[ Del 1 | Del 2 | Del 3 ]
I andan av Grant Fritcheys senaste gnäll, och Erin Stellatos ansträngningar sedan jag tror innan vi träffades, vill jag gå på tåget för att basunera ut och främja idén om att slänga spår till förmån för Extended Events. När någon säger spår , tänker de flesta direkt Profiler . Även om Profiler är sin egen speciella mardröm, ville jag idag prata om SQL Servers standardspår.
I vår miljö är det aktiverat på alla 200+ produktionsservrar, och det samlar en hel del skräp som vi aldrig kommer att undersöka. Faktiskt så mycket skräp att viktiga händelser som vi kan hitta användbara för felsökning rullar ut ur spårningsfilerna innan vi någonsin får chansen. Så jag började överväga möjligheten att stänga av den, eftersom:
- det är inte gratis (observatören ovanför själva spårningsaktiviteten, I/O som är involverad i att skriva till spårningsfilerna och utrymmet de förbrukar);
- på de flesta servrar har den aldrig tittats på; på andra, sällan; och,
- det är lätt att slå på igen för specifik, isolerad felsökning.
Ett par andra saker påverkar värdet på standardspårningen. Det går inte att konfigurera på något sätt — du kan inte ändra vilka händelser den samlar in, du kan inte lägga till filter och du kan inte kontrollera hur många filer den behåller (5), hur stora de kan bli (20 MB vardera) , eller var de är lagrade (SERVERPROPERTY('ErrorLogFileName') ). Så vi är helt utlämnade till arbetsbördan – på en given server kan vi inte förutsäga hur långt tillbaka data kan gå (händelser med större TextData värden, till exempel, kan ta mycket mer plats och pressa ut äldre händelser snabbare). Ibland kan det gå tillbaka en vecka, andra gånger kan det gå tillbaka bara några minuter.
Analysera nuvarande tillstånd
Jag körde följande kod mot 224 produktionsinstanser, bara för att förstå vilken typ av brus som fyller upp standardspåret i vår miljö. Det här är förmodligen mer komplicerat än det behöver vara och är inte ens lika komplext som den sista frågan jag använde, men det är en bra utgångspunkt för att analysera uppdelningen av händelsetyper på hög nivå som för närvarande fångas:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (EventSubClass-predikatet är till för att förhindra dubbelräkning av DDL-händelser.För en karta över EventClass-värden listade jag dem i det här svaret på Stack Exchange.)
Och resultaten är inte snygga (typiska resultat från en slumpmässig server). Följande representerar inte den exakta utmatningen av den frågan, men jag ägnade lite tid åt att aggregera resultaten till ett mer lättsmält format för att se hur mycket av data som var användbar och hur mycket brus (klicka för att förstora):
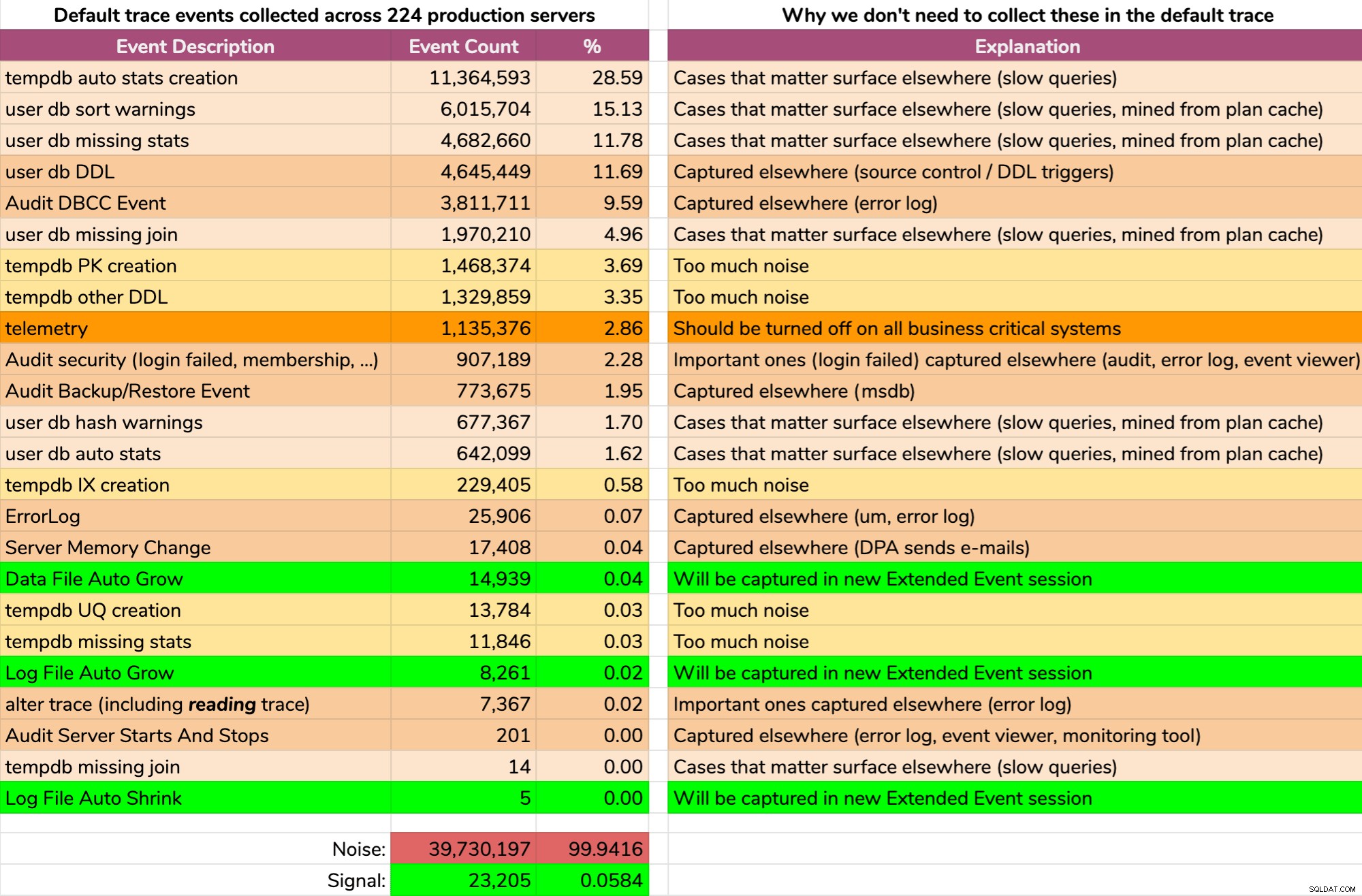
Nästan allt buller (99,94%). Det enda användbara vi någonsin behövde från standardspåret var filtillväxt och krymphändelser, eftersom de var det enda vi inte fångat någon annanstans på ett eller annat sätt. Men även det kan vi inte alltid lita på, eftersom data rullar iväg så snabbt.
Ett annat sätt jag delade upp data på:äldsta händelse per instans. Vissa instanser hade så mycket brus att de inte kunde hålla fast vid standardspårningsdata i mer än några minuter! Jag suddade ut servernamnen men det här är riktiga data (detta är de 20 servrarna med kortast historik – klicka för att förstora):
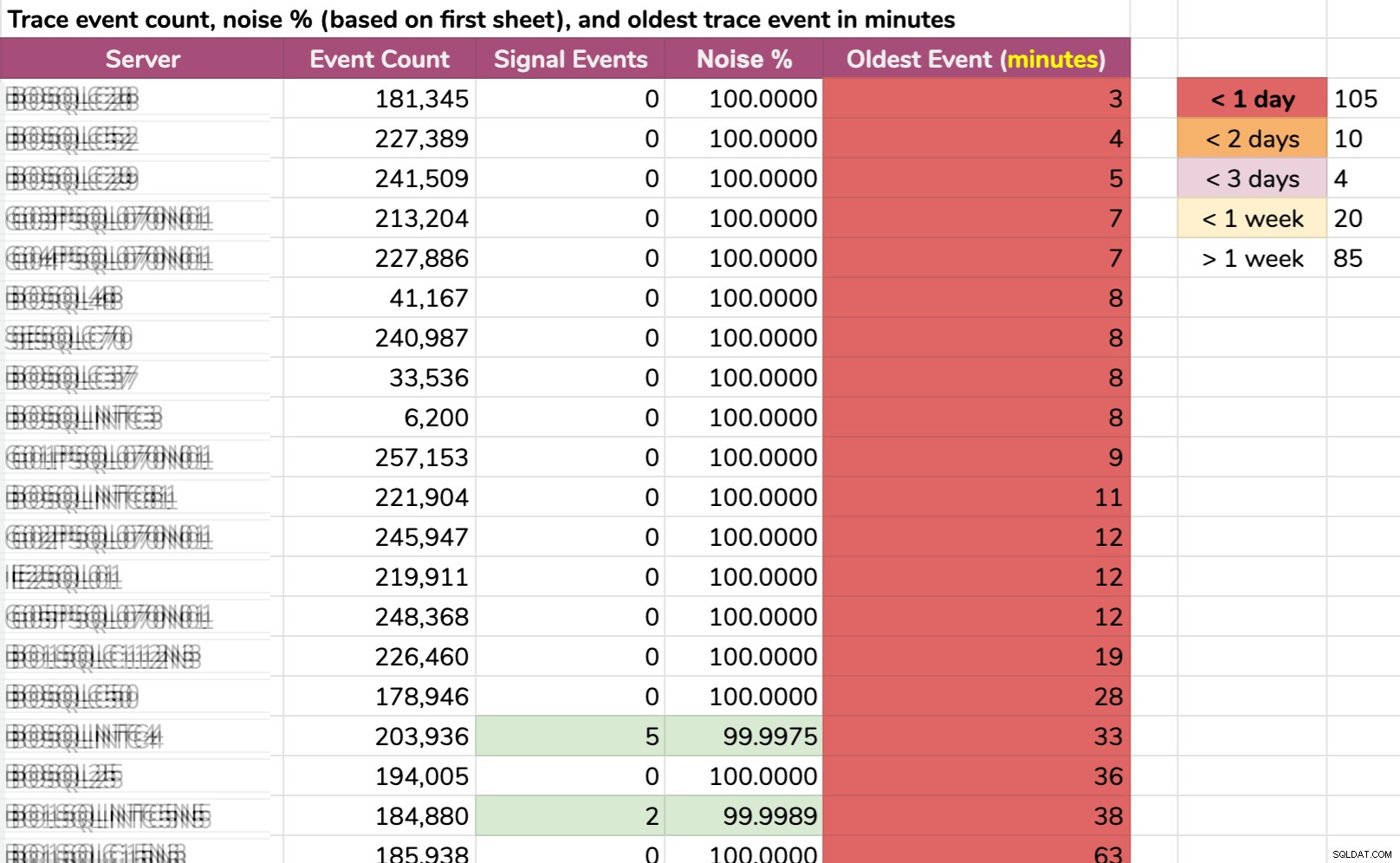
Även om spåret samlades bara relevant information och något intressant hände, vi måste agera snabbt för att fånga det, beroende på servern. Om det hände:
- 20 minuter sedan , då skulle den redan vara borta på 15 instanser .
- den här gången igår , skulle den vara borta på 105 instanser .
- för två dagar sedan , skulle den vara borta på 115 instanser .
- för mer än en vecka sedan , skulle den vara borta på 139 instanser .
Vi hade en handfull servrar i andra änden också, men de är ointressanta i det här sammanhanget; de servrarna är på det sättet helt enkelt för att inget intressant händer där (t.ex. de är inte upptagna eller ingår i någon kritisk arbetsbelastning).
På plussidan...
Att undersöka standardspårningen avslöjade vissa felkonfigurationer på några av våra servrar:
- Flera servrar hade fortfarande telemetri aktiverat . Jag är helt för att hjälpa Microsoft i vissa miljöer, men inte till någon overheadkostnad på affärskritiska system.
- Vissa bakgrundssynkroniseringsuppgifter var att lägga till medlemmar i roller i blindo , om och om igen, utan att kontrollera om de redan var i de rollerna. Detta är inte skadligt i sig, speciellt eftersom dessa händelser inte längre kommer att fylla upp standardspåret, men de fyller sannolikt även revisioner med brus, och det finns förmodligen andra blinda återansökningsoperationer som sker i samma mönster.
- Någon hade aktiverat automatisk krympning någonstans (god sorg!), så det här var något jag ville spåra upp och förhindra från att hända igen (nya XE kommer också att fånga dessa händelser).
Detta ledde till uppföljningsuppgifter för att åtgärda dessa problem och/eller lägga till villkor till befintlig automatisering som redan finns. Så vi kan förhindra upprepning utan att förlita oss på att bara ha turen att råka ut för dem i någon framtida standardspårgranskning, innan de rullades ut.
...men problemet kvarstår
Annars är allt antingen information som vi omöjligt kan agera på eller, som beskrivs i grafiken ovan, händelser vi redan fångar någon annanstans. Och återigen, de enda data jag är intresserad av från standardspåret som vi inte redan fångar på andra sätt är händelser som rör filtillväxt och krympning (även om standardspåret bara fångar den automatiska sorten).
Men det större problemet är egentligen inte ljudvolymen. Jag kan hantera stora massiva spårningsfiler med mycket skräp, eftersom WHERE-klausuler uppfanns för just detta ändamål. Det verkliga problemet är att viktiga händelser försvann för snabbt.
Svaret
Svaret, åtminstone i vårt scenario, var enkelt:inaktivera standardspårningen, eftersom det inte är värt att köra om det inte går att lita på.
Men med tanke på mängden buller ovan, vad ska ersätta det? Något?
Du kanske vill ha en utökad händelsesession som fångar allt standardspåret fångat. I så fall har Jonathan Kehayias dig täckt. Detta skulle ge dig samma information, men med kontroll över saker som lagring, var data lagras och, när du blir mer bekväm, möjligheten att ta bort några av de bullrigare eller mindre användbara händelserna, gradvis, över tiden.
Min plan var lite mer aggressiv och blev snabbt en "enkel" process för att utföra följande på alla servrar i miljön (via CMS):
- utveckla en utökad händelsesession som bara fångar filändringshändelser (både manuella och automatiska)
- inaktivera standardspårningen
- skapa en vy för att göra det enkelt för våra team att konsumera måldata
Observera att Jag föreslår inte att du blint inaktiverar standardspårningen , bara förklara varför jag valde att göra det i vår miljö. I kommande inlägg i den här serien kommer jag att visa den nya sessionen Extended Events, vyn som exponerar underliggande data, koden jag använde för att distribuera dessa ändringar på alla servrar och potentiella biverkningar som du bör tänka på.
[ Del 1 | Del 2 | Del 3 ]