Översikt
Oracle Data Mining (ODM) är en komponent i Oracle Advanced Analytics Database Option. ODM innehåller en uppsättning avancerade datautvinningsalgoritmer som är inbäddade i databasen som gör att du kan utföra avancerad analys av dina data.
Oracle Data Miner är en förlängning av Oracle SQL Developer, en grafisk utvecklingsmiljö för Oracle SQL. Oracle Data Miner använder datautvinningstekniken inbäddad i Oracle Database för att skapa, exekvera och hantera arbetsflöden som kapslar in datautvinningsoperationer. Arkitekturen för ODM illustreras i figur 1.
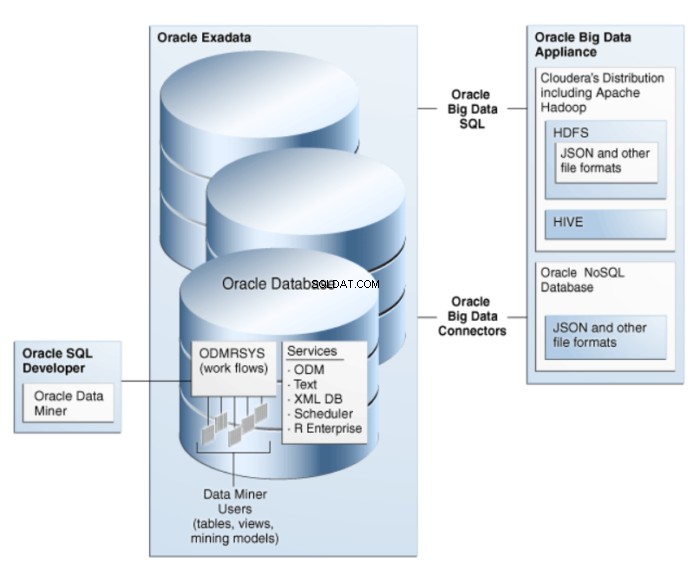
Figur 1:Oracle Data Mining Architecture for Big Data
Algoritmer implementeras som SQL-funktioner och utnyttjar styrkorna i Oracle-databasen. SQL-datautvinningsfunktionerna kan bryta transaktionsdata, aggregering, ostrukturerad data, t.ex. CLOB-datatyp (med Oracle Text) och rumslig data.
Varje dataminingfunktion specificerar en klass av problem som kan modelleras och lösas. Datautvinningsfunktioner delas i allmänhet in i två kategorier:övervakade och oövervakade.
Begreppen övervakad och oövervakad inlärning härrör från vetenskapen om maskininlärning, som har kallats ett underområde för artificiell intelligens.
Övervakat lärande är också känt som riktat lärande. Inlärningsprocessen styrs av ett tidigare känt beroende attribut eller mål. Riktad datautvinning försöker förklara beteendet hos målet som en funktion av en uppsättning oberoende attribut eller prediktorer.
Oövervakat lärande är oriktat. Det finns ingen skillnad mellan beroende och oberoende attribut. Det finns inget tidigare känt resultat för att vägleda algoritmen för att bygga modellen. Oövervakat lärande kan användas i beskrivande syfte.
Oracle Data Mining Övervakade Algoritmer
| Teknik | Tillämpning | Algorithms (kort beskrivning) |
|---|---|---|
Klassificering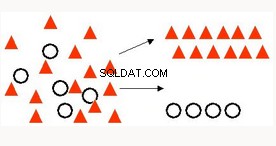 | Mest använda tekniken för att förutsäga ett specifikt resultat, t.ex. identifiering av cancertumörceller, sentimentanalys, narkotikaklassificering, skräppostdetektering. | Generaliserade linjära modeller Logistisk regression - klassisk statistisk teknik tillgänglig i Oracle-databasen i en högpresterande, skalbar, paralliserad implementering (gäller alla OAA ML-algoritmer). Stöder text och transaktionsdata (gäller nästan alla OAA ML-algoritmer) Naiva Bayes - Snabb, enkel, allmänt användbar. Stöd för vektormaskin - Maskininlärningsalgoritm, stöder text och breda data. Decision Tree - Populär ML-algoritm för tolkning. Ger mänskligt läsbara "regler". |
Regression | Teknik för att förutsäga ett kontinuerligt numeriskt utfall såsom astronomisk dataanalys, generera insikter om konsumentbeteende, lönsamhet och andra affärsfaktorer, beräkna orsakssamband mellan parametrar i biologiska system. | Generaliserade linjära modeller Multipel regression - klassisk statistisk teknik men nu tillgänglig i Oracle-databasen som en högpresterande, skalbar, paralliserad implementering. Stöder åsregression, skapande av funktioner och val av funktioner. Stöder text och transaktionsdata. Stöd för Vector Machine - Maskininlärningsalgoritm, stöder text och breda data. |
Attributvikt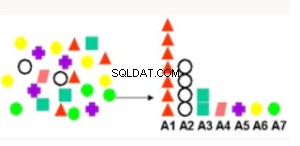 | Rangerar attribut efter styrkan av relationen med målattributet. Användningsfall inkluderar att hitta faktorer som mest förknippas med kunder som svarar på ett erbjudande, faktorer som mest förknippas med friska patienter. | Minsta beskrivningslängd – betraktar varje attribut som en enkel prediktiv modell av målklassen och ger relativt inflytande. |
Oracle Data Mining oövervakade algoritmer
| Teknik | Tillämpning | Algorithms |
|---|---|---|
Klustring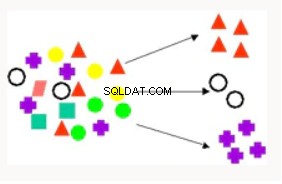 | Klustring används för att partitionera en databas poster i delmängder eller kluster där element i ett kluster delar en uppsättning gemensamma egenskaper. Exempel är att hitta nya kundsegment och filmrekommendationer. | K-Means - Stöder textutvinning, hierarkisk klustring, avståndsbaserad. Ortogonal partitioneringsklustring - Hierarkisk klustring, densitetsbaserad. Förväntningsmaximering - klustringsteknik som fungerar bra i problem med blandad data (tät och gles) datautvinning. |
Anomalidetektering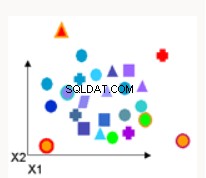 | Anomalidetektering identifierar datapunkter, händelser och/eller observationer som avviker från en datauppsättnings normala beteende. Vanliga exempel är bankbedrägerier, en strukturell defekt, medicinska problem eller fel i en text | One-Class Support Vector Machine - tränar otaggade data och försöker avgöra om en testpunkt tillhör distributionen av träningsdata. |
Funktionsval och extrahering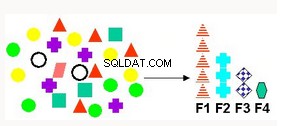 | Producerar nya attribut som linjär kombination av befintliga attribut. Tillämpligt för textdata, latent semantisk analys (LSA), datakomprimering, datauppdelning och projektion och mönsterigenkänning. | Icke-negativ matrisfaktorisering - Mappar originaldata till den nya uppsättningen attribut Principal Components Analysis (PCA) - skapar nya färre sammansatta attribut som representerar alla attribut. Singular Vector Decomposition - etablerad funktionsextraktionsmetod som har ett brett utbud av applikationer. |
Förening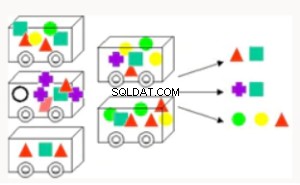 | Hittar regler som är associerade med ofta förekommande artiklar, som används för marknadskorganalys, korsförsäljning, grundorsaksanalys. Användbar för produktbuntning och defektanalys. | Apriori - Hashade ett träd för att samla in information i en databas |
Aktivera Oracle Data Mining-alternativet
Från 12c version 2 Oracle Advanced Analytics Alternativet inkluderar Data Mining och Oracle R-funktioner.
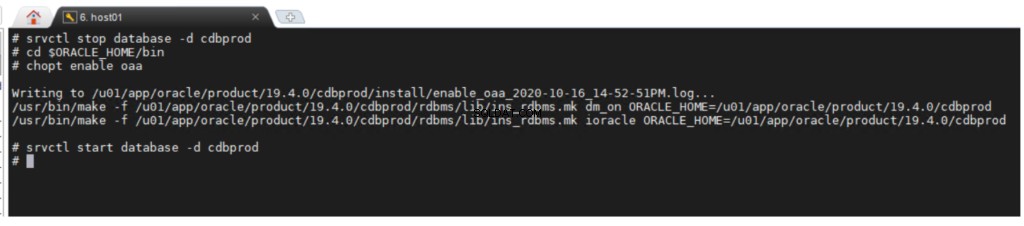
Alternativet Oracle Advanced Analytics är aktiverat som standard under installationen av Oracle Database Enterprise Edition. Om du vill aktivera eller inaktivera ett databasalternativ kan du använda kommandoradsverktyget chopt .
chopt [ enable | disable ] oaa
Så här aktiverar du alternativet Oracle Advanced Analytics:
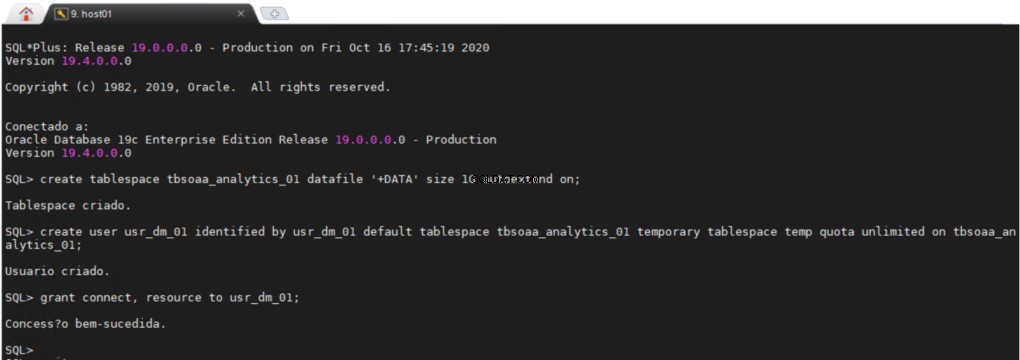
Skapa tabellutrymme ett ODM-schema
Alla användare behöver ett permanent tabellutrymme och ett tillfälligt tabellutrymme för att utföra sitt arbete, det kan vara mycket användbart att ha ett separat område i din databas där du kan skapa alla dina datautvinningsobjekt.
usr_dm_01 schemat kommer att innehålla alla dina datautvinningsarbeten.
Skapa ODM-förrådet
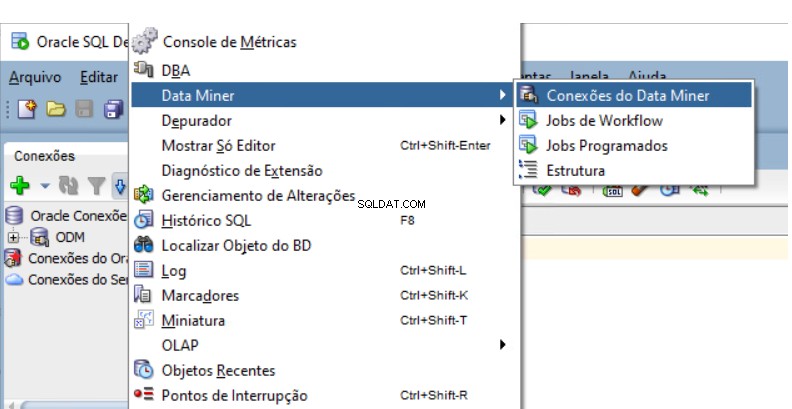
Du måste skapa ett Oracle Data Mining Repository i databasen. Gå till Data Miner Navigator i SQL Developer.
Välj Visa -> Data Miner -> Data Miner Connections:
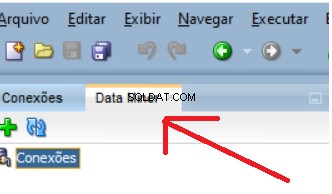
En ny flik öppnas bredvid din befintliga flik Anslutningar:
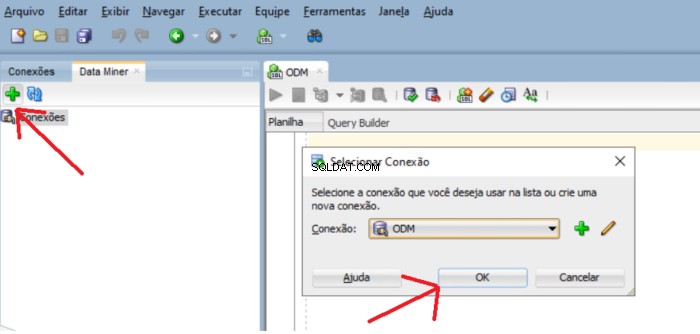
För att lägga till usr_dm_01 schema till den här listan, klicka på de gröna plusfönstren och OK
Om förvaret inte finns ett meddelande som frågar om du vill installera förvaret. Klicka på Ja för att fortsätta med installationen.
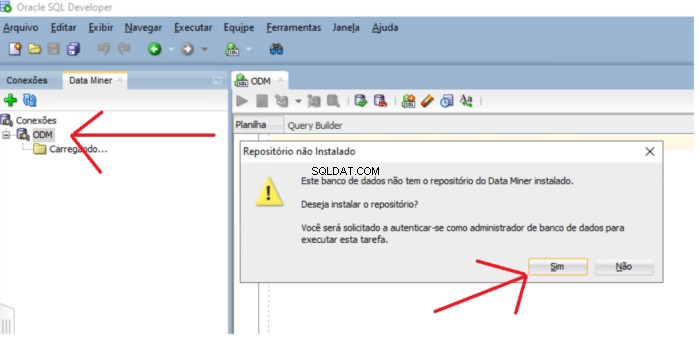
Du måste ange SYS-lösenordet
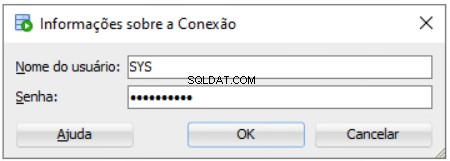
Installationsinställning för förvar
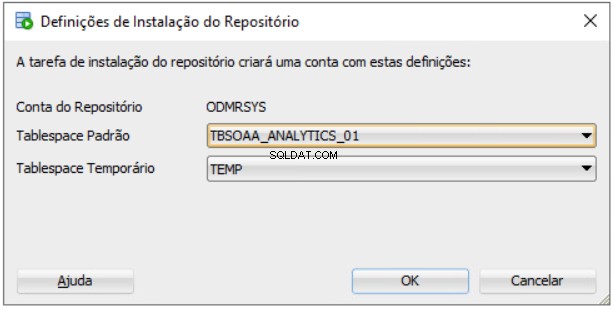
Förloppsfönster för installation av Data Miner Repository
Uppgiften slutförd framgångsrikt
Loggfil
Oracle Data Mining-komponenter
Arbetsflödet låter dig bygga upp en serie noder som utför all nödvändig bearbetning av dina data.
Exempel på ett arbetsflöde utvecklat för prediktiv analys
ODM Data Dictionary Views
Du kan få information om gruvmodeller från dataordboken.
Data Mining-dataordbokvyerna sammanfattas enligt följande:
Obs! * kan ersättas med ALL_, USER_, DBA_ och CDB_
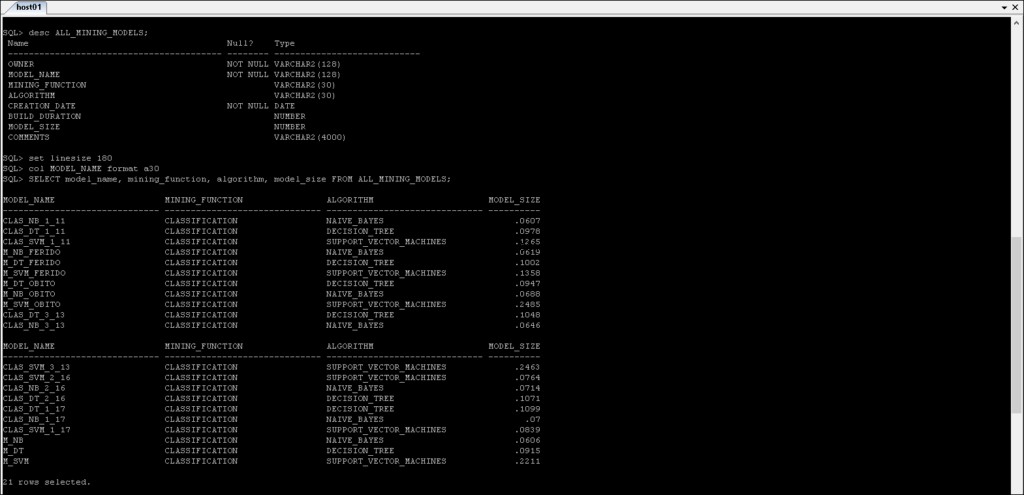
*_MINING_MODELS :Information om de gruvmodeller som har skapats.
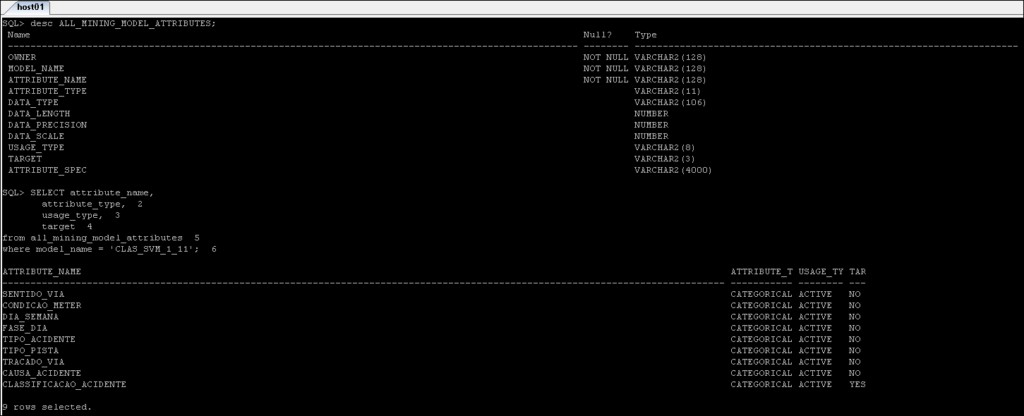
*_MINING_MODEL_ATTRIBUTES :Innehåller detaljerna om de attribut som har använts för att skapa Oracle Data Mining-modellen.
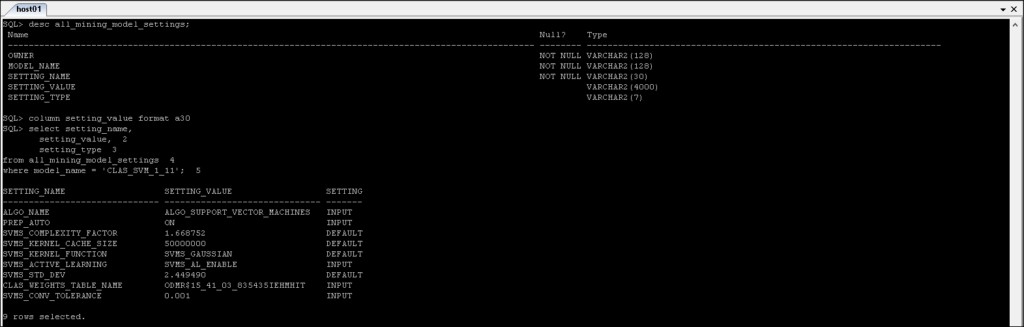
*_MINING_MODEL_SETTINGS :Returnerar information om inställningarna för de gruvmodeller som du har tillgång till.
Referenser
Oracle Data Mining Användarhandbok. Tillgänglig på:https://docs.oracle.com/en/database/oracle/oracle-database/19/dmprg/lot.html
Oracle Data Mining – Skalbar prediktiv analys i databasen. Tillgänglig på:https://www.oracle.com/database/technologies/advanced-analytics/odm.html
Oracle Data Miner Systemöversikt. Tillgänglig på:https://docs.oracle.com/database/sql-developer-17.4/DMRIG/oracle-data-miner-overview.htm#DMRIG124