I vår tidigare blogg om SCUMM-dashboards tittade vi på MySQL-översiktsdashboarden. Den nya versionen av ClusterControl (ver. 1.7) erbjuder ett antal högupplösta grafer med användbara mätvärden, och vi gick igenom innebörden av var och en av mätvärdena och hur de hjälper dig att felsöka din databas. I den här bloggen kommer vi att titta på MySQL-replikeringsinstrumentpanelen. Låt oss gå vidare med detaljerna i den här instrumentpanelen om vad som har att erbjuda.
MySQL Replication Dashboard
MySQL Replication Dashboard erbjuder en mycket enkel uppsättning av grafer som gör det lättare att övervaka din MySQL-master och replik(er). Med början från toppen visar den de viktigaste variablerna och informationen för att bestämma tillståndet för kopiorna eller till och med mastern. Denna instrumentbräda erbjuder en mycket användbar del när man inspekterar slavarnas hälsa eller en master i master-master-setup. Man kan också kontrollera på den här instrumentpanelen masterns binära loggskapande och bestämma den övergripande dimensionen, i termer av den genererade storleken, vid en viss given tidsperiod.
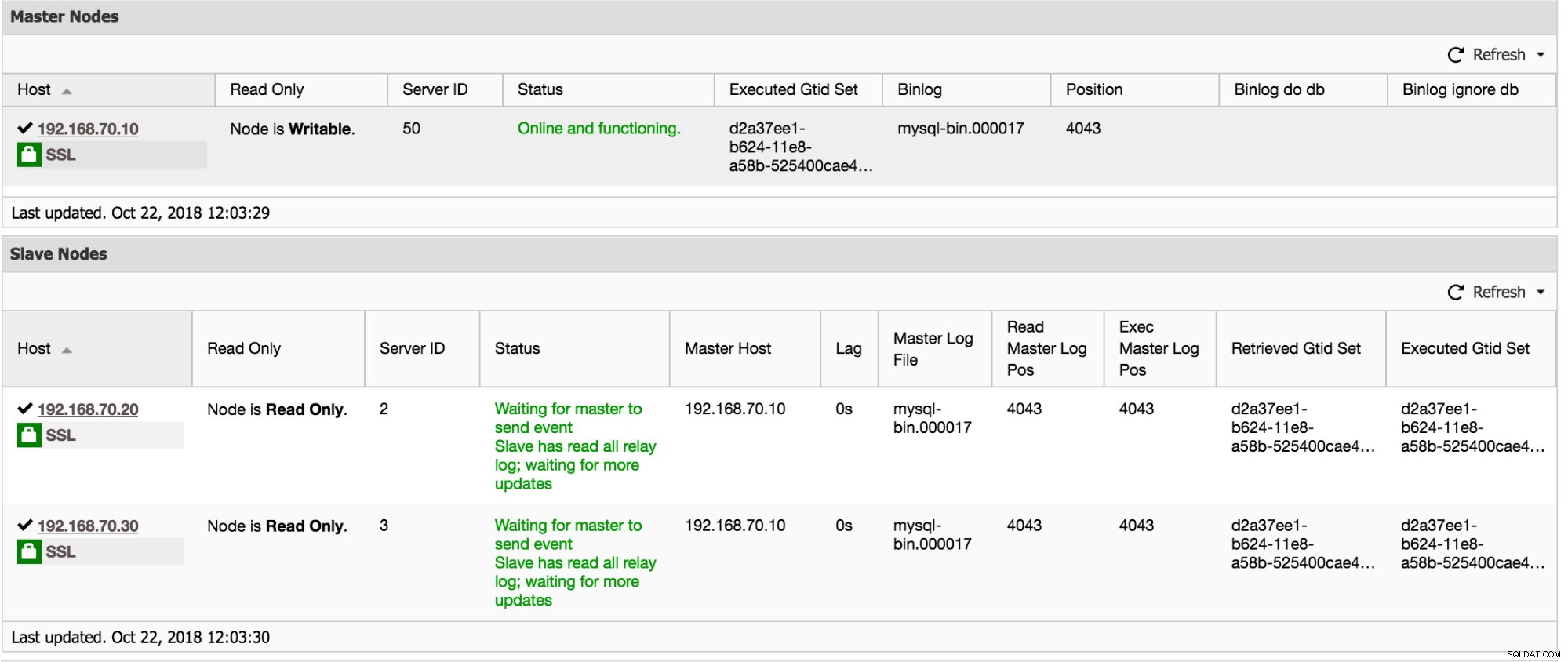
Det första i den här instrumentpanelen, den ger dig den viktigaste informationen du kan behöva om din replikas hälsa. Se grafen nedan:

I grund och botten kommer den att visa dig slavtrådens IO_Thread, SQL_Thread, replikeringsfel och om den har read_only-variabeln aktiverad. Från exempelskärmdumpen ovan visar all information att min slav 192.168.70.20 är frisk och fungerar normalt.
Dessutom har ClusterControl information att samla in också om du går över till Cluster -> Översikt. Scrolla ner och du kan se grafen nedan:
En annan plats att se replikeringsinställningen är topologivyn för replikeringsinställningen, tillgänglig på Cluster -> Topology. Det ger, med en snabb blick, en bild av de olika noderna i installationen, deras roller, replikeringsfördröjning, hämtat GTID med mera. Se grafen nedan:
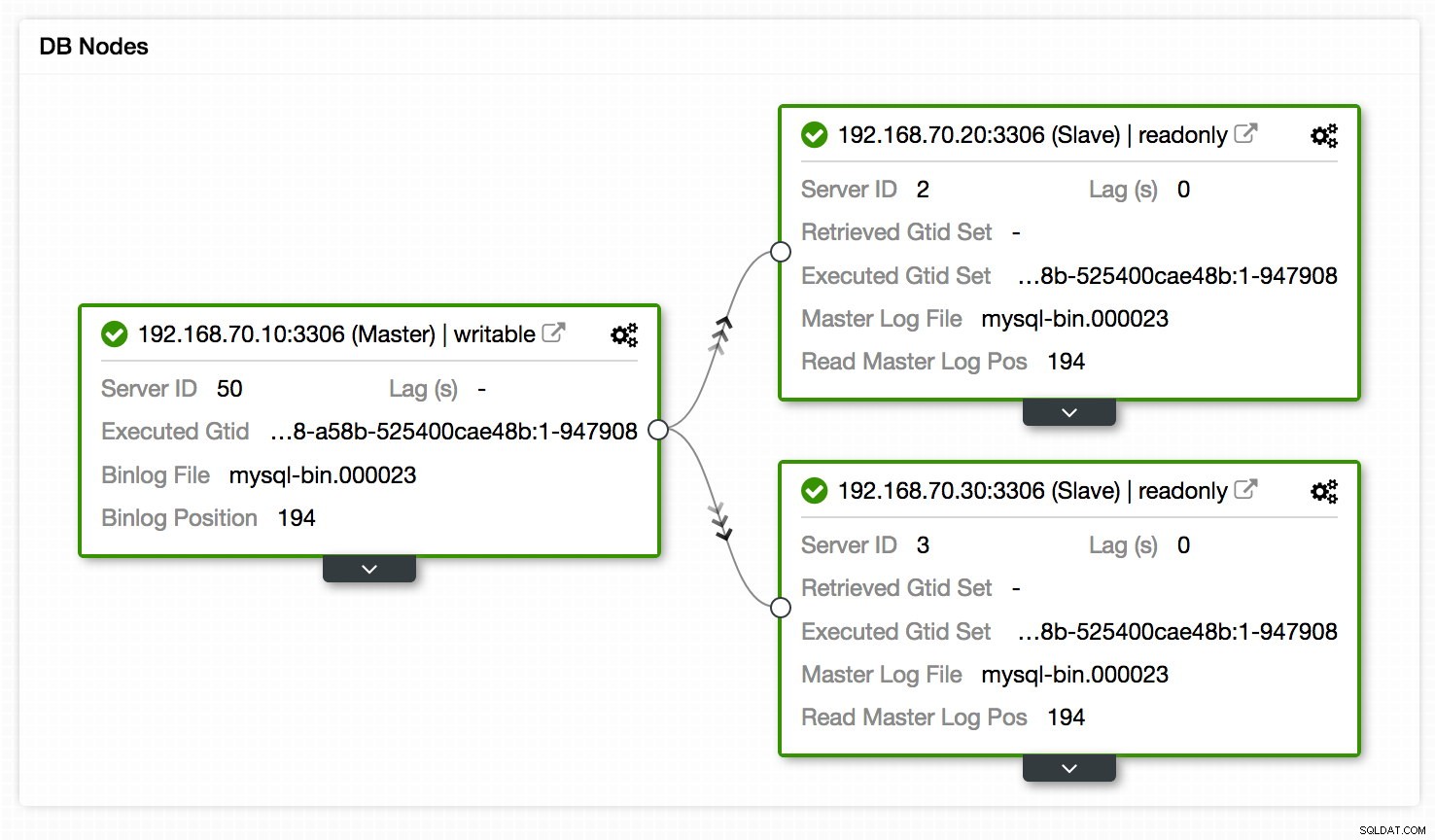
Utöver detta visar Topology View också alla olika noder som utgör en del av ditt databaskluster oavsett om det är databasnoderna, belastningsutjämnare (ProxySQL/MaxScale/HaProxy) eller skiljemän (garbd), såväl som kopplingarna mellan dem. Noderna, anslutningarna och deras status upptäcks av ClusterControl. Eftersom ClusterControl kontinuerligt övervakar noderna och behåller tillståndsinformation, återspeglas eventuella ändringar i topologin i webbgränssnittet. Om fel på noder rapporteras kan du använda den här vyn tillsammans med SCUMM Dashboards och se vilken påverkan som kan ha orsakat det.
Topology View har viss likhet med Orchestrator där du kan hantera noderna, ändra master genom att dra och släppa objektet på önskad master, starta om noder och synkronisera data. För att veta mer om vår topologivy föreslår vi att du läser vår tidigare blogg - "Visualisera din klustertopologi i ClusterControl".
Låt oss nu fortsätta med graferna.
-
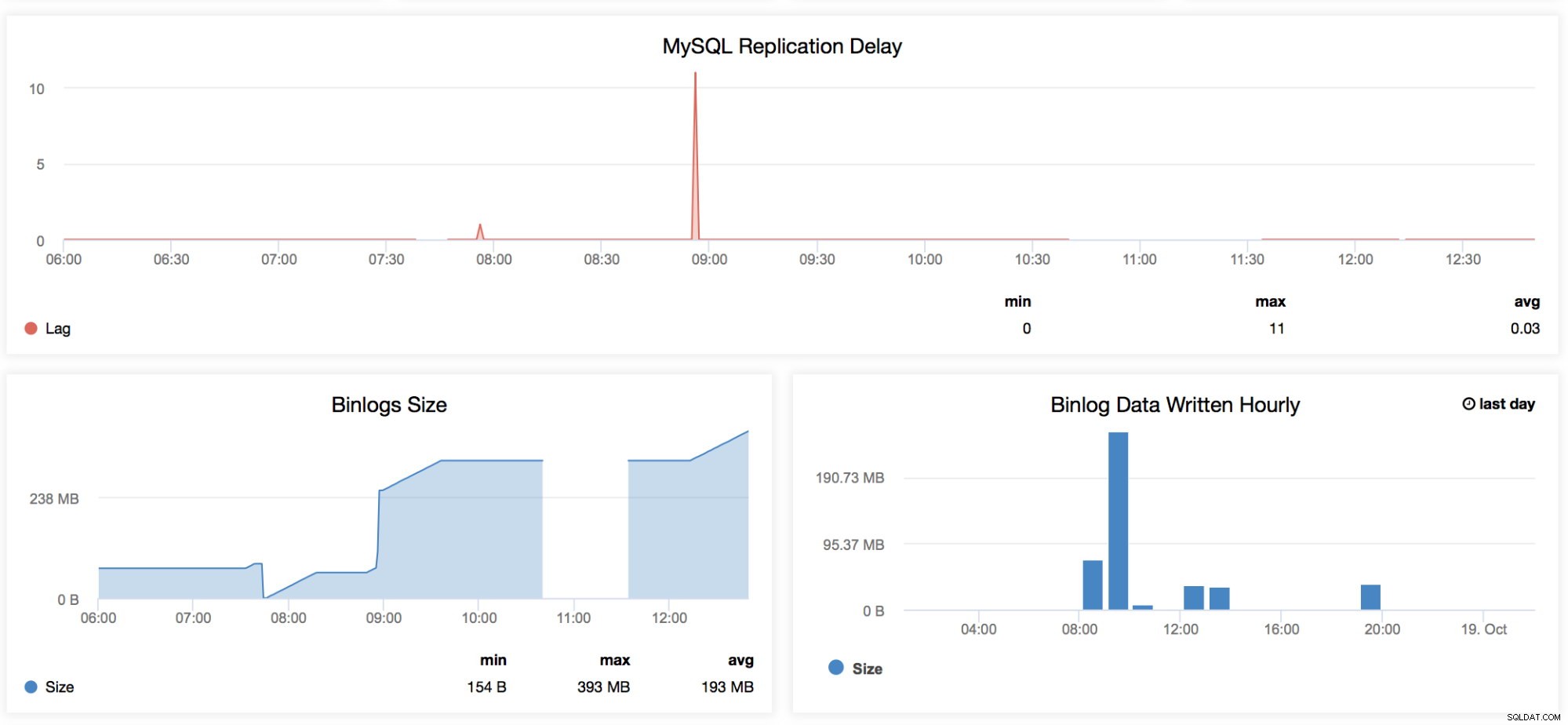
MySQL-replikeringsfördröjning
Den här grafen är mycket bekant för alla som hanterar MySQL, särskilt de som arbetar dagligen med sin master-slave-installation. Det här diagrammet har trenderna för alla fördröjningar som registrerats för ett specifikt tidsintervall som anges i den här instrumentpanelen. Närhelst vi vill kontrollera den periodiska nedgångstiden som vår replik har, så är den här grafen bra att titta på. Det finns vissa tillfällen då en replik kan släpa av konstiga anledningar som att din RAID har en degraderad BBU och behöver en ersättning, en tabell har ingen unik nyckel men inte på mastern, en oönskad genomsökning av hela tabellen eller full index-skanning, eller en dålig fråga lämnades igång av en utvecklare. Detta är också en bra indikator för att avgöra om slavfördröjning är en nyckelfråga, då kanske du vill dra fördel av parallell replikering. -
Binlog Storlek
Dessa grafer är relaterade till varandra. Grafen Binlog Size visar hur din nod genererar den binära loggen och hjälper till att bestämma dess dimension baserat på den tidsperiod du skannar. -
Binlog-data skrivs varje timme
Binlog-data skrivs varje timme är en graf baserad på den aktuella dagen och föregående dag som registrerats. Detta kan vara användbart när du vill identifiera hur stor din nod är som tar emot skrivningar, som du senare kan använda för kapacitetsplanering.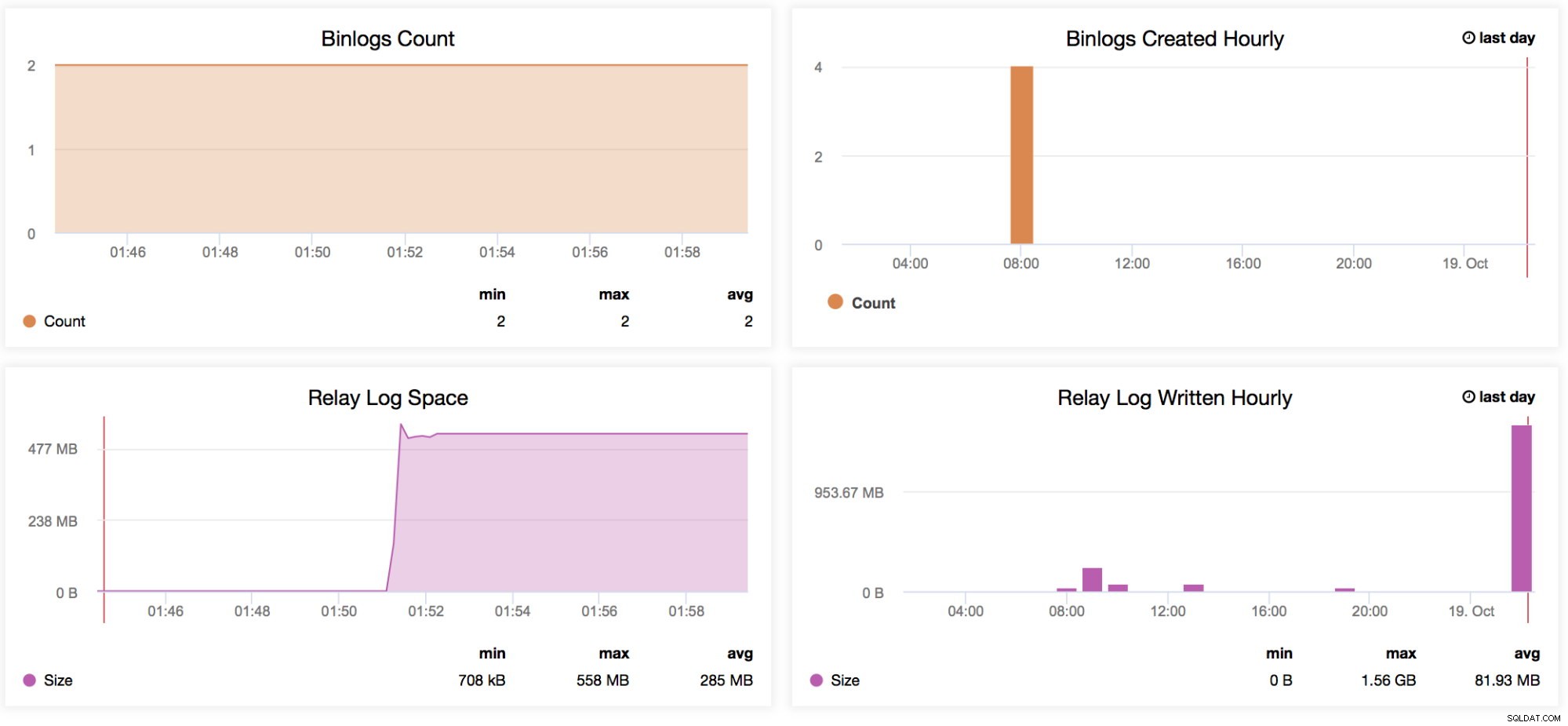
-
Binlogs Count
Låt oss säga att du förväntar dig hög trafik för en viss vecka. Du vill jämföra hur stora skrivningar som går igenom din herre och slavar med föregående vecka. Den här grafen är mycket användbar för denna typ av situation - För att bestämma hur höga de genererade binära loggarna var på själva mastern eller till och med på slavarna om variabeln log_slave_updates är aktiverad. Du kan också använda den här indikatorn för att bestämma dina genererade binära loggdata för master kontra slavar, speciellt om du filtrerar några tabeller eller scheman (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) på dina slavar som genererades medan log_slave_updates är aktiverat. -
Binlogs skapade varje timme
Det här diagrammet är en snabb översikt för att jämföra dina binlogs skapade varje timme från igår och dagens datum. -
Reläloggutrymme
Den här grafen fungerar som basen för de genererade reläloggarna från din replik. När den används tillsammans med MySQL-replikeringsfördröjningsgrafen hjälper den till att bestämma hur stort antal reläloggar som genereras är, vilket administratören måste ta hänsyn till när det gäller disktillgänglighet för den aktuella repliken. Det kan orsaka problem när din slav släpar efter kraftigt och genererar ett stort antal reläloggar. Detta kan konsumera ditt diskutrymme snabbt. Det finns vissa situationer som, på grund av ett högt antal skrivningar från mastern, kommer att släpa slaven/replikan enormt, så att generering av en stor mängd loggar kan orsaka några allvarliga problem på den repliken. Detta kan hjälpa operationsteamet när de pratar med sin ledning om kapacitetsplanering. -
Relälogg skrivs varje timme
Samma som reläloggutrymmet men lägger till en snabb översikt för att jämföra dina reläloggar skrivna från igår och dagens datum.
Slutsats
Du lärde dig att användning av SCUMM för att övervaka din MySQL-replikering ger mer produktivitet och effektivitet till driftteamet. Att använda funktionerna vi har från tidigare versioner i kombination med graferna som tillhandahålls med SCUMM är som att gå till gymmet och se enorma förbättringar av din produktivitet. Detta är vad SCUMM kan erbjuda:övervakning på steroider! (nu förespråkar vi inte att du ska ta steroider när du går till gymmet!)
I del 3 av den här bloggen kommer jag att diskutera InnoDB Metrics och MySQL Performance Schema Dashboards.