I mitt förra inlägg visade jag att en minnesoptimerad TVP vid små volymer kan ge betydande prestandafördelar för typiska frågemönster.
För att testa i lite högre skala gjorde jag en kopia av SalesOrderDetailEnlarged tabell, som jag hade utökat till ungefär 5 000 000 rader tack vare detta skript av Jonathan Kehayias (blogg | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Jag skapade också tre in-memory-versioner av denna tabell, var och en med olika bucket count (fiskar efter en "sweet spot") – 16 384, 131 072 och 1 048 576. (Du kan använda rundare tal, men de avrundas uppåt till nästa potens av 2 ändå.) Exempel:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Observera att jag ändrade skopstorleken från föregående exempel (256). När du bygger tabellen vill du välja "sweet spot" för hinkstorlek – du vill optimera hashindexet för punktuppslag, vilket innebär att du vill ha så många hinkar som möjligt med så få rader i varje hink som möjligt. Naturligtvis om du skapar ~5 miljoner hinkar (eftersom i det här fallet, kanske inte ett särskilt bra exempel, det finns ~5 miljoner unika kombinationer av värden), kommer du att ha en del minnesanvändning och avvägningar för sophämtning att hantera. Men om du försöker stoppa in ~5 miljoner unika värden i 256 hinkar, kommer du också att få problem. I vilket fall som helst går den här diskussionen långt utanför omfattningen av mina tester för det här inlägget.
För att testa mot standardtabellen gjorde jag liknande lagrade procedurer som i de tidigare testerna:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Så först, för att titta på planerna för, säg, 1 000 rader som infogas i tabellvariablerna, och sedan köra procedurerna:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Den här gången ser vi att i båda fallen har optimeraren valt en klustrad indexsökning mot bastabellen och en kapslad loop förenas mot TVP. Vissa kostnadsmått är olika, men annars är planerna ganska lika:
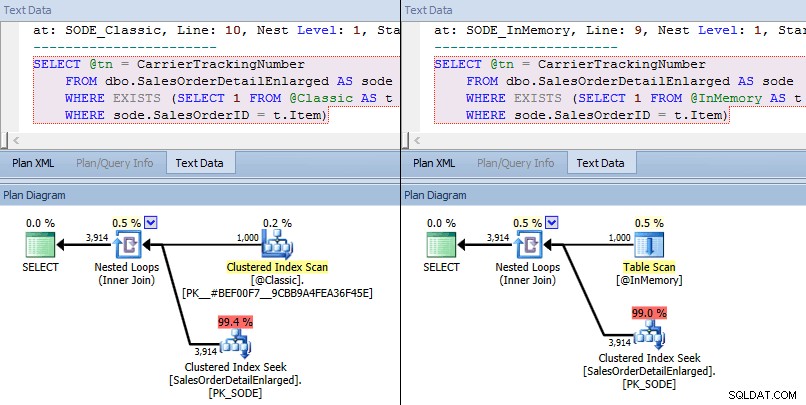 Liknande planer för in-memory TVP kontra klassisk TVP i högre skala
Liknande planer för in-memory TVP kontra klassisk TVP i högre skala
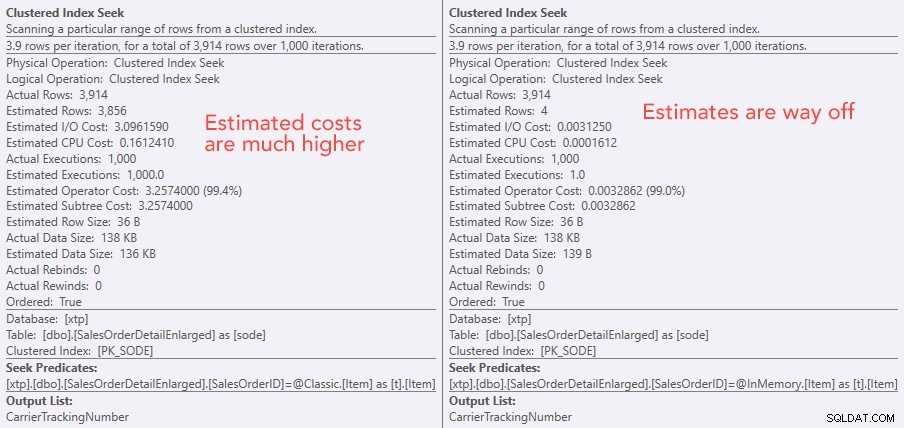 Jämföra sökoperatörskostnader – Classic till vänster, In-Memory till höger
Jämföra sökoperatörskostnader – Classic till vänster, In-Memory till höger
Det absoluta värdet av kostnaderna får det att verka som att den klassiska TVP skulle vara mycket mindre effektiv än In-Memory TVP. Men jag undrade om detta skulle vara sant i praktiken (särskilt eftersom siffran för det uppskattade antalet avrättningar till höger verkade misstänkt), så naturligtvis körde jag några tester. Jag bestämde mig för att kontrollera mot 100, 1 000 och 2 000 värden som skulle skickas till proceduren.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Prestandaresultaten visar att vid ett större antal punktuppslagningar leder användning av en In-Memory TVP till något minskande avkastning, och blir något långsammare varje gång:
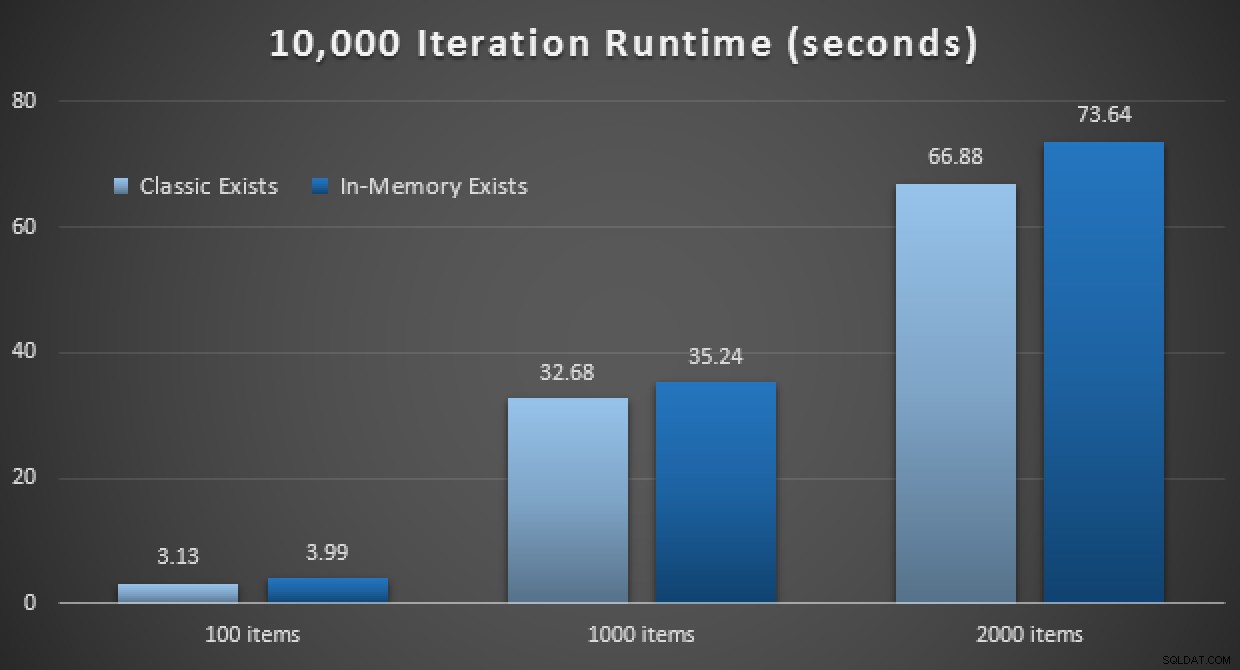
Resultat av 10 000 avrättningar med klassiska TVP och in-memory TVP em>
Så, i motsats till det intryck du kan ha fått från mitt tidigare inlägg, är det inte nödvändigtvis fördelaktigt att använda en TVP i minnet i alla fall.
Tidigare har jag också tittat på inbyggt kompilerade lagrade procedurer och tabeller i minnet, i kombination med minnes-TVP. Kan detta göra skillnad här? Spoiler:absolut inte. Jag skapade tre procedurer så här:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO En annan spoiler:Jag kunde inte köra dessa 9 tester med ett iterationsantal på 10 000 – det tog alldeles för lång tid. Istället gick jag igenom och körde varje procedur 10 gånger, körde den uppsättningen av tester 10 gånger och tog genomsnittet. Här är resultaten:
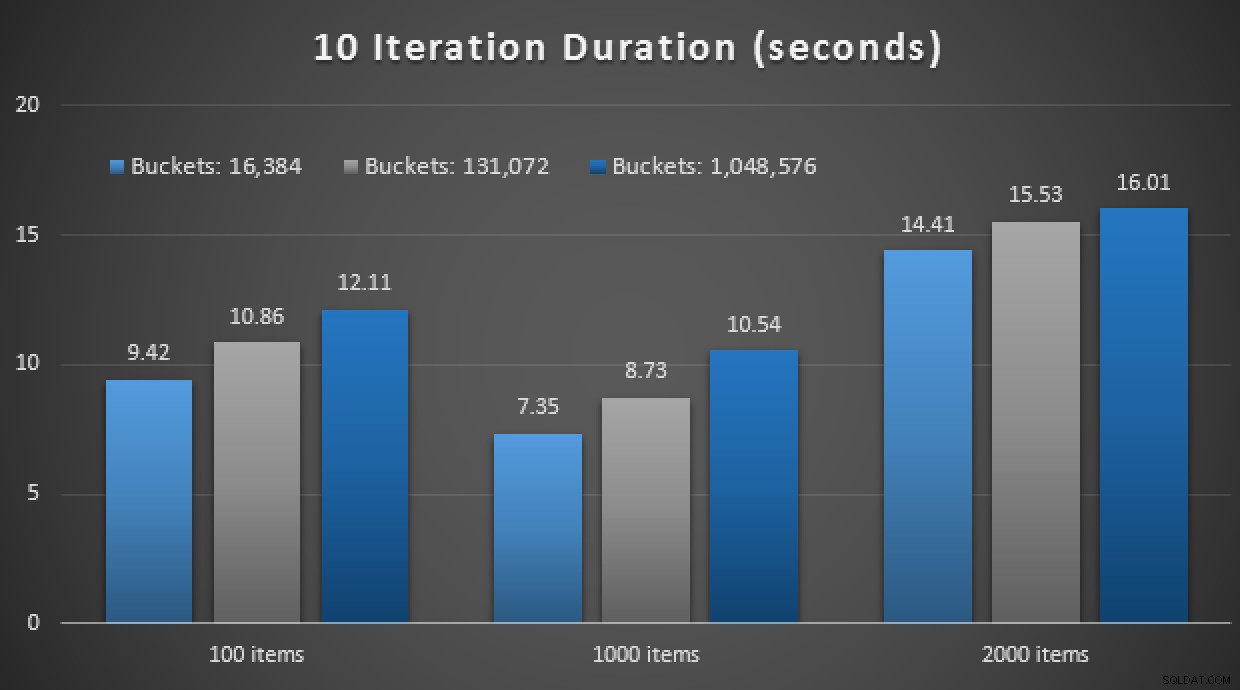
Resultat av 10 körningar med TVP:er i minnet och inbyggt kompilerade lagrade procedurer
Sammantaget var detta experiment ganska nedslående. Bara att titta på hur stor skillnaden är, med en tabell på disken, slutfördes det genomsnittliga lagrade proceduranropet på i genomsnitt 0,0036 sekunder. Men när allt använde in-memory-teknik var det genomsnittliga lagrade proceduranropet 1,1662 sekunder. Aj . Det är högst troligt att jag precis har valt ett dåligt användningsfall för att demonstrera överlag, men det verkade då vara ett intuitivt "första försök."
Slutsats
Det finns mycket mer att testa kring detta scenario, och jag har fler blogginlägg att följa. Jag har ännu inte identifierat det optimala användningsfallet för TVP:er i minnet i större skala, men hoppas att det här inlägget fungerar som en påminnelse om att även om en lösning verkar optimal i ett fall, är det aldrig säkert att anta att den är lika tillämplig till olika scenarier. Det är precis så här In-Memory OLTP bör närma sig:som en lösning med en smal uppsättning användningsfall som absolut måste valideras innan de implementeras i produktionen.