PostgreSQL är en av databaserna som kan distribueras via ClusterControl, tillsammans med MySQL, MariaDB och MongoDB. ClusterControl förenklar inte bara distributionen av databasklustret, utan har en funktion för skalbarhet om din applikation växer och kräver den funktionen.
Genom att skala upp din databas kommer din applikation att fungera mycket smidigare och bättre om applikationsbelastningen eller trafiken ökar. I det här blogginlägget kommer vi att granska stegen för hur man gör implementeringen samt uppskalning av PostgreSQL v13 med ClusterControl 1.8.2.
Implementering av användargränssnitt (UI)
Det finns två sätt att distribuera i ClusterControl, webbanvändargränssnitt (UI) samt kommandoradsgränssnitt (CLI). Användaren har friheten att välja vilket som helst av distributionsalternativen beroende på deras önskemål och behov. Båda alternativen är lätta att följa och väldokumenterade i vår dokumentation. I det här avsnittet kommer vi att gå igenom distributionsprocessen med det första alternativet - webbgränssnitt.
Det första steget är att logga in på din ClusterControl och klicka på Deploy:
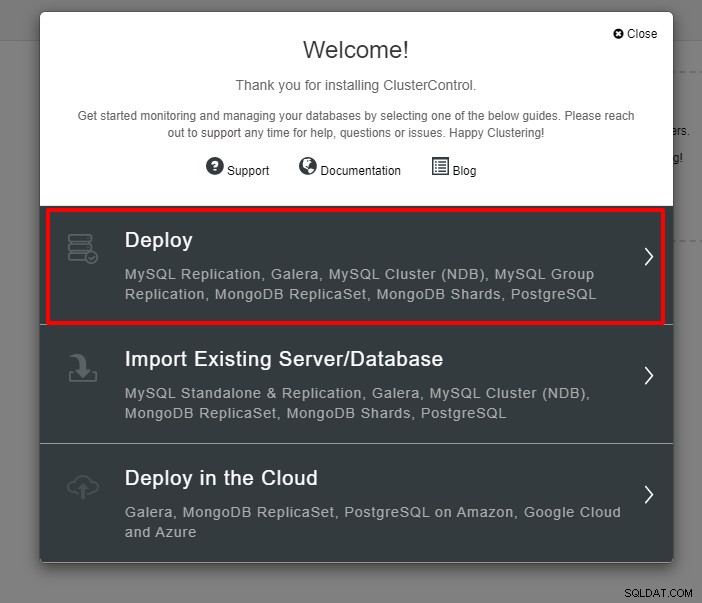
Du kommer att presenteras med skärmdumpen nedan för nästa steg i implementeringen , välj fliken PostgreSQL för att fortsätta:
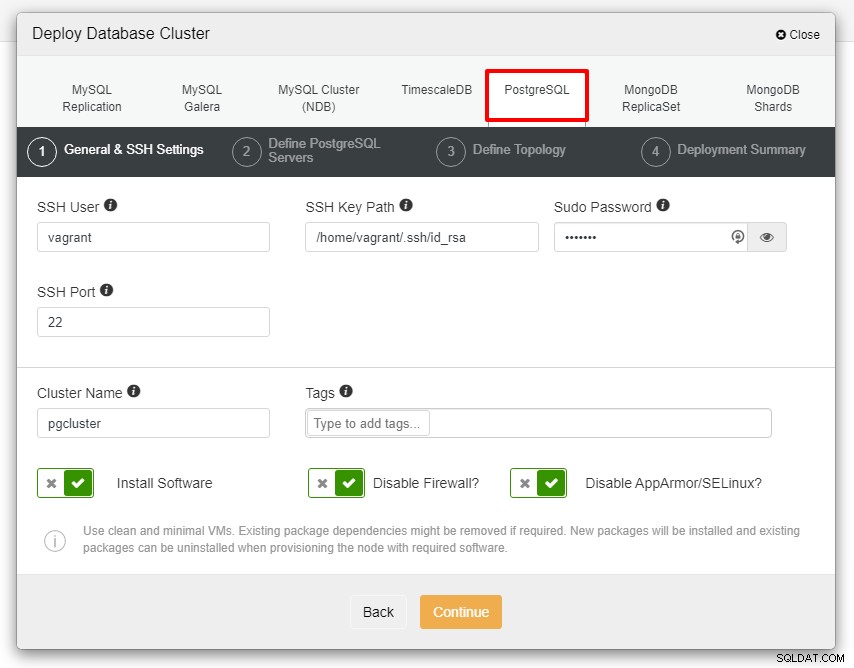
Innan vi går vidare vill jag påminna om att sambandet mellan ClusterControl-noden och databasens noder måste vara lösenordslösa. Innan vi implementerar är allt vi behöver göra att generera ssh-keygen från ClusterControl-noden och sedan kopiera den till alla noder. Fyll i inmatningen för SSH-användare, Sudo-lösenord samt klusternamn enligt dina krav och klicka på Fortsätt.
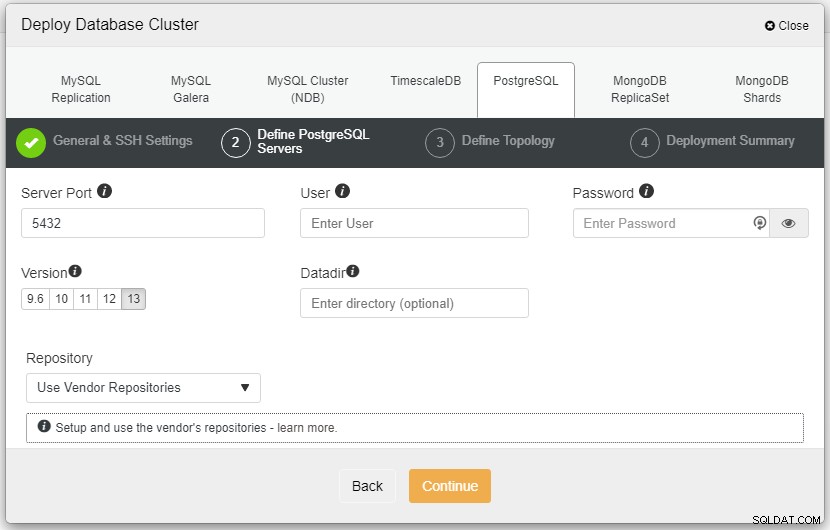
I skärmdumpen ovan måste du definiera serverporten (i om du skulle vilja använda andra), användaren som du vill använda samt lösenordet och se till att välja version 13 som du vill installera.
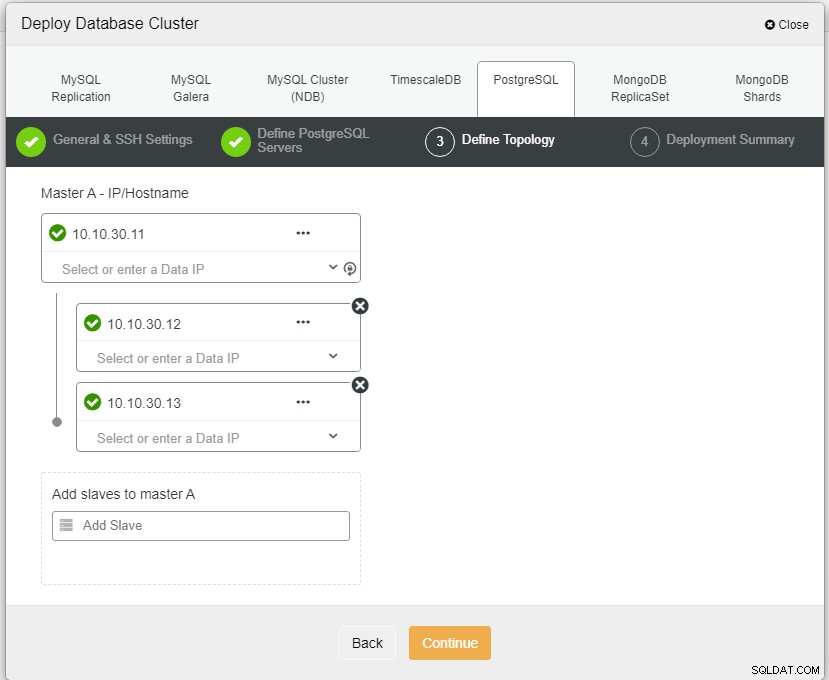 Photo authorPhoto description
Photo authorPhoto descriptionHär måste vi definiera servrarna antingen med värdnamnet eller IP-adressen, som i detta fall 1 master och 2 slavar. Det sista steget är att välja replikeringsläge för vårt kluster.
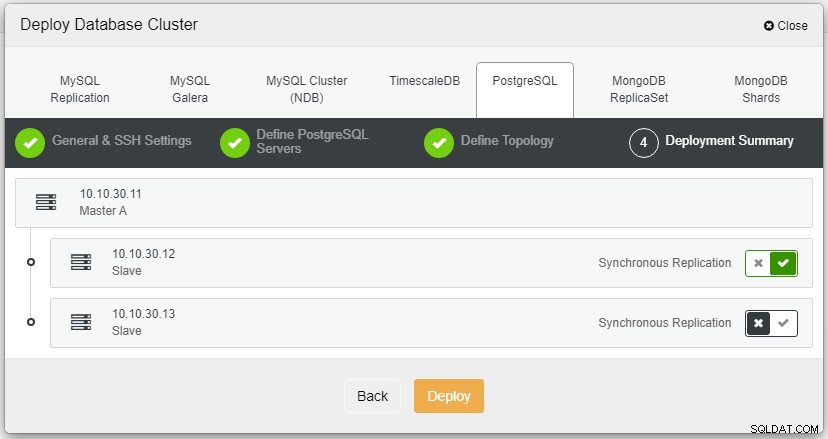
När du klickar på Distribuera startar distributionsprocessen och vi kan övervaka framsteg på fliken Aktivitet.
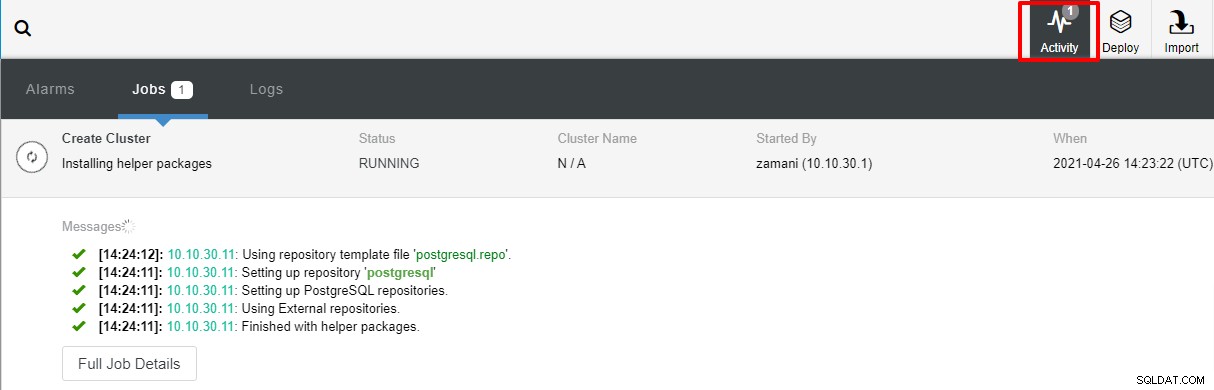
Distributionen tar normalt ett par minuter, prestandan beror mest på nätverk och serverns spec.

Nu när vi har PostgreSQL v13 installerad med ClusterControl GUI, vilket är ganska enkelt .
Command Line Interface (CLI) PostgreSQL-distribution
Från ovanstående kan vi se att implementeringen är ganska enkel med webbgränssnittet. Den viktiga noteringen är att alla noder måste ha lösenordslösa SSH-anslutningar innan distributionen. I det här avsnittet kommer vi att se hur man distribuerar med kommandoraden ClusterControl CLI eller "s9s"-verktyg.
Vi antog att ClusterControl har installerats innan detta, låt oss börja med att generera ssh-keygen. Kör följande kommandon i ClusterControl-noden:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3När alla kommandon ovan har körts framgångsrikt kan vi verifiera den lösenordslösa anslutningen genom att använda följande kommando:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordOm kommandot ovan körs med framgång kan klusterdistributionen startas från ClusterControl-servern med följande kommandorad:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logRätt efter att du kört kommandot ovan kommer du att se något i stil med detta vilket betyder att uppgiften har börjat köras:
Klustret kommer att skapas på 3 datanod(er).
Verifierar jobbparametrar.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
Du kan också verifiera det genom att logga in på webbkonsolen med det användarnamn som du har skapat. Nu har vi ett PostgreSQL-kluster distribuerat med tre noder. Om du vill lära dig mer om distributionskommandot ovan, här är den bästa referensen för dig.
Skala upp PostgreSQL med ClusterControl UI
PostgreSQL är en relationsdatabas och vi vet att det inte är lätt att skala ut den här typen av databas jämfört med en icke-relationell databas. Nuförtiden behöver de flesta applikationer skalbarhet för att ge bättre prestanda och snabbhet. Det finns många sätt att få detta implementerat beroende på din infrastruktur och miljö.
Skalbarhet är en av funktionerna som kan underlättas av ClusterControl och kan uppnås både med UI och CLI. I det här avsnittet ska vi se hur vi kan skala ut PostgreSQL med ClusterControl UI. Det första steget är att logga in på ditt användargränssnitt och välja klustret, när klustret är valt kan du klicka på alternativet enligt skärmdumpen nedan:
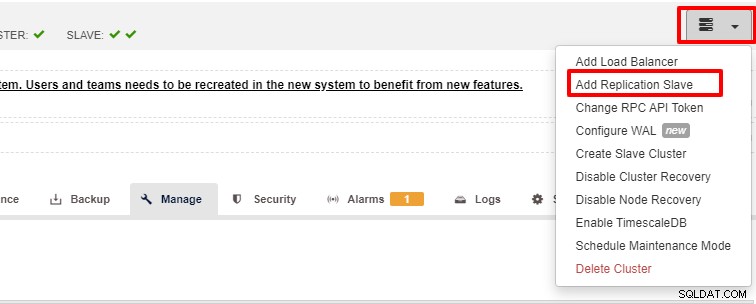
När du klickade på "Lägg till replikeringsslav" ser du följande sida . Du kan antingen välja "Lägg till ny..." eller "Importera..." beroende på din situation. I det här exemplet väljer vi det första alternativet:
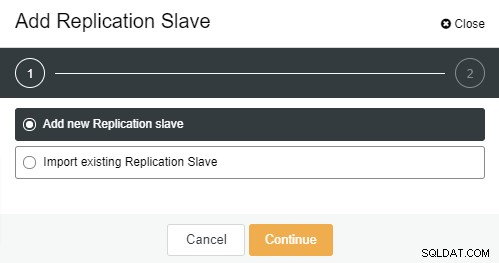
Följande skärm kommer att visas när du klickade på den:
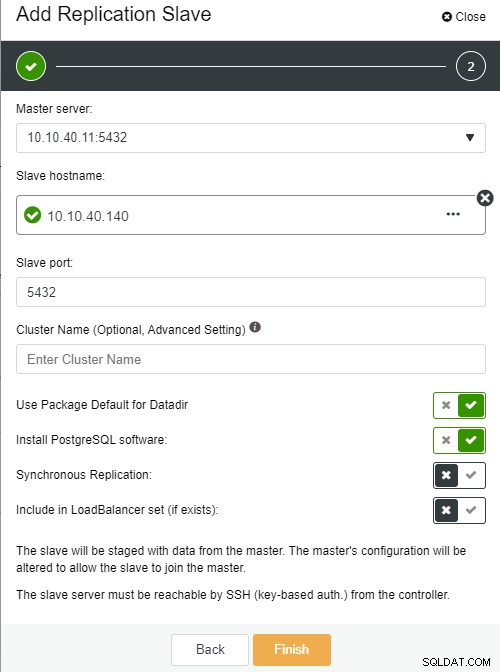 FotoförfattareFotobeskrivning
FotoförfattareFotobeskrivning-
Slavvärdnamn:värdnamnet/IP-adressen för den nya slaven eller noden
-
Slavport:Slavens PostgreSQL-port, standard är 5432
-
Klusternamn:namnet på klustret, du kan antingen lägga till eller lämna det tomt
-
Använd paketstandard för Datadir:du kan markera detta alternativ om du vill ha en annan plats för Datadir
-
Installera PostgreSQL-programvara:du kan låta det här alternativet vara markerat
-
Synkron replikering:du kan välja vilken typ av replikering du vill ha i den här
-
Inkludera i LoadBalancer-uppsättningen (om det finns):detta alternativ ska markeras om du har LoadBalancer konfigurerat för klustret
Den viktigaste anmärkningen här är att du måste konfigurera den nya slavvärden så att den är lösenordslös innan du kan köra den här installationen. När allt är bekräftat kan vi klicka på "Slutför"-knappen för att slutföra installationen. I det här exemplet har jag lagt till IP “10.10.40.140”.
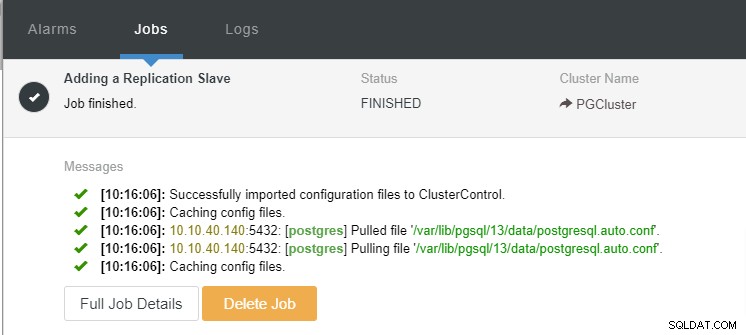
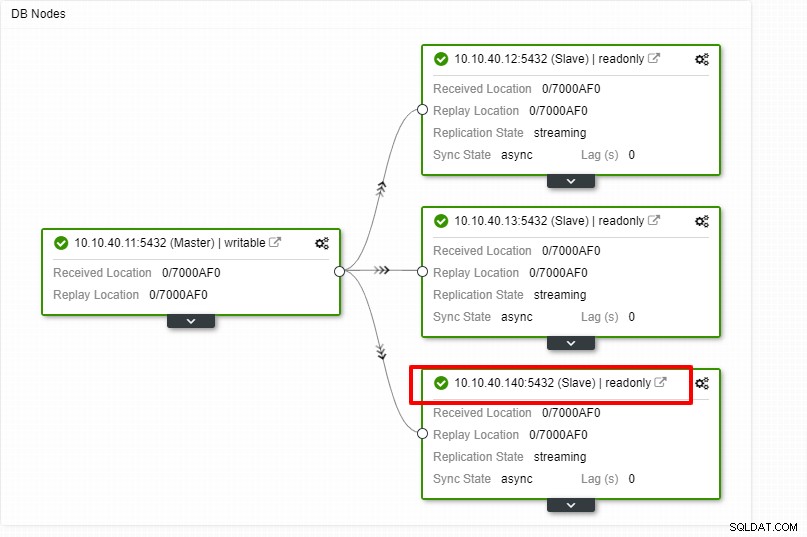
Vi kan nu övervaka jobbaktiviteten och låta installationen slutföras. För att bekräfta inställningen kan vi gå till fliken "Topologi" för att se den nya slaven:
Skala ut PostgreSQL med ClusterControl CLI
Att lägga till de nya noderna i det befintliga klustret är mycket enkelt med hjälp av CLI. Från kontrollernoden kör du följande kommando. Det första kommandot är att identifiera klustret som vi vill lägga till den nya noden till:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.I det här exemplet kan vi se att nod-ID är "1" för klusternamnet "PGCluster". Låt oss se det första kommandoalternativet om hur man lägger till en ny nod till det befintliga PostgreSQL-klustret:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logStenografin "--log" i slutet av raden låter oss se vad som är den aktuella uppgiften som körs efter kommandot utfört enligt nedan:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…Nästa tillgängliga kommando som du kan använda är som följande:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitLägg till nod i kluster
\ Job 9 RUNNING [▋ ] 5% Installing packagesLägg märke till att det finns "--vänta" förkortning på raden och utdata du kommer att se kommer att visas som ovan. När processen är klar kan vi bekräfta de nya noderna på fliken "Översikt" i klustret från användargränssnittet:
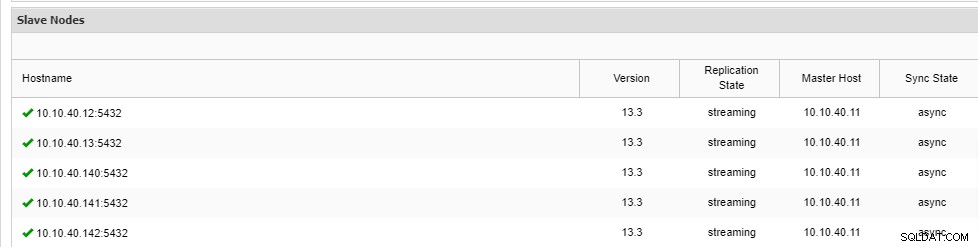
Slutsats
I det här blogginlägget har vi granskat två alternativ för att skala ut PostgreSQL i ClusterControl. Som du kanske märker är det enkelt att skala ut PostgreSQL med ClusterControl. ClusterControl kan inte bara göra skalbarheten utan du kan också uppnå hög tillgänglighetsinställning för ditt databaskluster. Funktioner som HAProxy, PgBouncer samt Keepalived är tillgängliga och redo att implementeras för ditt kluster närhelst du känner behov av dessa alternativ. Med ClusterControl är ditt databaskluster lätt att hantera och övervaka samtidigt.
Vi hoppas att det här blogginlägget hjälper dig att skala ut din PostgreSQL-inställning.