Övervakning är en av de grundläggande uppgifterna i alla system. Det kan hjälpa oss att upptäcka problem och vidta åtgärder, eller helt enkelt att veta det aktuella tillståndet för våra system. Att använda visuella skärmar kan göra oss mer effektiva eftersom vi lättare kan upptäcka prestandaproblem.
I den här bloggen kommer vi att se hur man använder SCUMM för att övervaka våra PostgreSQL-databaser och vilka mätvärden vi kan använda för denna uppgift. Vi går också igenom de tillgängliga instrumentpanelerna så att du enkelt kan ta reda på vad som verkligen händer med dina PostgreSQL-instanser.
Vad är SCUMM?
Först och främst, låt oss se vad som är SCUMM (Severalnines ClusterControl Unified Monitoring and Management ).
Det är en ny agentbaserad lösning med agenter installerade på databasnoderna.
SCUMM-agenterna är Prometheus-exportörer som exporterar mätvärden från tjänster som PostgreSQL som Prometheus-mätvärden.
En Prometheus-server används för att skrapa och lagra tidsseriedata från SCUMM-agenterna.
Prometheus är en övervaknings- och varningsverktygssats med öppen källkod som ursprungligen byggdes på SoundCloud. Det är nu ett fristående projekt med öppen källkod och underhålls oberoende.
Prometheus är designad för tillförlitlighet, för att vara systemet du går till under ett avbrott så att du snabbt kan diagnostisera problem.
Hur använder man SCUMM?
När vi använder ClusterControl, när vi väljer ett kluster, kan vi se en översikt över våra databaser, samt några grundläggande mätvärden som kan användas för att identifiera ett problem. I instrumentpanelen nedan kan vi se en master-slave-inställning med en master och 2 slavar, med HAProxy och Keepalved.
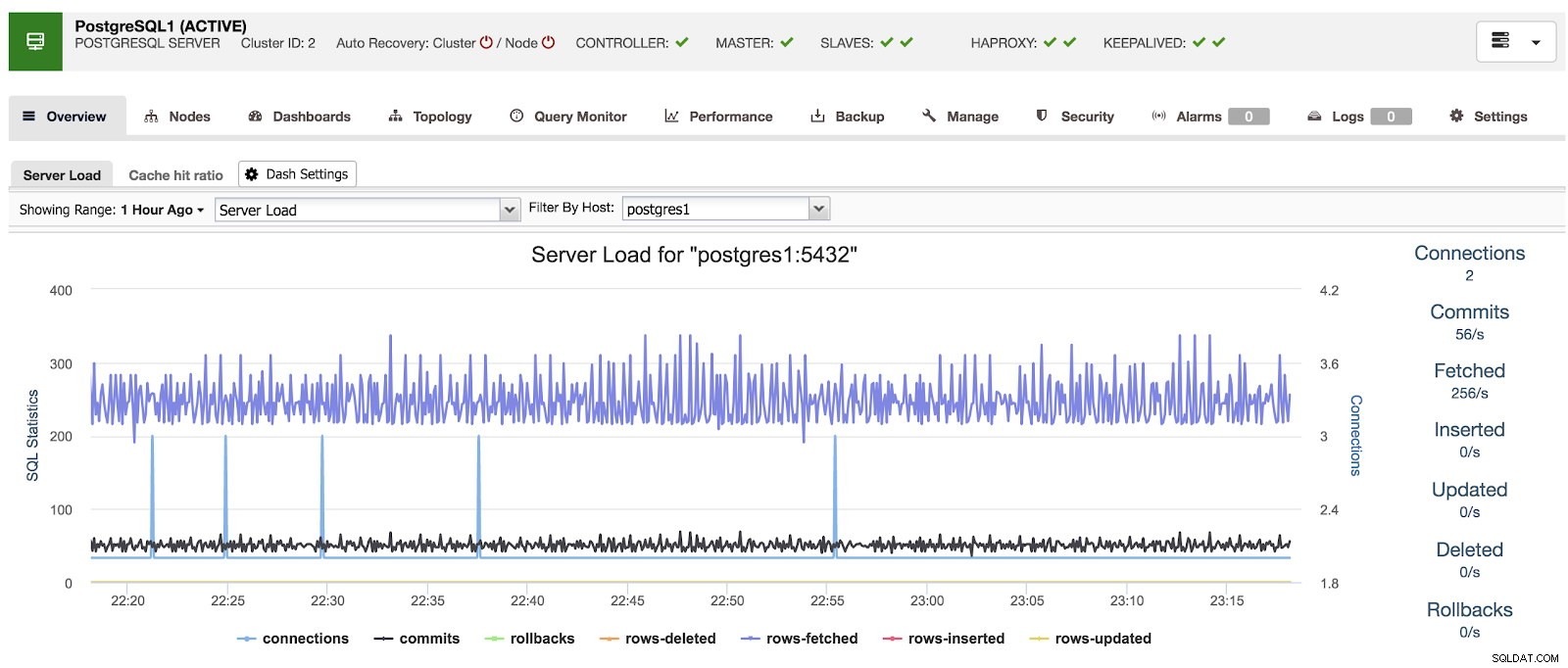 ClusterControl Översikt
ClusterControl Översikt Om vi går till alternativet "Dashboards" kan vi se ett meddelande som följande.
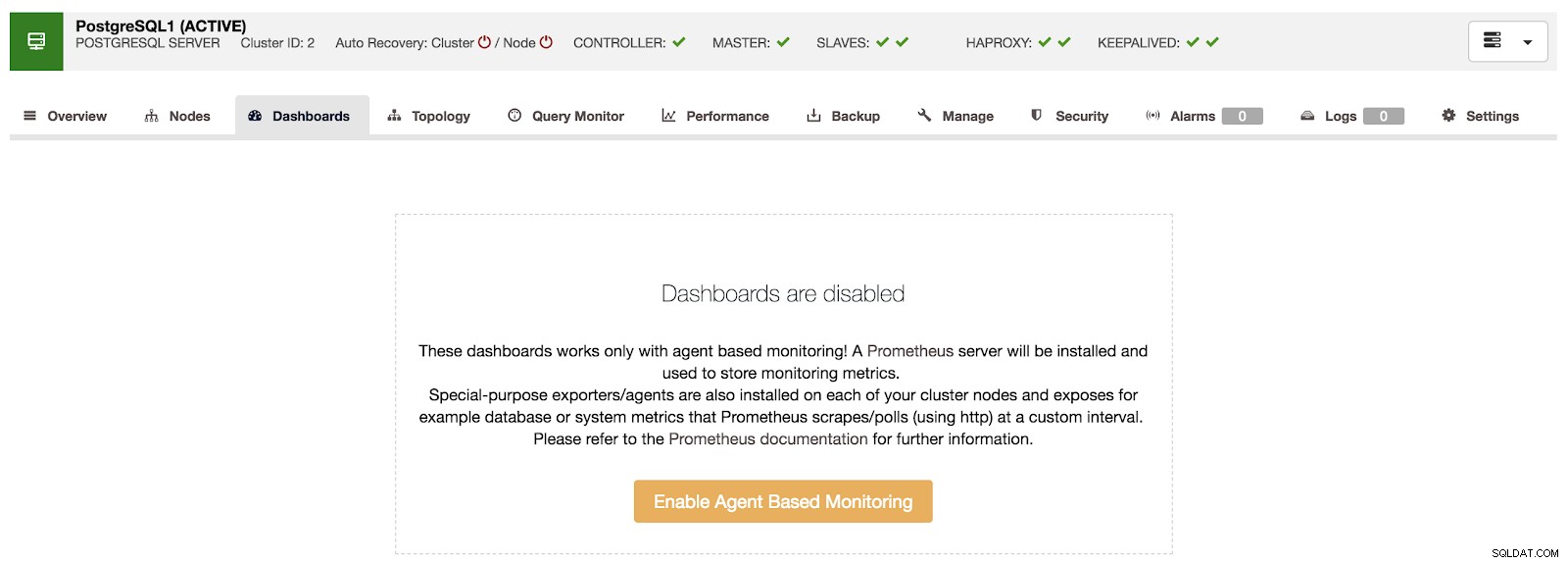 ClusterControl Dashboards inaktiverad
ClusterControl Dashboards inaktiverad För att använda den här funktionen måste vi aktivera agenten som nämns ovan. För detta behöver vi bara trycka på knappen "Aktivera agentbaserad övervakning" i det här avsnittet.
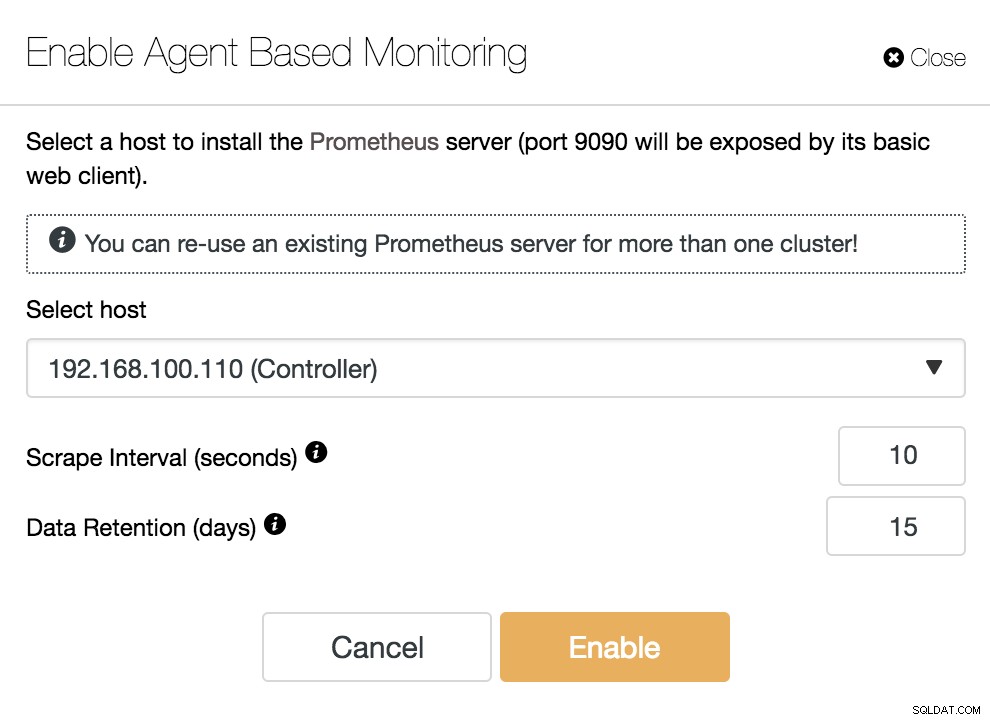 ClusterControl Aktivera agentbaserad övervakning
ClusterControl Aktivera agentbaserad övervakning För att aktivera vår agent måste vi ange den värd där vi ska installera vår Prometheus-server, som, som vi kan se i exemplet, kan vara vår ClusterControl-server.
Vi måste också specificera:
- Scrape Interval (sekunder):Ange hur ofta noderna ska skrapas för mätvärden. Standard är 10 sekunder.
- Datalagring (dagar):Ange hur länge mätvärdena sparas innan de tas bort. Standard är 15 dagar.
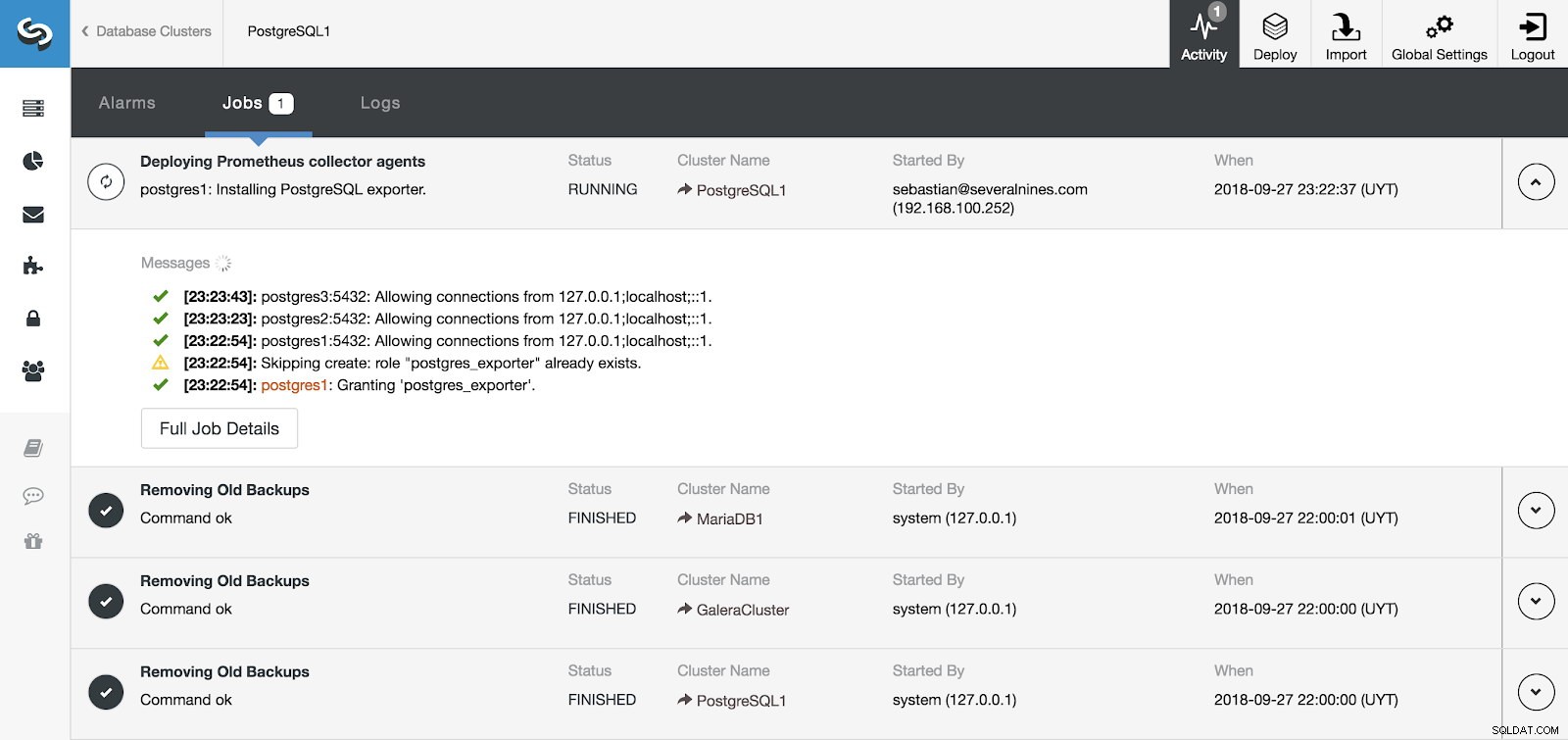 ClusterControl Activity Section
ClusterControl Activity Section Vi kan övervaka installationen av vår server och agenter från aktivitetssektionen i ClusterControl och när den är klar kan vi se vårt kluster med agenterna aktiverade från ClusterControls huvudskärm.
 ClusterControl Agents aktiverade
ClusterControl Agents aktiverade Instrumentpaneler
Om vi har våra agenter aktiverade, om vi går till avsnittet Dashboards, skulle vi se något sånt här:
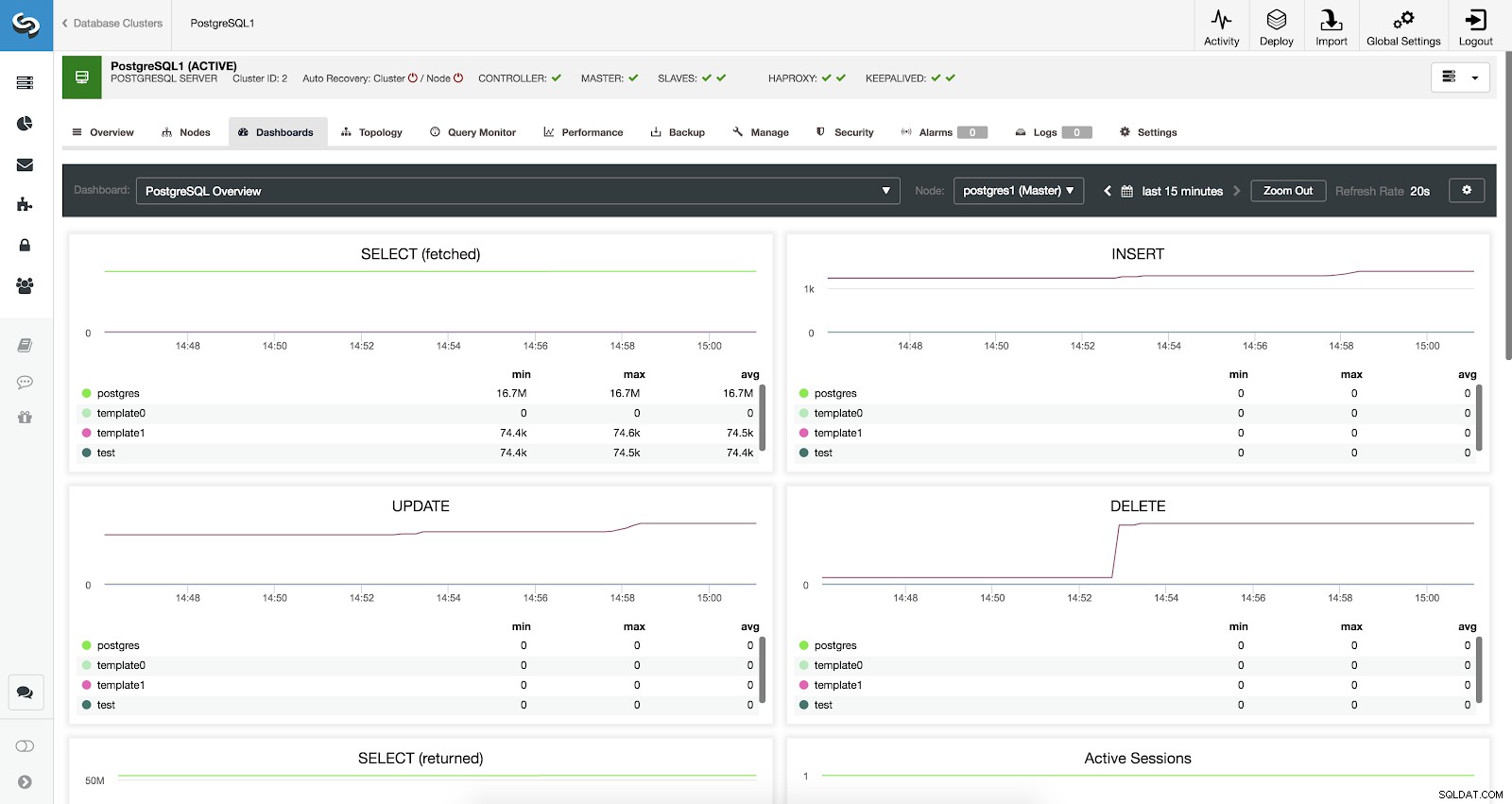 ClusterControl Dashboards aktiverade
ClusterControl Dashboards aktiverade Vi har tre olika typer av instrumentpaneler tillgängliga, Systemöversikt, Cross Server Graphs och PostgreSQL-översikt. Den sista är vad vi ser som standard när vi går in i det här avsnittet.
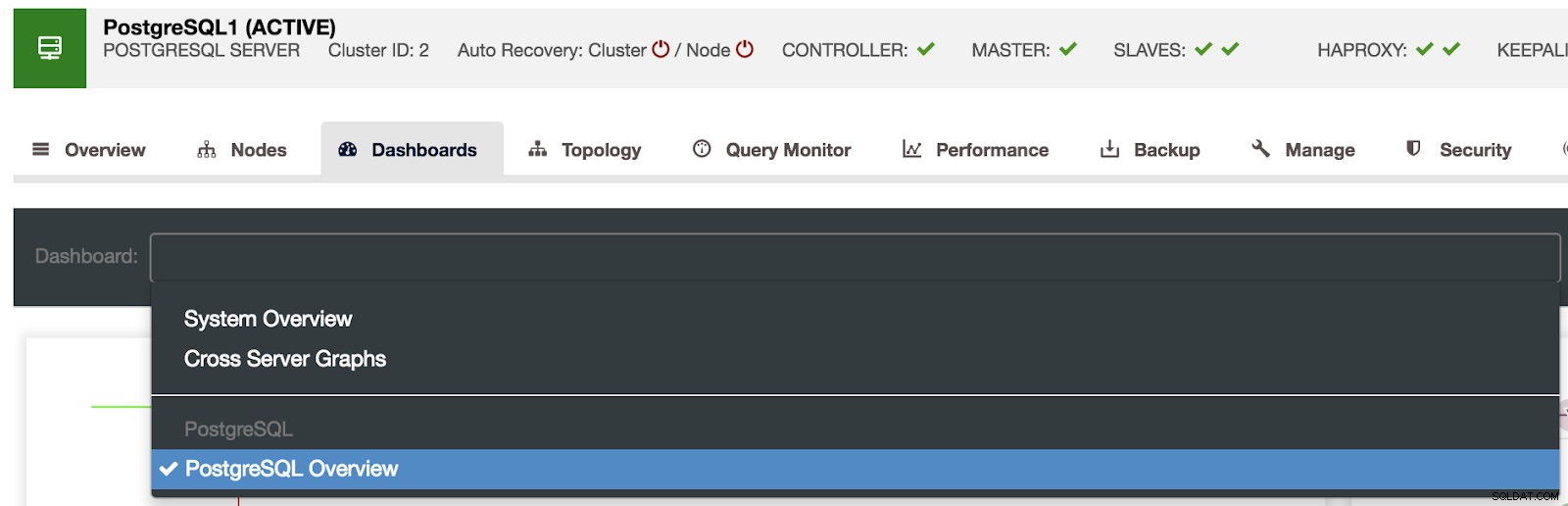 Val av ClusterControl Dashboards
Val av ClusterControl Dashboards Här kan vi också specificera vilken nod som ska övervakas, tidsintervall och uppdateringsfrekvens.
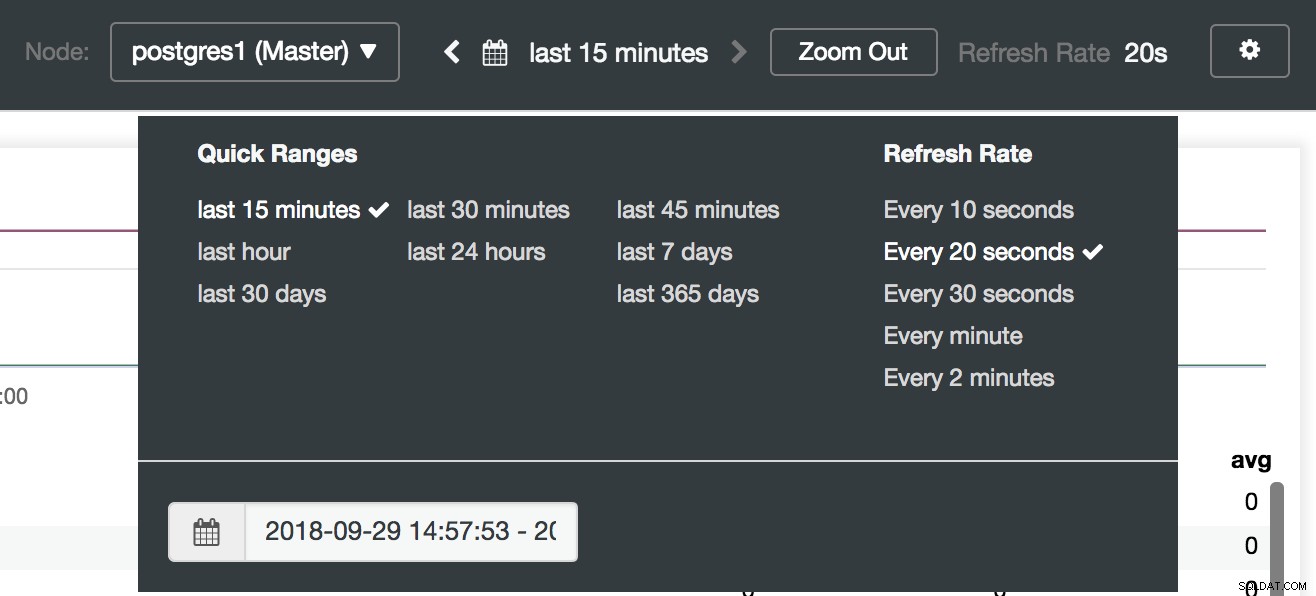 Alternativ för ClusterControl Dashboard
Alternativ för ClusterControl Dashboard I konfigurationsavsnittet kan vi aktivera eller inaktivera våra agenter (exportörer), kontrollera agenternas status och verifiera versionen av vår Prometheus-server.
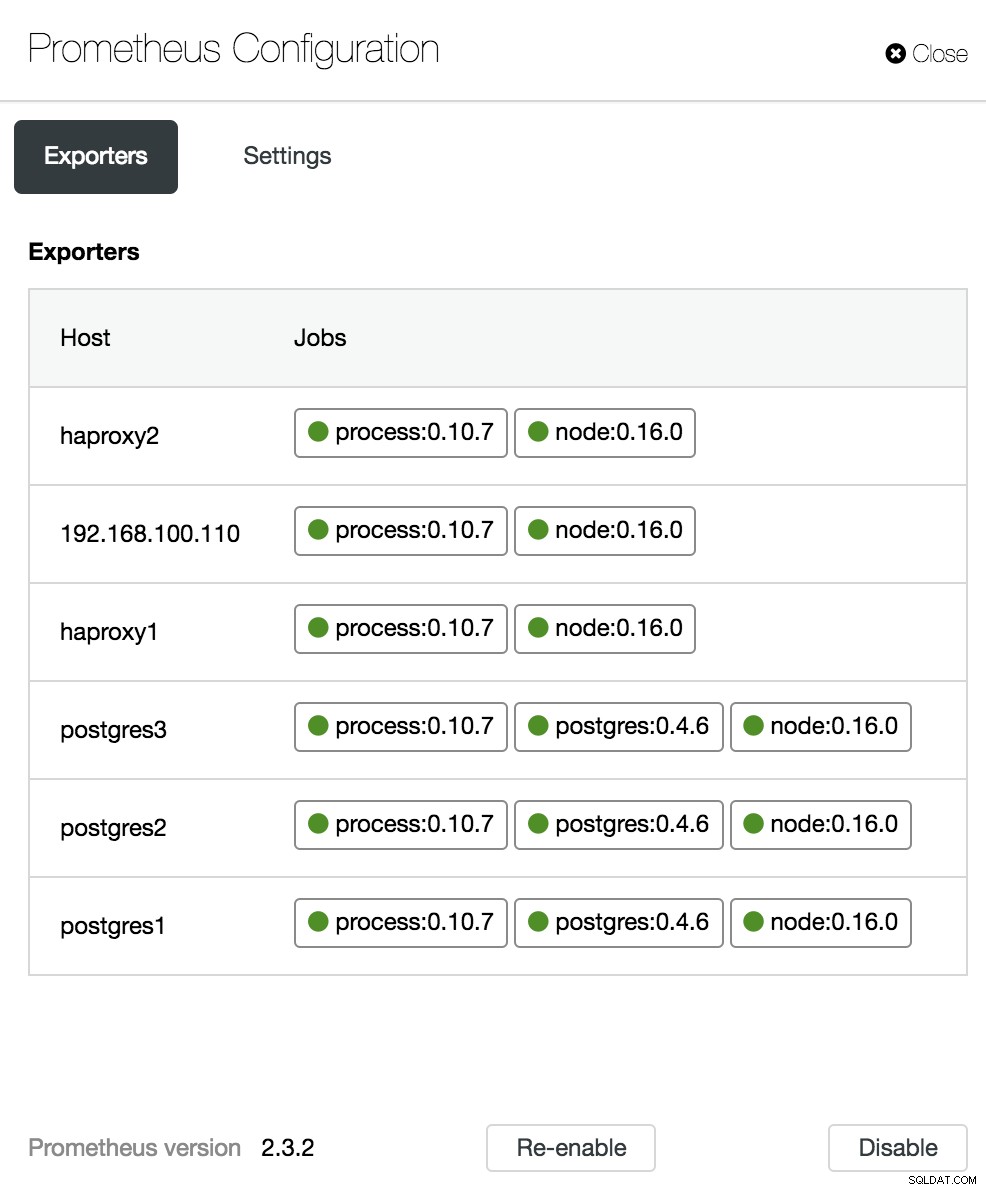 Konfiguration av ClusterControl Dashboard
Konfiguration av ClusterControl Dashboard PostgreSQL-översiktsstatistik
Låt oss nu se vilka mätvärden vi har tillgängliga för var och en av våra PostgreSQL-databaser (alla för den valda noden).
- SELECT (hämtat):Antalet rader som valts (hämtat) för varje databas. De hämtade raderna hänvisar till liverader som hämtats från tabellen.
- SELECT (returnerat):Antalet rader valda (returnerade) för varje databas. De returnerade raderna hänvisar till alla rader som läses från tabellen, som inkluderar döda rader och rader som ännu inte har registrerats (i motsats till de hämtade raderna som endast räknar de levande tuplarna).
- INSERT:Antalet rader som infogats för varje databas.
- UPPDATERING:Antalet rader som uppdateras för varje databas.
- DELETE:Antal rader som tagits bort för varje databas.
- Aktiva sessioner:Antalet aktiva sessioner (min, max och genomsnitt) för varje databas.
- Inaktiva sessioner:Antalet lediga sessioner (min, max och genomsnitt) för varje databas.
- Låstabeller:Antalet lås (min, max och genomsnitt) separerade efter typ för varje databas.
- Disk IO-användning:Serverdisk IO-användning.
- Diskanvändning:Serverdiskanvändning i procent (min, max och genomsnitt).
- Disklatens:Serverdisklatens.
ClusterControl PostgreSQL översiktsstatistik Systemöversiktsstatistik
För att övervaka vårt system har vi följande mätvärden tillgängliga för varje server (alla för den valda noden):
- Systemdrifttid:Tid sedan servern var uppe.
- CPU:er:Antalet processorer.
- RAM:Mängden RAM-minne.
- Tillgängligt minne:Procentandel av tillgängligt RAM-minne.
- Belastningsmedelvärde:Min, max och genomsnittlig serverbelastning.
- Minne:Tillgängligt, totalt och använt serverminne.
- CPU-användning:Min, max och genomsnittlig server CPU-användningsinformation.
- Minnesdistribution:Minnesdistribution (buffert, cache, ledig och använd) på den valda noden.
- Mättnadsmått:Min, max och medelvärde av IO-belastning och CPU-belastning på den valda noden.
- Avancerad minnesinformation:Minnesanvändningsdetaljer som sidor, buffert och mer, på den valda noden.
- Gafflar:Antal gaffelprocesser. Gaffel är en operation där en process skapar en kopia av sig själv. Det är vanligtvis ett systemanrop, implementerat i kärnan.
- Processer:Antalet processer som körs eller väntar på operativsystemet.
- Kontextväxlar:En kontextväxling är åtgärden att lagra tillståndet för en process eller en tråd.
- Avbrott:Antalet avbrott. Ett avbrott är en händelse som ändrar det normala exekveringsflödet för ett program och kan genereras av hårdvaruenheter eller till och med av processorn själv.
- Nätverkstrafik:Inkommande och utgående nätverkstrafik i KByte per sekund på den valda noden.
- Nätverksutnyttjande per timme:Trafik som skickades och togs emot under det senaste dygnet.
- Swap:Byt användning (gratis och använd) på den valda noden.
- Swap-aktivitet:Läser och skriver data om swap.
- I/O-aktivitet:Sida in och sida ut på IO.
- Filbeskrivningar:Tilldelade och begränsa filbeskrivningar.
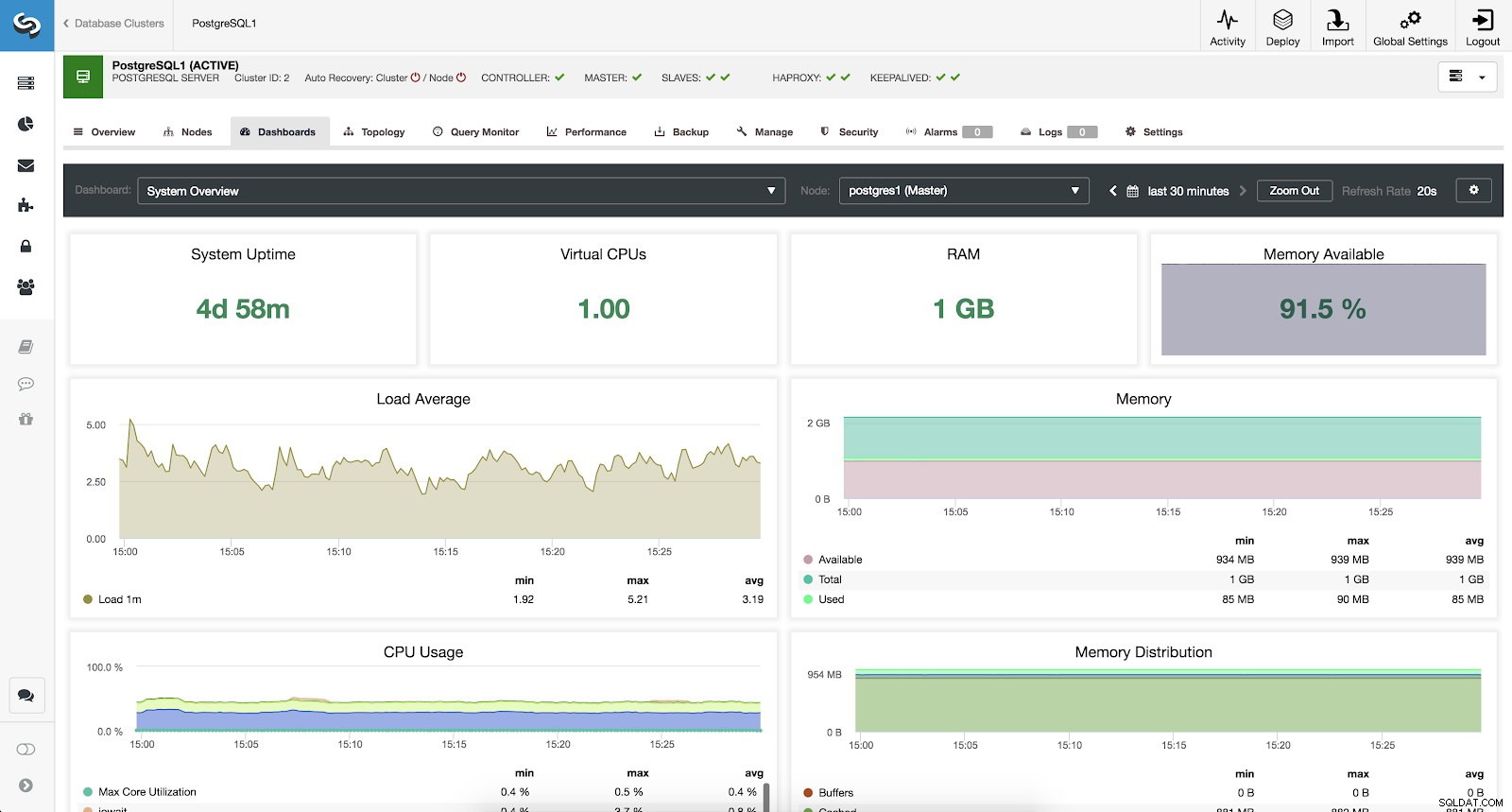 ClusterControl System Översiktsstatistik
ClusterControl System Översiktsstatistik Cross Server Graphs Metrics
Om vi vill se det allmänna tillståndet för alla våra servrar kan vi använda den här instrumentpanelen med följande mätvärden:
- Belastningsgenomsnitt:servrar laddar i genomsnitt för varje server.
- Minnesanvändning:Procentandel av minnesanvändning för varje server.
- Nätverkstrafik:Min, max och genomsnittliga kByte nätverkstrafik per sekund.
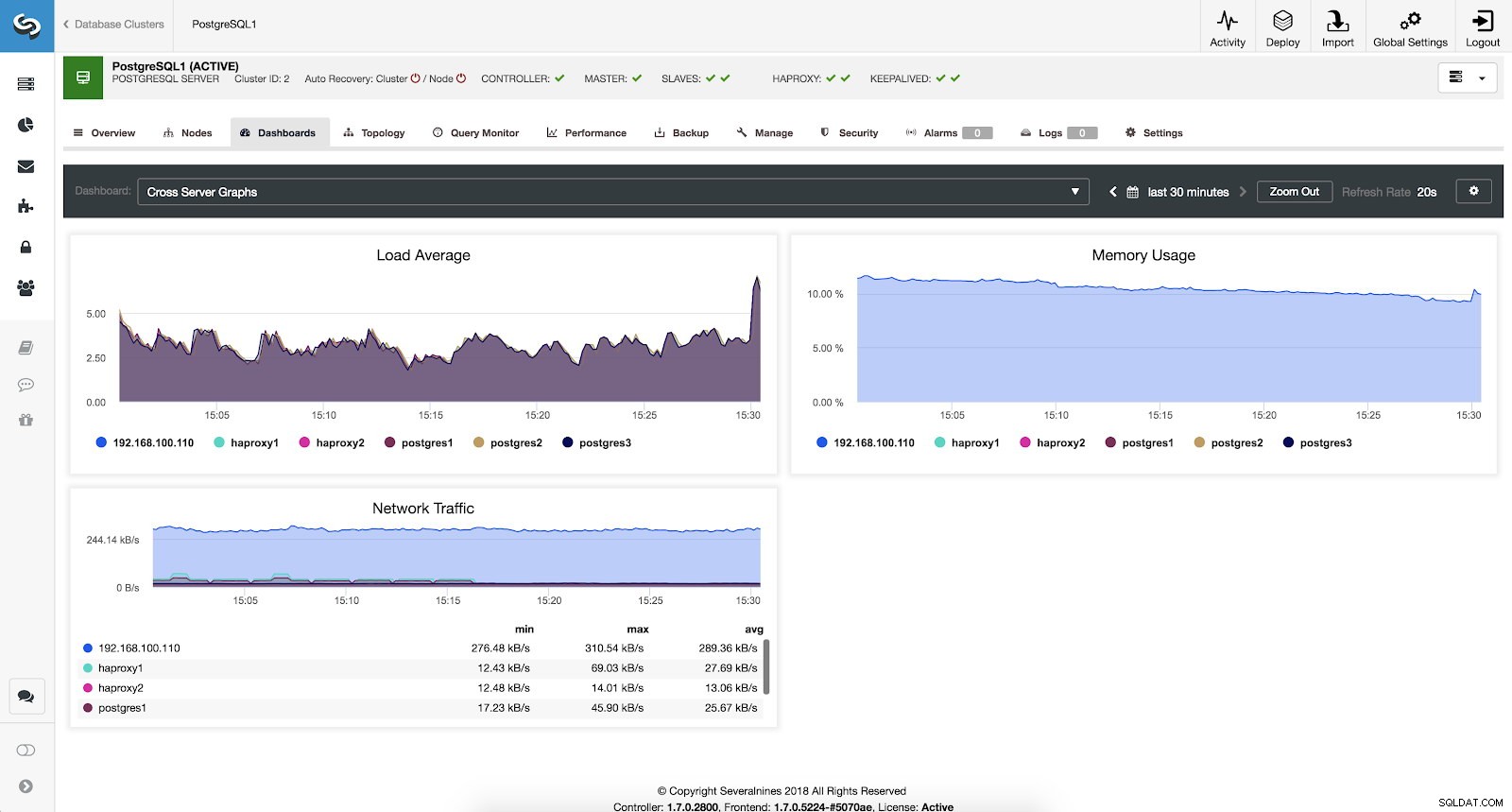 ClusterControl Cross Server Graphs Metrics
ClusterControl Cross Server Graphs Metrics Slutsats
Det finns flera sätt att övervaka PostgreSQL. ClusterControl tillhandahåller både agentfri och nu agentbaserad övervakning genom Prometheus. Det ger övervakningsdata med högre upplösning, såväl som olika instrumentpaneler för att förstå databasprestanda. ClusterControl kan också integreras med externa verktyg som Slack eller PagerDuty för varning.