En av de coola funktionerna i Galera är automatisk nodprovisionering och medlemskontroll. Om en nod misslyckas eller förlorar kommunikationen kommer den automatiskt att vräkas från klustret och förbli inoperativ. Så länge som majoriteten av noderna fortfarande kommunicerar (Galera kallar denna PC - primär komponent), finns det en mycket stor chans att den misslyckade noden automatiskt skulle kunna gå samman igen, synkronisera om och återuppta replikeringen när anslutningen är tillbaka.
I allmänhet är alla Galera-noder lika. De har samma datamängd och samma roll som masters, kan hantera läsning och skrivning samtidigt, tack vare Galera gruppkommunikation och certifieringsbaserad replikeringsplugin. Därför finns det faktiskt ingen failover från databasens synvinkel på grund av denna jämvikt. Endast från applikationssidan som skulle kräva failover, för att hoppa över de opererande noderna medan klustret är partitionerat.
I det här blogginlägget kommer vi att undersöka hur Galera Cluster utför nod- och klusteråterställning om nätverkspartitionen inträffar. Bara som en sidoanteckning har vi tagit upp ett liknande ämne i det här blogginlägget för en tid sedan. Codership har förklarat Galeras återställningskoncept i detalj på dokumentationssidan, Node Failure and Recovery.
Nodfel och vräkning
För att förstå återställningen måste vi först förstå hur Galera upptäcker nodfel och vräkningsprocessen. Låt oss lägga in detta i ett kontrollerat testscenario så att vi kan förstå vräkningsprocessen bättre. Anta att vi har ett Galera-kluster med tre noder som illustreras nedan:
Följande kommando kan användas för att hämta våra Galera-leverantörsalternativ:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GDet är en lång lista, men vi behöver bara fokusera på några av parametrarna för att förklara processen:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Först och främst följer Galera ISO 8601-formatering för att representera varaktighet. P1D betyder att längden är en dag, medan PT15S betyder att längden är 15 sekunder (observera tidsbeteckningen, T, som föregår tidsvärdet). Till exempel om man ville öka evs.view_forget_timeout till 1 och en halv dag skulle man ställa in P1DT12H eller PT36H.
Med tanke på att alla värdar inte har konfigurerats med några brandväggsregler använder vi följande skript som heter block_galera.sh på galera2 för att simulera ett nätverksfel till/från denna nod:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateGenom att köra skriptet får vi följande utdata:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Den rapporterade tidsstämpeln kan betraktas som början på klusterpartitioneringen, där vi förlorar galera2, medan galera1 och galera3 fortfarande är online och tillgängliga. Vid det här laget ser vår Galera Cluster-arkitektur ut ungefär så här:
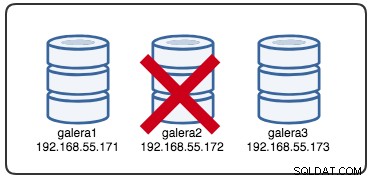
Från partitionerad nodperspektiv
På galera2 kommer du att se några utskrifter i MySQL-felloggen. Låt oss dela upp dem i flera delar. Driftstoppet startade runt 16:46:02 UTC-tid och efter gmcast.peer_timeout=PT3S , visas följande:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0När den passerade evs.suspect_timeout =PT5S , båda noderna galera1 och galera3 misstänks vara döda av galera2:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveSedan kommer Galera att revidera den aktuella klustervyn och positionen för denna nod:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Med den nya klustervyn kommer Galera att utföra kvorumberäkning för att avgöra om denna nod är en del av den primära komponenten. Om den nya komponenten ser "primär =nej", kommer Galera att sänka det lokala nodtillståndet från SYNCED till OPEN:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Med den senaste ändringen av klustervyn och nodtillståndet, returnerar Galera klustervyn efter avhysning och global status enligt nedan:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Du kan se följande globala status för galera2 har ändrats under denna period:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+Vid denna tidpunkt är MySQL/MariaDB-servern på galera2 fortfarande tillgänglig (databasen lyssnar på 3306 och Galera på 4567) och du kan fråga i mysql-systemtabellerna och lista ut databaserna och tabellerna. Men när du hoppar in i icke-systemtabellerna och gör en enkel fråga så här:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useDu kommer omedelbart att få ett felmeddelande som indikerar att WSREP är laddat men inte redo att användas av denna nod, som rapporterats av wsrep_ready status. Detta beror på att noden förlorar sin anslutning till den primära komponenten och den går in i det icke-operativa tillståndet (den lokala nodens status ändrades från SYNCED till OPEN). Data som läses från noder i ett icke-operativt tillstånd anses vara inaktuella, om du inte ställer in wsrep_dirty_reads=ON för att tillåta läsning, även om Galera fortfarande avvisar alla kommandon som modifierar eller uppdaterar databasen.
Slutligen kommer Galera att fortsätta lyssna och återansluta till andra medlemmar i bakgrunden i det oändliga:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Vräkningsprocessens flöde av Galera-gruppkommunikation för den partitionerade noden under nätverksproblem kan sammanfattas enligt nedan:
- Kopplar från klustret efter gmcast.peer_timeout .
- Mistankar om andra noder efter evs.suspect_timeout .
- Hämtar den nya klustervyn.
- Utför kvorumberäkning för att bestämma nodens tillstånd.
- Degraderar noden från SYNCED till OPEN.
- Försök att återansluta till den primära komponenten (andra Galera-noder) i bakgrunden.
Från primärkomponentperspektiv
På galera1 respektive galera3, efter gmcast.peer_timeout=PT3S , visas följande i MySQL-felloggen:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Efter att den gått evs.suspect_timeout =PT5S , galera2 misstänks vara död av galera3 (och galera1):
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera kollar om de andra noderna svarar på gruppkommunikationen på galera3, den finner att galera1 är i primärt och stabilt tillstånd:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera reviderar klustervyn för denna nod (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera tar sedan bort den partitionerade noden från den primära komponenten:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Den nya primära komponenten består nu av två noder, galera1 och galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Den primära komponenten kommer att utbyta staten mellan varandra för att komma överens om den nya klustervyn och globala tillståndet:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera beräknar och verifierar beslutförhet för statens utbyte mellan onlinemedlemmar:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera uppdaterar den nya klustervyn och globala tillstånd efter galera2 vräkning:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)Vid det här laget kommer både galera1 och galera3 att rapportera liknande global status:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+De listar den problematiska medlemmen i wsrep_evs_delayed status. Eftersom den lokala staten är "Synced" är dessa noder i drift och du kan omdirigera klientanslutningarna från galera2 till vilken som helst av dem. Om det här steget är obekvämt, överväg att använda en lastbalanserare som sitter framför databasen för att förenkla anslutningsändpunkten från klienterna.
Nodåterställning och sammanfogning
En partitionerad Galera-nod kommer att fortsätta att försöka upprätta förbindelse med den primära komponenten i det oändliga. Låt oss spola iptables-reglerna på galera2 för att låta den ansluta till de återstående noderna:
# on galera2
$ iptables -FNär noden kan ansluta till en av noderna kommer Galera att börja återupprätta gruppkommunikationen automatiskt:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableNod galera2 kommer sedan att ansluta till en av de primära komponenterna (i detta fall är galera1, nod-ID 737422d6) för att få den aktuella klustervyn och nodernas tillstånd:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera kommer sedan att utföra tillståndsutbyte med resten av medlemmarna som kan bilda den primära komponenten:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Statsutbytet tillåter galera2 att beräkna kvorumet och producera följande resultat:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera kommer sedan att främja det lokala nodtillståndet från ÖPPEN till PRIMÄR, för att starta och upprätta nodanslutningen till den primära komponenten:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Som rapporterats av raden ovan, beräknar Galera gapet på hur långt noden är bakom från klustret. Den här noden kräver tillståndsöverföring för att komma ikapp till skrivuppsättningsnummer 2836958 från 2761994:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera förbereder IST-avlyssnaren på port 4568 på denna nod och ber alla synkade noder i klustret att bli donator. I det här fallet väljer Galera automatiskt galera3 (192.168.55.173), eller så kan den också välja en givare från listan under wsrep_sst_donor (om definierat) för synkroniseringsoperationen:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Den kommer då att ändra den lokala nodens tillstånd från PRIMÄR till JOINER. I detta skede beviljas galera2 med begäran om tillståndsöverföring och börjar cachelagra skrivuppsättningar:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetNod galera2 börjar ta emot de saknade skrivuppsättningarna från den valda givarens gcache (galera3):
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.När alla saknade skrivuppsättningar har tagits emot och tillämpats kommer Galera att marknadsföra galera2 som JOINED tills seqnr 2837012:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Noden tillämpar alla cachade skrivuppsättningar i sin slavkö och avslutar ikapp klustret. Dess slavkö är nu tom. Galera kommer att marknadsföra galera2 till SYNCED, vilket indikerar att noden nu är i drift och redo att betjäna kunder:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsVid denna tidpunkt är alla noder i drift igen. Du kan verifiera genom att använda följande uttalanden på galera2:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+wsrep_cluster_size rapporteras som 3 och klusterstatusen är Primär, vilket indikerar att galera2 är en del av den primära komponenten. Den wsrep_evs_delayed har också rensats och den lokala staten är nu synkroniserad.
Återställningsprocessens flöde för den partitionerade noden under nätverksproblem kan sammanfattas enligt nedan:
- Återupprättar gruppkommunikation till andra noder.
- Hämtar klustervyn från en av de primära komponenterna.
- Utför tillståndsutbyte med den primära komponenten och beräknar kvorumet.
- Ändrar den lokala nodens status från ÖPPEN till PRIMÄR.
- Beräknar gapet mellan lokal nod och klustret.
- Ändrar den lokala nodens status från PRIMÄR till JOINER.
- Förbereder IST-lyssnare/mottagare på port 4568.
- Begär statlig överföring via IST och väljer en donator.
- Börjar ta emot och tillämpa den saknade skrivuppsättningen från den valda givarens gcache.
- Ändrar den lokala nodens status från JOINER till JOINED.
- Kommer ikapp klustret genom att applicera de cachade skrivuppsättningarna i slavkön.
- Ändrar den lokala nodens status från JOINED till SYNCED.
Klusterfel
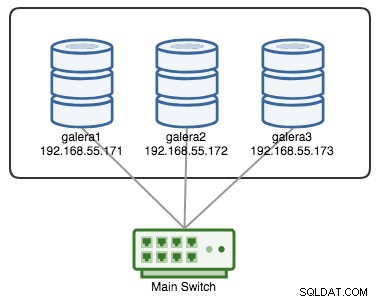
Ett Galera-kluster anses misslyckat om ingen primär komponent (PC) är tillgänglig. Betrakta ett liknande Galera-kluster med tre noder som visas i diagrammet nedan:
Ett kluster anses vara operativt om alla noder eller majoriteten av noderna är online. Online betyder att de kan se varandra genom Galeras replikeringstrafik eller gruppkommunikation. Om ingen trafik kommer in och ut från noden kommer klustret att skicka en hjärtslagssignal så att noden svarar i tid. Annars kommer den att läggas in i fördröjnings- eller misstänkt lista enligt hur noden svarar.
Om en nod går ner, låt oss säga nod C, kommer klustret att förbli operativt eftersom nod A och B fortfarande är beslutför med 2 röster av 3 för att bilda en primär komponent. Du bör få följande klustertillstånd på A och B:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Om låt oss säga att en primär switch gick kaput, som illustreras i följande diagram:
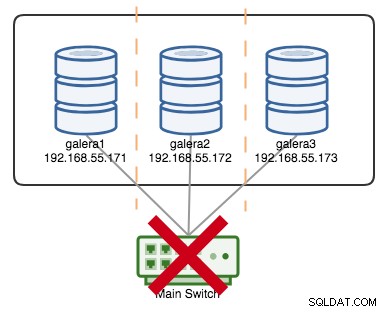
Vid denna tidpunkt förlorar varje enskild nod kommunikation med varandra, och klustertillståndet kommer att rapporteras som icke-primärt på alla noder (som vad som hände med galera2 i föregående fall). Varje nod skulle beräkna kvorumet och ta reda på att det är minoriteten (1 röst av 3) och därmed förlora beslutförhet, vilket innebär att ingen primärkomponent bildas och följaktligen vägrar alla noder att leverera data. Detta anses vara klusterfel.
När nätverksproblemet är löst kommer Galera automatiskt att återupprätta kommunikationen mellan medlemmarna, utbyta nodens tillstånd och fastställa möjligheten att reformera den primära komponenten genom att jämföra nodtillstånd, UUID och seqnos. Om sannolikheten är där kommer Galera att slå samman de primära komponenterna som visas på följande rader:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
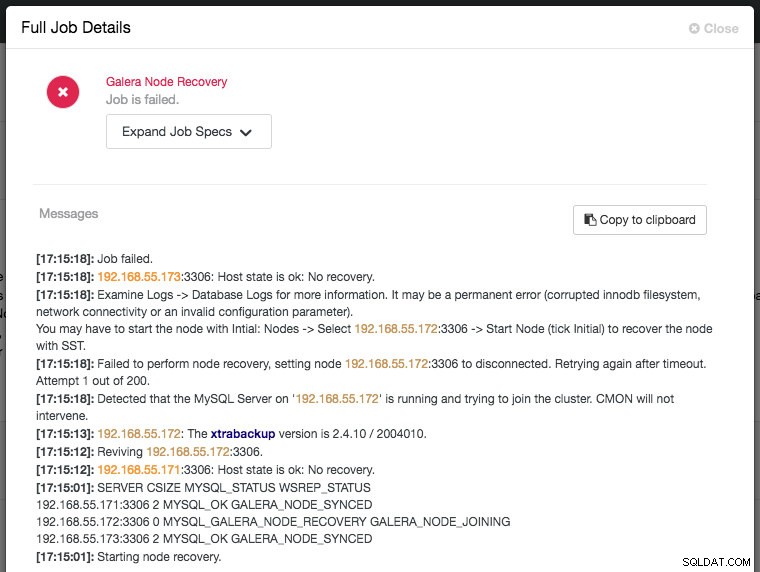
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Slutsats
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.