Benchmarks är en av de aktiviteter som databasadministratörer utför. Du kör dem för att se hur din hårdvara beter sig, du kör dem för att se hur din applikation och databas fungerar tillsammans under press. Du kör dem i många olika situationer. Låt oss prata lite om dem, vilka utmaningar du kommer att möta, vilka problem du bör undvika.
Typer av riktmärken
Varje benchmark är olika. De tjänar olika syften och det måste tas med i beräkningen när du planerar att köra en. Generellt sett kan du definiera två huvudtyper av benchmark:syntetiskt benchmark och, låt oss kalla det, ett "riktigt" benchmark.
Syntetiska riktmärken är vanligtvis verktyg som simulerar någon form av arbetsbelastning. Det kan vara en OLTP-arbetsbelastning som i fallet med Sysbench, det kan vara något "standard" benchmark som i TPC-C eller TPC-H. Vanligtvis är tanken att ett sådant riktmärke simulerar någon form av arbetsbelastning och det kan vara användbart om din verkliga arbetsbelastning kommer att följa samma mönster. Den kan också användas för att bestämma hur din blandning av hårdvara och databaskonfiguration fungerar tillsammans under en viss typ av arbetsbelastning. Fördelarna med syntetiska riktmärken är ganska tydliga. Du kan köra dem överallt, de beror inte på någon speciell installation eller schemadesign. Jo, det gör de men de kommer på verktyg för att ställa in allt från den tomma databasservern. Den största nackdelen är att detta inte är din arbetsbörda. Om du ska köra OLTP-tester med Sysbench måste du komma ihåg att din applikation aldrig kommer att bli Sysbench. Det kan också köra OLTP-arbetsbelastning men frågemixen kommer att vara annorlunda. Aldrig, under några omständigheter, kommer syntetiska benchmark att berätta exakt hur din applikation kommer att bete sig på en given hårdvara/konfigurationsmix.
I andra änden av spektrumet har vi, vad vi kallade, riktmärken för "verkliga världen". Vad vi menar här med det är ett riktmärke som använder en datamängd och frågor relaterade till din applikation. Den har inte alltid en fullständig datamängd och fullständig frågemix. Du kanske vill fokusera på vissa delar av din applikation, men huvudtanken bakom det är att du vill förstå den exakta interaktionen mellan applikationen, hårdvaran och databaskonfigurationen, antingen generellt eller i någon speciell aspekt.
Som vi nämnde ovan har vi två huvudsakliga, olika typer av riktmärken, men de har fortfarande några vanliga saker du måste tänka på när du försöker köra riktmärkena.
-
Bestämma vad du vill testa
För det första är benchmarking för att köra benchmarks meningslöst. Det måste utformas för att faktiskt åstadkomma något. Vad vill du få ut av benchmarkkörningen? Vill du finjustera frågorna? Vill du justera konfigurationen? Vill du bedöma skalbarheten av din stack? Vill du förbereda din stack för en högre belastning? Vill du göra en generisk konfigurations-tweking för ett nytt projekt? Vill du bestämma de bästa inställningarna för din hårdvara? Det är exempel på mål du kanske vill uppnå. Var och en av dessa kommer att kräva ett annat tillvägagångssätt och olika riktmärken.
-
Gör en ändring i taget
Vad du än testar och justerar är det av yttersta vikt att du bara gör en konfigurationsändring åt gången. Detta är verkligen kritiskt. Riktmärket är avsett att ge dig en uppfattning om prestandan. Frågor per sekund, latens, 99 percentil, allt detta berättar hur snabbt du kan utföra frågorna och hur stabil och förutsägbar arbetsbelastningen är. Det är lätt att se om ändringen du gjorde i konfigurationen, hårdvaran eller frågemixen ändrar något:mätvärdena från riktmärket kommer att se annorlunda ut. Saken är den att om du gör ett par ändringar samtidigt finns det inget sätt att säga vilken som är ansvarig för det totala resultatet. Det kan gå ännu längre än så. Låt oss säga att du har ändrat två värden i databaskonfigurationen. Värde A och B. Den totala förbättringen är 20 %, vilket är ganska bra för bara en konfigurationsändring. Under huven innebar dock förändringen av värde A en förbättring på 30 % medan ytterligare förändring av värde B satte tillbaka det till 20 %. Med flera ändringar samtidigt kan du bara observera deras gemensamma inverkan, detta är inte sättet att korrekt bestämma resultatet av varje enskild förändring du gjort. Visst, detta ökar avsevärt tiden du kommer att spendera på att köra riktmärket, men det är så det är.
-
Gör flera benchmarkkörningar
Datorer är komplexa system i sig. De har flera komponenter som interagerar med varandra:minne, CPU, disk, nätverk. Låt oss sedan lägga till denna virtualisering, containerisering. Sedan mjukvara - operativsystem, applikation, databas. Lager över lager över lager över lager av element som interagerar på något sätt. Det är inte lätt att förutse dess beteende. Tja, man kan säga att det är nästan omöjligt att exakt förutsäga beteendet hos sådana komplexa system. Detta är anledningen till att det inte räcker att köra en benchmarkkörning för att dra slutsatserna. Tänk om, omedvetet för dig, något element, helt orelaterade till det du vill testa, påverkar den övergripande prestandan? Hög belastning på en annan virtuell dator som finns på samma värd. Någon annan server strömmar säkerhetskopiering över nätverket. Detta kan tillfälligt påverka prestandan och skeva benchmarkresultaten. Om du kör bara en benchmarkkörning kommer du att få felaktiga resultat. Det är därför den bästa praxisen är att utföra flera pass av ett riktmärke och sedan ta bort den långsammaste och snabbaste, med ett genomsnitt av de andra.
-
En bild är värd tusentals ord
Tja, detta är i stort sett en mycket korrekt beskrivning av benchmarking. Om bara möjligt, generera alltid grafer. Spåra helst mätvärdena under benchmark så ofta du kan. En sekunds granularitet borde räcka för de flesta fall. För att undvika att skriva tusentals ord tar vi med det här exemplet. Vad tycker du är mer användbart? Denna uppsättning benchmark-utgångar som representerar genomsnittlig QPS för vart och ett av 10 pass, varje pass tar 600 sekunder
11650.52
11237.97
11550.16
11247.08
11177.78
11163.76
11131.47
11235.06
11235.59
11277.25
Eller denna handling:
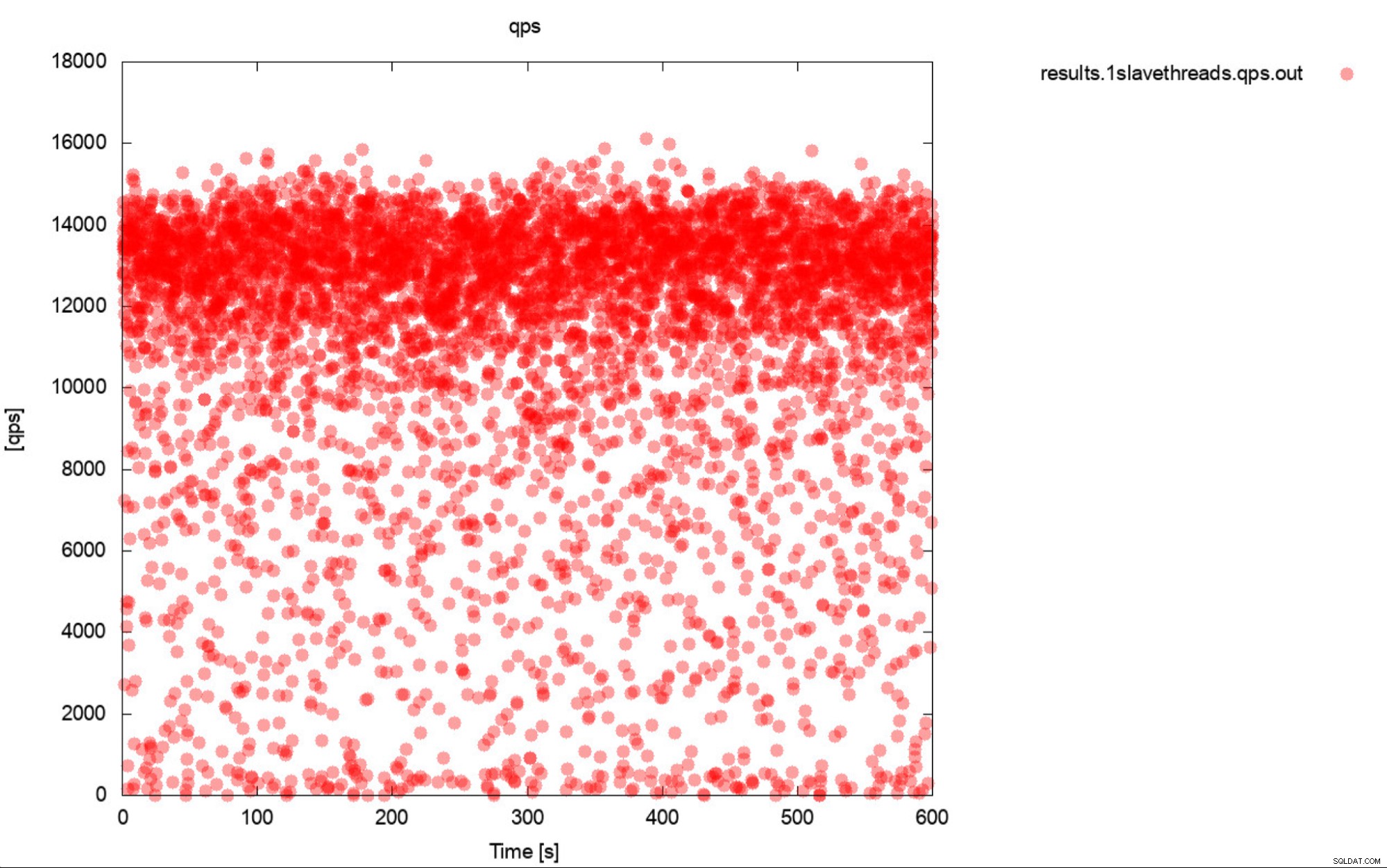
Den genomsnittliga QPS är 11k men verkligheten är att prestandan är över hela plats, inklusive nedgångar till 0 frågor som körs inom en sekund, och det är definitivt något du vill arbeta och förbättra på produktionssystemen.
-
Frågor per sekund är inte det viktigaste måttet
Du kanske tror att fråga per sekund är prestandas heliga graal eftersom det representerar hur många frågor en databas kan köra inom en sekund. Sanningen är att det inte är det viktigaste måttet, särskilt om vi talar om genomsnittlig produktion från ett riktmärke. QPS representerar genomströmningen men ignorerar latensen. Du kan försöka driva en stor mängd frågor men sedan väntar du på att de ska ge resultat. Detta är inte vad användarna förväntar sig av applikationen. Användare förväntar sig stabil prestanda. Det behöver inte vara blixtsnabbt, men när en åtgärd tar en sekund att slutföra, tenderar vi att förvänta oss att det alltid tar den 1 sekunden att utföra den åtgärden. Om det av någon anledning börjar ta längre tid tenderar människor att bli oroliga. Detta är den främsta anledningen till att vi tenderar att föredra latens, särskilt dess P99 (99:e percentilen) som ett mer tillförlitligt mått. Latency berättar hur länge applikationen fick vänta på resultatet från databasen. P99 berättar för oss latens att 99% av frågorna har lägre än. Låt oss säga att vi har en P99 på 100 ms, det betyder att 99% av frågorna returnerar resultat inte långsammare än 100 ms. Om vi ser att P99-latensen är låg betyder det att nästan alla frågor återkommer snabbt och presterar på ett stabilt, förutsägbart sätt. Detta är något som våra användare vill se.
-
Förstå vad som händer innan du drar slutsatser
Sista punkten som vi har i denna korta blogg men vi skulle säga att den är den viktigaste. Du kommer att se olika udda och oväntade resultat och beteenden under benchmarks. Ännu värre, du kan se ganska vanliga, repetitiva men fortfarande felaktiga resultat. De flesta av dem kan spåras till beteendet hos databasen eller hårdvaran. Detta är verkligen avgörande – innan du tar resultatet för givet bör du kunna förklara beteendet och beskriva vad som hände. Vi vet att det inte är lätt och vi vet att det verkligen kräver databasspecifik kunskap, särskilt kunskap relaterad till databasens interna delar. Vi vet att människor i den verkliga världen vanligtvis inte bryr sig om detta, de vill bara få resultat. Saken är, särskilt för fall där du försöker förbättra prestandan genom konfiguration eller hårdvarujusteringar, att förstå vad som hände under huven gör att du kan välja rätt sätt på vilket din justering ska fortsätta. Det gör det också möjligt att avgöra om riktmärket som har utförts kan ha någon mening. Testar vi verkligen rätt element? Ett exempel skulle vara ett test som körs över nätverket (eftersom du inte vill använda lokala CPU-kärnor i databasnoden för benchmarkverktyg). Det är ganska troligt att själva nätverket och softirq CPU-belastning kommer att vara den begränsande faktorn, långt tidigare än du skulle träffa "förväntade" flaskhalsar som CPU-mättnad. Om du inte är medveten om din miljö och dess beteende kommer du att mäta din nätverksprestanda för att överföra stora datamängder, inte CPU-prestandan.
Som du kan se är benchmarking inte det lättaste att göra, du måste ha en nivå av medvetenhet om vad som händer, du bör ha en ordentlig plan för vad du ska göra och vad vill du testa? I nästa del av den här bloggen kommer vi att gå igenom några av de verkliga testfallen. Vad kan gå fel, vilka problem vi kommer att stöta på och hur vi ska hantera dem.