I våra tidigare Hybrid Cloud-bloggar nämner vi ofta att ett av de primära alternativen för att använda Hybrid Cloud-topologiinställningen är att använda detta som ditt katastrofåterställningsmål. Det är vanligt för en organisationsstruktur att en Disaster Recovery Plan (DRP) alltid åtgärdas innan den arkitektoniska implementeringen av din databasinstallation, antingen i molnet eller på plats. Du kanske tror att allt kommer att misslyckas på ett oförutsägbart sätt och kan påverka din verksamhet tragiskt om det inte tas upp och förstås på rätt sätt. För att övervinna dessa utmaningar krävs en effektiv DRP (Disaster Recovery Plan), för vilken ditt system är väl konfigurerat enligt din applikation, infrastruktur och affärskrav. Nyckeln till framgång i dessa typer av situationer är hur snabbt vi kan åtgärda eller återhämta oss från problemet.
Medan DRP tar itu med katastrofförhållandena kommer Business Continuity att se till att DRP alltid är testad och i drift när det behövs. Dina katastrofåterställningsalternativ för dina databaser måste säkerställa kontinuerlig drift och gränser till förväntningarnas gränser. Det måste vara i linje med din önskade RTO och RPO. Det är absolut nödvändigt att se till att produktionsdatabaser är tillgängliga för applikationerna även under katastrofer; annars kan det bli en dyr affär. DBA:er, arkitekterna, måste säkerställa att databasmiljöer kan uthärda katastrofer och är SLA-kompatibla för katastrofåterställning. Databasinstallationer måste konfigureras korrekt för att säkerställa att katastrofer inte påverkar databasens tillgänglighet och kontinuitet.
Alternativ för katastrofåterställning
Ditt PostgreSQL-kluster måste konfigureras med ett systematiskt tillvägagångssätt som förbinder sig till bästa praxis och som är acceptabel för industristandarder. Tillsammans med de systematiska tillvägagångssätten hjälper följande processer eller mekanismer dig att säkerställa att din PostgreSQL som distribueras till ett hybridmoln har dessa närvaro:
-
Failover/Switchover
-
Automatisk säkerhetskopiering
-
Mycket tillgänglig
-
Lastbalansering
-
Mycket distribuerad miljö
Failover/Switchover
Failover är en automatiserad process om din master misslyckas; antingen hot standby eller varm standby server befordras till rollen som primär/master. Det är en bästa praxis som ger en hög tillgänglighetsmiljö att ha åtminstone en sekundär nod för att fungera som en kandidat för en failover-nod. När den primära servern misslyckas, bör standby-servern påbörja failover-procedurerna, och sedan ska den sekundära eller standby-servern ta rollen som en master. Ett failover-system använder i vanliga fall minst två servrar, som fungerar som primär och standby. Dess anslutningskontroll assisteras av en hjärtslagsmekanism som gör non-stop kontroller och verifierar om båda är i gott skick och kommunikationen är levande. Men i vissa fall kan anslutningen ge ett falskt larm. Därför, i vissa inställningar och miljöer, finns närvaron av ett tredje system, såsom en övervakningsnod, på ett separat nätverk eller datacenter. Detta är ett idiotsäkert alternativ för att förhindra olämplig eller oönskad failover. En idiotsäker verifieringsnod kan ha extra funktioner och kontroller, vilket ökar komplexiteten. Den här installationen kräver fullständiga och rigorösa tester för att säkerställa att failover görs rätt när det sker en förändring i implementeringen. Detta är också viktigt för att förhindra eventuell försämring av din PostgreSQL
Låt oss säga att du har ditt sekundära eller standby-kluster på ett annat datacenter med en annan hårdvaruinställning; du kanske inte vill göra failover abrupt, särskilt om det inte är ett idealiskt fall på grund av bara en falsk positiv. Men i det här scenariot måste din dataåterställningsmålnod eller -kluster ha samma resurser och specifikationer som din primära nod eller kluster. Om ditt dataåterställningsmål finns i ett offentligt moln och det primära är lokalt, se till att det redan har täckts in i din kapacitetsplanering och att resurser har nästan samma specifikationer för att undvika oönskade resultat.
När du använder och förbereder din failover-mekanism i ditt PostgreSQL-kluster inom ett hybridmoln måste du se till att ditt verktyg passar perfekt för att utföra jobbet som är tänkt att uppnå. Det finns verktyg från tredje part som inte är buntade i PostgreSQL när det gäller förväg failover. Till exempel finns det ClusterControl, pg_auto_failover av CitusData (c/o Microsoft), Pgpool-II, Bucardo och andra. Dessa avancerade verktyg ger nodfäktning eller känd som STONITH (skjut den andra noden i huvudet). Detta säkerställer att din misslyckade primära eller huvudnod ska undvika att acceptera skrivningar eller komma tillbaka online som dess tidigare tillstånd för att betjäna normala transaktioner. Det här problemet är allmänt känt som scenario med split-brain. Den förlorar datasynkronisering på grund av ett fel (hårdvaru- eller resursnivå) men fortfarande agerar dina primära servrar, som förmodligen bara är en primär server, som om de gör vanliga mottagare av dataskrivförfrågningar vilket orsakar datakorruption i hela kluster.
Automatisk säkerhetskopiering
Säkerhetskopiering ger alltid hög säkerhet och skydd mot dataförlust. Säkerhetskopiering maximerar din RPO eftersom det hjälper till att minimera dataförlust när en katastrof inträffar. Saker du måste tänka på och förbereda för din automatiska säkerhetskopiering omfattar din säkerhetskopieringsenhet/hårdvara, säkerhetskopieringsdataredundans, säkerhet, prestanda, hastighet och datalagring.
Backupenhet
Du måste ha det bästa valet för din backup-enhet här. Hastighet, betydande lagringsvolym och hög tillgänglighet kan vara ditt önskade val. Vissa förlitar sig på SAN- eller NAS-lagring eller sprider ut sina data till andra tredjepartsleverantörer av backuplagring. Det är viktigt att din säkerhetskopieringsenhet erbjuder snabbhet för att skriva och läsa data, särskilt om du använder komprimering och kryptering för dina data i vila. Dekompression och dekryptering kräver resurser, så du måste tänka på när du måste använda dataåterställning. Under det här tillståndet måste du bestämma att du måste uppnå din maximala RPO och förbinda det uppnåbara SLA (Service-Level Agreement) till dina kunder. Det är också idealiskt att du kanske måste isolera din säkerhetskopia från ditt lokala nätverk eller lagra den på en avlägsen plats. Ett alternativt tillvägagångssätt är att samarbeta med tredjepartsleverantörer. Att lagra din säkerhetskopia i molnet kan till exempel vara ett alternativ, och deras anläggning är mycket sofistikerad och uppfyller dina krav.
Redundans för säkerhetskopiering
Att sprida dina data på flera platser är en idealisk lösning. Detta stärker dina chanser för dataåterställning, till exempel ett mänskligt fel eller ett logiskt programvarufel som får dig att radera gamla kopior av säkerhetskopior men av misstag radera hela viktiga säkerhetskopior. I vissa sofistikerade miljöer, som lagring i en molnmiljö som Amazon S3, Cloud Storage by Google eller Azure Blob Storage erbjuder replikering av din lagrade fil. Detta ger mer redundans och kan ställas in på ett flexibelt sätt som passar dina krav.
Mycket tillgänglig
Ett mycket tillgängligt PostgreSQL-kluster i ett hybridmoln säkerställer alltid att din databaskommunikation säkerställer drifttid. Det ideala fallet med hög tillgänglighet beror på mätningen av din tillgänglighet. I det här fallet kan en vanlig inställning för en PostgreSQL som distribueras i ett hybridmoln vara antingen din databas som är värd i ett offentligt moln kan vara ditt sekundära kluster som fungerar som ditt dataåterställningskluster om det primära klustret misslyckas eller drabbas av en nätverkskatastrof och kan ta mycket stillestånd. I vissa inställningar är det möjligt att det sekundära klustret som ligger i det offentliga molnet kanske inte är exakt lika sofistikerat som det primära, låt oss säga att detta är ditt lokala eller privata moln. Din applikation kan leka för att begränsa antalet besökare eller trafik som kan ansluta till din databas. Den här typen av scenario kan minska din installationskostnad, men detta beror naturligtvis bara på dina krav. Om din applikationstyp är massiv och måste ta emot normala till livliga trafiksituationer utan avbrott, se till att dina sekundära klusterresurser måste vara lika kraftfulla som de primära för att säkerställa hög tillgänglighet, dvs. 99,9999999%.
För att uppnå ett högst tillgängligt PostgreSQL-kluster i en hybridmolnmiljö måste du ha en failover-mekanism. I händelse av ett misslyckande och ett primärt kluster eller primär server går ner, kan en sekundär eller standby-server sedan ta rollen som en master, beroende på vilken plats den kan vara. Det viktigaste är funktionaliteten, och prestandan, speciellt ur applikations- eller klientsynpunkt, påverkas inte alls eller åtminstone väldigt minimal.
Lastbalansering
Lastbalanseringsmekanism för ditt PostgreSQL-kluster underlättar din hybridmolninstallation, som är mer hanterbar och mindre riskabel, särskilt när hög trafikbelastning uppstår. I många situationer får en server en kraftig hög belastning som gör att servern får panik. Detta leder till att servern inte kan användas på grund av upptagna resurser som förbrukas av många trådar som körs i bakgrunden. Denna situation kan förbättras genom att fixa dåliga frågor och designarkitekturen för din databas. Detta bör inkludera hur du fördelar läsningen mot skrivbelastning och en djupgående förståelse för dina applikationskrav som master-master-installation eller bara en master men skala den vertikalt för att ge högre beräknings- och minnesresurser. Det finns också ett stort urval av tredjepartsverktyg som pgbouncer och Pgpool II för att hjälpa din PostgreSQL-distribution i en hybrid molnmiljö.
Mycket distribuerad miljö
Skalbarhetsmässigt, att vara mycket distribuerad på flera platser eller olika molnleverantörer (på plats eller privata och offentliga moln) ger mer flexibilitet och tolerabilitet i en hybridmolnmiljö och detta är utmärkt för katastrofåterställning. Det är flexibelt när det behöver failover på en viss molnplats som är gynnsam för naturkatastrofer eller katastrofer, särskilt om din utsedda region där ditt primära kluster finns för närvarande är ödelagt eller påverkat av en naturlig orsak. Detta är en oundviklig orsak som du måste förstå och vara pålitlig i den nuvarande situationen. Din applikation och dina kunder måste betjänas kontinuerligt non-stop. Detta tjänar syftet att vara tillgängligt offentligt i molnet samtidigt som det fungerar i en privat eller lokal miljö. Denna inställning ger mer komplexitet och kräver avancerad kunskap om databassidan och säkerhet och nätverk. Optimering och justering är avgörande för framgång här eftersom det är mycket viktigt att samtidigt som det tjänar en skärpt säkerhet för att kapsla in din data när du reser på internet, måste prestanda bevisas stabiliseras och inte påverkas av den implementerade installationen.
På grund av komplexiteten i installationen är ett verktyg idealiskt för att hantera driftsättningen och underlätta dina databasers övergripande status, övervaka den ena aspekten av ditt kluster men på hela nivån från on-prem, privat moln, och om det offentliga molnet. Alla inställningar måste hållas på en hanterbar och okomplicerad nivå så att det i händelse av larm och varningar är lätt att åtgärda och åtgärda problemet korrekt och i tid.
ClusterControl för katastrofåterställning i en hybridmolnmiljö
ClusterControl tillåter organisationen eller företagen att hantera databasen med flexibilitet och minska installationens övergripande komplexitet. ClusterControl erbjuder failover, automatiserad säkerhetskopiering, ger en mycket tillgänglig installation, lastbalansering och stöder en distribuerad miljödistribution, vilket gör det lättare att lägga till noder antingen i ett offentligt moln eller privat eller lokalt.
ClusterControl Auto Recovery
Den automatiska återställningen av ClusterControl representerar massor av failover-mekanism och återställningsegenskaper, särskilt när en nod går ner eller ett kluster går in i ett försämrat tillstånd. Detta kan enkelt göras enligt skärmdumpen nedan:
Säkerhetskopiera och återställa
ClusterControl har också en säkerhetskopierings- och återställningsfunktion som låter dig hantera din säkerhetskopia, skapa en säkerhetskopia, schemalägga en säkerhetskopia och återställa en säkerhetskopia. Att hantera din säkerhetskopia är mycket enkelt och att skapa eller schemalägga en säkerhetskopia är enkelt men erbjuder även avancerade alternativ. Det erbjuder också alternativ för molnsäkerhetskopiering som gör att du kan ha säkerhetskopiering av dataredundans, vilket stärker dina alternativ för katastrofåterställning. Se nedan:
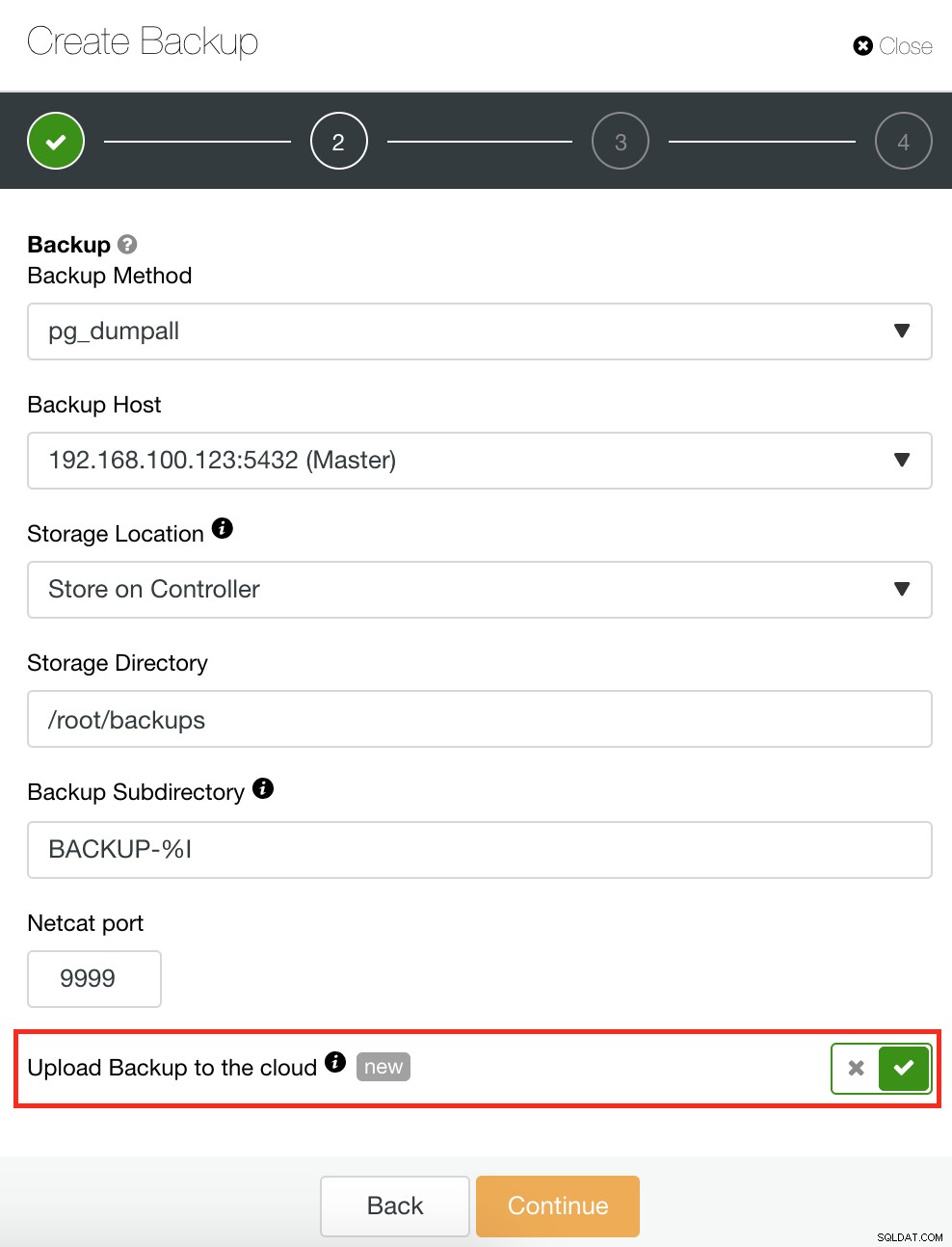
Som visas nedan ger hantering av din säkerhetskopia ett enkelt användargränssnitt där du kan välja vilken säkerhetskopia du vill återställa, eller så kanske du måste släppa. ClusterControl backup låter dig välja en lagringsperiod, så om du har en lång lista kan några av dessa raderas när den når sin lagringsperiod. 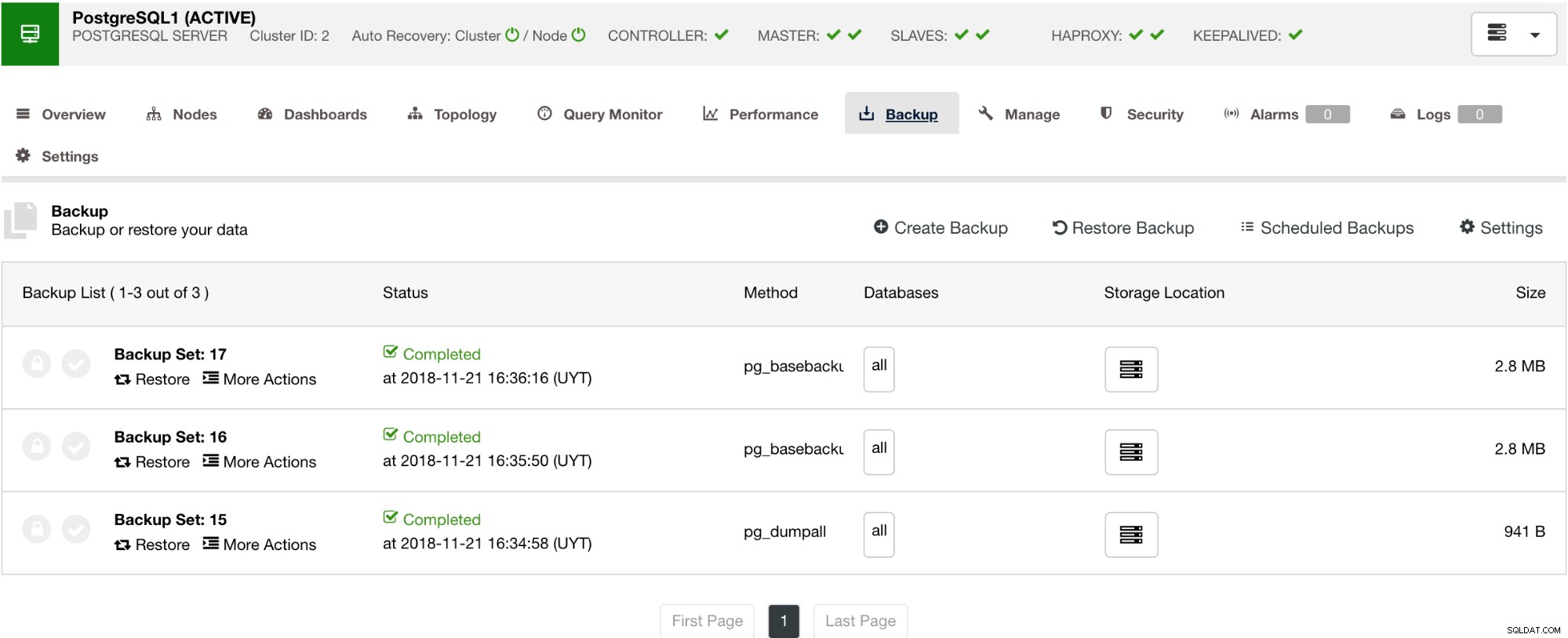
Stöder mekanismer för hög tillgänglighet (HA) och lastbalansering (LB)
Du behöver inte ställa in manuellt eller ens undersöka några sätt att lägga till hög tillgänglighet i ditt PostgreSQL-kluster. Det finns ett enkelt och bekvämt sätt att få jobbet gjort med ClusterControl. Om du kan se exemplet på skärmdumpen har den en HAProxy och Keepalved-inställning. Se skärmdump nedan:
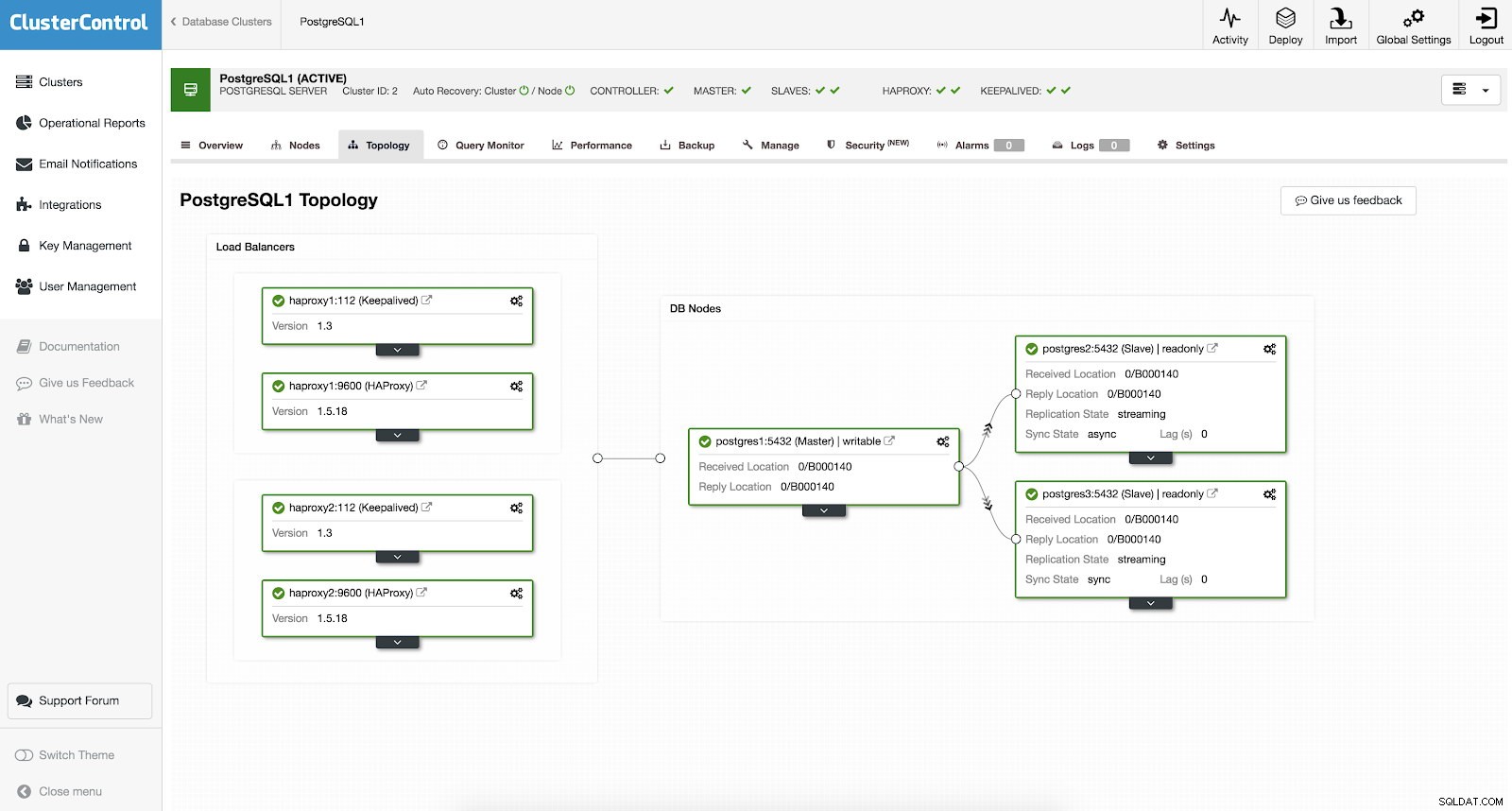
Inställning av hög tillgänglighet med ClusterControl kan göras genom att gå igenom
Stöder distribuerad miljö
Om du vill ha jämn distribution från lokalt eller privat moln till offentligt moln, stöder ClusterControl även molndistribution. Men för ett PostgreSQL-kluster och du planerar att ha en sekundär slav som bor på ett annat moln, kan du skapa ett slavkluster som visas nedan,
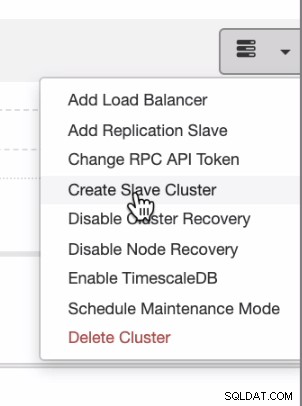
och du kan komma fram med slutresultatet som visas nedan,

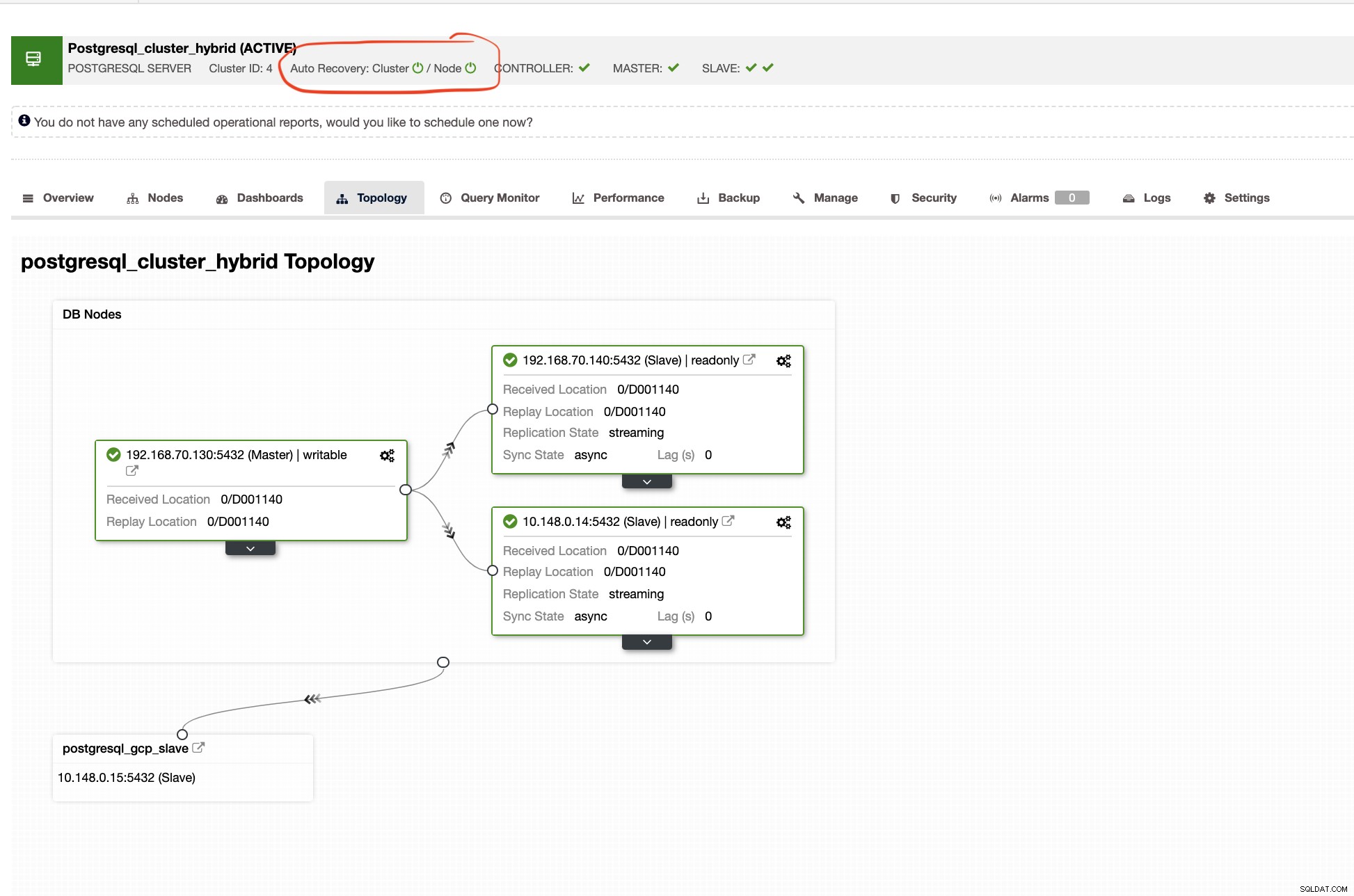
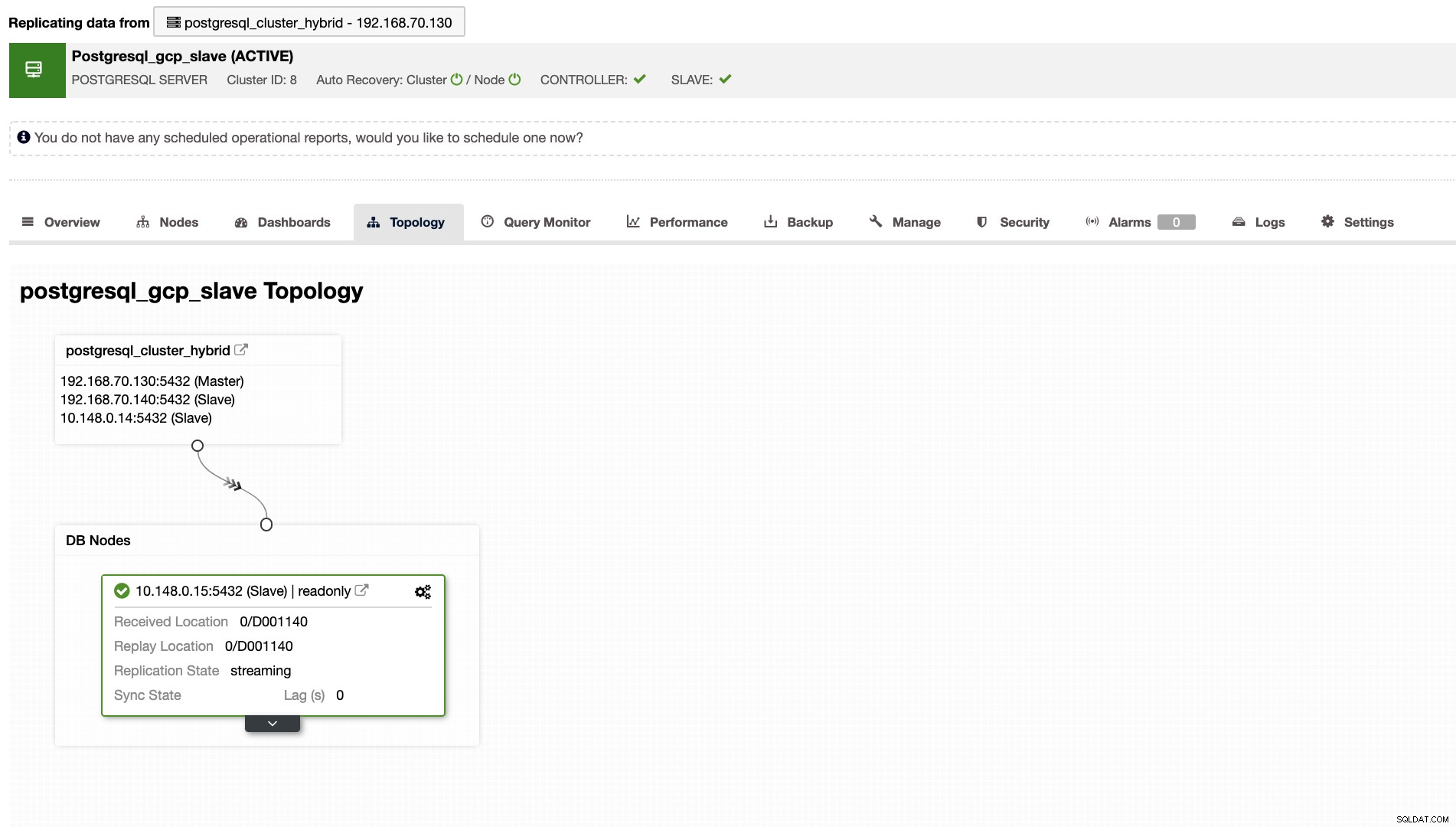
ClusterControl visar dig också rätt topologi för ditt kluster närhelst du har en hybridmolnmiljö. Se följande nedan,
Medan i slavklustret kommer topologin att visa dess ursprungsträd och avslöja sin herre. Slaven här visas som den är placerad i ett separat nätverk huvudsakligen i Google Cloud, medan mastern är lokal.
Slutsats
Det är acceptabelt att erkänna att en hybridmolninstallation, speciellt med PostgreSQL-kluster, tillför komplexitet. Du måste ha rätt verktyg med alternativ för att stödja din katastrofåterställningsplanering. Dessa är mycket viktiga för att rädda och undvika ditt företag från den potentiella katastrofen med ekonomisk skada och att förlora kundernas förtroende. Investera i din tekniks rätt verktyg och färdigheter så kommer du att rädda ditt företag från negativ påverkan.