Galera-klustret tvingar fram en stark datakonsistens, där alla noder i klustret är tätt kopplade. Även om nätverkssegmentering stöds, är replikeringsprestanda fortfarande bunden av två faktorer:
-
Rundturstiden (RTT) till den längsta noden i klustret från ursprungsnoden.
-
Storleken på en skrivuppsättning som ska överföras och certifieras för konflikt på mottagarnoden.
Även om det finns sätt att öka prestandan hos Galera, är det inte möjligt att kringgå dessa två begränsande faktorer.
Lyckligtvis byggdes Galera Cluster ovanpå MySQL, som också kommer med en inbyggd replikeringsfunktion (duh!). Både Galera-replikering och MySQL-replikering finns i samma serverprogramvara oberoende av varandra. Vi kan använda dessa teknologier för att arbeta tillsammans, där all replikering inom ett datacenter kommer att ske på Galera, medan replikering mellan datacenter kommer att ske på standard MySQL-replikering. Slavplatsen kan fungera som en hot-standby-plats, redo att servera data när applikationerna omdirigeras till säkerhetskopieringsplatsen. Vi tog upp detta i en tidigare blogg om MySQL-arkitekturer för katastrofåterställning.
Kluster-till-kluster-replikering introducerades i ClusterControl i version 1.7.4. I det här blogginlägget visar vi hur enkelt det är att ställa in replikering mellan två Galera-kluster (PXC 8.0). Sedan ska vi titta på den mer utmanande delen:hantera fel på både nod- och klusternivå med hjälp av ClusterControl; failover- och failback-operationer är avgörande för att bevara dataintegriteten i hela systemet.
Klusterdistribution
För vårt exempel behöver vi minst två kluster och två platser – en för den primära och en annan för den sekundära. Det fungerar på samma sätt som traditionell MySQL master-slave replikering men i en större skala med tre databasnoder på varje plats. Med ClusterControl skulle du uppnå detta genom att distribuera ett primärt kluster, följt av att distribuera det sekundära klustret på katastrofåterställningsplatsen som ett replikkluster, replikerat av en dubbelriktad asynkron replikering.
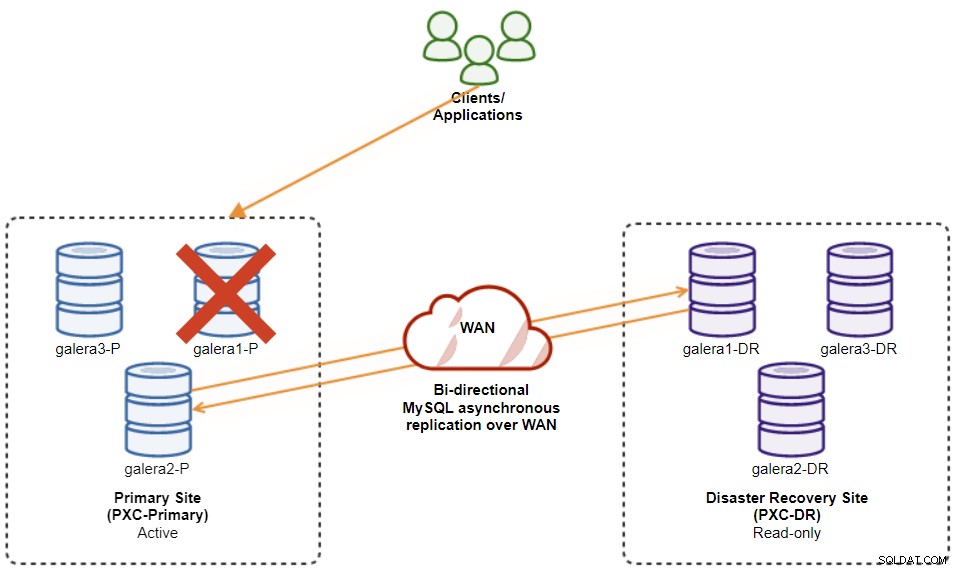
Följande diagram illustrerar vår slutliga arkitektur:

Vi har totalt sex databasnoder, tre på den primära webbplatsen och ytterligare en tre på katastrofåterställningsplatsen. För att förenkla nodrepresentationen kommer vi att använda följande notationer:
-
Primär webbplats:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Webbplats för katastrofåterställning:
-
galera1-DR - 192.168.11.181 (slav)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Först, distribuera helt enkelt det första klustret, och vi kallar det PXC-Primary. Öppna ClusterControl UI → Deploy → MySQL Galera och ange alla nödvändiga detaljer:
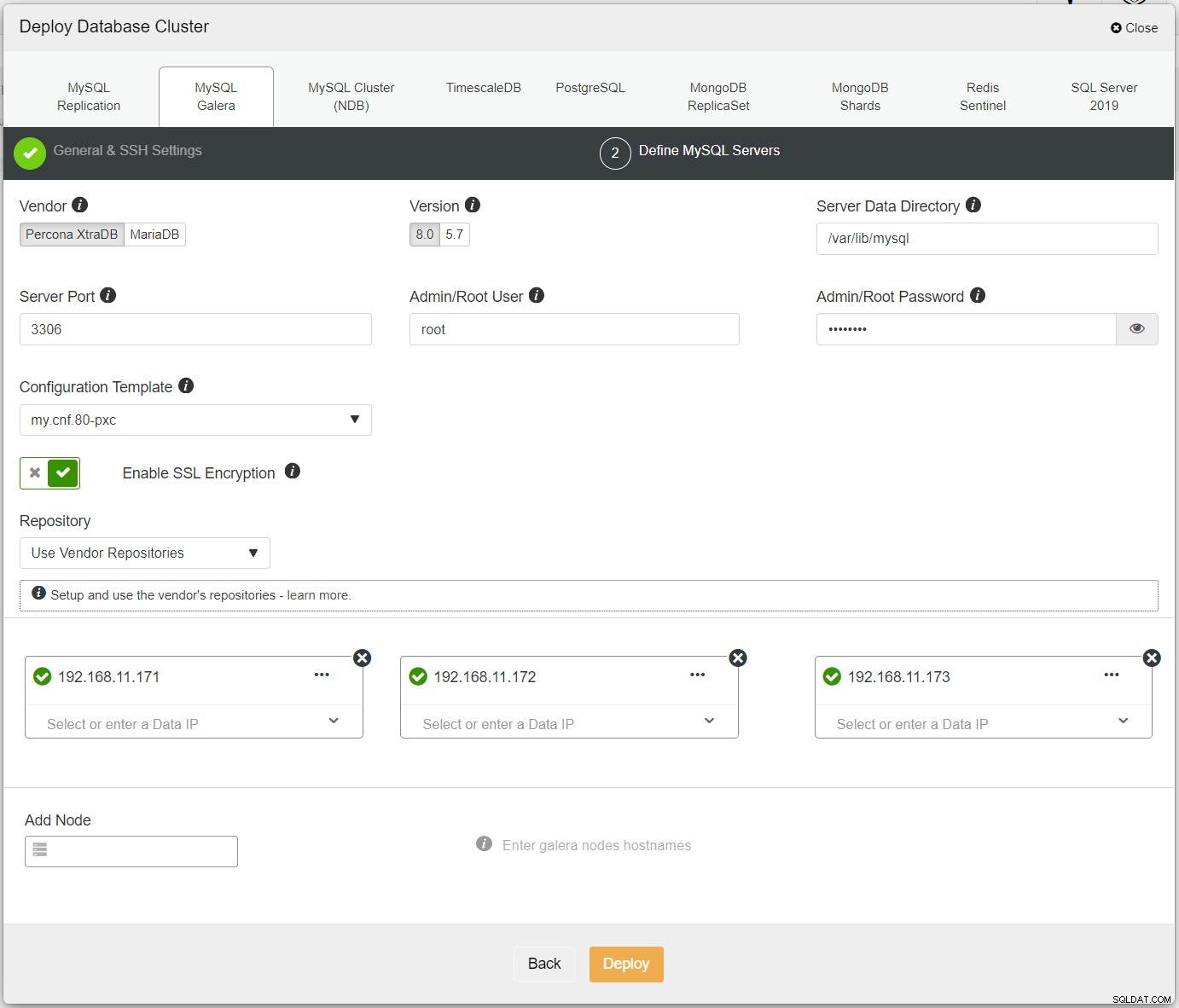
Se till att varje specificerad nod har en grön bock bredvid sig, vilket indikerar att ClusterControl kan ansluta till värden via lösenordslös SSH. Klicka på Distribuera och vänta på att distributionen ska slutföras. När du är klar bör du se följande kluster listat på klustrets instrumentpanelssida:
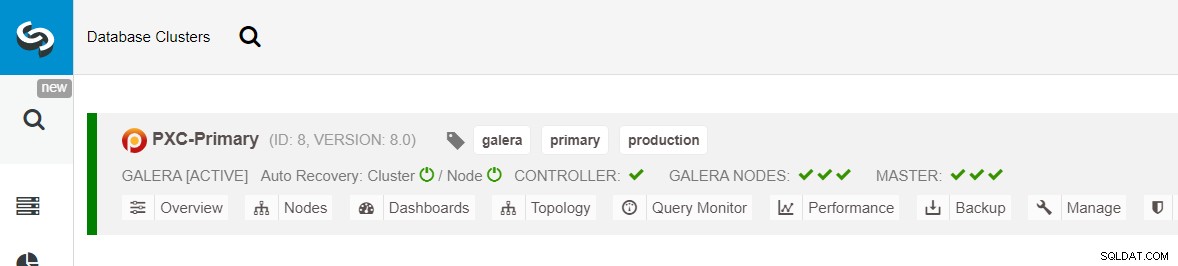
Närnäst kommer vi att använda ClusterControl-funktionen som heter Create Replica Cluster, tillgänglig från rullgardinsmenyn Cluster Action:
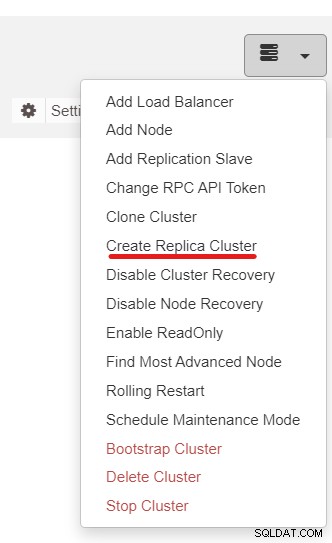
Du kommer att presenteras med följande sidofältspopup:
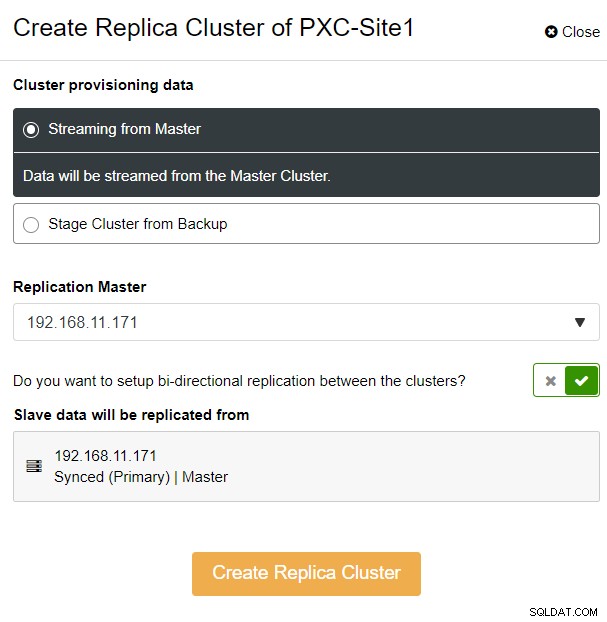
Vi valde alternativet "Streaming from Master", där ClusterControl kommer att använda vald master för att synkronisera replikklustret och konfigurera replikeringen. Var uppmärksam på alternativet för dubbelriktad replikering. Om det är aktiverat kommer ClusterControl att ställa in en dubbelriktad replikering mellan båda platserna (cirkulär replikering). Den valda mastern kommer att replikera från den första mastern som definierats för replikklustret och vice versa. Denna inställning kommer att minimera mellanlagringstiden som krävs vid återställning efter failover eller failback. Klicka på "Skapa replikkluster", där ClusterControl öppnar en ny distributionsguide för replikklustret, som visas nedan:
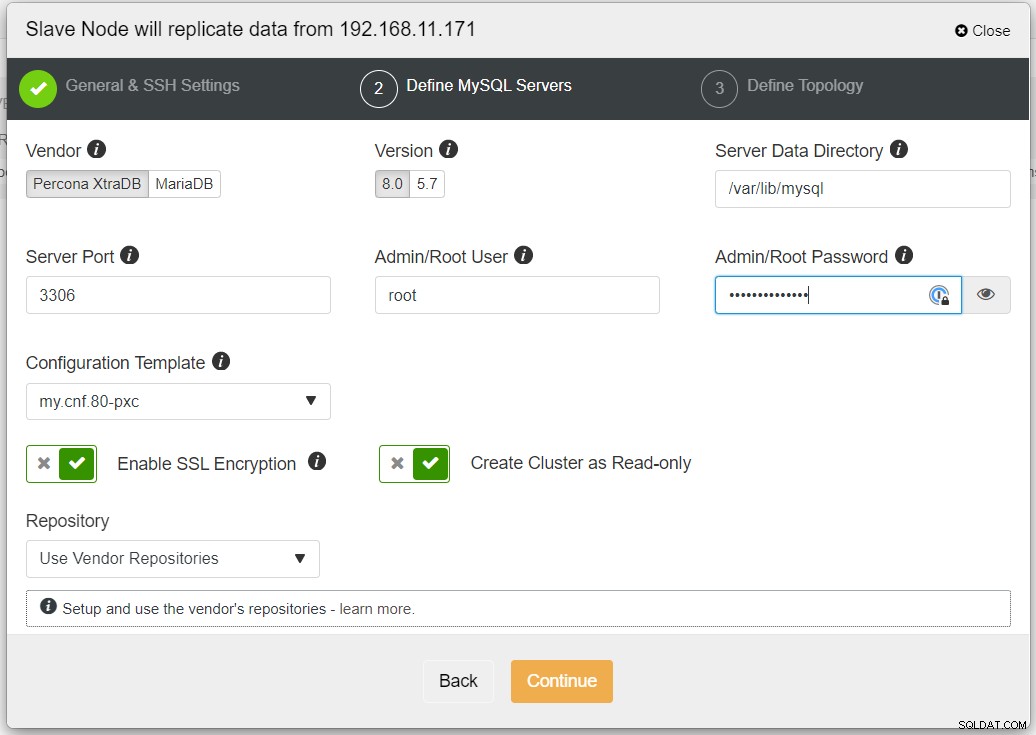
Det rekommenderas att aktivera SSL-kryptering om replikeringen involverar opålitliga nätverk som WAN, icke-tunnlade nätverk eller Internet. Se också till att "Skapa kluster som skrivskyddad" är växlad; detta är skyddet mot oavsiktlig skrivning och en bra indikator för att enkelt skilja mellan det aktiva klustret (läs-skriv) och det passiva klustret (skrivskyddat).
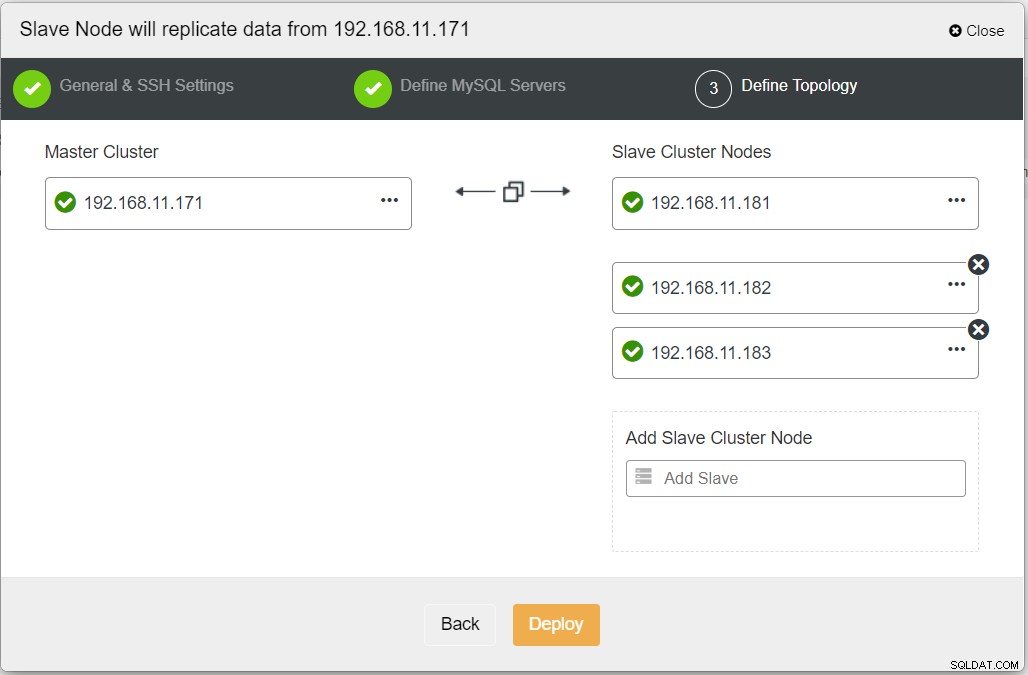
När du fyller i all nödvändig information bör du nå följande steg för att definiera replikklustertopologin:
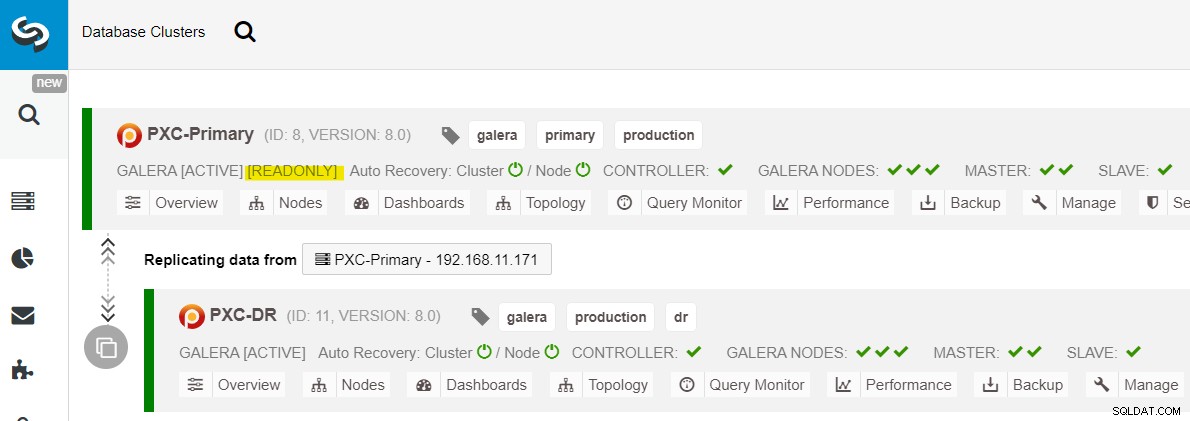
Från ClusterControl-instrumentpanelen, när distributionen är klar, bör du se DR-webbplatsen har en dubbelriktad pil kopplad till den primära platsen:
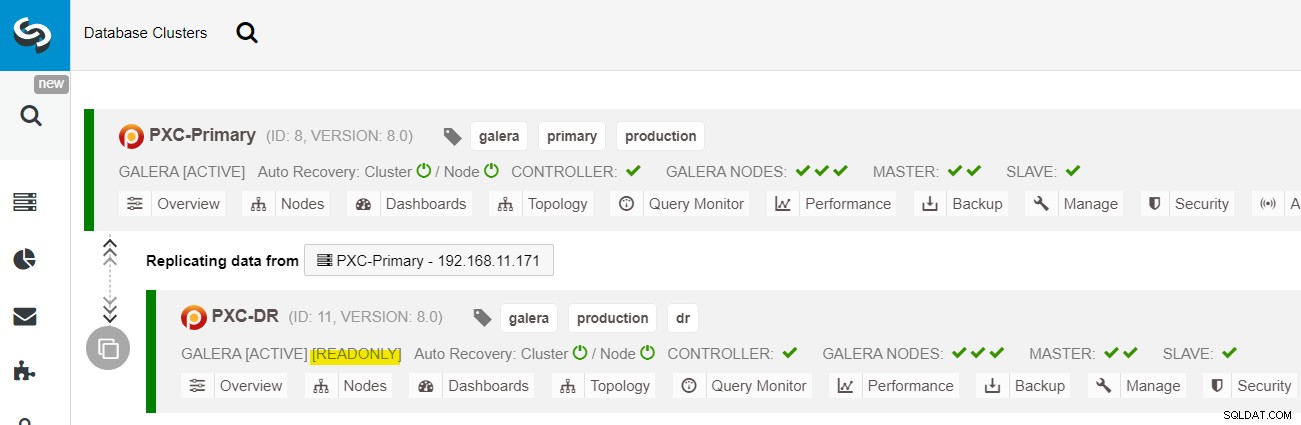
Distributionen är nu klar. Applikationer bör endast skicka skrivningar till den primära platsen eftersom detta är den aktiva platsen och DR-platsen är konfigurerad för skrivskyddad (markerad i gult). Läsningar kan skickas till båda platserna, även om DR-platsen riskerar att släpa efter på grund av den asynkrona replikeringsnaturen. Denna inställning kommer att göra de primära och katastrofåterställningsplatserna oberoende av varandra, löst kopplade till asynkron replikering. En av Galera-noderna på DR-platsen kommer att vara en slav som replikerar från en av Galera-noderna (master) på den primära platsen.
Vi har nu ett system där ett klusterfel på den primära platsen inte kommer att påverka säkerhetskopieringsplatsen. Prestandamässigt kommer WAN-latens inte att påverka uppdateringar på det aktiva klustret. Dessa skickas asynkront till säkerhetskopieringsplatsen.
Som en sidoanteckning är det också möjligt att ha en dedikerad slavinstans som ett replikeringsrelä istället för att använda en av Galera-noderna som en slav.
Galera Node Failover-procedur
Om den nuvarande mastern (galera1-P) misslyckas och de återstående noderna på den primära platsen fortfarande är uppe, bör slaven på katastrofåterställningsplatsen (galera1-DR) dirigeras till alla tillgängliga masters på den primära platsen, som visas i följande diagram:
Från ClusterControl-klusterlistan kan du se att klusterstatusen är försämrad , och om du rullar över utropsteckenikonen kan du se felet för just den noden (galera1-P):
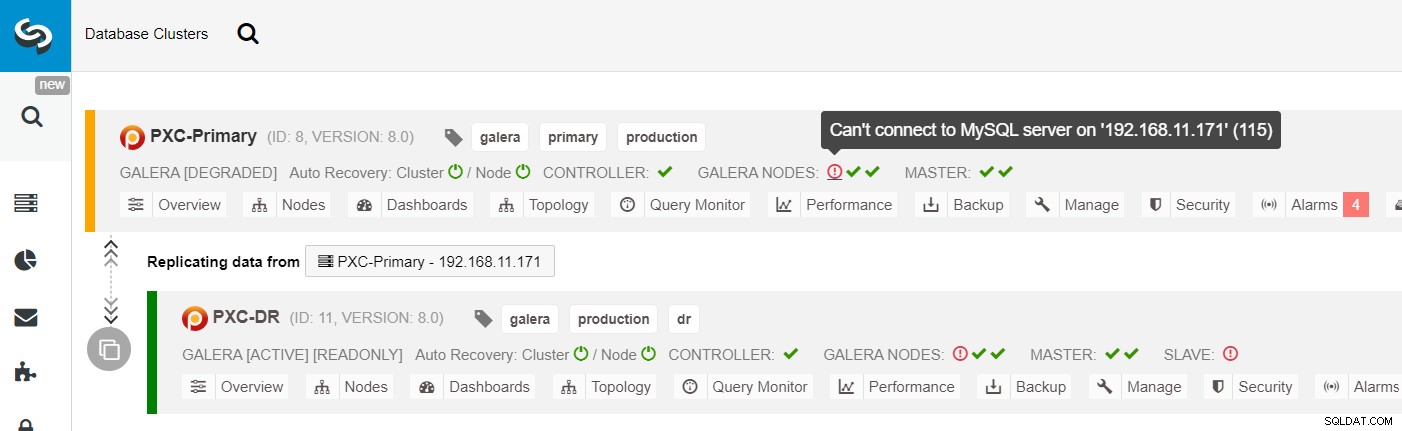
Med ClusterControl kan du helt enkelt gå till PXC-DR-kluster → Noder → välj galera1-DR → Nodåtgärder → Bygg om replikeringsslav och du kommer att presenteras med följande konfigurationsdialogruta:
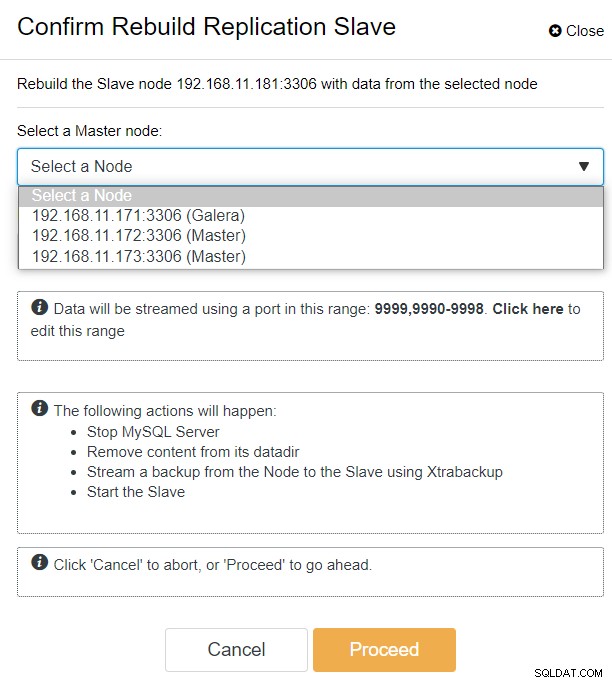
Vi kan se alla Galera-noder på den primära platsen (192.168.11.17x ) från rullgardinsmenyn. Välj den sekundära noden, 192.168.11.172 (galera2-P), och klicka på Fortsätt. ClusterControl kommer sedan att konfigurera replikeringstopologin som den ska vara och ställa in dubbelriktad replikering från galera2-P till galera1-DR. Du kan bekräfta detta från klustrets instrumentpanelssida (markerad i gult):
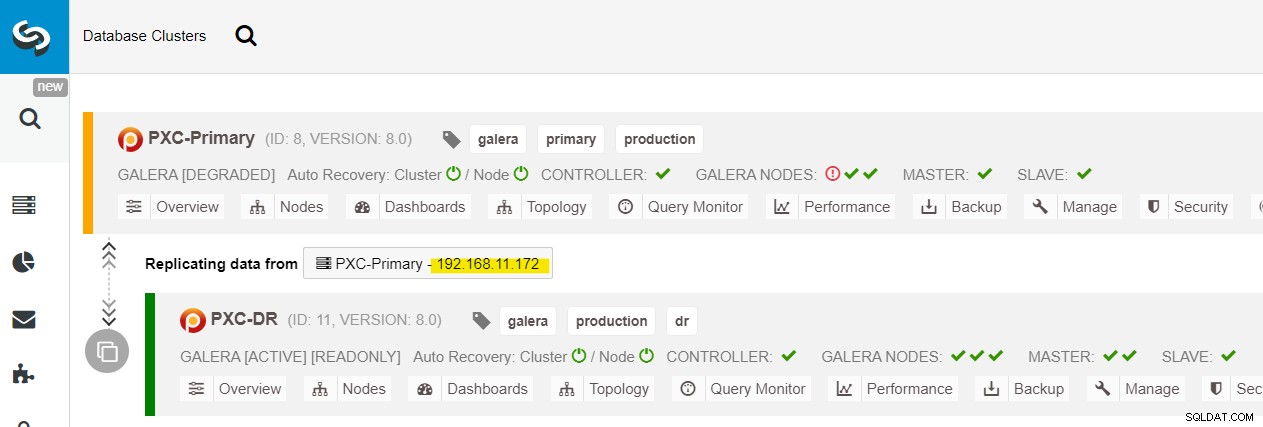
Vid denna tidpunkt fungerar det primära klustret (PXC-Primary) fortfarande som det aktiva klustret för denna topologi. Det bör inte påverka databastjänstens drifttid för det primära klustret.
Galera Cluster Failover-procedur
Om det primära klustret går ner, kraschar eller helt enkelt förlorar anslutningen från applikationssynpunkt, kan applikationen dirigeras till DR-webbplatsen nästan omedelbart. SysAdmin behöver helt enkelt inaktivera skrivskyddat på alla Galera-noder på katastrofåterställningsplatsen genom att använda följande uttalande:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRFör ClusterControl-användare kan du använda ClusterControl UI → Noder → välj DB-noden → Nodåtgärder → Inaktivera skrivskyddad. ClusterControl CLI är också tillgängligt genom att utföra följande kommandon på ClusterControl-noden:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writeFeilövergången till DR-webbplatsen är nu klar, och applikationerna kan börja skicka skrivningar till PXC-DR-klustret. Från ClusterControl UI bör du se något i stil med detta:
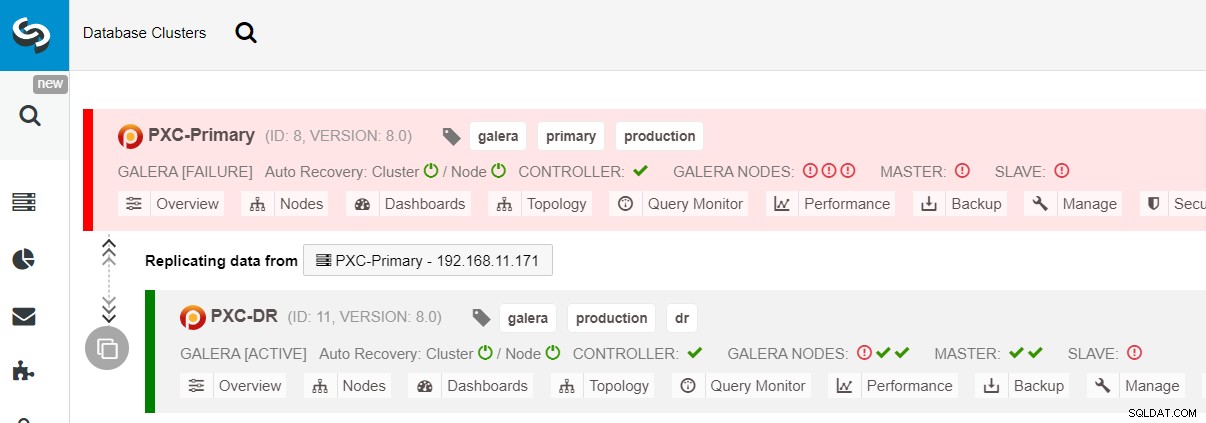
Följande diagram visar vår arkitektur efter att applikationen misslyckades till DR-webbplatsen :
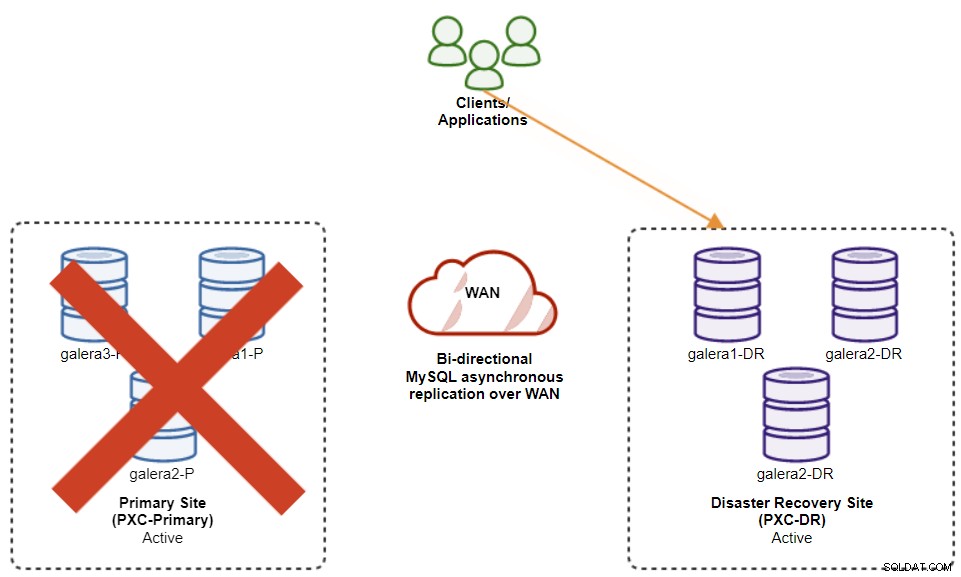
Förutsatt att den primära webbplatsen fortfarande är nere, så finns det ingen replikering mellan platser tills den primära webbplatsen kommer upp igen.
Galera Cluster Failback-procedur
Efter att den primära platsen har kommit upp är det viktigt att notera att det primära klustret måste ställas in på skrivskyddat, så vi vet att det aktiva klustret är det på webbplatsen för katastrofåterställning. Från ClusterControl, gå till klustrets rullgardinsmeny och välj "Aktivera skrivskyddad", vilket kommer att aktivera skrivskyddat på alla noder i det primära klustret och sammanfattar den aktuella topologin enligt nedan:
Se till att allt är grönt innan du planerar att starta klustrets failback-process (grönt) betyder att alla noder är uppe och synkroniserade med varandra). Om det till exempel finns en nod i försämrad status, den replikerande noden släpar efter, eller bara några av noderna i det primära klustret var nåbara, vänta tills klustret är helt återställt, antingen genom att vänta på ClusterControls automatiska återställningsprocedurer att slutföra, eller manuellt ingripande.
Vid denna tidpunkt är det aktiva klustret fortfarande DR:s kluster, och det primära klustret fungerar som ett sekundärt kluster. Följande diagram illustrerar den nuvarande arkitekturen:
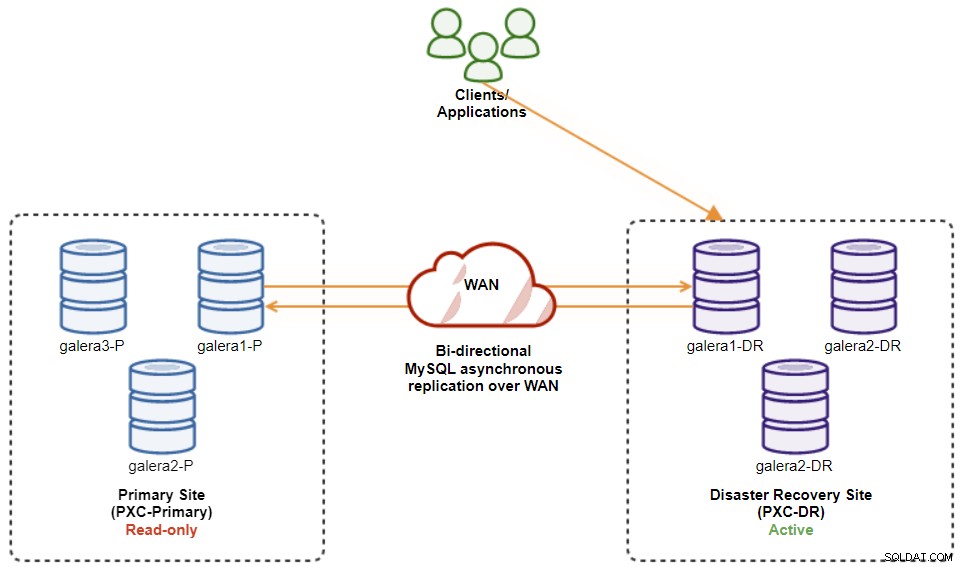
Det säkraste sättet att failback till den primära webbplatsen är att ställa in skrivskyddad på DR:s kluster, följt av inaktivering av skrivskyddad på den primära webbplatsen. Gå till ClusterControl UI → PXC-DR (rullgardinsmeny) → Aktivera skrivskyddad. Detta kommer att utlösa ett jobb för att ställa in skrivskyddat på alla noder i DR:s kluster. Gå sedan till ClusterControl UI → PXC-Primary → Noder och inaktivera skrivskyddat på alla databasnoder i det primära klustret.
Du kan också förenkla procedurerna ovan med ClusterControl CLI. Alternativt kan du utföra följande kommandon på ClusterControl-värden:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writeNär det är klart har replikeringsriktningen gått tillbaka till sin ursprungliga konfiguration, där PXC-Primary är det aktiva klustret och PXC-DR är standby-klustret. Följande diagram illustrerar den slutliga arkitekturen efter klustrets failback-operation:
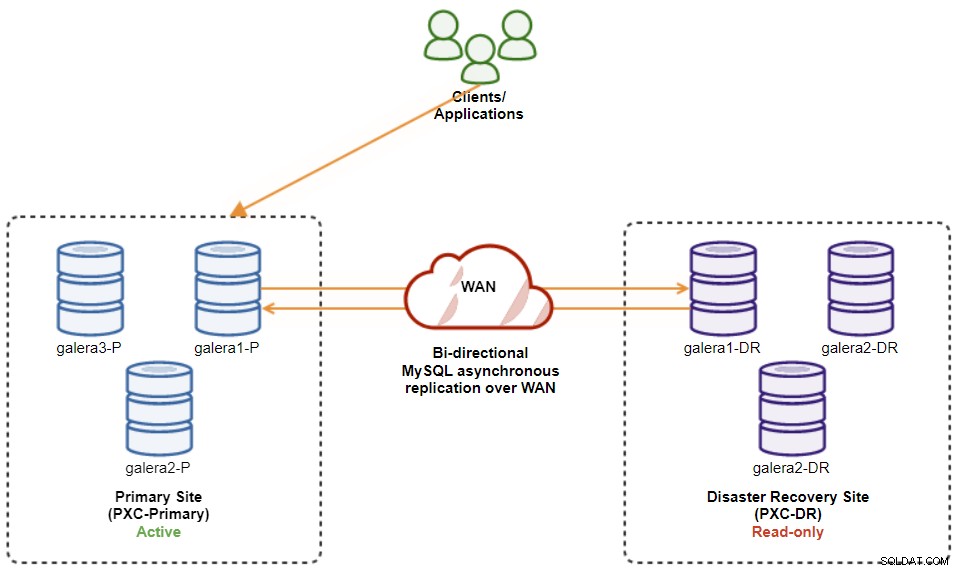
Vid denna tidpunkt är det nu säkert att omdirigera applikationerna att skriva på den primära webbplatsen.
Fördelar med kluster-till-kluster asynkron replikering
Kluster-till-kluster med asynkron replikering kommer med ett antal fördelar:
-
Minimal driftstopp under en databasfelövergång. I grund och botten kan du omdirigera skrivningen nästan omedelbart till slavsidan, bara om du kan skydda skrivningar så att de inte når huvudsidan (eftersom dessa skrivningar inte skulle replikeras och förmodligen kommer att skrivas över när du synkroniserar om från DR-sidan).
-
Ingen påverkan av prestanda på den primära webbplatsen eftersom den är oberoende av säkerhetskopieringsplatsen (DR). Replikering från master till slav utförs asynkront. Masterplatsen genererar binära loggar, slavplatsen replikerar händelserna och tillämpar händelserna vid något senare tillfälle.
-
Sajter för katastrofåterställning kan användas för andra ändamål, till exempel säkerhetskopiering av databas, säkerhetskopiering av binär logg och rapportering, eller tunga analytiska frågor (OLAP). Båda platserna kan användas samtidigt, förutom replikeringsfördröjningen och skrivskyddade operationer på slavsidan.
-
DR-klustret kan potentiellt köras på mindre instanser i en offentlig molnmiljö, så länge de kan hänga med med det primära klustret. Du kan uppgradera instanserna om det behövs. I vissa scenarier kan det spara vissa kostnader.
-
Du behöver bara en extra plats för katastrofåterställning jämfört med aktiva Galera-replikeringsinställningar för flera platser, som kräver minst tre aktiva webbplatser för att fungera korrekt.
Nackdelar med asynkron replikering från kluster till kluster
Det finns också nackdelar med den här inställningen, beroende på om du använder dubbelriktad eller enkelriktad replikering:
-
Det finns en chans att missa data under failover om slaven var bakom, eftersom replikeringen är asynkron. Detta kan förbättras med semi-synkron och flertrådig slavreplikering, även om det kommer att finnas ytterligare en uppsättning utmaningar som väntar (nätverksoverhead, replikeringsgap, etc.).
-
I enkelriktad replikering, trots att failover-procedurerna är ganska enkla, kan failback-procedurerna vara knepiga och benägna för människor fel. Det kräver viss expertis för att byta master/slav roll tillbaka till den primära platsen. Det rekommenderas att förvara procedurerna dokumenterade, repetera failover/failback-operationen regelbundet och använda korrekta rapporterings- och övervakningsverktyg.
-
Det kan bli ganska kostsamt eftersom du måste ställa in ett liknande antal noder på webbplatsen för katastrofåterställning . Detta är inte svart och vitt, eftersom kostnadsmotiveringen vanligtvis kommer från kraven i ditt företag. Med viss planering är det möjligt att maximera användningen av databasresurser på båda platserna, oavsett databasroller.
Avsluta
Att ställa in asynkron replikering för dina MySQL Galera-kluster kan vara en relativt enkel process – så länge du förstår hur man korrekt hanterar fel på både nod- och klusternivå. I slutändan är failover- och failback-operationer avgörande för att säkerställa dataintegritet.
För fler tips om hur du designar dina Galera-kluster med failover- och failback-strategier i åtanke, kolla in det här inlägget om MySQL-arkitekturer för katastrofåterställning. Om du letar efter hjälp med att automatisera dessa operationer, utvärdera ClusterControl gratis i 30 dagar och följ stegen i det här inlägget.
Glöm inte att följa oss på Twitter eller LinkedIn och prenumerera på vårt nyhetsbrev och håll dig uppdaterad om de senaste nyheterna och bästa praxis för att hantera din databasinfrastruktur med öppen källkod.