I det här blogginlägget kommer vi att analysera 6 olika felscenarier i produktionsdatabassystem, allt från problem med en servrar till planer för failover för flera datacenter. Vi kommer att leda dig genom återställnings- och failover-procedurer för respektive scenario. Förhoppningsvis kommer detta att ge dig en god förståelse för de risker du kan möta och saker att tänka på när du utformar din infrastruktur.
Databasschema skadat
Låt oss börja med installation av en enda nod - en databasinstallation i den enklaste formen. Lätt att implementera, till lägsta kostnad. I det här scenariot kör du flera applikationer på den enda servern där vart och ett av databasschemana tillhör det olika programmet. Tillvägagångssättet för återställning av ett enda schema skulle bero på flera faktorer.
- Har jag någon säkerhetskopia?
- Har jag en säkerhetskopia och hur snabbt kan jag återställa den?
- Vilken typ av lagringsmotor används?
- Har jag en PITR-kompatibel (point in time recovery) säkerhetskopia?
Datakorruption kan identifieras av mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Ersätt DATABASE med namnet på databasen och ersätt TABLE med namnet på tabellen som du vill kontrollera:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck kontrollerar den angivna databasen och tabellerna. Om en tabell klarar kontrollen visar mysqlcheck OK för tabellen. I exemplet nedan kan vi se att tabellen löner kräver återställning.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKFör en enda nodinstallation utan ytterligare DR-servrar skulle det primära tillvägagångssättet vara att återställa data från backup. Men detta är inte det enda du behöver tänka på. Att ha flera databasscheman under samma instans orsakar ett problem när du måste ta ner din server för att återställa data. En annan fråga är om du har råd att återställa alla dina databaser till den senaste säkerhetskopian. I de flesta fall skulle det inte vara möjligt.
Det finns några undantag här. Det är möjligt att återställa en enstaka tabell eller databas från den senaste säkerhetskopian när tidpunktsåterställning inte behövs. En sådan process är mer komplicerad. Om du har mysqldump kan du extrahera din databas från den. Om du kör binära säkerhetskopior med xtradbackup eller mariabackup och du har aktiverat tabell per fil, så är det möjligt.
Så här kontrollerar du om du har ett alternativ för tabell per fil aktiverat.
mysql> SET GLOBAL innodb_file_per_table=1; Med innodb_file_per_table aktiverat kan du lagra InnoDB-tabeller i en tbl_name .ibd-fil. Till skillnad från MyISAM-lagringsmotorn, med sina separata tbl_name .MYD- och tbl_name .MYI-filer för index och data, lagrar InnoDB datan och indexen tillsammans i en enda .ibd-fil. För att kontrollera din lagringsmotor måste du köra:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';eller direkt från konsolen:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: För att återställa tabeller från xtradbackup måste du gå igenom en exportprocess. Säkerhetskopiering måste förberedas innan den kan återställas. Exporten sker i förberedelsestadiet. När en fullständig säkerhetskopia har skapats, kör standardförberedelseproceduren med den extra flaggan --export :
innobackupex --apply-log --export /u01/backupDetta kommer att skapa ytterligare exportfiler som du kommer att använda senare i importfasen. För att importera en tabell till en annan server, skapa först en ny tabell med samma struktur som den som kommer att importeras till den servern:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;kassera tabellutrymmet:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Kopiera sedan filerna mytable.ibd och mytable.exp till databasens hem och importera dess tabellutrymme:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Men för att göra detta på ett mer kontrollerat sätt skulle rekommendationen vara att återställa en databasbackup i en annan instans/server och kopiera det som behövs tillbaka till huvudsystemet. För att göra det måste du köra installationen av mysql-instansen. Detta kan göras antingen på samma maskin - men kräver mer ansträngning att konfigurera på ett sätt som båda instanserna kan köras på samma maskin - till exempel skulle det kräva olika kommunikationsinställningar.
Du kan kombinera både uppgiftsåterställning och installation med ClusterControl.
ClusterControl leder dig genom tillgängliga säkerhetskopior på plats eller i molnet, låter dig välja exakt tid för en återställning eller exakt loggposition och installera en ny databasinstans om det behövs.
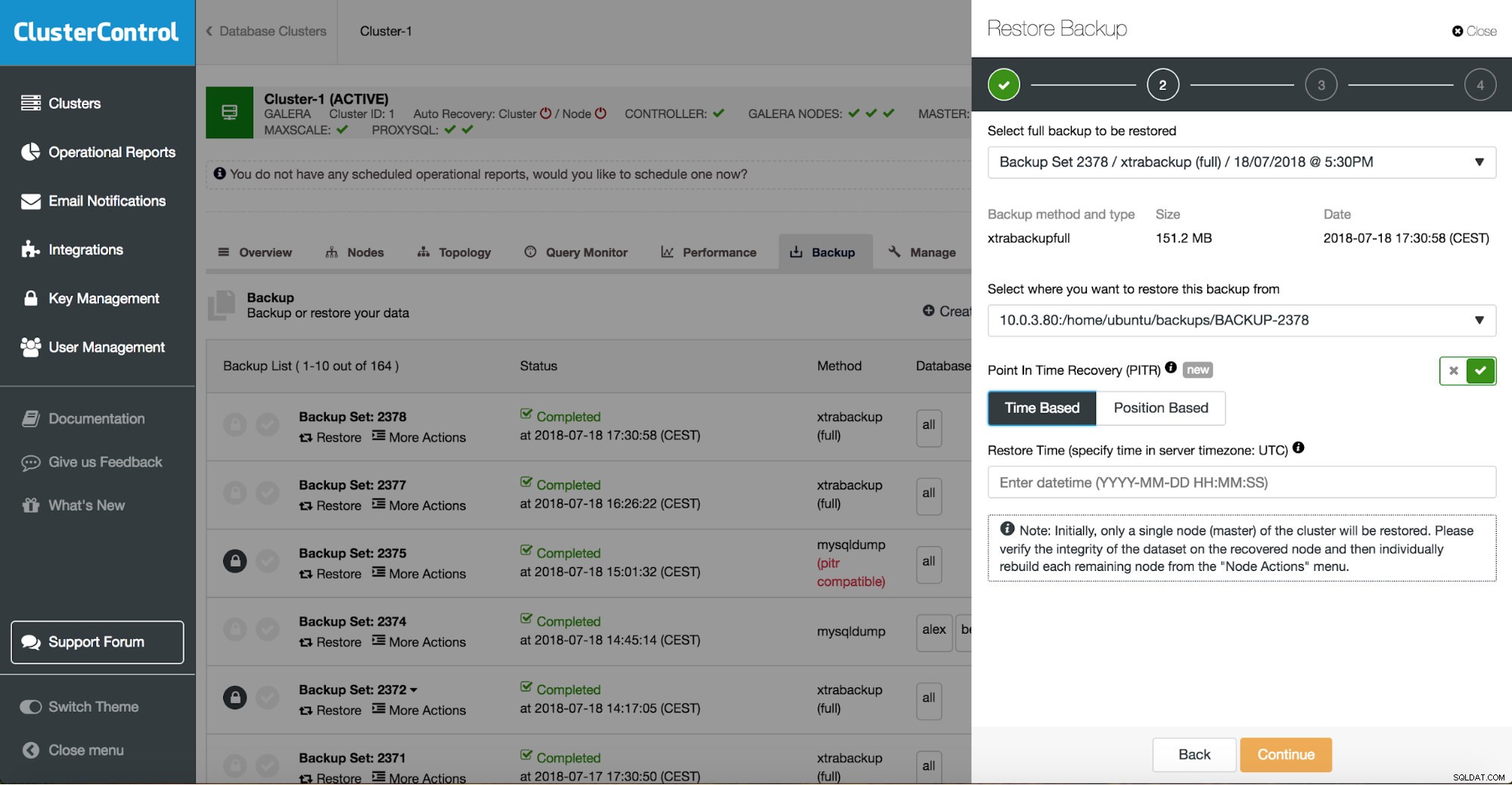 ClusterControl tidpunktsåterställning
ClusterControl tidpunktsåterställning 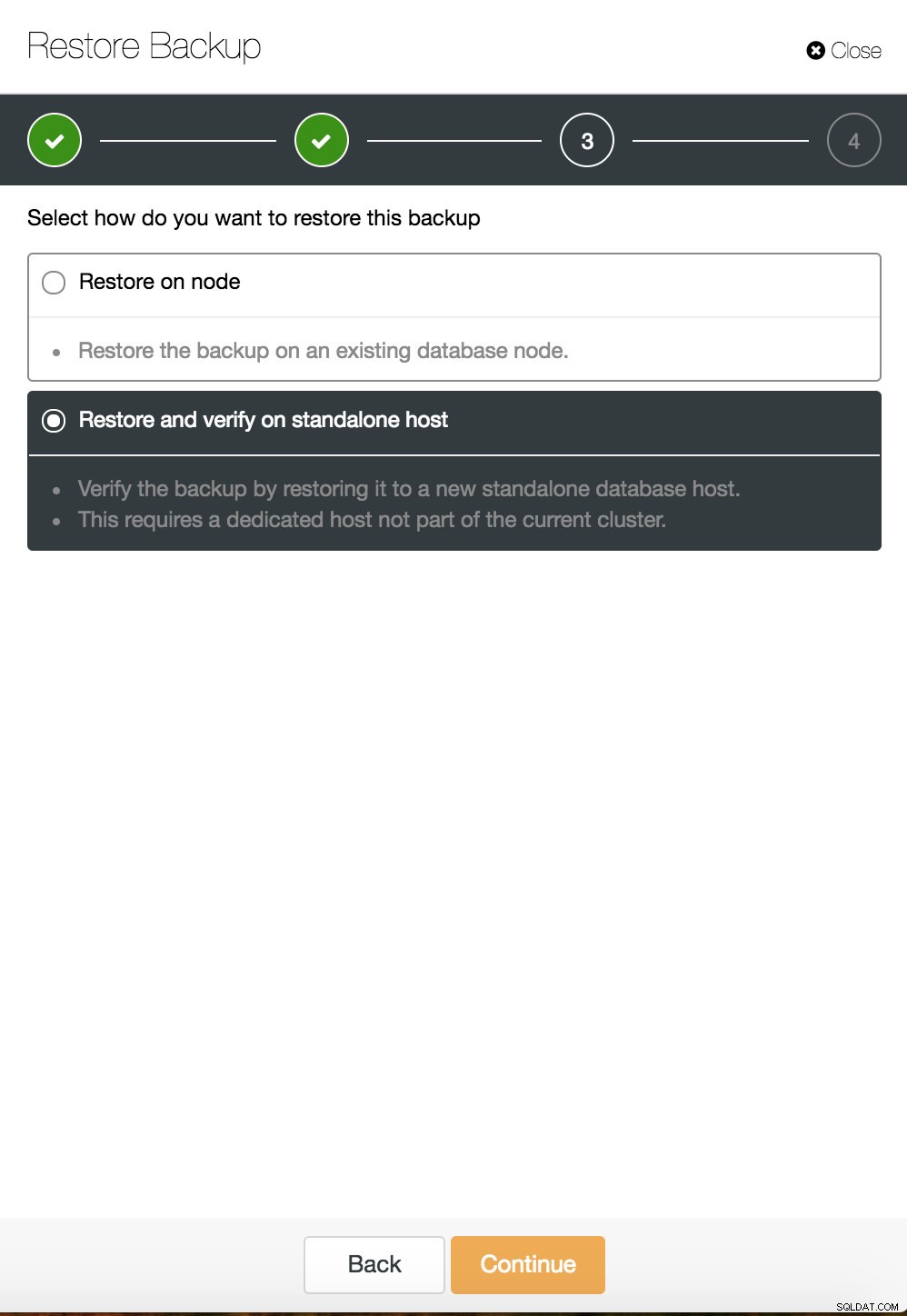 ClusterControl återställer och verifierar på en fristående värd
ClusterControl återställer och verifierar på en fristående värd 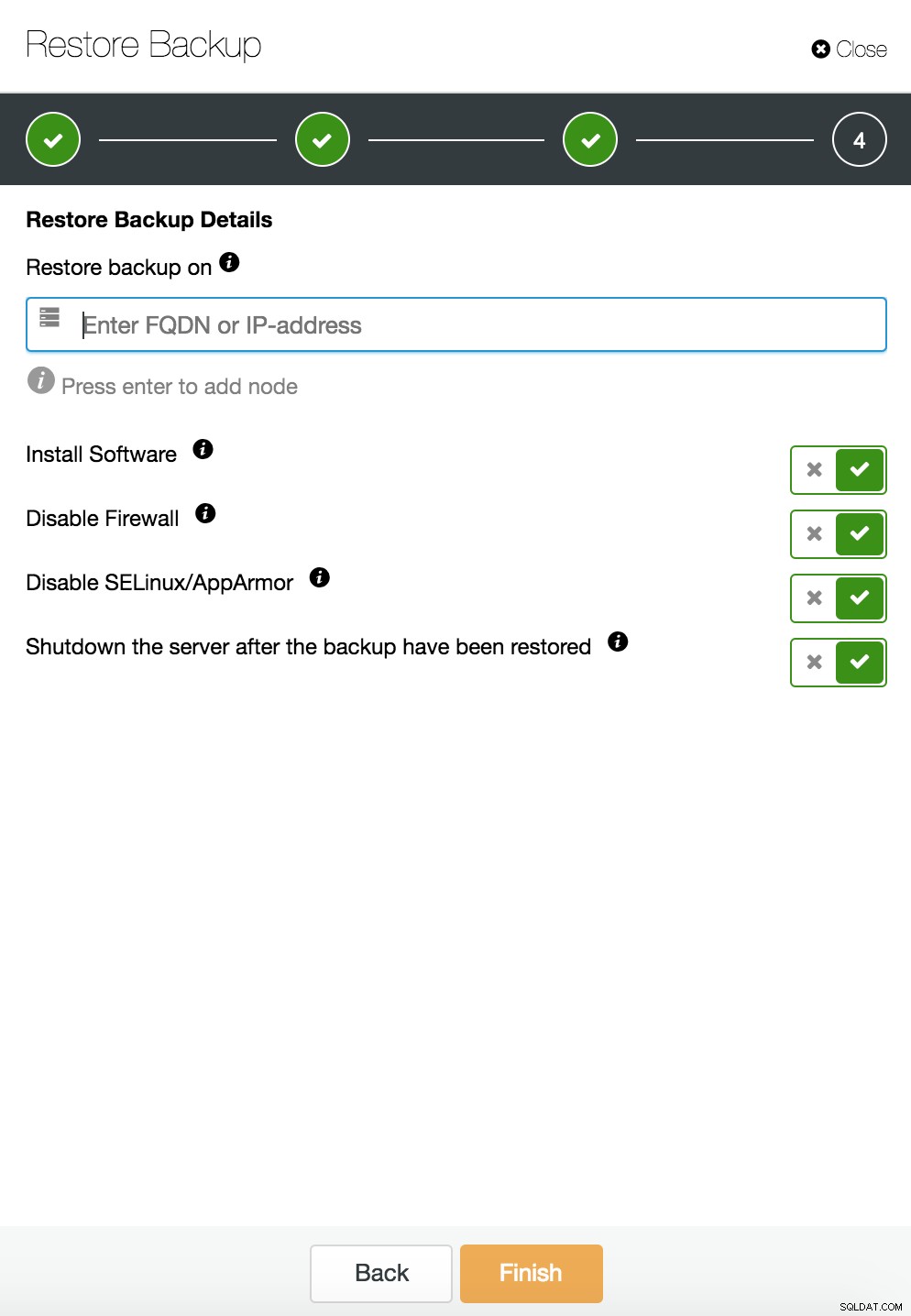 CusterControl återställer och verifierar på en fristående värd. Installationsalternativ.
CusterControl återställer och verifierar på en fristående värd. Installationsalternativ. Du kan hitta mer information om dataåterställning i bloggen Min MySQL-databas är skadad... Vad gör jag nu?
Databasinstans skadad på den dedikerade servern
Defekter i den underliggande plattformen är ofta orsaken till databaskorruption. Din MySQL-instans förlitar sig på ett antal saker för att lagra och hämta data - diskundersystem, kontroller, kommunikationskanaler, drivrutiner och firmware. En krasch kan påverka delar av din data, mysql-binärfiler eller till och med säkerhetskopieringsfiler som du lagrar på systemet. För att separera olika applikationer kan du placera dem på dedikerade servrar.
Olika applikationsscheman på separata system är en bra idé om du har råd med dem. Man kan säga att detta är ett slöseri med resurser, men det finns en chans att affärseffekten blir mindre om bara en av dem går ner. Men även då måste du skydda din databas från dataförlust. Att lagra backup på samma server är ingen dålig idé så länge du har en kopia någon annanstans. Idag är molnlagring ett utmärkt alternativ till bandbackup.
ClusterControl gör att du kan behålla en kopia av din säkerhetskopia i molnet. Den stöder uppladdning till de tre främsta molnleverantörerna - Amazon AWS, Google Cloud och Microsoft Azure.
När du har återställt din fullständiga säkerhetskopia kanske du vill återställa den till en viss tidpunkt. Point-in-time återställning kommer att uppdatera servern till en senare tidpunkt än när den fullständiga säkerhetskopian togs. För att göra det måste du ha dina binära loggar aktiverade. Du kan kontrollera tillgängliga binära loggar med:
mysql> SHOW BINARY LOGS;Och aktuell loggfil med:
SHOW MASTER STATUS;Sedan kan du fånga inkrementell data genom att skicka binära loggar till sql-filen. Saknade operationer kan sedan utföras igen.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outDetsamma kan göras i ClusterControl.
 ClusterControl molnsäkerhetskopiering
ClusterControl molnsäkerhetskopiering 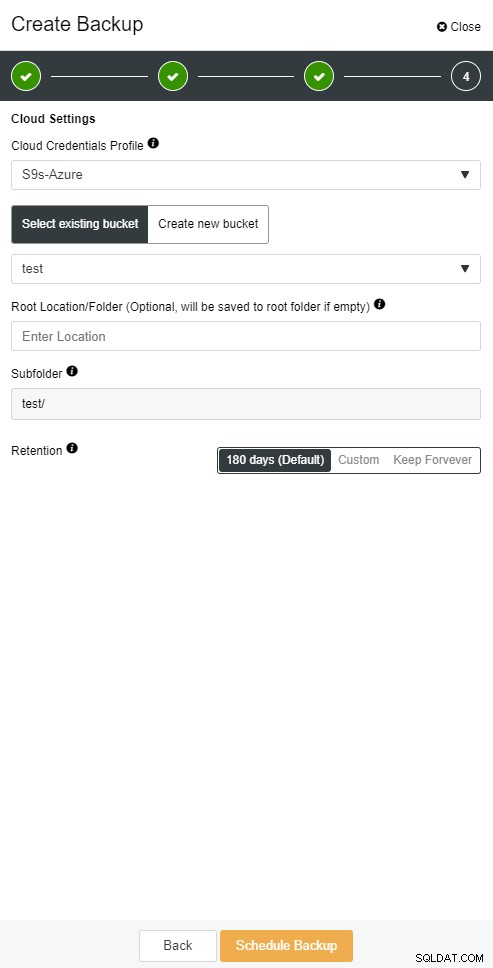 ClusterControl molnsäkerhetskopiering
ClusterControl molnsäkerhetskopiering Databasslav går ner
Ok, så du har din databas som körs på en dedikerad server. Du skapade ett sofistikerat säkerhetskopieringsschema med en kombination av fullständiga och inkrementella säkerhetskopior, ladda upp dem till molnet och lagra den senaste säkerhetskopian på lokala diskar för snabb återställning. Du har olika lagringspolicyer för säkerhetskopiering – kortare för säkerhetskopior som lagras på lokala diskdrivrutiner och utökade för dina molnsäkerhetskopior.
Det låter som att du är väl förberedd för ett katastrofscenario. Men när det kommer till återställningstiden kanske det inte tillfredsställer ditt företags behov.
Du behöver en snabb failover-funktion. En server som kommer att vara igång och tillämpa binära loggar från mastern där skrivning sker. Master/Slav-replikering startar ett nytt kapitel i failover-scenariot. Det är en snabb metod att återuppliva din applikation om du behärskar går ner.
Men det finns få saker att tänka på i failover-scenariot. Den ena är att ställa in en fördröjd replikeringsslav, så att du kan reagera på feta fingerkommandon som utlöstes på masterservern. En slavserver kan släpa efter mastern med åtminstone en viss tid. Standardfördröjningen är 0 sekunder. Använd alternativet MASTER_DELAY för CHANGE MASTER TO för att ställa in fördröjningen till N sekunder:
CHANGE MASTER TO MASTER_DELAY = N;Det andra är att aktivera automatisk failover. Det finns många automatiserade failover-lösningar på marknaden. Du kan ställa in automatisk failover med kommandoradsverktyg som MHA, MRM, mysqlfailover eller GUI Orchestrator och ClusterControl. När det är korrekt konfigurerat kan det minska ditt avbrott avsevärt.
ClusterControl stöder automatisk failover för MySQL-, PostgreSQL- och MongoDB-replikationer samt multi-master klusterlösningar Galera och NDB.
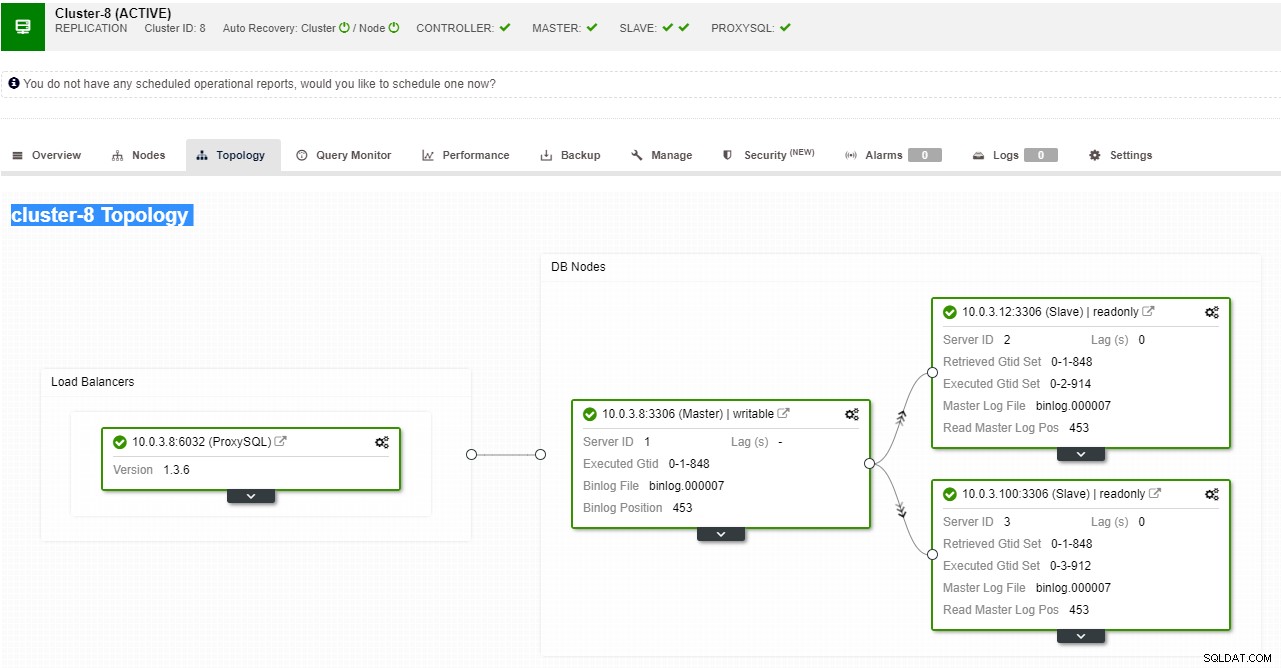 ClusterControl replikeringstopologivy
ClusterControl replikeringstopologivy När en slavnod kraschar och servern släpar efter kraftigt, kanske du vill bygga om din slavserver. Slavåteruppbyggnadsprocessen liknar återställning från säkerhetskopia.
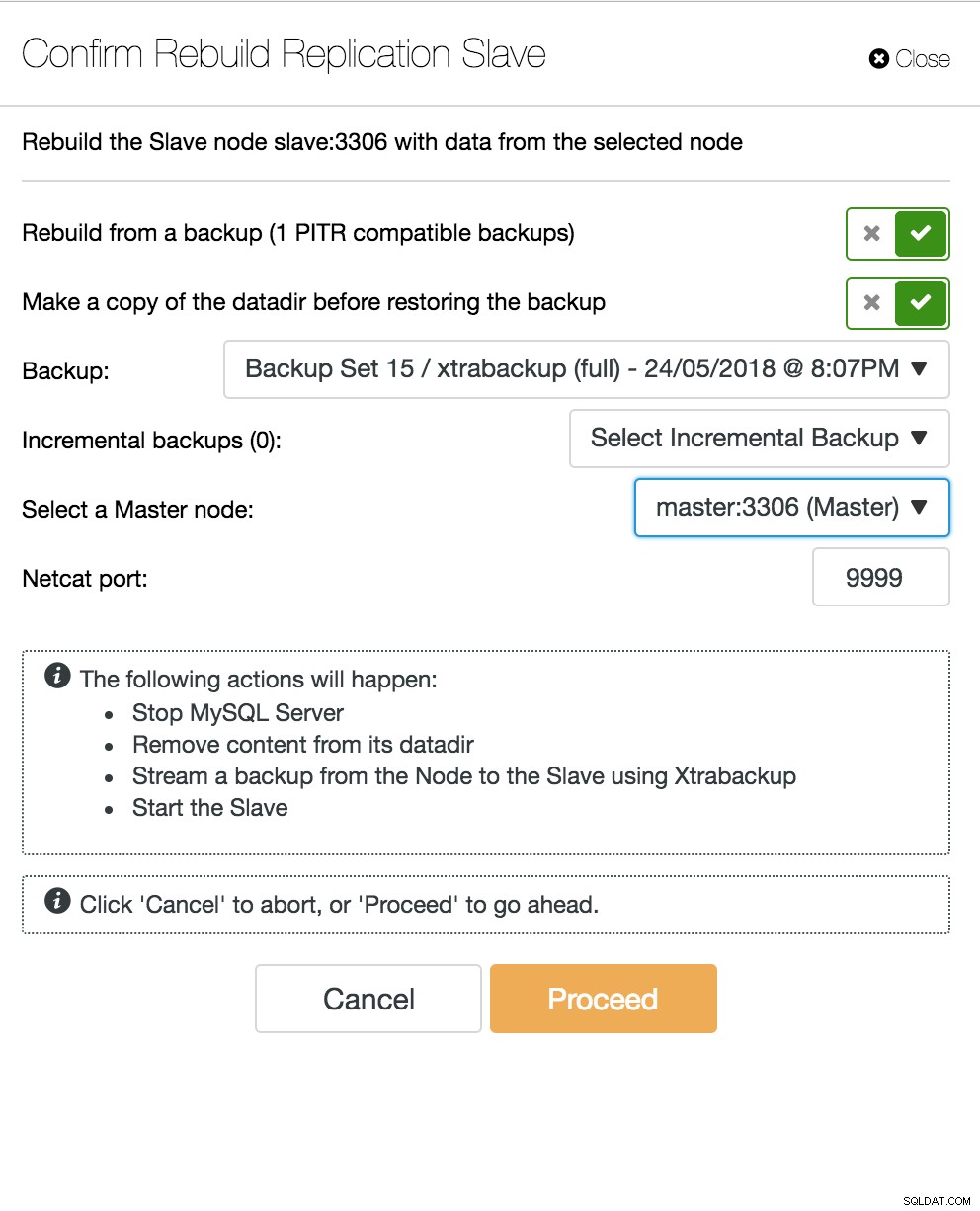 ClusterControl återuppbygga slav
ClusterControl återuppbygga slav Databas Multi-Master Server går ner
Nu när du har en slavserver som fungerar som en DR-nod, och din failover-process är väl automatiserad och testad, blir ditt DBA-liv bekvämare. Det är sant, men det finns några fler pussel att lösa. Datorkraft är inte gratis, och ditt företagsteam kan be dig att bättre använda din hårdvara, du kanske vill använda din slavserver inte bara som passiv server, utan också för att tjäna skrivoperationer.
Du kanske sedan vill undersöka en multi-master replikeringslösning. Galera Cluster har blivit ett vanligt alternativ för MySQL och MariaDB med hög tillgänglighet. Och även om det nu är känt som en trovärdig ersättning för traditionella MySQL master-slave-arkitekturer, är det inte en drop-in ersättare.
Galera-klustret har en delad ingenting-arkitektur. Istället för delade diskar använder Galera certifieringsbaserad replikering med gruppkommunikation och transaktionsbeställning för att uppnå synkron replikering. Ett databaskluster bör kunna överleva en förlust av en nod, även om det uppnås på olika sätt. När det gäller Galera är den kritiska aspekten antalet noder. Galera kräver ett kvorum för att fortsätta fungera. Ett kluster med tre noder kan överleva kraschen av en nod. Med fler noder i ditt kluster kan du överleva fler misslyckanden.
Återställningsprocessen är automatiserad så du behöver inte utföra några failover-operationer. Men den goda praxis skulle vara att döda noder och se hur snabbt du kan ta tillbaka dem. För att göra denna operation mer effektiv kan du ändra storleken på galeras cache. Om storleken på galeras cache inte är korrekt planerad, måste din nästa startnod ta en fullständig säkerhetskopia istället för att bara sakna skrivuppsättningar i cachen.
Failover-scenariot är enkelt som att starta instansen. Baserat på data i galera-cachen kommer startnoden att utföra SST (återställning från fullständig säkerhetskopia) eller IST (tillämpa saknade skrivuppsättningar). Detta är dock ofta kopplat till mänskligt ingripande. Om du vill automatisera hela failover-processen kan du använda ClusterControls autoåterställningsfunktion (nod- och klusternivå).
 ClusterControl kluster autoåterställning
ClusterControl kluster autoåterställning Uppskatta galera cachestorlek:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;För att göra failover mer konsekvent bör du aktivera gcache.recover=yes i mycnf. Detta alternativ kommer att återuppliva galera-cachen vid omstart. Detta innebär att noden kan fungera som en GIVARE och betjäna saknade skrivuppsättningar (underlättar IST istället för att använda SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Proxy SQL-noden går ner
Om du har en virtuell IP-installation behöver du bara peka din applikation till den virtuella IP-adressen och allt bör vara korrekt anslutningsmässigt. Det räcker inte att ha dina databasinstanser som sträcker sig över flera datacenter, du behöver fortfarande dina applikationer för att komma åt dem. Anta att du har skalat ut antalet lästa repliker, kanske du vill implementera virtuella IP-adresser för var och en av dessa lästa repliker också på grund av underhålls- eller tillgänglighetsskäl. Det kan bli en besvärlig pool av virtuella IP-adresser som du måste hantera. Om en av dessa lästa repliker kraschar måste du omtilldela den virtuella IP-adressen till den andra värden, annars kommer din applikation att ansluta till antingen en värd som är nere eller i värsta fall en eftersläpande server med inaktuella data.
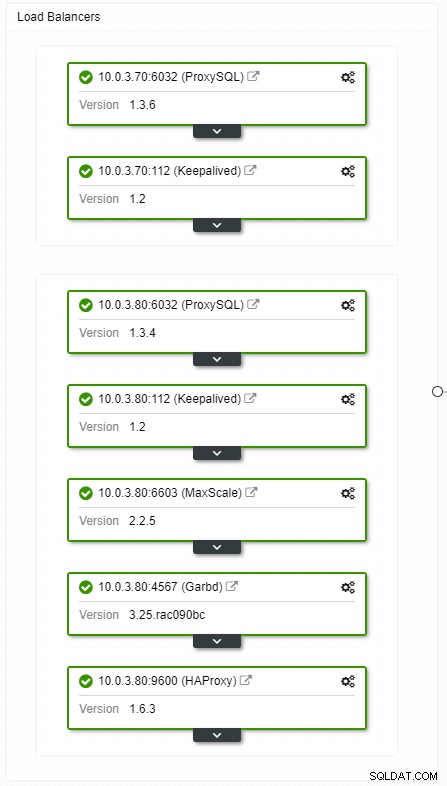 ClusterControl HA load balancers topologivy
ClusterControl HA load balancers topologivy Krascher är inte frekventa, men mer troliga än att servrar går ner. Om en slav av någon anledning går ner, kommer något som ProxySQL att omdirigera all trafik till mastern, med risk för att den överbelastas. När slaven återhämtar sig kommer trafiken att omdirigeras tillbaka till den. Vanligtvis bör sådana stillestånd inte ta mer än ett par minuter, så den övergripande svårighetsgraden är medelhög, även om sannolikheten också är medelstor.
För att få dina lastbalanseringskomponenter redundanta kan du använda keepalived.
 ClusterControl:Implementera keepalived för ProxySQL belastningsbalanserare
ClusterControl:Implementera keepalived för ProxySQL belastningsbalanserare Datacenter går ner
Det största problemet med replikering är att det inte finns någon majoritetsmekanism för att upptäcka ett datacenterfel och tjäna en ny master. Ett av besluten är att använda Orchestrator/Flotte. Orchestrator är en topologiövervakare som kan kontrollera failovers. När den används tillsammans med Raft kommer Orchestrator att bli kvorummedveten. En av Orchestrator-instanserna väljs till ledare och utför återställningsuppgifter. Kopplingen mellan orkestratornoden korrelerar inte med transaktionsdatabasbekräftelser och är sparsam.
Orchestrator/Raft kan använda extra instanser som utför övervakning av topologin. I fallet med nätverkspartitionering kommer de partitionerade Orchestrator-instanserna inte att vidta några åtgärder. Den del av Orchestrator-klustret som har kvorum kommer att välja en ny mästare och göra de nödvändiga topologiändringarna.
ClusterControl används för hantering, skalning och, vad som är viktigast, nodåterställning - Orchestrator skulle hantera failovers, men om en slav skulle krascha kommer ClusterControl att se till att den kommer att återställas. Orchestrator och ClusterControl skulle placeras i samma tillgänglighetszon, åtskilda från MySQL-noderna, för att säkerställa att deras aktivitet inte kommer att påverkas av nätverksdelningar mellan tillgänglighetszoner i datacentret.