ClusterControl 1.9.0 släpptes den 16 juli 2021 med många nya funktioner introducerade i systemet. Dessa funktioner inkluderar Redis Management and Monitoring, ett nytt agentbaserat frågeövervakningssystem för MySQL och PostgreSQL, pgBackRest-förbättringar samt några andra förbättringar som listas här. Vi är ganska exalterade eftersom detta är vår andra stora release för 2021 efter ClusterControl 1.8.2.
Om du är ny på ClusterControl är Query Monitor en av våra användbara funktioner där du kan få information om din databas arbetsbelastning. Query Monitor ger en sammanfattning av frågebehandling över alla noder i klustret, vilket blir oumbärligt när du märker eller upplever prestandaförsämring. Alla Query Monitoring-funktioner är inte desamma för varje databastyp, till exempel är Query Monitor för MySQL-baserad annorlunda än Query Monitor för PostgreSQL.
Att ha en förstklassig prestanda är ingen ursäkt, särskilt när du kör verksamhetskritiska applikationer förutom att ge den bästa användarupplevelsen.
I det här blogginlägget kommer vi att diskutera vad den nya Query Monitor har erbjudit och gå igenom några av stegen för hur man aktiverar den för både MySQL-baserade och PostgreSQL-baserade system. Utan vidare, låt oss komma igång!
Vår nya MySQL Query Monitor
Om du redan har uppdaterat den här nya versionen kommer du förmodligen att märka några av ändringarna i gränssnittet. Den nya Query Monitor kommer att ha en extra flik som heter Översikt. Frågeöversikten är en plats där du kan få en allmän översikt över alla frågor för ditt databaskluster. För MySQL-baserade databasinstanser måste du aktivera parametern "performance_schema" för alla dina MySQL-instanser innan frågeagenten kan installeras. Du skulle se följande skärmdump om du klickar på fliken Översikt över frågor:

Om du inte har aktiverat "performance_schema" kommer du inte att kunna använda den här instrumentpanelen. Du kan aktivera parametern genom Cluster -> Hantera -> Konfigurationer och redigera filen /etc/my.cnf för alla värdar. Se till att uppdatera värdet till följande:
performance_schema =PÅ
När detta är gjort måste du göra en rullande omstart av klustret från klustrets åtgärdslista så att ändringen träder i kraft. Utan en rullande omstart kan frågeagenten inte installeras.
Naturligtvis kan du också göra det manuellt från dina databasnoder, det beror på dina önskemål. Om du väljer det manuella sättet kan du SSH till din databasinstans och redigera /etc/my.cnf. Om du vill SSH från ClusterControl UI kan du enkelt göra det från nodåtgärdslistan som i skärmdumpen nedan:
Nu bör du lägga märke till följande skärmdump efter att den rullande omstarten är klar och allt du behöver göra är att klicka på Install Query Monitor Agent:
Det borde bara ta ett tag innan du kunde se den nya översiktspanelen för frågor som följande skärmdump:
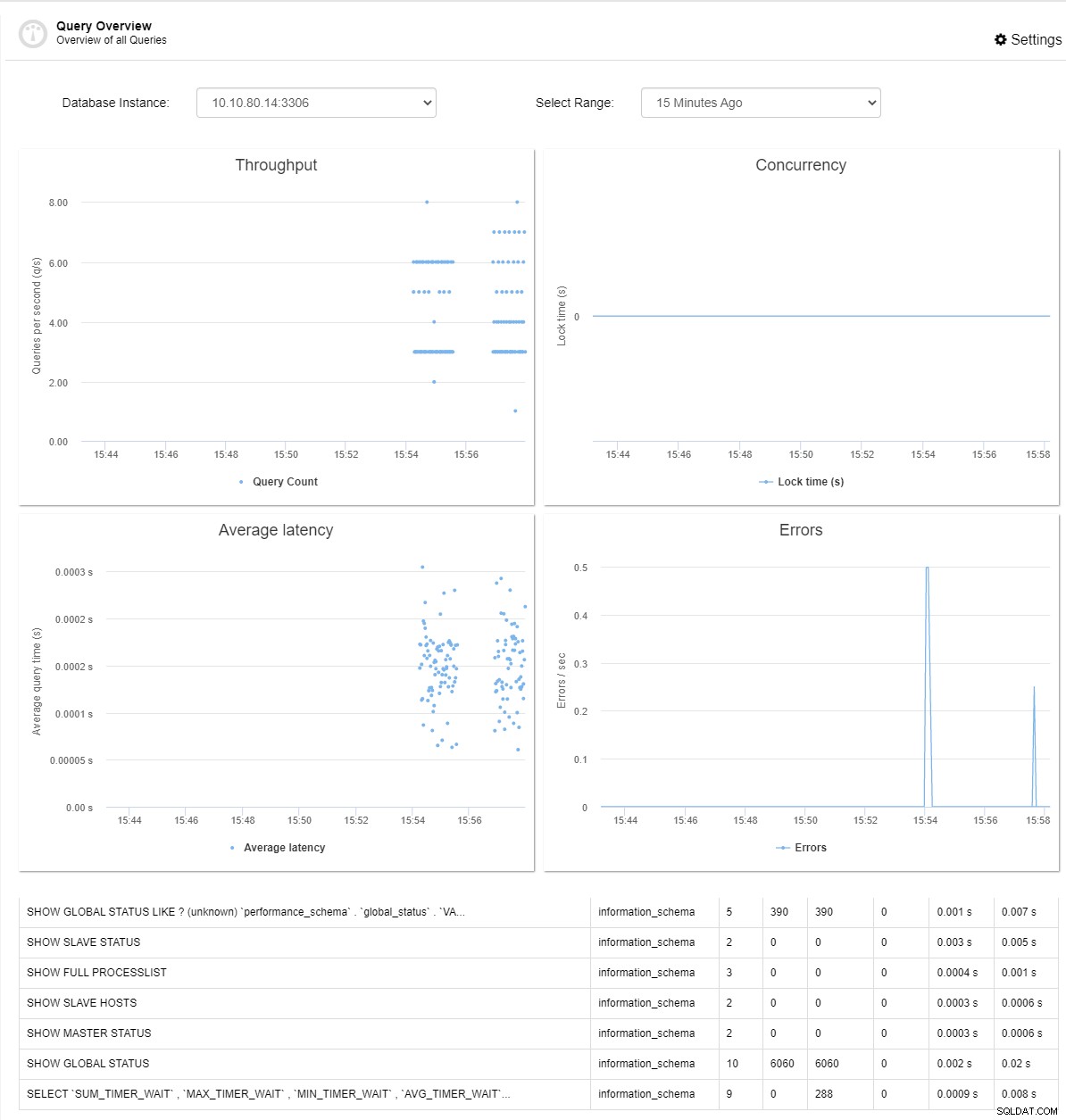
I vår nya översiktsöversikt över frågor finns det några variabler som du kan övervaka och hämta mätvärdena från. Här kunde du se genomströmning, samtidighet, genomsnittlig latens, fel samt listan över frågorna längst ner. Förklaringen till var och en av dem är följande:
-
Genomströmning - Fråga per sekund (q/s)
-
Den övergripande förmågan att bearbeta data som mäts i frågor per sekund, transaktion per sekund eller den genomsnittliga svarstiden .
-
-
Samtidighet - Låstid(er)
-
Antalet samtidiga frågor, speciellt INSERT-frågan. Det mäts i sekunder.
-
-
Genomsnittlig fördröjning - Genomsnittlig frågetid (er)
-
Latensfördelningen av uttalanden som körs inom denna MySQL-instans.
-
-
Fel - Fel (sek)
-
Antalet frågefel per sekund för klustret.
-
Du kan välja vilken databasinstans som du vill se mätvärdena samt tidsramen från 15 minuter upp till 4 timmar för var och en av dem. Med det här alternativet kan du enkelt identifiera vad som händer i det specifika fallet.
Längst ner på instrumentpanelen kan du märka att det finns en lista över frågor som för närvarande körs för ditt kluster. Här kan du se informationen om frågesammanfattningen, schemat, antal, rader och även körningstiden.
I motsats till den äldre versionen (1.8.2) är detta en helt ny instrumentpanel och den kommer att vara mycket användbar när du vill ha en överblick över klustret. Med mätvärdena här kommer du att kunna vidta nödvändiga åtgärder om du märker att ditt klusterprestanda inte är optimalt.
Ny frågeövervakare för PostgreSQL
Samma process måste göras för PostgreSQL:när du uppgraderar ClusterControl till 1.9.0 måste du installera frågeövervakaren innan du kan få mätvärdena för frågeöversikten. Du kommer att se utdata som liknar den nedan:
Men för PostgreSQL behöver du inte aktivera någon parameter som du behöver för MySQL-baserade databaser kan du genast installera agenten från instrumentpanelen. Installationen bör ta ett tag innan du kan se översiktspanelen för frågor som nedan.
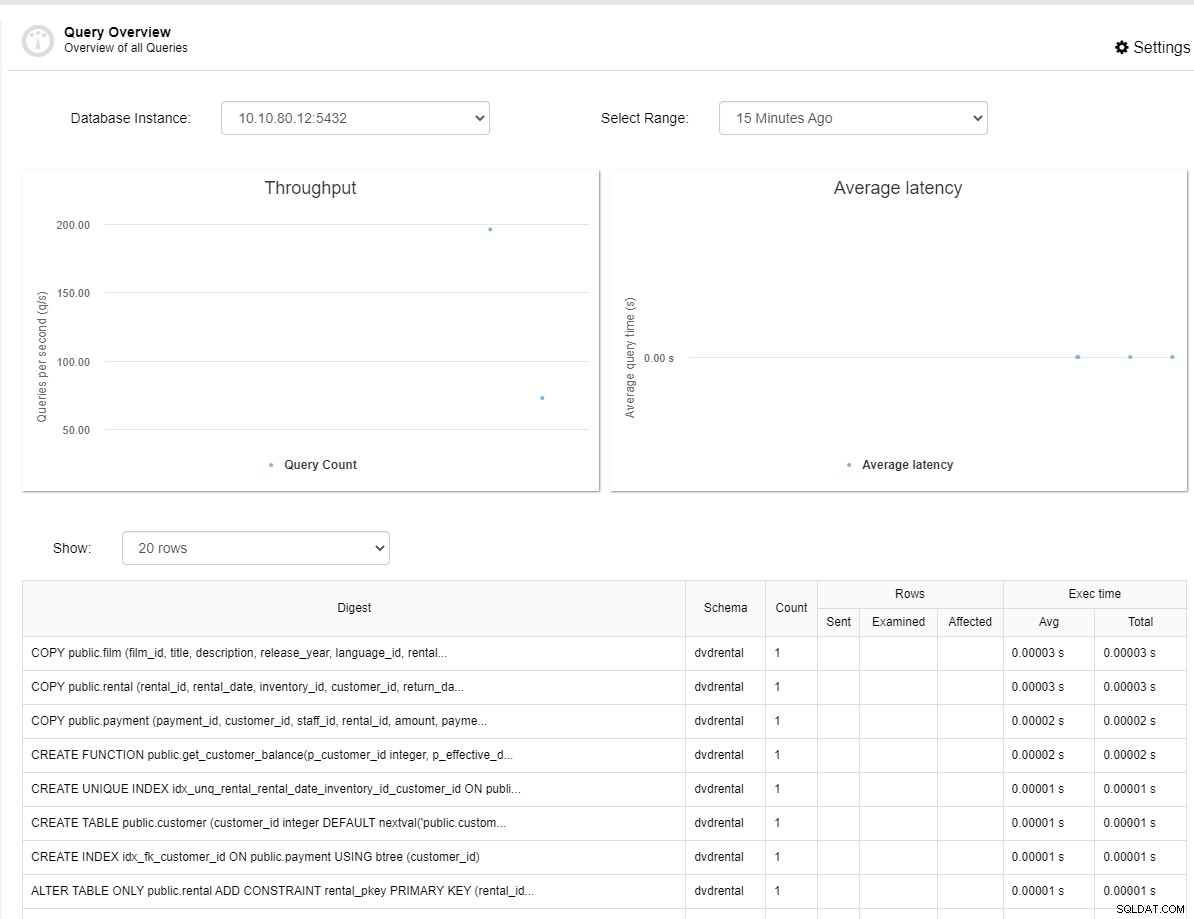
Som du kan se är instrumentpanelen lite annorlunda än MySQL instrumentpanel där det bara finns 2 mätvärden som är genomströmning och genomsnittlig latens. Som MySQL-baserad översiktsöversiktspanel, kan du också välja den databasinstans som du vill se mätvärdena såväl som tidsintervallet.
Du kan också se listan över frågorna nedan över mätvärdena som visas i skärmdumpen ovan. I frågelistan kan du se sammanfattning, schema, antal, rader och körningstid för varje fråga.
Sluta tankar
Vi tror att den nya Query Monitor är ganska användbar när du vill se vad som händer med dina frågor i en databasinstans. Föreställ dig att du har några noder:du kan enkelt byta databasinstans från frågeöversikten för att se statistiken. Med det här alternativet kan du veta specifikt vad som händer på var och en av dina databasinstanser.
För MySQL-baserade instanser, kom ihåg att aktivera/aktivera "performance_schema" för var och en av databasinstanserna innan du installerar frågeagenten och fortsätter för att se översikten.
Vad tycker du om vår nya Query Monitor? Gillar du den och tycker att den är användbar? Låt oss veta i kommentarsfältet nedan.