Även om de flesta databasservrar (särskilt de som hanterar OLTP-liknande arbetsbelastningar) i framtiden kommer att använda en flash-baserad lagring, är vi inte där än – flash-lagring är fortfarande betydligt dyrare än traditionella hårddiskar, och så många system använder en mix SSD- och HDD-enheter. Det betyder dock att vi måste bestämma hur vi ska dela upp databasen – vad som ska gå till spinning rust (HDD) och vad som är en bra kandidat för flashlagring som är dyrare men mycket bättre på att hantera slumpmässiga I/O.
Det finns lösningar som försöker hantera detta automatiskt på lagringsnivå genom att automatiskt använda SSD:er som cache, och automatiskt behålla den aktiva delen av datan på SSD. Lagringsenheter/SAN gör ofta detta internt, det finns hybrid SATA/SAS-enheter med stor hårddisk och liten SSD i ett enda paket, och det finns naturligtvis lösningar för att göra detta direkt hos värden – till exempel finns dm-cache i Linux, LVM fick också en sådan kapacitet (byggd ovanpå dm-cache) 2014, och ZFS har naturligtvis L2ARC.
Men låt oss ignorera alla dessa automatiska alternativ, och låt oss säga att vi har två enheter anslutna direkt till systemet - en baserad på hårddiskar, den andra flashbaserad. Hur ska du dela upp databasen för att få ut så mycket som möjligt av den dyra flashen? Ett vanligt förekommande mönster är att göra detta efter objekttyp, särskilt tabeller kontra index. Vilket är vettigt i allmänhet, men vi ser ofta människor som placerar index på SSD-lagringen, eftersom index är associerade med slumpmässig I/O. Även om detta kan tyckas rimligt, visar det sig att detta är precis motsatsen till vad du borde göra.
Låt mig visa dig ett riktmärke ...
Låt mig demonstrera detta på ett system med både HDD-lagring (RAID10 byggd av 4x 10k SAS-enheter) och en enda SSD-enhet (Intel S3700). Systemet har 16 GB RAM, så låt oss använda pgbench med skalor 300 (=4,5 GB) och 3000 (=45 GB), det vill säga en som enkelt passar in i RAM och en multipel av RAM. Låt oss sedan placera tabeller och index på olika lagringssystem (genom att använda tabellutrymmen) och mäta prestandan. Databasklustret var rimligt konfigurerat (delade buffertar, WAL-gränser etc.) med avseende på hårdvaruresurserna. WAL placerades på en separat SSD-enhet, kopplad till en RAID-kontroller som delas med SAS-enheterna.
På den lilla (4,5 GB) datamängden ser resultaten ut så här (notera att y-axeln börjar vid 3000 tps):
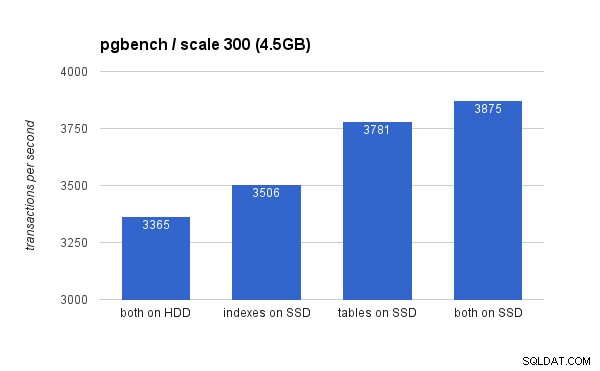
Att placera indexen på SSD ger helt klart lägre fördelar jämfört med att använda SSD för tabeller. Även om datamängden lätt passar in i RAM, måste ändringarna så småningom skrivas till disken så småningom, och medan RAID-kontrollern har en skrivcache, kan den inte riktigt konkurrera med flashlagringen. Nya RAID-kontroller skulle förmodligen prestera lite bättre, men det skulle också nya SSD-enheter.
På den stora datamängden är skillnaderna mycket mer signifikanta (den här gången börjar y-axeln vid 0):
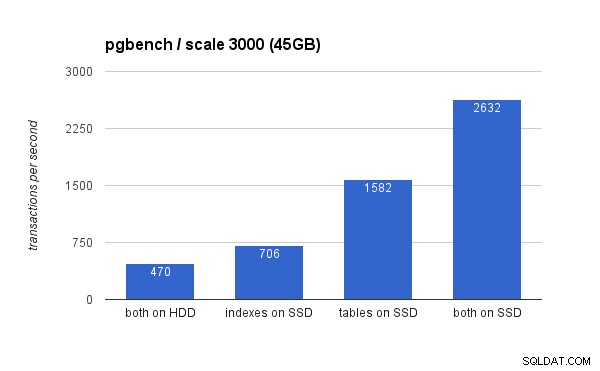
Att placera indexen på SSD resulterar i betydande prestandaökning (nästan 50 %, med hårddisklagring som baslinje), men att flytta tabeller till SSD:n slog lätt det genom att få mer än 200 %. Naturligtvis, om du placerar både tabeller och index på SSD-enheter, kommer du att förbättra prestandan ytterligare – men om du kunde göra det behöver du inte oroa dig för de andra fallen.
Men varför?
Att få bättre prestanda från att placera bord på SSD-enheter kan verka lite kontraintuitivt, så varför beter det sig så här? Tja, det är förmodligen en kombination av flera faktorer:
- index är vanligtvis mycket mindre än tabeller och passar därför lättare in i minnet
- sidorna i indexnivåer (i trädet) är vanligtvis ganska heta och finns därför kvar i minnet
- vid skanning och indexering är mycket av den faktiska I/O-en sekventiell till sin natur (särskilt för bladsidor)
Konsekvensen av detta är att en överraskande mängd I/O mot index antingen inte inträffar alls (tack vare cachning) eller är sekventiell. Å andra sidan är index en stor källa till slumpmässig I/O mot tabellerna.
Det är dock mer komplicerat …
Naturligtvis var detta bara ett enkelt exempel, och slutsatserna kan vara olika för till exempel väsentligt olika arbetsbelastningar. På samma sätt, eftersom SSD-enheter är dyrare, tenderar system att ha mer diskutrymme på hårddiskar än på SSD-enheter, så tabeller kanske inte får plats på SSD medan index skulle göra det. I dessa fall är en mer utarbetad placering nödvändig – till exempel med tanke på inte bara typen av objekt, utan också hur ofta det används (och bara flytta de hårt använda tabellerna till SSD-enheter), eller till och med undergrupper av tabeller (t.ex. genom att gradvis flytta gamla data från SSD till HDD).