
När jobbet är klart har du precis skapat ditt första kluster. Klusteröversikten ska se ut så här:
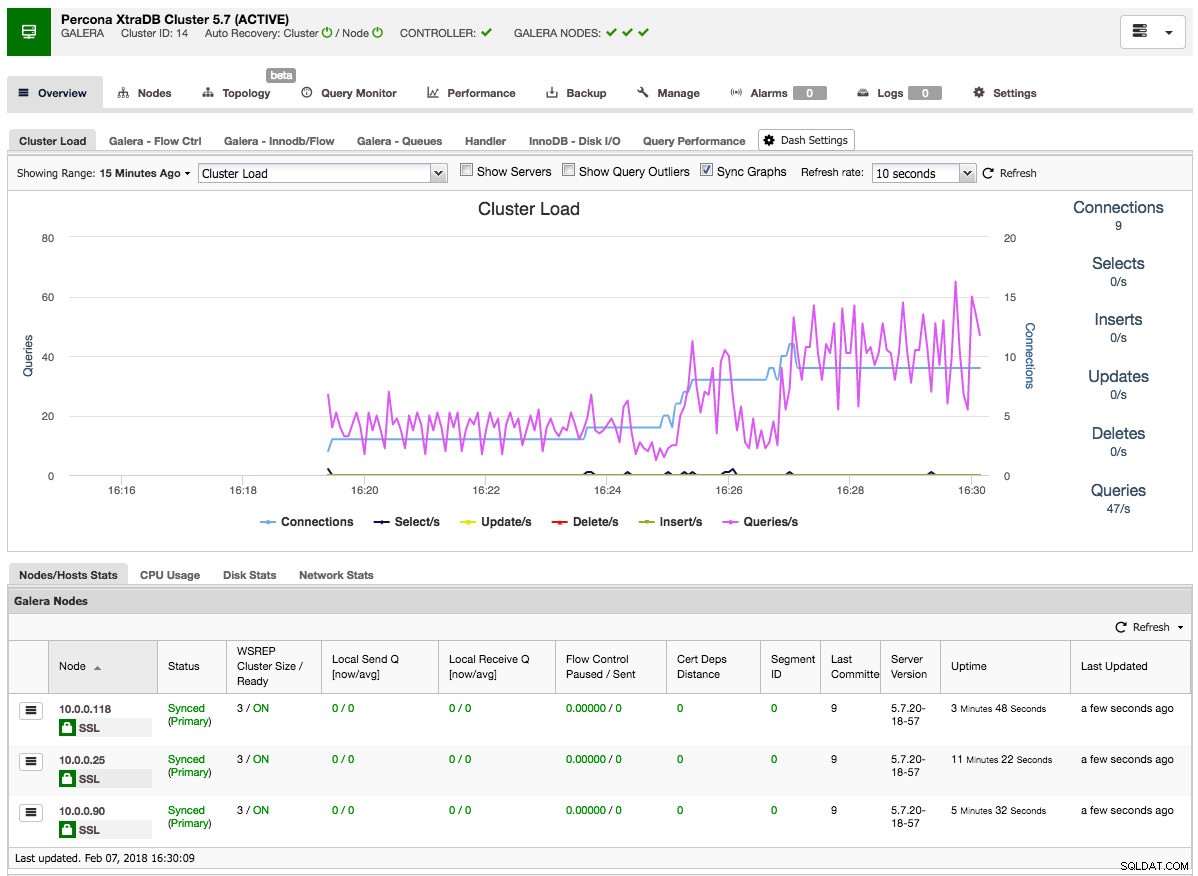
På nodfliken kan du göra ungefär vilken operation du normalt skulle göra på ett kluster. Frågemonitorn ger dig en bra översikt över både pågående och vanliga frågor. Prestandafliken hjälper dig att hålla ett öga på prestandan för ditt kluster och innehåller även rådgivare som hjälper dig att agera proaktivt på trender i data. Fliken Säkerhetskopiering gör att du enkelt kan schemalägga säkerhetskopior och lagra dem på lokal eller molnlagring. Hantera-fliken låter dig utöka ditt kluster eller göra det mycket tillgängligt för dina applikationer genom en lastbalanserare.
All denna funktion kommer att behandlas i senare blogginlägg i den här serien.
Distribuera ett MySQL-replikeringskluster
Att distribuera en MySQL-replikeringsinställning liknar Galera-databasinstallationen, förutom att den har en extra flik i distributionsdialogrutan där du kan definiera replikeringstopologin:
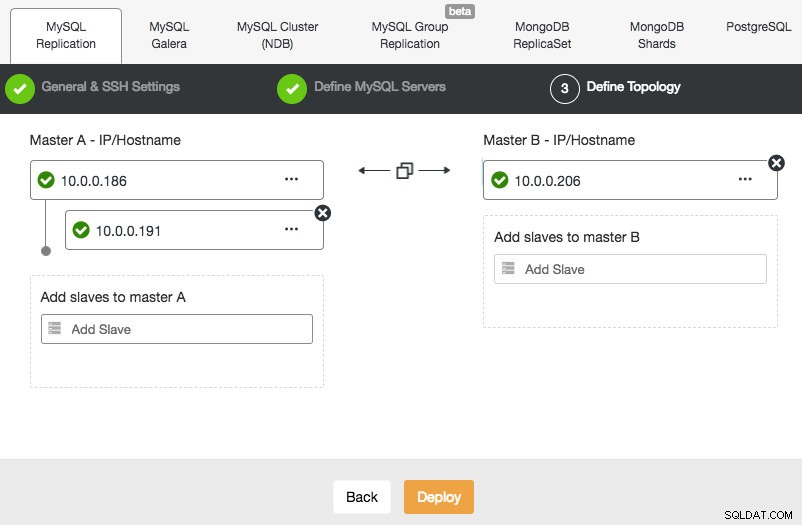
Du kan ställa in standard master-slave replikering, såväl som master-master replikering. I fallet med det senare kommer endast en master att vara skrivbar åt gången. Tänk på att master-master-replikering inte kommer med konfliktlösning och garanterad datakonsistens, som i fallet med Galera. Använd denna inställning med försiktighet, eller titta på Galera-klustret. När allt är grönt och du har klickat på Deploy, kommer ett jobb att skapas för att bygga det nya klustret.
Återigen, distributionsförloppet är tillgängligt under Aktivitet -> Jobb.
För att skala ut slaven (läs kopia), använd helt enkelt alternativet "Lägg till nod" i klusterlistan:
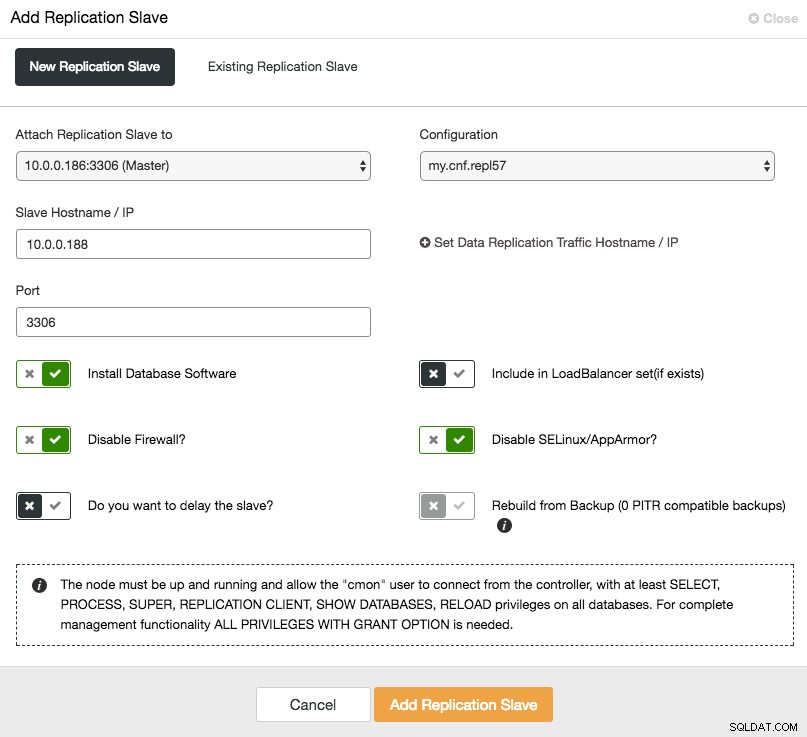
Efter att ha lagt till slavnoden kommer ClusterControl att förse slaven med en kopia av data från sin master med Xtrabackup eller från befintliga PITR-kompatibla säkerhetskopior för det klustret.
Distribuera PostgreSQL-replikering
ClusterControl stöder distributionen av PostgreSQL version 9.x och högre. Stegen liknar MySQL-replikering, där du i slutet av installationssteget kan definiera databastopologin när du lägger till noderna:
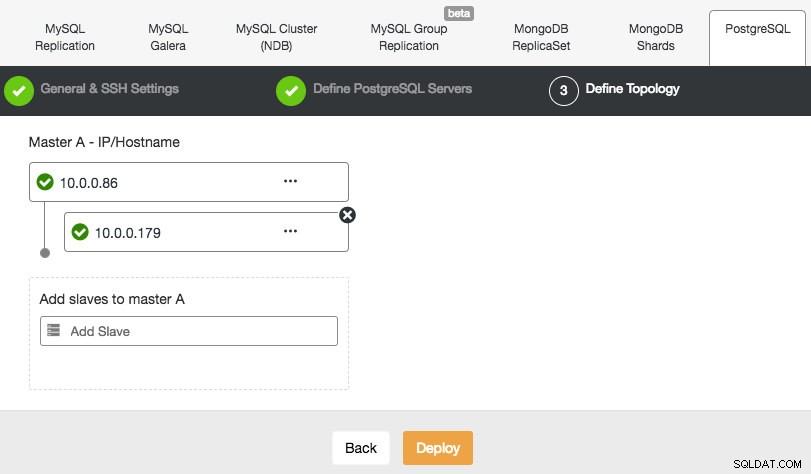
I likhet med MySQL-replikering kan du skala ut när distributionen är klar genom att lägga till replikeringsslav till klustret. Steget är så enkelt som att välja master och fylla i FQDN för den nya slaven:
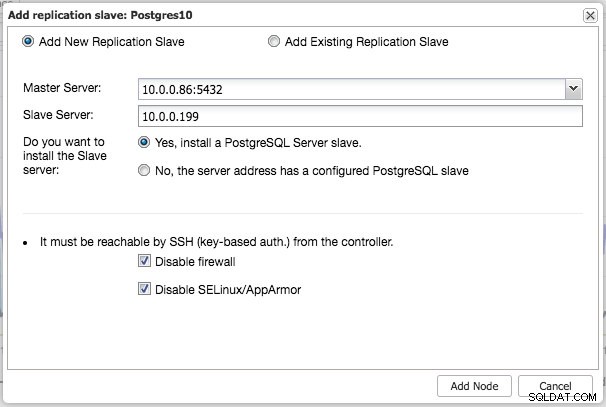
ClusterControl kommer sedan att utföra nödvändig datainställning från den valda mastern med hjälp av pg_basebackup, konfigurera replikeringsanvändaren och aktivera strömmande replikering. PostgreSQL-klusteröversikten ger dig lite insikt i din installation:
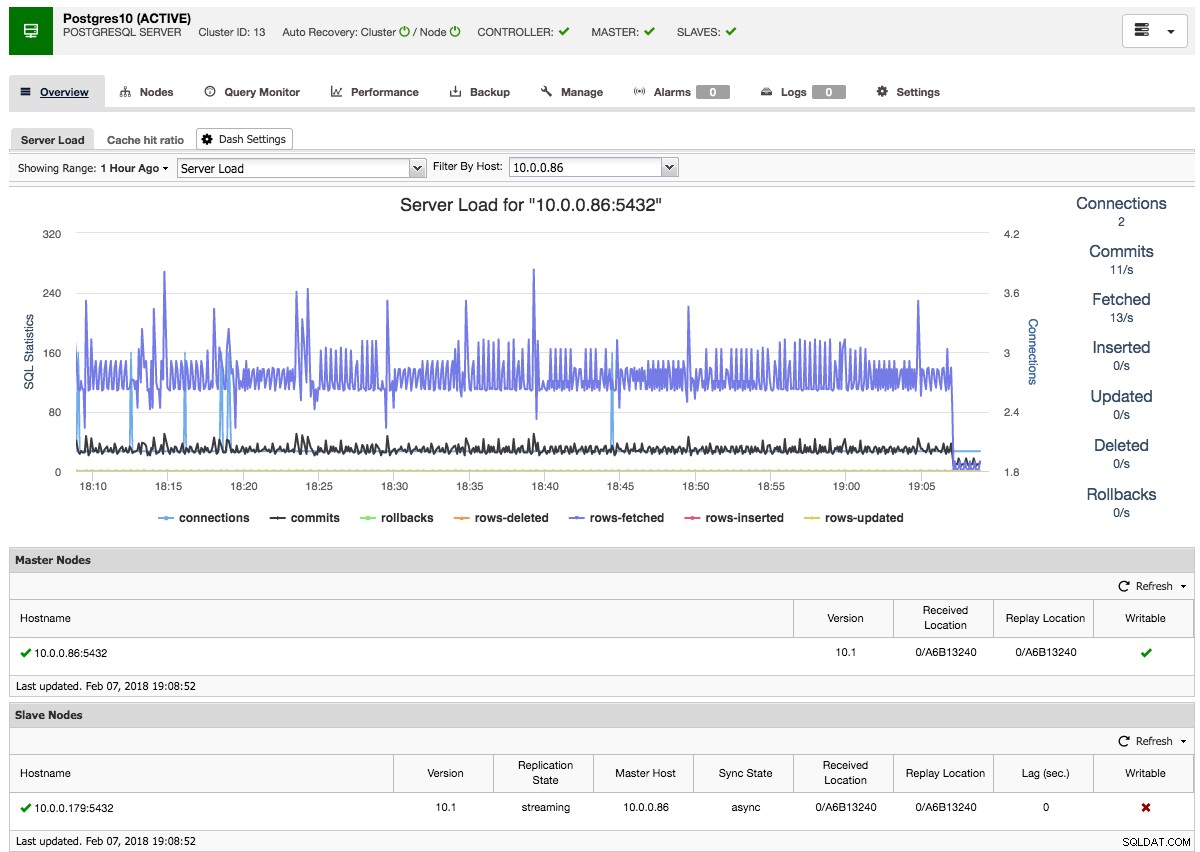
Precis som med Galera- och MySQL-klusteröversikterna kan du hitta alla nödvändiga flikar och funktioner här:frågeövervakaren, prestanda, säkerhetskopieringsflikarna gör att du kan utföra de nödvändiga operationerna.
Distribuera en MongoDB Replica Set
Att distribuera en ny MongoDB Replica Set liknar de andra klustren. I dialogrutan Distribuera databaskluster väljer du MongoDB ReplicatSet, definierar de föredragna databasalternativen och lägger till databasnoderna:
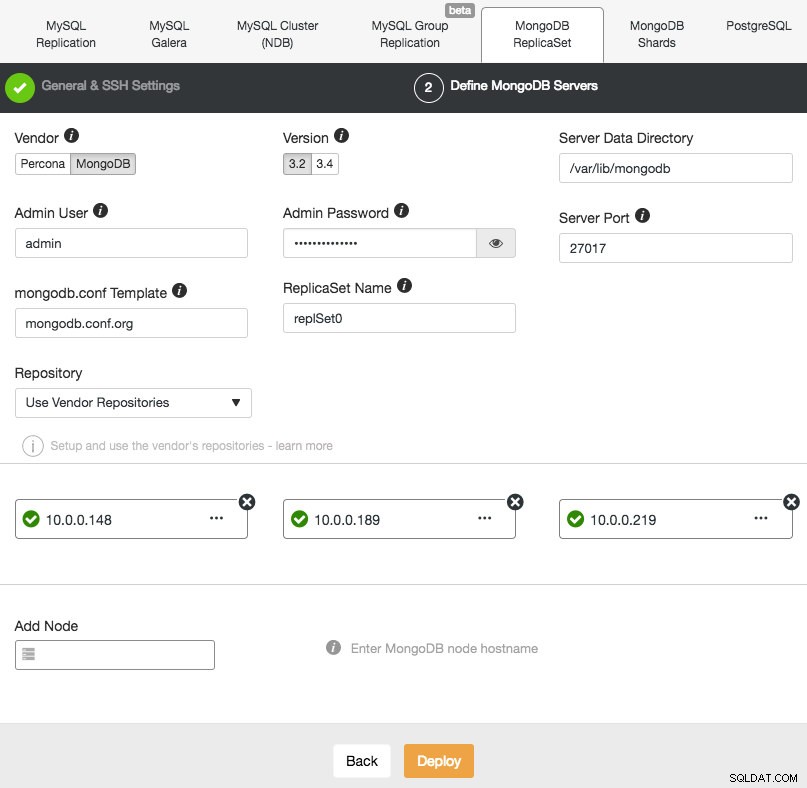
Du kan antingen välja att installera Percona Server för MongoDB från Percona eller MongoDB Server från MongoDB, Inc (tidigare 10gen). Du måste också ange MongoDB adminanvändare och lösenord eftersom ClusterControl som standard kommer att distribuera ett MongoDB-kluster med autentisering aktiverad.
Efter att ha installerat klustret kan du lägga till ytterligare en slav- eller arbiternod i replikuppsättningen med hjälp av menyn "Lägg till nod" under samma rullgardinsmeny från klusteröversikten:
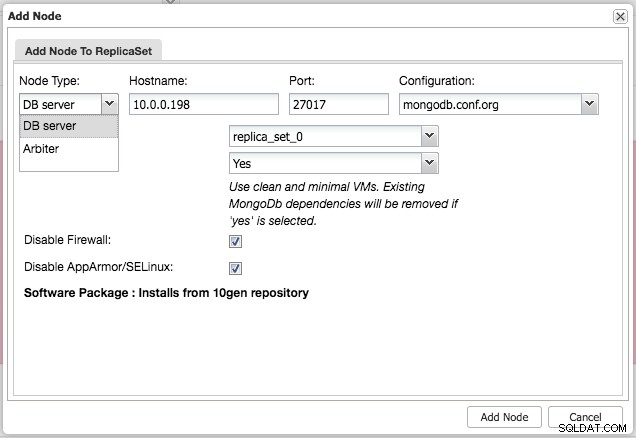
Efter att ha lagt till slaven eller arbitern till replikuppsättningen kommer ett jobb att skapas. När det här jobbet är klart kommer det att ta en kort stund innan MongoDB lägger till det i klustret och det blir synligt i klusteröversikten:
Sluta tankar
Med dessa tre exempel har vi visat dig hur enkelt det är att sätta upp olika kluster från början på bara ett par minuter. Det fina med att använda denna Vagrant-installation är att du, lika enkelt som att skapa denna miljö, också kan ta ner den och sedan spawna igen. Imponera på dina kollegor genom att visa hur snabbt du kan skapa en arbetsmiljö.
Naturligtvis skulle det vara lika intressant att lägga till befintliga värdar och redan distribuerade kluster i ClusterControl, och det är vad vi kommer att ta upp nästa gång.