Puppet är programvara med öppen källkod för konfigurationshantering och distribution. Det grundades 2005 och är flera plattformar och har till och med ett eget deklarativt språk för konfiguration.

Uppgifterna relaterade till administration och underhåll av PostgreSQL (eller annan programvara egentligen) består av dagliga, repetitiva processer som kräver övervakning. Detta gäller även för de uppgifter som drivs av skript eller kommandon genom ett schemaläggningsverktyg. Komplexiteten i dessa uppgifter ökar exponentiellt när de körs på en massiv infrastruktur, men att använda Puppet för den här typen av uppgifter kan ofta lösa dessa typer av storskaliga problem eftersom Puppet centraliserar och automatiserar utförandet av dessa operationer på ett mycket smidigt sätt.
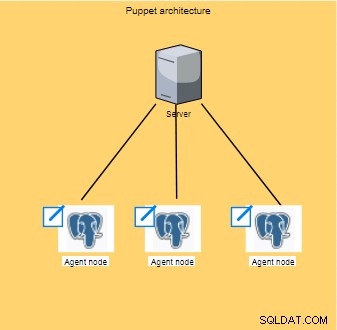
Puppet arbetar inom arkitekturen på klient/servernivå där konfigurationen utförs; dessa operationer sprids sedan och exekveras på alla klienter (även kända som noder).
Körs vanligtvis var 30:e minut, agenternas nod samlar in en uppsättning information (typ av processor, arkitektur, IP-adress, etc..), även kallad fakta, och skickar sedan informationen till master som väntar på svar för att se om det finns några nya konfigurationer att tillämpa.
Dessa fakta gör att mastern kan anpassa samma konfiguration för varje nod.
Puppet är på ett mycket förenklat sätt ett av de viktigaste DevOps-verktygen tillgänglig idag. I den här bloggen ska vi ta en titt på följande...
- Användningsfallet för Puppet &PostgreSQL
- Installera Puppet
- Konfigurera och programmera docka
- Konfigurera Puppet för PostgreSQL
Installationen och installationen av Puppet (version 5.3.10) som beskrivs nedan utfördes i en uppsättning värdar som använder CentOS 7.0 som operativsystem.
Användningsfallet för Puppet &PostgreSQL
Anta att det finns ett problem i din brandvägg på de maskiner som är värd för alla dina PostgreSQL-servrar, skulle det då vara nödvändigt att neka alla utgående anslutningar till PostgreSQL och göra det så snart som möjligt.

Puppet är det perfekta verktyget för denna situation, särskilt eftersom hastighet och effektivitet är grundläggande. Vi kommer att prata om det här exemplet som presenteras i avsnittet "Konfigurera Puppet för PostgreSQL" genom att hantera parametern listen_addresses.
Installera Puppet
Det finns en uppsättning vanliga steg att utföra antingen på master- eller agentvärdar:
Steg ett
Uppdatering av /etc/hosts-fil med värdnamn och deras IP-adress
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetSteg två
Lägga till Puppet-förråden på systemet
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmFör andra operativsystem eller CentOS-versioner finns det lämpligaste arkivet i Puppet, Inc. Yum Repositories.
Steg tre
Konfiguration av NTP-server (Network Time Protocol)
$ sudo yum -y install chronySteg fyra
Chrony används för att synkronisera systemklockan från olika NTP-servrar och håller därmed tiden synkroniserad mellan master- och agentserver.
När chrony har installerats måste den aktiveras och startas om:
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.serviceSteg fem
Inaktivera SELinux-parametern
På filen /etc/sysconfig/selinux måste parametern SELINUX (Security Enhanced Linux) inaktiveras för att inte begränsa åtkomsten på båda värdarna.
SELINUX=disabledSteg sex
Innan Puppet-installationen (antingen master eller agent) måste brandväggen i dessa värdar definieras i enlighet därmed:
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Installera Puppet Master
När paketförrådet puppet5-release-5.0.0-1-el7.noarch.rpm har lagts till i systemet kan dockserverinstallationen göras:
$ sudo yum install -y puppetserverParametern för max minnesallokering är en viktig inställning för att uppdatera på /etc/sysconfig/puppetserver-filen till 2 GB (eller till 1 GB om tjänsten inte startar):
JAVA_ARGS="-Xms2g –Xmx2g "I konfigurationsfilen /etc/puppetlabs/puppet/puppet.conf är det nödvändigt att lägga till följande parametrering:
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hPuppetserver-tjänsten använder porten 8140 för att lyssna på nodförfrågningarna, så det är nödvändigt att säkerställa att denna port kommer att aktiveras:
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadNär alla inställningar har gjorts i Puppet Master är det dags att starta den här tjänsten:
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver
Installera Puppet Agent
Puppet-agenten i paketförrådet puppet5-release-5.0.0-1-el7.noarch.rpm läggs också till i systemet. Puppet-agent-installationen kan utföras direkt:
$ sudo yum install -y puppet-agentPuppet-agent-konfigurationsfilen /etc/puppetlabs/puppet/puppet.conf måste också uppdateras genom att lägga till följande parameter:
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hNästa steg består av att registrera agentnoden på mastervärden genom att utföra följande kommando:
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}I detta ögonblick, på huvudvärden, finns det en väntande begäran från marionettagenten om att signera ett certifikat:

Det måste signeras genom att köra ett av följande kommandon:
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.comeller
$ sudo /opt/puppetlabs/bin/puppet cert sign --allÄntligen (och när dockmästaren har undertecknat certifikatet) är det dags att tillämpa konfigurationerna på agenten genom att hämta katalogen från marionettmästaren:
$ sudo /opt/puppetlabs/bin/puppet agent --testI det här kommandot betyder parametern --test inte ett test, inställningarna som hämtas från mastern kommer att tillämpas på den lokala agenten. För att testa/kontrollera konfigurationerna från master måste följande kommando köras:
$ sudo /opt/puppetlabs/bin/puppet agent --noopKonfigurera och programmera docka
Puppet använder en deklarativ programmeringsmetod där syftet är att specificera vad man ska göra och spelar ingen roll hur man uppnår det!
Den mest elementära koden på Puppet är resursen som specificerar en systemegenskap som kommando, tjänst, fil, katalog, användare eller paket.
Nedan presenteras syntaxen för en resurs för att skapa en användare:
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Olika resurser kan kopplas till den tidigare klassen (även känd som ett manifest) av fil med filtillägget "pp" (det står för Puppet Program), men ändå flera manifest och data (som fakta, filer och mallar) kommer att komponera en modul. Alla där logiska hierarkier och regler representeras i diagrammet nedan:
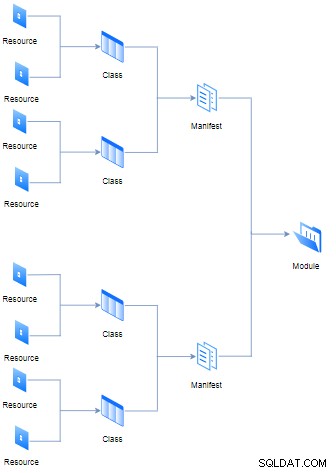
Syftet med varje modul är att innehålla alla manifest som behövs för att exekvera enstaka uppgifter på ett modulärt sätt. Å andra sidan är begreppet klass inte detsamma från objektorienterade programmeringsspråk, i Puppet fungerar det som en aggregator av resurser.
Dessa filorganisationer har en specifik katalogstruktur att följa:
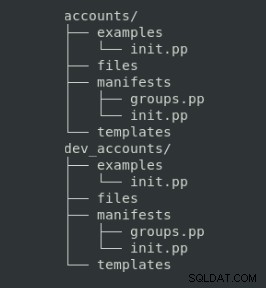
som syftet med varje mapp är följande:
| Mapp | Beskrivning |
| manifest | Dockkod |
| filer | Statiska filer som ska kopieras till noder |
| mallar | Mallfiler som ska kopieras till hanterade noder (den kan anpassas med variabler) |
| exempel | Manifest för att visa hur du använder modulen |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}I nästa avsnitt visar vi dig hur du genererar innehållet i exempelmappen samt kommandon för att testa och publicera varje modul.
Konfigurera Puppet för PostgreSQL
Innan du presenterar flera konfigurationsexempel för att distribuera och underhålla en PostgreSQL-databas är det nödvändigt att installera PostgreSQL-dockormodulen (på servervärden) för att använda alla deras funktioner:
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlFör närvarande finns tusentals moduler redo att användas på Puppet på det offentliga modulförrådet Puppet Forge.
Steg ett
Konfigurera och distribuera en ny PostgreSQL-instans. Här är all nödvändig programmering och konfiguration för att installera en ny PostgreSQL-instans i alla noder.
Det första steget är att skapa en ny modulstrukturkatalog som delas tidigare:
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Sedan, i manifestfilen manifests/init.pp, måste du inkludera klassen postgresql::server som tillhandahålls av den installerade modulen :
class db_postgresql_admin{
include postgresql::server
}För att kontrollera syntaxen för manifestet är det bra att utföra följande kommando:
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppOm inget returneras betyder det att syntaxen är korrekt
För att visa dig hur du använder den här modulen i exempelmappen är det nödvändigt att skapa en ny manifestfil init.pp med följande innehåll:
include db_postgresql_adminExempelplatsen i modulen måste testas och tillämpas på huvudkatalogen:
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppSlutligen är det nödvändigt att definiera vilken modul varje nod har åtkomst i filen "/etc/puppetlabs/code/environments/production/manifests/site.pp" :
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}Eller en standardkonfiguration för alla noder:
node default {
include db_postgresql_admin
}Vanligtvis kontrollerar noderna huvudkatalogen var 30:e minut, men denna fråga kan tvingas fram på nodsidan med följande kommando:
$ /opt/puppetlabs/bin/puppet agent -tEller om syftet är att simulera skillnaderna mellan masterkonfigurationen och de aktuella nodinställningarna, kan den användas med parametern nopp (ingen operation):
$ /opt/puppetlabs/bin/puppet agent -t --noopSteg två
Uppdatera PostgreSQL-instansen för att lyssna på alla gränssnitt. Den tidigare installationen definierar en instansinställning i ett mycket begränsat läge:tillåter endast anslutningar på localhost som kan bekräftas av värdarna som är associerade för porten 5432 (definierad för PostgreSQL):
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres För att tillåta lyssnande på alla gränssnitt är det nödvändigt att ha följande innehåll i filen /etc/puppetlabs/code/environments/production/modules/db_postgresql_admin/manifests/init.pp
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}I exemplet ovan deklareras klassen postgresql::server och parametern listen_addresses ställs in på "*", vilket betyder alla gränssnitt.
Nu är port 5432 associerad med alla gränssnitt, den kan bekräftas med följande IP-adress/port:"0.0.0.0:5432"
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres För att återställa den ursprungliga inställningen:tillåt endast databasanslutningar från localhost parametern listen_addresses måste ställas in på "localhost" eller ange en lista med värdar, om så önskas:
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'För att hämta den nya konfigurationen från huvudvärden behöver du bara begära den på noden:
$ /opt/puppetlabs/bin/puppet agent -tSteg tre
Skapa en PostgreSQL-databas. PostgreSQL-instansen kan skapas med en ny databas såväl som en ny användare (med lösenord) för att använda denna databas och en regel på filen pg_hab.conf för att tillåta databasanslutningen för denna nya användare:
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Den här sista resursen har namnet "Autentisering för fleranines" och filen pg_hba.conf kommer att ha ytterligare en regel:
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5För att hämta den nya konfigurationen från huvudvärden behöver du bara begära den på noden:
$ /opt/puppetlabs/bin/puppet agent -tSteg fyra
Skapa en skrivskyddad användare. För att skapa en ny användare, med skrivskyddad behörighet, måste följande resurser läggas till i det tidigare manifestet:
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}För att hämta den nya konfigurationen från huvudvärden behöver du bara begära den på noden:
$ /opt/puppetlabs/bin/puppet agent -tSlutsats
I det här blogginlägget visade vi dig de grundläggande stegen för att distribuera och börja konfigurera din PostgreSQL-databas på ett automatiskt och anpassat sätt på flera noder (som till och med kan vara virtuella maskiner).
Dessa typer av automatisering kan hjälpa dig att bli mer effektiv än att göra det manuellt och PostgreSQL-konfiguration kan enkelt utföras genom att använda flera av klasserna som finns tillgängliga i puppetforge-förvaret