Hög tillgänglighet är ett krav för nästan alla företag runt om i världen som använder PostgreSQL. Det är välkänt att PostgreSQL använder Streaming Replication som replikeringsmetod. PostgreSQL Streaming-replikering är asynkron som standard, så det är möjligt att ha vissa transaktioner utförda i den primära noden som ännu inte har replikerats till standby-servern. Det betyder att det finns risk för viss dataförlust.
Denna fördröjning i commit-processen är tänkt att vara mycket liten... om standby-servern är tillräckligt kraftfull för att hålla jämna steg med belastningen. Om denna lilla risk för dataförlust inte är acceptabel i företaget kan du också använda synkron replikering istället för standard.
I synkron replikering kommer varje commit av en skrivtransaktion att vänta tills bekräftelsen att commit har skrivits till skriv-framåtloggningsdisken för både den primära och standby-servern.
Denna metod minimerar risken för dataförlust. För att dataförlust ska uppstå måste både den primära och vänteläget misslyckas samtidigt.
Nackdelen med den här metoden är densamma för alla synkrona metoder som med denna metod ökar svarstiden för varje skrivtransaktion. Detta beror på behovet av att vänta tills alla bekräftelser på att transaktionen genomfördes. Lyckligtvis kommer skrivskyddade transaktioner inte att påverkas av detta men; endast skrivtransaktionerna.
I den här bloggen visar du hur du installerar ett PostgreSQL-kluster från början, konverterar den asynkrona replikeringen (standard) till en synkron. Jag visar dig också hur du återställer om svarstiden inte är acceptabel eftersom du enkelt kan gå tillbaka till det tidigare tillståndet. Du kommer att se hur du enkelt distribuerar, konfigurerar och övervakar en PostgreSQL synkron replikering med ClusterControl med endast ett verktyg för hela processen.
Installera ett PostgreSQL-kluster
Låt oss börja installera och konfigurera en asynkron PostgreSQL-replikering, det vill säga det vanliga replikeringsläget som används i ett PostgreSQL-kluster. Vi kommer att använda PostgreSQL 11 på CentOS 7.
PostgreSQL-installation
Efter den officiella installationsguiden för PostgreSQL är den här uppgiften ganska enkel.
Installera först arkivet:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstallera PostgreSQL-klienten och serverpaketen:
$ yum install postgresql11 postgresql11-serverInitiera databasen:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11På standbynoden kan du undvika det sista kommandot (starta databastjänsten) eftersom du kommer att återställa en binär säkerhetskopia för att skapa strömningsreplikeringen.
Låt oss nu se vilken konfiguration som krävs av en asynkron PostgreSQL-replikering.
Konfigurera asynkron PostgreSQL-replikering
Inställning av primär nod
I den primära PostgreSQL-noden måste du använda följande grundläggande konfiguration för att skapa en Async-replikering. Filerna som kommer att ändras är postgresql.conf och pg_hba.conf. I allmänhet finns de i datakatalogen (/var/lib/pgsql/11/data/) men du kan bekräfta det på databassidan:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Ändra eller lägg till följande parametrar i postgresql.conf-konfigurationsfilen.
Här måste du lägga till IP-adresserna där du kan lyssna på. Standardvärdet är 'localhost', och för det här exemplet använder vi '*' för alla IP-adresser på servern.
listen_addresses = '*' Ställ in serverporten där du vill lyssna på. Som standard 5432.
port = 5432 Bestämma hur mycket information som skrivs till WALs. De möjliga värdena är minimala, replika eller logiska. Hot_standby-värdet mappas till replika och används för att behålla kompatibiliteten med tidigare versioner.
wal_level = hot_standby Ställ in det maximala antalet walsender-processer som hanterar anslutningen med en standby-server.
max_wal_senders = 16Ställ in den minsta mängden WAL-filer som ska behållas i katalogen pg_wal.
wal_keep_segments = 32Ändra dessa parametrar kräver en omstart av databastjänsten.
$ systemctl restart postgresql-11Pg_hba.conf
Ändra eller lägg till följande parametrar i konfigurationsfilen pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Som du kan se måste du lägga till behörigheten för användaråtkomst här. Den första kolumnen är anslutningstypen, som kan vara värd eller lokal. Sedan måste du ange databas (replikering), användare, käll-IP-adress och autentiseringsmetod. För att ändra denna fil krävs en omladdning av databastjänsten.
$ systemctl reload postgresql-11Du bör lägga till denna konfiguration i både primära och standbynoder, eftersom du kommer att behöva den om standbynoden befordras till master i händelse av fel.
Nu måste du skapa en replikeringsanvändare.
replikeringsroll
ROLEN (användaren) måste ha REPLICATION-behörighet för att kunna använda den i strömmande replikering.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLENär du har konfigurerat motsvarande filer och skapat användarna måste du skapa en konsekvent säkerhetskopia från den primära noden och återställa den på standbynoden.
Inställning av standby-nod
På standbynoden, gå till katalogen /var/lib/pgsql/11/ och flytta eller ta bort den aktuella datakatalogen:
$ cd /var/lib/pgsql/11/
$ mv data data.bkKör sedan kommandot pg_basebackup för att hämta den aktuella primära datakatalogen och tilldela rätt ägare (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataNu måste du använda följande grundläggande konfiguration för att skapa en Async-replikering. Filen som kommer att ändras är postgresql.conf, och du måste skapa en ny recovery.conf-fil. Båda kommer att finnas i /var/lib/pgsql/11/.
Recovery.conf
Ange att denna server ska vara en standby-server. Om den är på kommer servern att fortsätta att återställa genom att hämta nya WAL-segment när slutet av arkiverad WAL nås.
standby_mode = 'on'Ange en anslutningssträng som ska användas för att standby-servern ska ansluta till den primära noden.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Ange återställning till en viss tidslinje. Standard är att återställa längs samma tidslinje som var aktuell när bassäkerhetskopian togs. Om du ställer in detta på "senast" återställs till den senaste tidslinjen som finns i arkivet.
recovery_target_timeline = 'latest'Ange en triggerfil vars närvaro avslutar återställningen i vänteläget.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Ändra eller lägg till följande parametrar i postgresql.conf-konfigurationsfilen.
Bestämma hur mycket information som skrivs till WALs. De möjliga värdena är minimala, replika eller logiska. Hot_standby-värdet mappas till replika och används för att behålla kompatibiliteten med tidigare versioner. Att ändra detta värde kräver omstart av tjänsten.
wal_level = hot_standbyTillåt frågorna under återställningen. Att ändra detta värde kräver omstart av tjänsten.
hot_standby = onStarta standby-nod
Nu har du all nödvändig konfiguration på plats, du behöver bara starta databastjänsten på standbynoden.
$ systemctl start postgresql-11Och kontrollera databasloggarna i /var/lib/pgsql/11/data/log/. Du borde ha något sånt här:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Du kan också kontrollera replikeringsstatusen i den primära noden genom att köra följande fråga:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Som du kan se använder vi en asynkron replikering.
Konvertera asynkron PostgreSQL-replikering till synkron replikering
Nu är det dags att konvertera den här asynkrona replikeringen till en synkroniserad, och för detta måste du konfigurera både den primära noden och standbynoden.
Primär nod
I den primära PostgreSQL-noden måste du använda denna grundläggande konfiguration utöver den tidigare asynkroniserade konfigurationen.
Postgresql.conf
Ange en lista över standby-servrar som kan stödja synkron replikering. Detta väntelägesservernamn är inställningen application_name i väntelägets recovery.conf-fil.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Anger om transaktionsbekräftelse kommer att vänta på att WAL-poster skrivs till disken innan kommandot returnerar en "framgång"-indikation till klienten. De giltiga värdena är on, remote_apply, remote_write, local och off. Standardvärdet är på.
synchronous_commit = onStälla in standbynod
I PostgreSQL standby-noden måste du ändra filen recovery.conf genom att lägga till värdet 'application_name i parametern primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Starta om databastjänsten i både den primära och i standbynoderna:
$ service postgresql-11 restartNu bör du ha din synkroniseringsreplikering igång:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Återställning från synkron till asynkron PostgreSQL-replikering
Om du behöver gå tillbaka till asynkron PostgreSQL-replikering behöver du bara återställa ändringarna som utförts i postgresql.conf-filen på den primära noden:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onOch starta om databastjänsten.
$ service postgresql-11 restartSå nu bör du ha asynkron replikering igen.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Hur man distribuerar en PostgreSQL Synchronous Replikering med ClusterControl
Med ClusterControl kan du utföra driftsättning, konfiguration och övervakningsuppgifter allt-i-ett från samma jobb och du kommer att kunna hantera det från samma användargränssnitt.
Vi antar att du har ClusterControl installerat och att den kan komma åt databasnoderna via SSH. För mer information om hur du konfigurerar ClusterControl-åtkomsten, se vår officiella dokumentation.
Gå till ClusterControl och använd alternativet "Deploy" för att skapa ett nytt PostgreSQL-kluster.
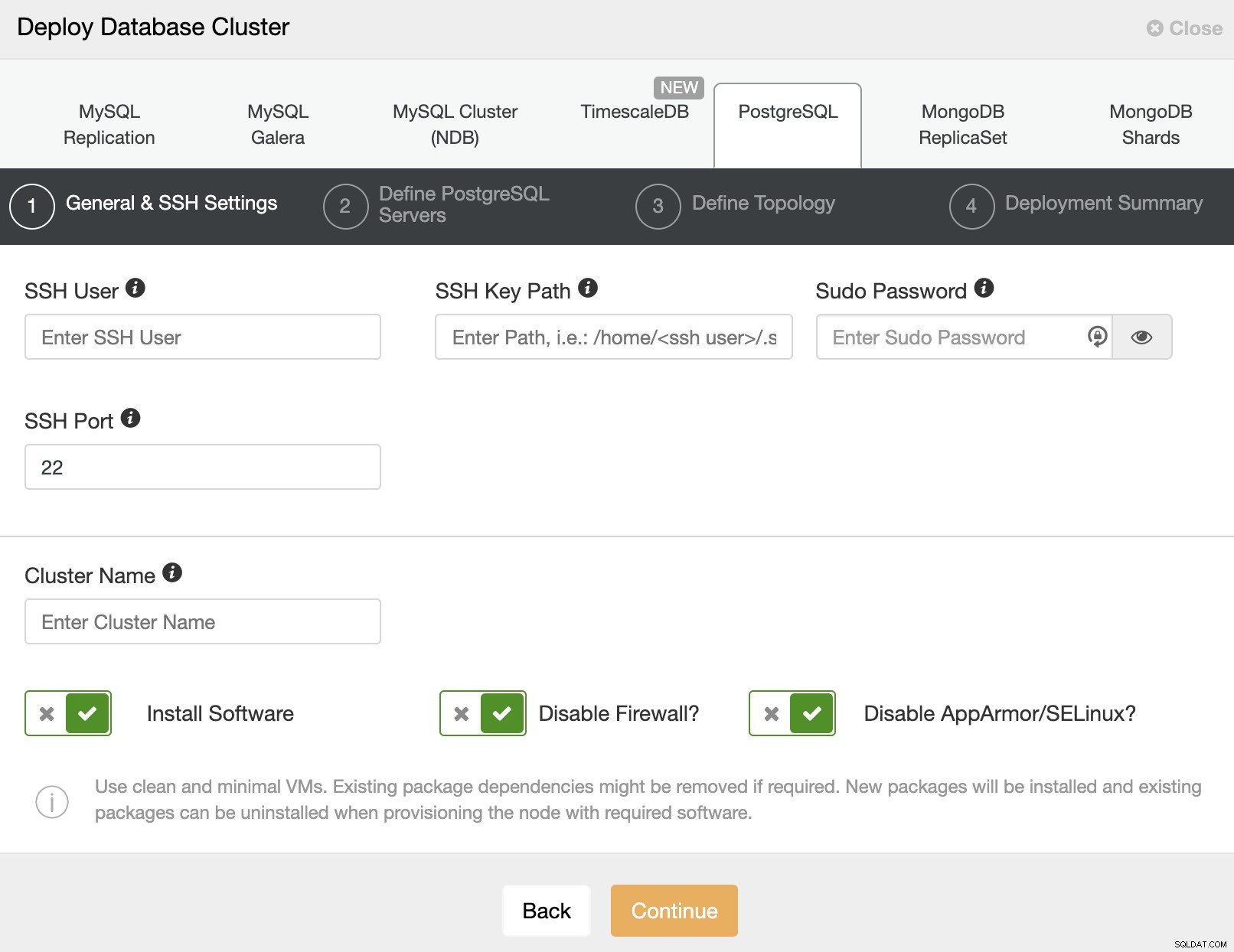
När du väljer PostgreSQL måste du ange Användare, Nyckel eller Lösenord och en port för att ansluta med SSH till våra servrar. Du behöver också ett namn för ditt nya kluster och om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
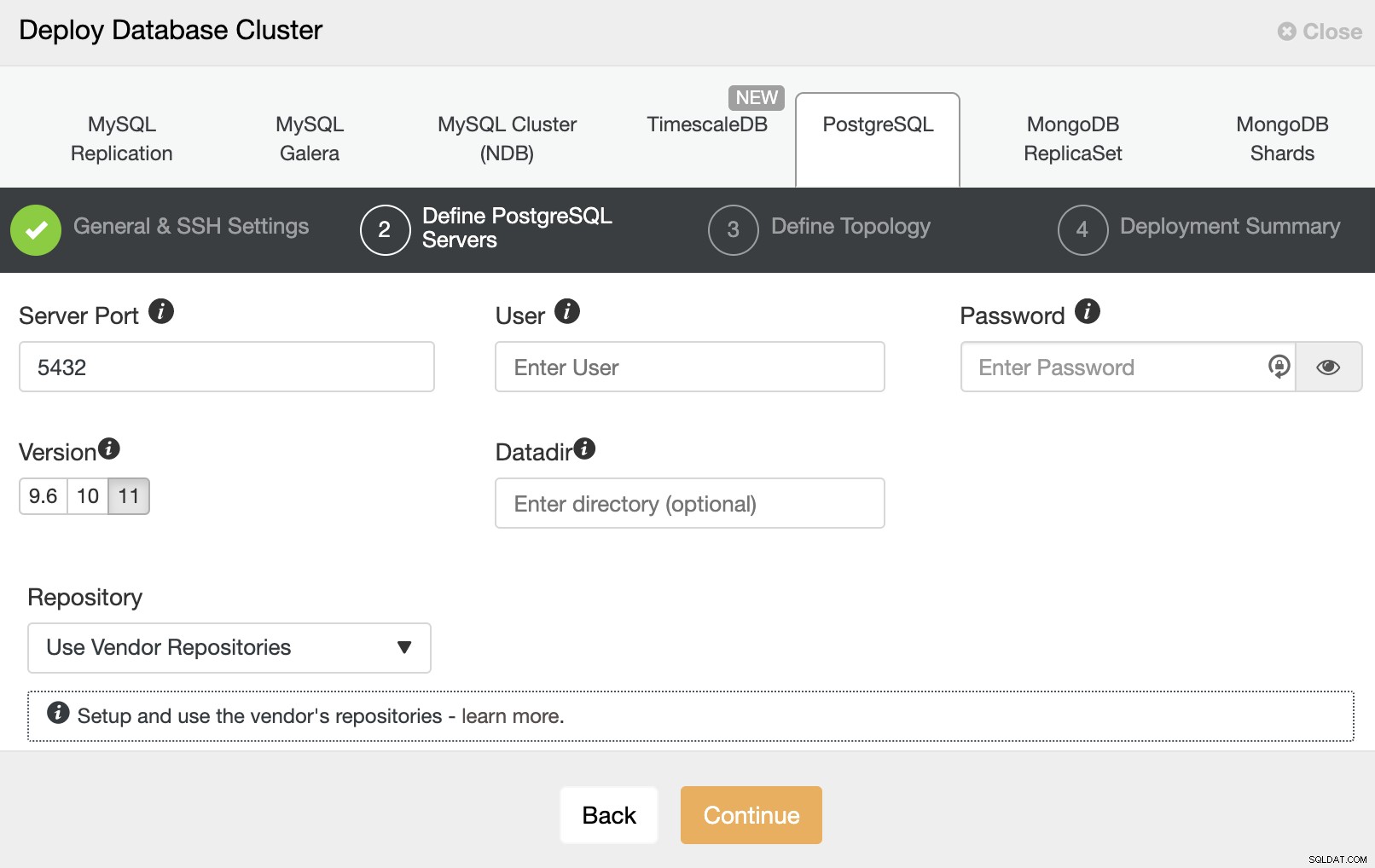
När du har ställt in SSH-åtkomstinformationen måste du ange data för att komma åt din databas. Du kan också ange vilket arkiv som ska användas.
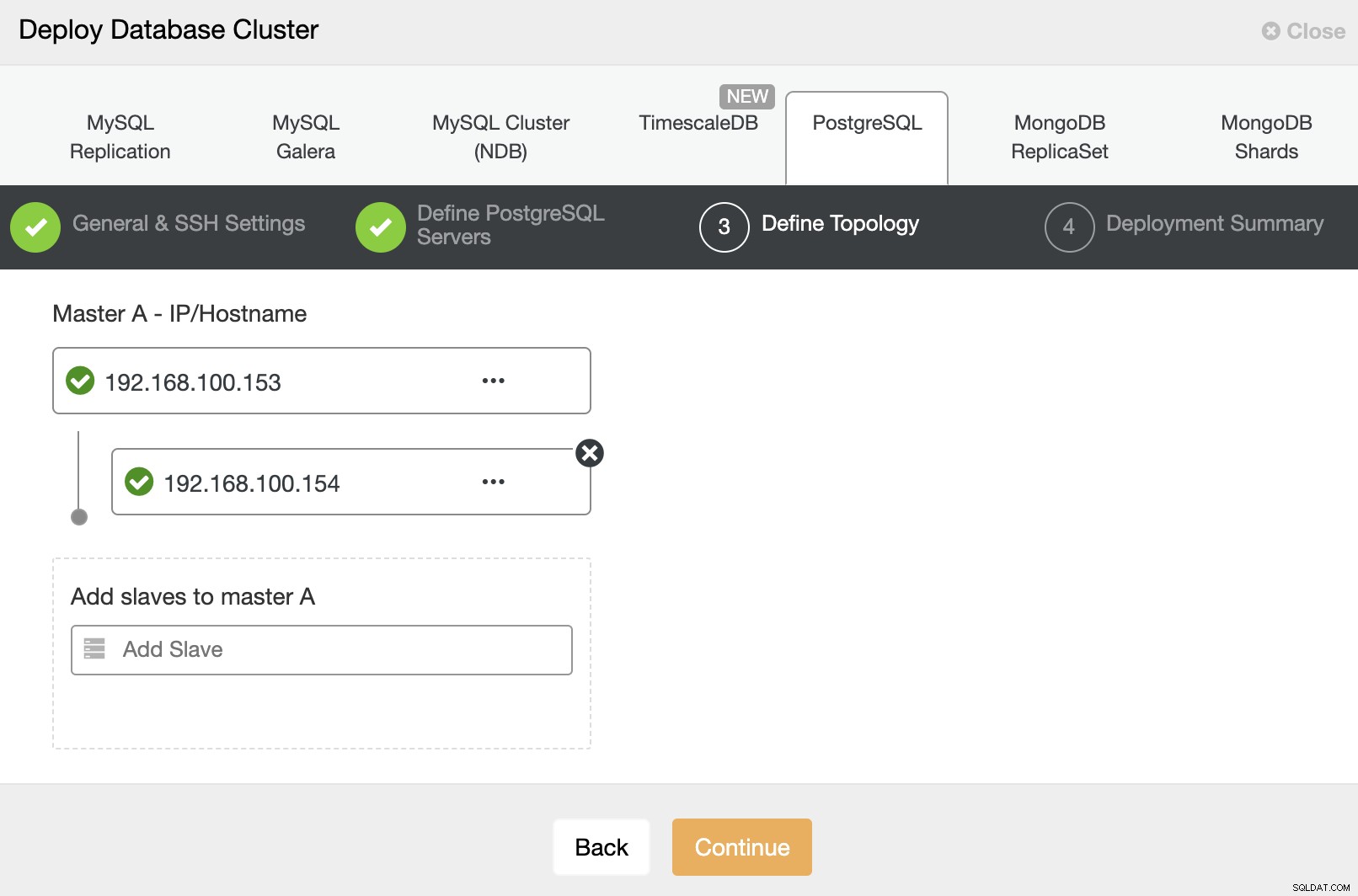
I nästa steg måste du lägga till dina servrar i klustret som du ska skapa. När du lägger till dina servrar kan du ange IP eller värdnamn.
Och slutligen, i det sista steget, kan du välja replikeringsmetoden, som kan vara asynkron eller synkron replikering.
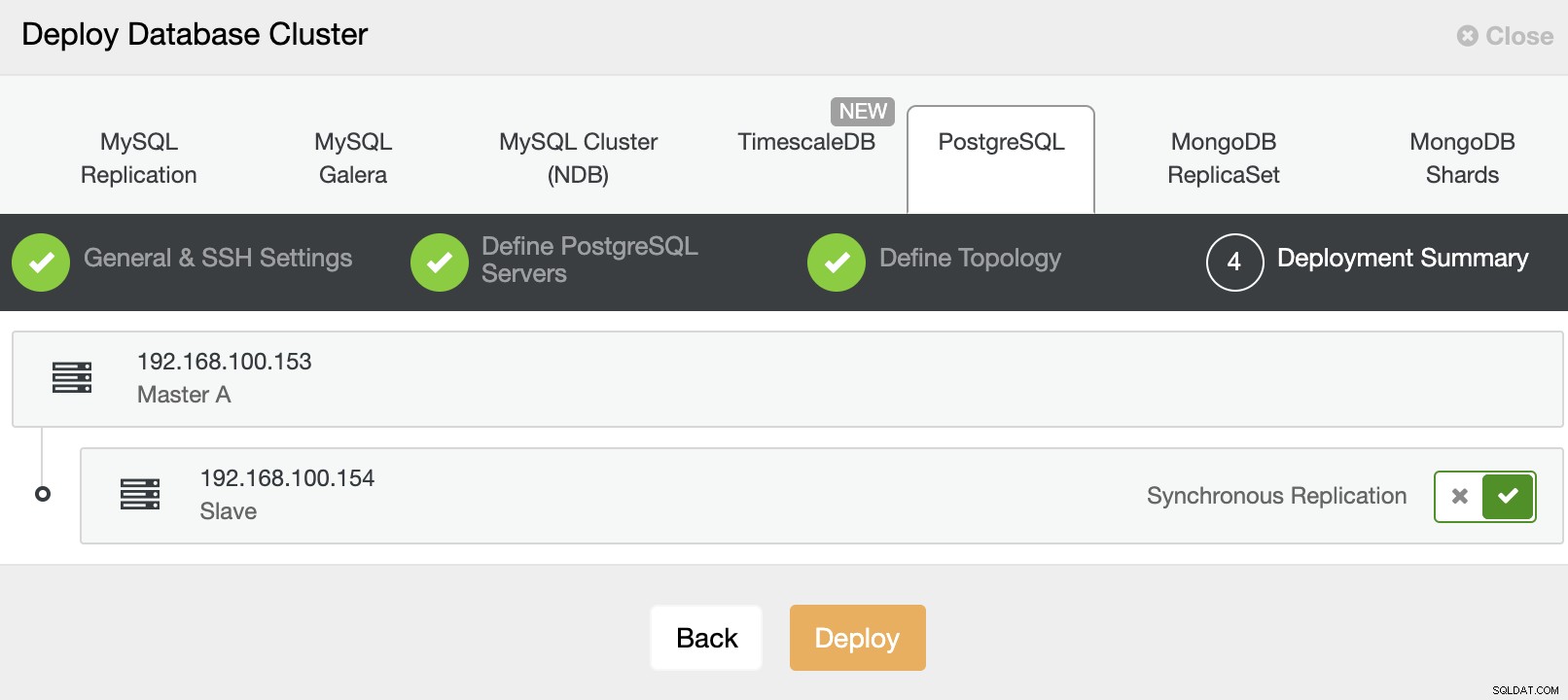
Det var allt. Du kan övervaka jobbstatus i avsnittet ClusterControl-aktivitet.
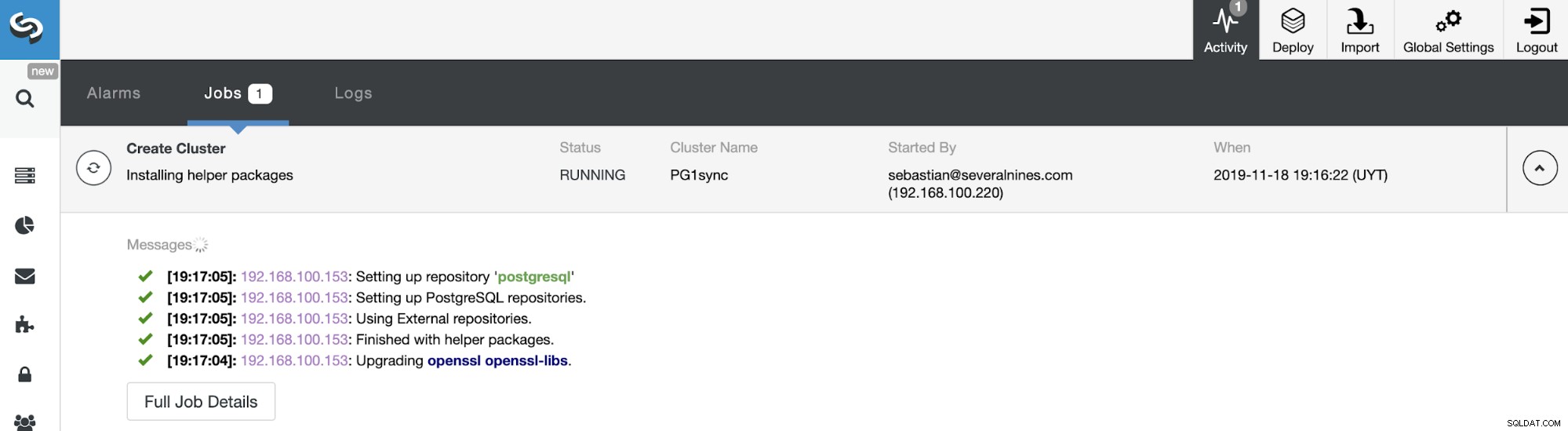
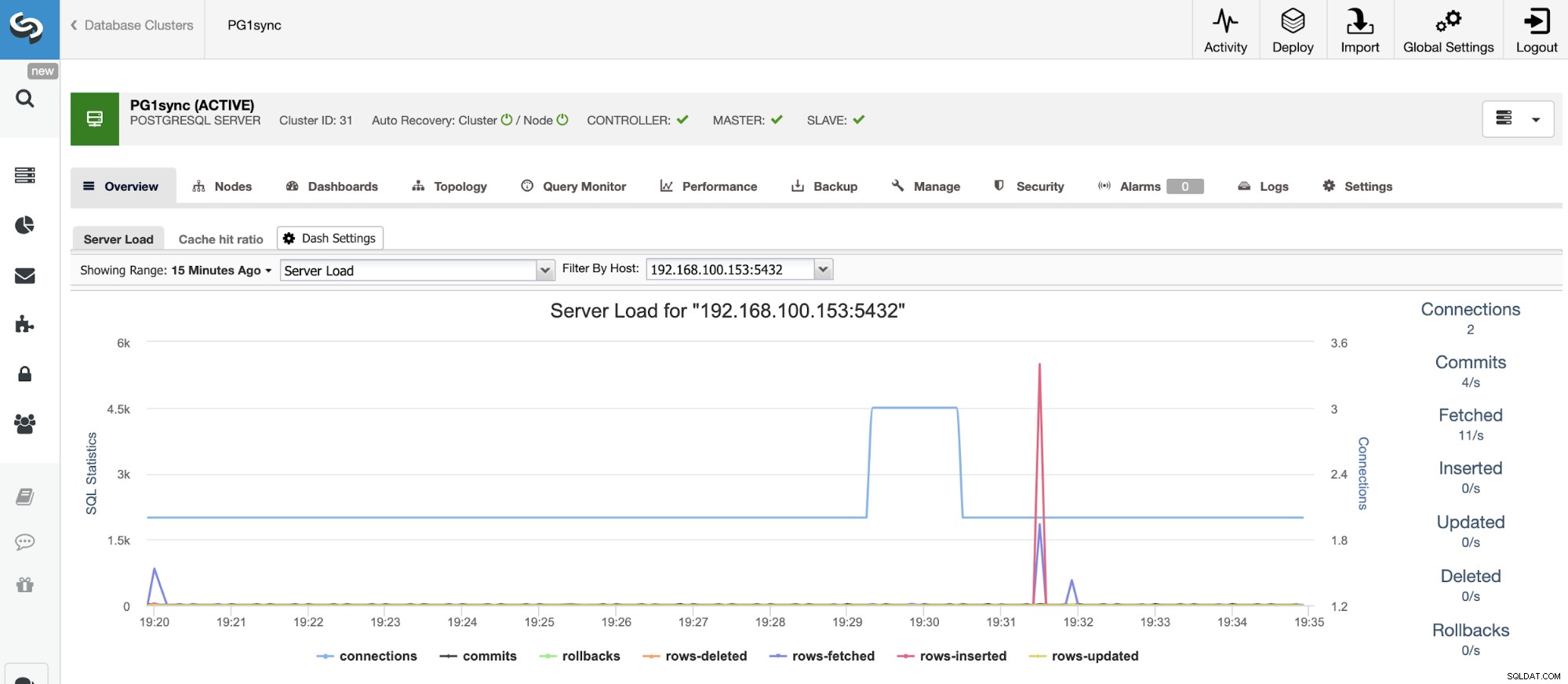
Och när det här jobbet är klart kommer du att ha ditt PostgreSQL synkrona kluster installerat, konfigureras och övervakas av ClusterControl.
Slutsats
Som vi nämnde i början av den här bloggen är hög tillgänglighet ett krav för alla företag, så du bör känna till de tillgängliga alternativen för att uppnå det för varje teknik som används. För PostgreSQL kan du använda synkron streamingreplikering som det säkraste sättet att implementera det, men den här metoden fungerar inte för alla miljöer och arbetsbelastningar.
Var försiktig med latensen som genereras genom att vänta på bekräftelsen av varje transaktion som kan vara ett problem istället för en lösning med hög tillgänglighet.