Ett av de mest populära sätten att uppnå hög tillgänglighet för MySQL är replikering. Replikering har funnits i många år och blev mycket mer stabil med introduktionen av GTID. Men även med dessa förbättringar kan replikeringsprocessen bryta av olika anledningar - till exempel när master och slav är osynkroniserade eftersom skrivningar skickades direkt till slaven. Hur felsöker du replikeringsproblem och hur åtgärdar du dem?
I det här blogginlägget kommer vi att diskutera några av de vanliga problemen med replikering och hur man fixar dem med ClusterControl. Låt oss börja med den första.
Replikeringen stoppades med något fel
De flesta MySQL DBA:er kommer vanligtvis att se den här typen av problem minst en gång under sin karriär. Av olika anledningar kan en slav skadas eller kanske sluta synkronisera med mastern. När detta händer är det första du ska göra för att starta felsökningen att kontrollera felloggen för meddelanden. För det mesta är felmeddelandet lätt att spåra i felloggen eller genom att köra frågan SHOW SLAVE STATUS.
Låt oss ta en titt på följande exempel från VISA STATUSSLAV:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Vi kan tydligt se att felet är relaterat till Fick fatal error 1236 från master vid läsning av data från binär logg:'Kunde inte hitta GTID-tillstånd som begärts av slav i några binlogfiler. Förmodligen är slavtillståndet för gammalt och obligatoriska binlogfiler har rensats.'. Med andra ord, vad felet säger oss är i huvudsak att det finns inkonsekvens i data och de nödvändiga binära loggfilerna har redan raderats.
Detta är ett bra exempel där replikeringsprocessen slutar fungera. Förutom VISA SLAVSTATUS kan du också spåra statusen på fliken "Översikt" i klustret i ClusterControl. Så hur fixar man detta med ClusterControl? Du har två alternativ att prova:
-
Du kan försöka starta slaven igen från "Nod Action"
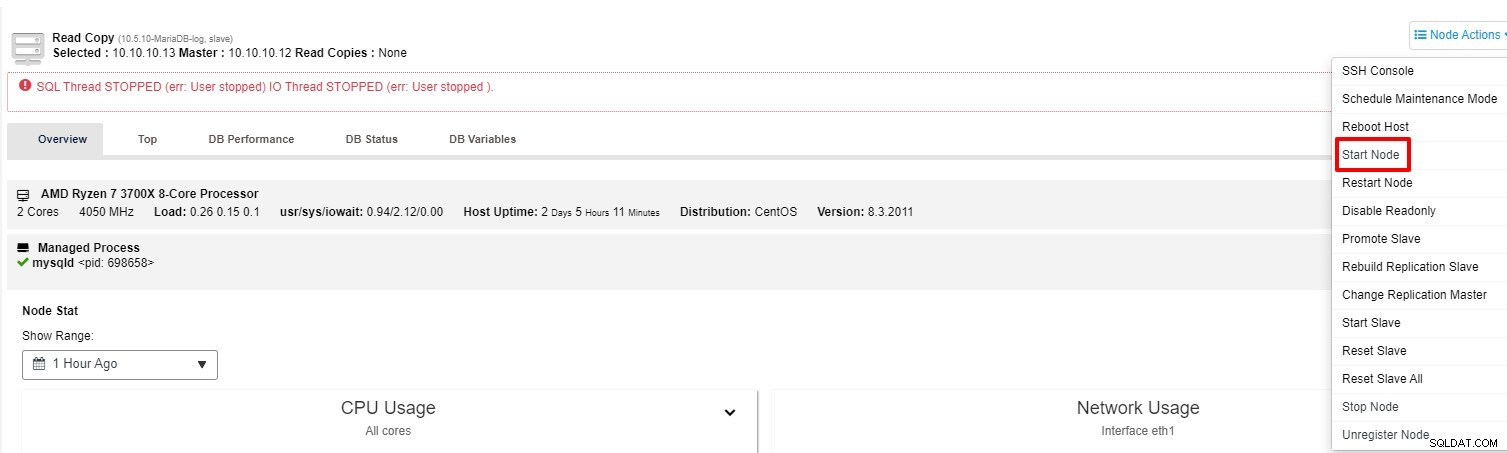
-
Om slaven fortfarande inte fungerar kan du köra "Rebuild Replication Slave"-jobbet från "Nodåtgärd"
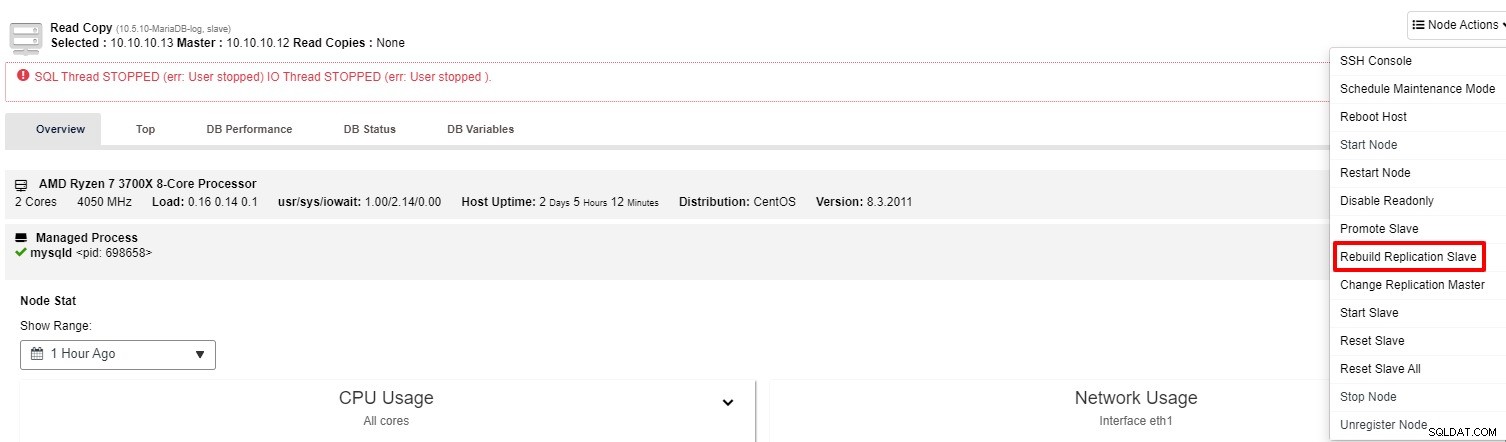
För det mesta kommer det andra alternativet att lösa problemet. ClusterControl tar en säkerhetskopia av mastern och bygger om den trasiga slaven genom att återställa data. När data har återställts ansluts slaven till mastern så att den kan komma ikapp.
Det finns också flera manuella sätt att bygga om slav enligt listan nedan, du kan också hänvisa till den här länken för mer information:
-
Använda Mysqldump för att bygga om en inkonsekvent MySQL-slav
-
Använda Mydumper för att bygga om en inkonsekvent MySQL-slav
-
Använda en ögonblicksbild för att bygga om en inkonsekvent MySQL-slav
-
Använda en Xtrabackup eller Mariabackup för att bygga om en inkonsekvent MySQL-slav
Främja en slav för att bli en mästare
Med tiden måste operativsystemet eller databasen korrigeras eller uppgraderas för att upprätthålla stabilitet och säkerhet. En av de bästa metoderna för att minimera stilleståndstiden, speciellt för en större uppgradering, är att marknadsföra en av slavarna som ska bemästras efter att uppgraderingen har gjorts framgångsrikt på just den noden.
Genom att utföra detta kan du peka din applikation till den nya mastern och master-slave-replikeringen kommer att fortsätta att fungera. Under tiden kan du också fortsätta med uppgraderingen på den gamla mastern med sinnesfrid. Med ClusterControl kan detta utföras med några få klick endast förutsatt att replikeringen är konfigurerad som Global Transaction ID-baserad eller GTID-baserad för kort. För att undvika dataförlust är det värt att stoppa alla programförfrågningar om den gamla mastern fungerar korrekt. Detta är inte den enda situationen där du kan marknadsföra slaven. I händelse av att masternoden är nere kan du också utföra den här åtgärden.
Utan ClusterControl finns det några steg för att marknadsföra slaven. Vart och ett av stegen kräver några frågor för att köras också:
-
Ta ner mastern manuellt
-
Välj den mest avancerade slaven för att bli en mästare och förbered den
-
Återanslut andra slavar till den nya mastern
-
Ändra den gamla mästaren till att vara en slav
Ändå är stegen för att marknadsföra slav med ClusterControl bara några få klick:Cluster> Noder> välj slavnod> Marknadsför slav enligt skärmdumpen nedan:
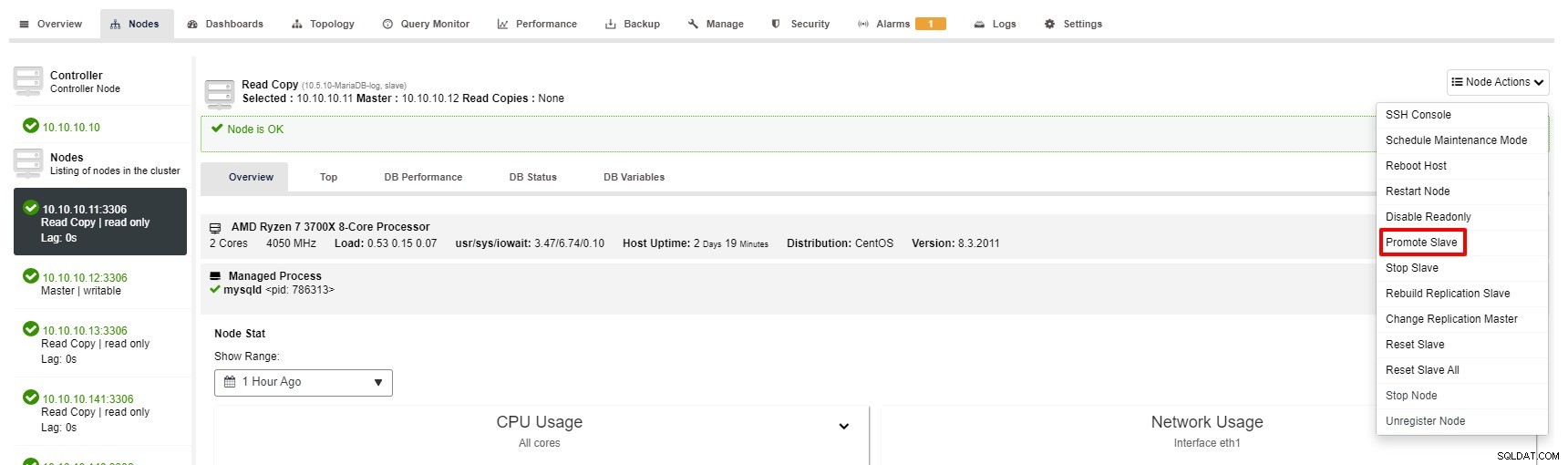
Master blir otillgänglig
Föreställ dig att du har stora transaktioner att köra men databasen är nere. Det spelar ingen roll hur försiktig du är, detta är förmodligen den allvarligaste eller mest kritiska situationen för en replikeringsinställning. När detta händer kan din databas inte acceptera en enda skrivning, vilket är dåligt. Dessutom kommer din(a) applikation(er), naturligtvis inte att fungera korrekt.
Det finns några orsaker eller orsaker som leder till det här problemet. Några av exemplen är hårdvarufel, OS-korruption, databaskorruption och så vidare. Som DBA måste du agera snabbt för att återställa huvuddatabasen.
Tack vare klusterfunktionen "Auto Recovery" som är tillgänglig i ClusterControl kan failover-processen automatiseras. Det kan aktiveras eller inaktiveras med ett enda klick. Som namnet säger, vad det kommer att göra är att ta upp hela klustertopologin när det behövs. Till exempel måste en master-slav-replikering ha minst en master vid varje given tidpunkt, oavsett antalet tillgängliga slavar. När mastern inte är tillgänglig kommer den automatiskt att marknadsföra en av slavarna.
Låt oss ta en titt på skärmdumpen nedan:
I skärmdumpen ovan kan vi se att "Autoåterställning" är aktiverat för både kluster och nod. Lägg märke till att den aktuella huvud-IP-adressen är 10.10.10.11 i topologin. Vad händer om vi tar ner masternoden för testsyften?
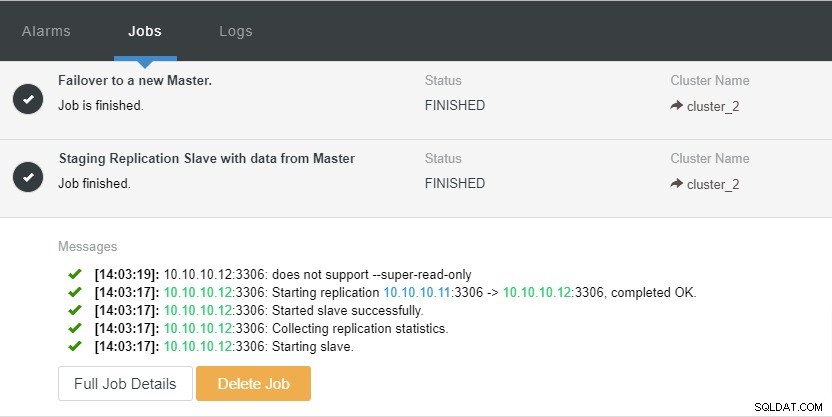
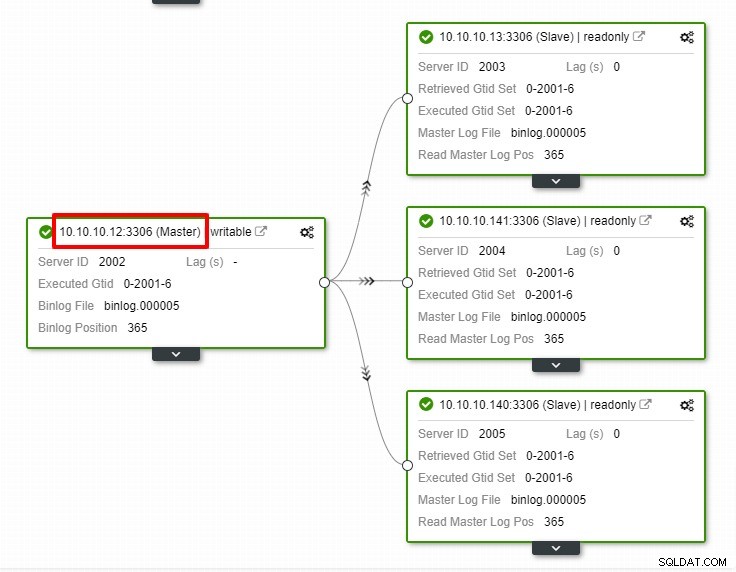
Som du kan se är slavnoden med IP 10.10.10.12 automatiskt befordrad till master, så att replikeringstopologin omkonfigureras. Istället för att göra det manuellt, vilket naturligtvis kommer att innebära många steg, hjälper ClusterControl dig att underhålla din replikeringsinställning genom att ta bort krånglet från händerna.
Slutsats
I alla olyckliga händelser med din replikering är korrigeringen mycket enkel och mindre krångel med ClusterControl. ClusterControl hjälper dig att snabbt återställa dina replikeringsproblem, vilket ökar upptiden för dina databaser.