TeamCity är en server för kontinuerlig integration och kontinuerlig leverans byggd i Java. Den är tillgänglig som en molntjänst och lokalt. Som du kan föreställa dig är kontinuerliga integrations- och leveransverktyg avgörande för mjukvaruutveckling, och deras tillgänglighet måste vara opåverkad. Lyckligtvis kan TeamCity distribueras i ett mycket tillgängligt läge.
Det här blogginlägget kommer att täcka förberedelser och driftsättning av en mycket tillgänglig miljö för TeamCity.
Miljön
TeamCity består av flera element. Det finns en Java-applikation och en databas som säkerhetskopierar det. Den använder också agenter som kommunicerar med den primära TeamCity-instansen. Den mycket tillgängliga distributionen består av flera TeamCity-instanser, där en fungerar som den primära och de andra sekundär. Dessa instanser delar åtkomst till samma databas och datakatalogen. Ett användbart schema är tillgängligt på TeamCity-dokumentationssidan, som visas nedan:

Som vi kan se finns det två delade element – datakatalogen och databasen. Vi måste se till att de också är mycket tillgängliga. Det finns olika alternativ som du kan använda för att bygga ett delat fäste; men vi kommer att använda GlusterFS. När det gäller databasen kommer vi att använda ett av de relationsdatabashanteringssystem som stöds – PostgreSQL, och vi kommer att använda ClusterControl för att bygga en hög tillgänglighetsstack baserad runt den.
Hur man konfigurerar GlusterFS
Låt oss börja med grunderna. Vi vill konfigurera värdnamn och /etc/hosts på våra TeamCity-noder, där vi också kommer att distribuera GlusterFS. För att göra det måste vi ställa in arkivet för de senaste paketen av GlusterFS på dem alla:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateDå kan vi installera GlusterFS på alla våra TeamCity-noder:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS använder port 24007 för anslutning mellan noderna; vi måste se till att den är öppen och tillgänglig för alla noder.
När anslutningen är på plats kan vi skapa ett GlusterFS-kluster genom att köra från en nod:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Nu kan vi testa hur statusen ser ut:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Det verkar som att allt är bra och anslutningen är på plats.
Närnäst bör vi förbereda en blockenhet som ska användas av GlusterFS. Detta måste utföras på alla noder. Skapa först en partition:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Formatera sedan den partitionen:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Slutligen, på alla noder måste vi skapa en katalog som kommer att användas för att montera partitionen och redigera fstab för att säkerställa att den kommer att monteras vid start:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabLåt oss nu verifiera att detta fungerar:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Nu kan vi använda en av noderna för att skapa och starta GlusterFS-volymen:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successObservera att vi använder värdet "3" för antalet repliker. Det betyder att varje volym kommer att finnas i tre exemplar. I vårt fall kommer varje block, varje /dev/sdb1-volym på alla noder att innehålla all data.
När volymerna har startat kan vi verifiera deras status:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksSom du kan se ser allt ok ut. Det som är viktigt är att GlusterFS valde port 49152 för åtkomst till den volymen, och vi måste se till att den är tillgänglig på alla noder där vi ska montera den.
Nästa steg blir att installera GlusterFS-klientpaketet. För det här exemplet behöver vi det installerat på samma noder som GlusterFS-servern:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Därefter måste vi skapa en katalog på alla noder som ska användas som en delad datakatalog för TeamCity. Detta måste hända på alla noder:
example@sqldat.com:~# sudo mkdir /teamcity-storageMontera slutligen GlusterFS-volymen på alla noder:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageDetta slutför förberedelserna för delad lagring.
Bygga ett mycket tillgängligt PostgreSQL-kluster
När installationen av delad lagring för TeamCity är klar kan vi nu bygga vår högtillgängliga databasinfrastruktur. TeamCity kan använda olika databaser; men vi kommer att använda PostgreSQL i den här bloggen. Vi kommer att utnyttja ClusterControl för att distribuera och sedan hantera databasmiljön.
TeamCitys guide för att bygga utplacering med flera noder är användbar, men den verkar utelämna den höga tillgängligheten för allt annat än TeamCity. TeamCitys guide föreslår en NFS- eller SMB-server för datalagring, som i sig inte har redundans och kommer att bli en enda felpunkt. Vi har åtgärdat detta genom att använda GlusterFS. De nämner en delad databas, eftersom en enda databasnod uppenbarligen inte ger hög tillgänglighet. Vi måste bygga en ordentlig stack:

I vårt fall. den kommer att bestå av tre PostgreSQL-noder, en primär och två repliker. Vi kommer att använda HAProxy som en lastbalanserare och använda Keepalived för att hantera virtuell IP för att tillhandahålla en enda slutpunkt för applikationen att ansluta till. ClusterControl kommer att hantera fel genom att övervaka replikeringstopologin och utföra eventuell återställning efter behov, som att starta om misslyckade processer eller misslyckas över till en av replikerna om den primära noden går ner.
Till att börja kommer vi att distribuera databasnoderna. Tänk på att ClusterControl kräver SSH-anslutning från ClusterControl-noden till alla noder som den hanterar.

Sedan väljer vi en användare som vi ska använda för att ansluta till databas, dess lösenord och PostgreSQL-versionen att distribuera:

Närnäst kommer vi att definiera vilka noder som ska användas för att distribuera PostgreSQL :
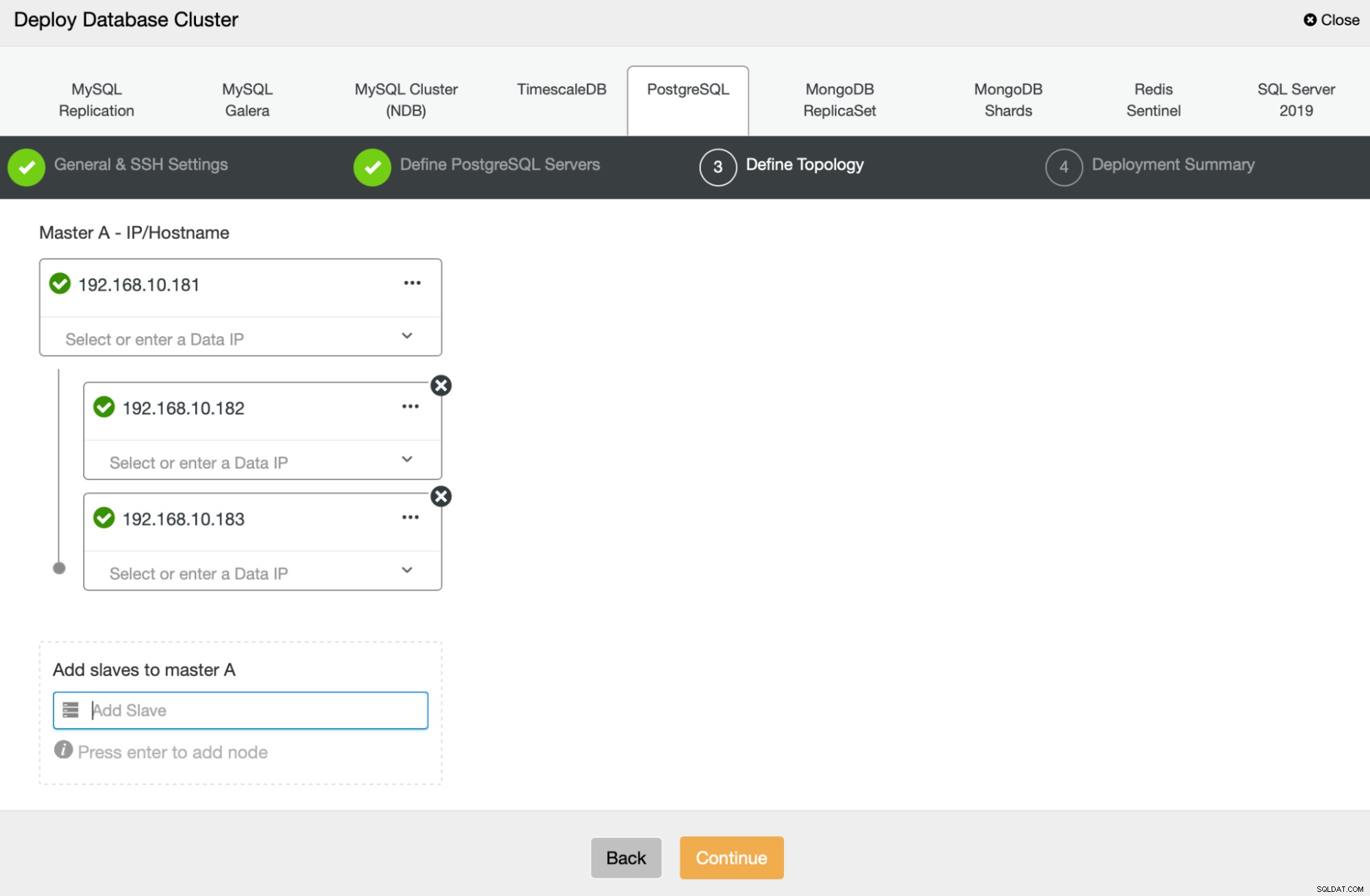
Slutligen kan vi definiera om noderna ska använda asynkron eller synkron replikering. Den största skillnaden mellan dessa två är att synkron replikering säkerställer att varje transaktion som körs på den primära noden alltid kommer att replikeras på replikerna. Men synkron replikering saktar också ner commit. Vi rekommenderar att du aktiverar synkron replikering för bästa hållbarhet, men du bör kontrollera senare om prestandan är acceptabel.

När vi har klickat på “Distribuera”, startar ett distributionsjobb. Vi kan övervaka dess framsteg på fliken Aktivitet i ClusterControl UI. Vi bör så småningom se att jobbet har slutförts och att klustret har implementerats framgångsrikt.

Distribuera HAProxy-instanser genom att gå till Hantera -> Lastbalanserare. Välj HAProxy som lastbalanserare och fyll i formuläret. Det viktigaste valet är var du vill distribuera HAProxy. Vi använde en databasnod i det här fallet, men i en produktionsmiljö vill du med största sannolikhet separera lastbalanserare från databasinstanser. Välj sedan vilka PostgreSQL-noder som ska inkluderas i HAProxy. Vi vill ha dem alla.

Nu startar HAProxy-distributionen. Vi vill upprepa det åtminstone en gång till för att skapa två HAProxy-instanser för redundans. I den här implementeringen bestämde vi oss för att använda tre HAProxy-lastbalanserare. Nedan är en skärmdump av inställningsskärmen när du konfigurerar distributionen av en andra HAProxy:
När alla våra HAProxy-instanser är igång kan vi distribuera Keepalived . Tanken här är att Keepalved kommer att samlokaliseras med HAProxy och övervaka HAProxys process. En av instanserna med fungerande HAProxy kommer att ha Virtual IP tilldelad. Denna VIP ska användas av applikationen för att ansluta till databasen. Keepalived kommer att upptäcka om den HAProxy blir otillgänglig och flyttar till en annan tillgänglig HAProxy-instans.
Implementeringsguiden kräver att vi skickar HAProxy-instanser som vi vill att Keelived ska övervaka. Vi måste också skicka IP-adressen och nätverksgränssnittet för VIP.

Det sista och sista steget blir att skapa en databas för TeamCity:

Med detta har vi avslutat distributionen av det mycket tillgängliga PostgreSQL-klustret.
Distribuera TeamCity som multi-nod
Nästa steg är att distribuera TeamCity i en miljö med flera noder. Vi kommer att använda tre TeamCity-noder. Först måste vi installera Java JRE och JDK som matchar TeamCitys krav.
apt install default-jre default-jdkNu, på alla noder, måste vi ladda ner TeamCity. Vi kommer att installera i en lokal, inte delad katalog.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzDå kan vi starta TeamCity på en av noderna:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logNär TeamCity har startat kan vi komma åt användargränssnittet och börja implementera. Till en början måste vi passera datakatalogen. Det här är den delade volymen vi skapade på GlusterFS.

Välj sedan databasen. Vi kommer att använda ett PostgreSQL-kluster som vi redan har skapat.

Ladda ner och installera JDBC-drivrutinen:

Fyll sedan i åtkomstinformation. Vi kommer att använda den virtuella IP som tillhandahålls av Keepalved. Observera att vi använder port 5433. Detta är porten som används för läs/skrivbackend av HAProxy; den kommer alltid att peka mot den aktiva primärnoden. Välj sedan en användare och databasen som ska användas med TeamCity.

När detta är gjort kommer TeamCity att börja initiera databasstrukturen.

Godkänn licensavtalet:

Skapa slutligen en användare för TeamCity:

Det var allt! Vi bör nu kunna se TeamCity GUI:

Nu måste vi ställa in TeamCity i multi-nod-läge. Först måste vi redigera startskripten på alla noder:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shVi måste se till att följande två variabler exporteras. Kontrollera att du använder rätt värdnamn, IP och rätt kataloger för lokal och delad lagring:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"När detta är gjort kan du starta de återstående noderna:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startDu bör se följande utdata i Administration -> Nodkonfiguration:En huvudnod och två standbynoder.

Tänk på att failover i TeamCity inte är automatiserat. Om huvudnoden slutar fungera bör du ansluta till en av de sekundära noderna. För att göra detta, gå till "Nodes Configuration" och främja den till "Main"-noden. Från inloggningsskärmen kommer du att se en tydlig indikation på att detta är en sekundär nod:

I "Nodes Configuration" ser du att den ena noden har tappade från klustret:

Du kommer att få ett meddelande om att du inte kan skriva till denna nod. Oroa dig inte; skrivningen som krävs för att främja denna nod till "huvud"-status kommer att fungera bra:

Klicka på "Aktivera" så har vi framgångsrikt marknadsfört en sekundär TimeCity-nod:

När nod1 blir tillgänglig och TeamCity startas igen på den noden kommer vi att se den gå med i klustret igen:

Om du vill förbättra prestandan ytterligare kan du distribuera HAProxy + Keepalved framför TeamCity UI för att tillhandahålla en enda ingångspunkt till GUI. Du kan hitta information om hur du konfigurerar HAProxy för TeamCity i dokumentationen.
Avsluta
Som du kan se är det inte så svårt att distribuera TeamCity för hög tillgänglighet – det mesta har täckts noggrant i dokumentationen. Om du letar efter sätt att automatisera en del av detta och lägga till en mycket tillgänglig databasbackend, överväg att utvärdera ClusterControl gratis i 30 dagar. ClusterControl kan snabbt distribuera och övervaka backend, vilket ger automatisk failover, återställning, övervakning, säkerhetskopieringshantering och mer.
För fler tips om mjukvaruutvecklingsverktyg och bästa praxis, kolla in hur du stödjer ditt DevOps-team med deras databasbehov.
För att få de senaste nyheterna och bästa praxis för att hantera din öppen källkodsbaserad databasinfrastruktur, glöm inte att följa oss på Twitter eller LinkedIn och prenumerera på vårt nyhetsbrev. Vi ses snart!