Ibland är det svårt att hantera en stor mängd data i ett företag, särskilt med den exponentiella ökningen av dataanalys och IoT-användning. Beroende på storleken kan denna mängd data påverka prestanda för dina system och du kommer förmodligen att behöva skala dina databaser eller hitta ett sätt att fixa detta. Det finns olika sätt att skala dina PostgreSQL-databaser och ett av dem är Sharding. I den här bloggen kommer vi att se vad Sharding är och hur man konfigurerar det i PostgreSQL med ClusterControl för att förenkla uppgiften.
Vad är Sharding?
Sharding är åtgärden att optimera en databas genom att separera data från en stor tabell i flera små. Mindre tabeller är Shards (eller partitioner). Partitionering och Sharding är liknande koncept. Den största skillnaden är att sharding innebär att data sprids över flera datorer medan partitionering handlar om att gruppera delmängder av data i en enda databasinstans.
Det finns två typer av sönderdelning:
-
Horisontell delning:Varje ny tabell har samma schema som den stora tabellen men unika rader. Det är användbart när frågor tenderar att returnera en delmängd av rader som ofta är grupperade.
-
Vertikal delning:Varje ny tabell har ett schema som är en delmängd av den ursprungliga tabellens schema. Det är användbart när frågor tenderar att returnera endast en delmängd av kolumner av data.
Låt oss se ett exempel:
Originaltabell
| ID | Namn | Ålder | Land |
|---|---|---|---|
| 1 | James Smith | 26 | USA |
| 2 | Mary Johnson | 31 | Tyskland |
| 3 | Robert Williams | 54 | Kanada |
| 4 | Jennifer Brown | 47 | Frankrike |
Vertikal sönderdelning
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Namn | Ålder | ID | Land |
| 1 | James Smith | 26 | 1 | USA |
| 2 | Mary Johnson | 31 | 2 | Tyskland |
| 3 | Robert Williams | 54 | 3 | Kanada |
| 4 | Jennifer Brown | 47 | 4 | Frankrike |
Horisontell skärning
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Namn | Ålder | Land | ID | Namn | Ålder | Land |
| 1 | James Smith | 26 | USA | 3 | Robert Williams | 54 | Kanada |
| 2 | Mary Johnson | 31 | Tyskland | 4 | Jennifer Brown | 47 | Frankrike |
Nu när vi har granskat några Sharding-koncept, låt oss gå vidare till nästa steg.
Hur distribuerar man ett PostgreSQL-kluster?
Vi kommer att använda ClusterControl för denna uppgift. Om du inte använder ClusterControl ännu kan du installera den och distribuera eller importera din nuvarande PostgreSQL-databas genom att välja alternativet "Importera" och följa stegen för att dra fördel av alla ClusterControl-funktioner som säkerhetskopiering, automatisk failover, varningar, övervakning och mer .
För att utföra en distribution från ClusterControl, välj helt enkelt alternativet "Deploy" och följ instruktionerna som visas.
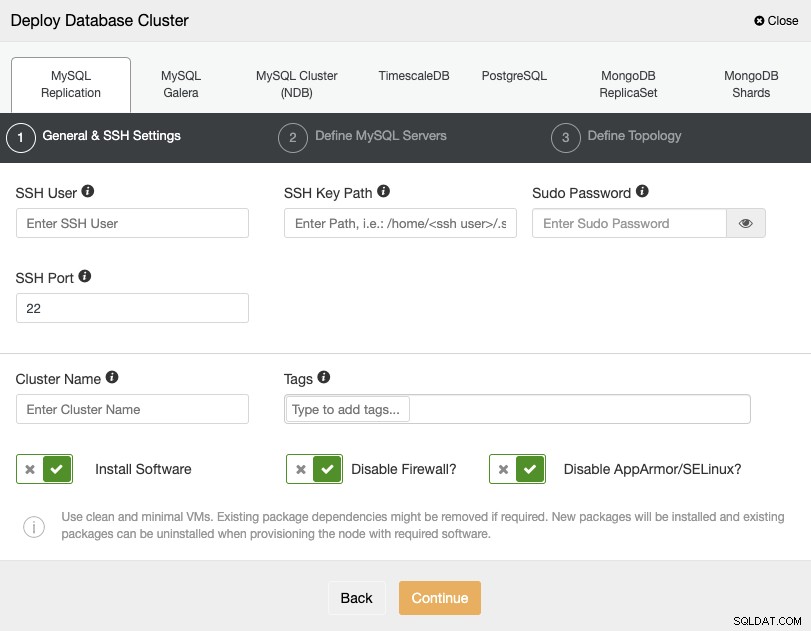
När du väljer PostgreSQL måste du ange din användare, nyckel eller lösenord och Port för att ansluta med SSH till dina servrar. Du kan också lägga till ett namn för ditt nya kluster och om du vill kan du också använda ClusterControl för att installera motsvarande programvara och konfigurationer åt dig.
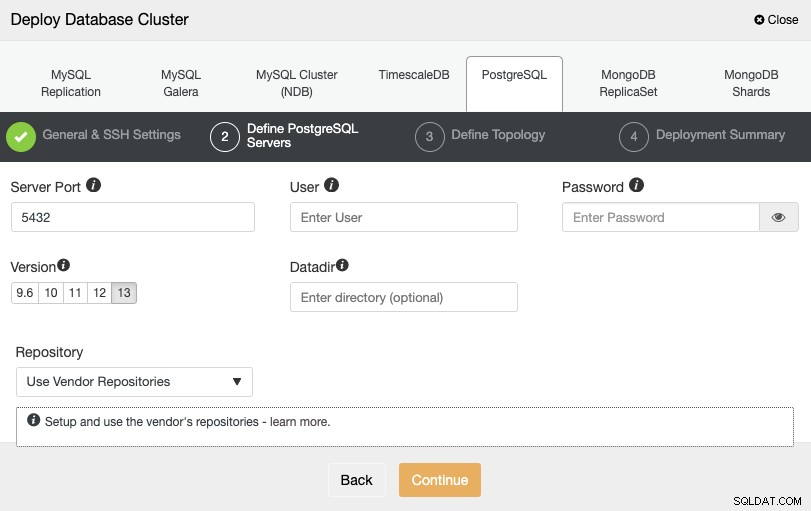
När du har ställt in SSH-åtkomstinformationen måste du definiera databasens autentiseringsuppgifter , version och datadir (valfritt). Du kan också ange vilket arkiv som ska användas.
För nästa steg måste du lägga till dina servrar i klustret som du ska skapa med IP-adressen eller värdnamnet.
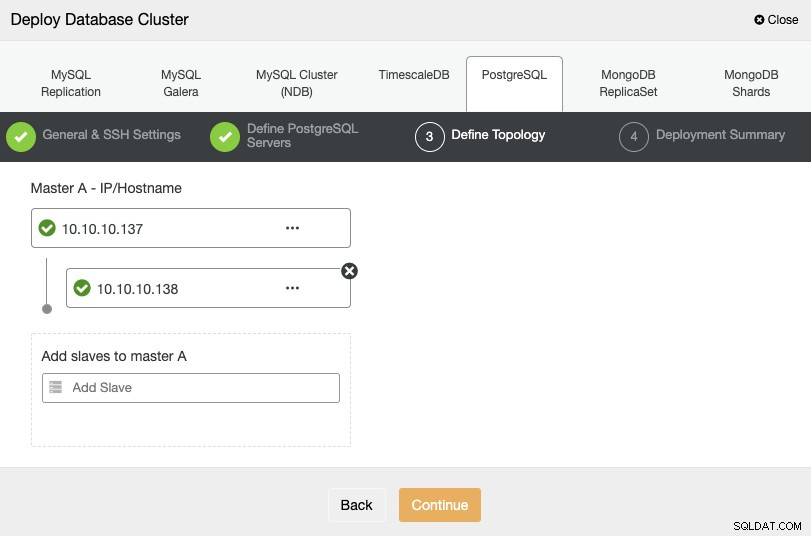
I det sista steget kan du välja om din replikering ska vara Synkron eller Asynkron och tryck sedan bara på "Deploy".
När uppgiften är klar kommer du att se ditt nya PostgreSQL-kluster i huvudskärmen för ClusterControl.

Nu när du har skapat ditt kluster kan du utföra flera uppgifter på det som att lägga till en lastbalanserare (HAProxy), anslutningspooler (pgBouncer) eller en ny replik.
Upprepa processen för att ha minst två separata PostgreSQL-kluster för att konfigurera Sharding, vilket är nästa steg.
Hur konfigurerar man PostgreSQL Sharding?
Nu kommer vi att konfigurera Sharding med PostgreSQL-partitioner och Foreign Data Wrapper (FDW). Denna funktion gör att PostgreSQL kan komma åt data som lagras på andra servrar. Det är en förlängning som är tillgänglig som standard i den vanliga PostgreSQL-installationen.
Vi kommer att använda följande miljö:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersFör att aktivera FDW-tillägget behöver du bara köra följande kommando på din huvudserver, i det här fallet Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONLåt oss nu skapa tabellkunderna uppdelade efter registrerat datum:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Och följande partitioner:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Dessa partitioner är lokala. Låt oss nu infoga några testvärden och kontrollera dem:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Här kan du fråga huvudpartitionen för att se all data:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Eller till och med fråga efter motsvarande partition:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Som du kan se, infogades data i olika partitioner, enligt det registrerade datumet. Nu, i fjärrnoden, i det här fallet Shard2, låt oss skapa en annan tabell:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Du måste skapa denna Shard2-server i Shard1 på det här sättet:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Och användaren för att komma åt det:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Skapa nu utländsk tabell i Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;Och låt oss infoga data i denna nya fjärrtabell från Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Om allt gick bra borde du kunna komma åt data från både Shard1 och Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Det är allt. Nu använder du Sharding i ditt PostgreSQL-kluster.
Slutsats
Partitionering och Sharding i PostgreSQL är bra funktioner. Det hjälper dig om du behöver separera data i en stor tabell för att förbättra prestanda, eller till och med rensa data på ett enkelt sätt, bland andra situationer. En viktig punkt när du använder Sharding är att välja en bra shard-nyckel som fördelar data mellan noderna på bästa sätt. Du kan också använda ClusterControl för att förenkla PostgreSQL-distributionen och för att dra fördel av vissa funktioner som övervakning, varning, automatisk failover, säkerhetskopiering, punkt-i-tid återställning och mer.