UPPDATERING:2 september 2021 (Ursprungligen publicerad 26 juli 2012.)
Många saker förändras under loppet av några större versioner av vår favoritdatabasplattform. SQL Server 2016 gav oss STRING_SPLIT, en inbyggd funktion som eliminerar behovet av många av de anpassade lösningar vi har behövt tidigare. Det är snabbt också, men det är inte perfekt. Till exempel stöder den bara en avgränsare med ett tecken, och den returnerar ingenting för att indikera ordningen på inmatningselementen. Jag har skrivit flera artiklar om den här funktionen (och STRING_AGG, som kom till SQL Server 2017) sedan detta inlägg skrevs:
- Prestanda överraskningar och antaganden:STRING_SPLIT()
- STRING_SPLIT() i SQL Server 2016:Uppföljning #1
- STRING_SPLIT() i SQL Server 2016:Uppföljning #2
- SQL Server Split String Ersättningskod med STRING_SPLIT
- Jämföra metoder för strängdelning/sammansättning
- Lös gamla problem med SQL Servers nya STRING_AGG- och STRING_SPLIT-funktioner
- Hantera enteckenavgränsaren i SQL Servers STRING_SPLIT-funktion
- Snälla hjälp med STRING_SPLIT-förbättringar
- Ett sätt att förbättra STRING_SPLIT i SQL Server – och du kan hjälpa till
Jag kommer att lämna innehållet nedan här för eftervärlden och historisk relevans, och även för att en del av testmetoden är relevant för andra problem förutom att dela strängar, men se några av ovanstående referenser för information om hur du ska dela strängar i moderna versioner av SQL Server som stöds – liksom det här inlägget, som förklarar varför dela strängar kanske inte är ett problem du vill att databasen ska lösa i första hand, ny funktion eller inte.
- Dela strängar:Nu med mindre T-SQL
Jag vet att många människor är uttråkade av problemet med "delade strängar", men det verkar fortfarande dyka upp nästan dagligen på forum och Q &A-sajter som Stack Overflow. Det här är problemet där folk vill skicka i en sträng som denna:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Inne i proceduren vill de göra något sånt här:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Detta fungerar inte eftersom @FavoriteTeams är en enda sträng, och ovanstående översätts till:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server kommer därför att försöka hitta ett team som heter Patriots,Red Sox,Bruins , och jag antar att det inte finns något sådant lag. Vad de verkligen vill här är motsvarigheten till:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Men eftersom det inte finns någon array-typ i SQL Server är det inte så här variabeln tolkas alls – det är fortfarande en enkel, enkel sträng som råkar innehålla kommatecken. Bortsett från tvivelaktig schemadesign, i det här fallet måste den kommaseparerade listan "delas upp" i individuella värderingar – och detta är frågan som ofta leder till mycket "ny" debatt och kommentarer om den bästa lösningen för att uppnå just detta.
Svaret verkar vara, nästan undantagslöst, att du bör använda CLR. Om du inte kan använda CLR – och jag vet att det är många av er där ute som inte kan, på grund av företagspolicy, den spetsiga chefen eller envishet – så använder du en av de många lösningar som finns. Och många lösningar finns.
Men vilken ska du använda?
Jag ska jämföra prestandan för några lösningar – och fokusera på frågan alla alltid ställer:"Vilken är snabbast?" Jag tänker inte fördjupa diskussionen kring *alla* potentiella metoder, eftersom flera redan har eliminerats på grund av att de helt enkelt inte skalas. Och jag kanske kommer att återbesöka detta i framtiden för att undersöka effekten på andra mätvärden, men för tillfället kommer jag bara att fokusera på varaktighet. Här är utmanarna jag ska jämföra (med SQL Server 2012, 11.00.2316, på en Windows 7 VM med 4 processorer och 8 GB RAM):
CLR
Om du vill använda CLR bör du definitivt låna kod från andra MVP Adam Machanic innan du funderar på att skriva din egen (jag har tidigare bloggat om att återuppfinna hjulet, och det gäller även gratis kodsnuttar som denna). Han tillbringade mycket tid med att finjustera denna CLR-funktion för att effektivt analysera en sträng. Om du för närvarande använder en CLR-funktion och det här inte är den, rekommenderar jag starkt att du distribuerar den och jämför – jag testade den mot en mycket enklare, VB-baserad CLR-rutin som var funktionellt likvärdig, men VB-metoden fungerade ungefär tre gånger sämre än Adams.
Så jag tog Adams funktion, kompilerade koden till en DLL (med csc) och distribuerade just den filen till servern. Sedan lade jag till följande sammansättning och funktion till min databas:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Det här är den typiska funktionen jag använder för engångsscenarier där jag vet att inmatningen är "säker", men är inte en jag rekommenderar för produktionsmiljöer (mer om det nedan).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO En mycket stark varning måste följa med XML-metoden:den kan bara användas om du kan garantera att din inmatningssträng inte innehåller några olagliga XML-tecken. Ett namn med <,> eller &och funktionen kommer att sprängas. Så oavsett prestanda, om du ska använda det här tillvägagångssättet, var medveten om begränsningarna – det bör inte anses vara ett genomförbart alternativ för en generisk strängdelare. Jag tar med det i den här sammanfattningen eftersom du kan ha ett fall där du kan lita på indata – till exempel är det möjligt att använda för kommaseparerade listor med heltal eller GUID.
Siffertabell
Denna lösning använder en Numbers-tabell, som du måste bygga och fylla i själv. (Vi har efterfrågat en inbyggd version i evigheter.) Tabellen Numbers bör innehålla tillräckligt många rader för att överskrida längden på den längsta strängen du ska dela. I det här fallet kommer vi att använda 1 000 000 rader:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Att använda datakomprimering kommer att drastiskt minska antalet sidor som krävs, men självklart bör du bara använda det här alternativet om du kör Enterprise Edition. I det här fallet kräver den komprimerade datan 1 360 sidor, mot 2 102 sidor utan komprimering – ungefär en besparing på 35 %. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Vanligt tabelluttryck
Denna lösning använder en rekursiv CTE för att extrahera varje del av strängen från "resten" av föregående del. Som en rekursiv CTE med lokala variabler kommer du att notera att detta måste vara en funktion med flera påståenden i tabellvärde, till skillnad från de andra som alla är inline.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Jeff Modens splitter En funktion baserad på Jeff Modens splitter med mindre ändringar för att stödja längre strängar
På SQLServerCentral presenterade Jeff Moden en splitterfunktion som konkurrerade med prestanda hos CLR, så jag tyckte att det bara var rättvist att inkludera en variant med ett liknande tillvägagångssätt i denna sammanfattning. Jag var tvungen att göra några mindre ändringar i hans funktion för att kunna hantera vår längsta sträng (500 000 tecken), och gjorde även namnkonventionerna liknande:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; För de som använder Jeff Modens lösning kan du överväga att använda en siffertabell enligt ovan och experimentera med en liten variation av Jeffs funktion:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Detta kommer att byta ut något högre läsningar mot något lägre CPU, så det kan vara bättre beroende på om ditt system redan är CPU- eller I/O-bundet.)
Syndhetskontroll
Bara för att vara säkra på att vi är på rätt väg kan vi verifiera att alla fem funktioner ger de förväntade resultaten:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Och i själva verket är dessa resultat vi ser i alla fem fallen...

Testdata
Nu när vi vet att funktionerna beter sig som förväntat kan vi komma till den roliga delen:testa prestanda mot olika antal strängar som varierar i längd. Men först behöver vi ett bord. Jag skapade följande enkla objekt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Jag fyllde den här tabellen med en uppsättning strängar av varierande längd, och såg till att ungefär samma uppsättning data skulle användas för varje test – först 10 000 rader där strängen är 50 tecken lång, sedan 1 000 rader där strängen är 500 tecken lång , 100 rader där strängen är 5 000 tecken lång, 10 rader där strängen är 50 000 tecken lång och så vidare upp till 1 rad med 500 000 tecken. Jag gjorde detta både för att jämföra samma mängd övergripande data som bearbetas av funktionerna, samt för att försöka hålla mina testtider något förutsägbara.
Jag använder en #temp-tabell så att jag helt enkelt kan använda GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Att skapa och fylla i den här tabellen tog cirka 20 sekunder på min dator, och tabellen representerar cirka 6 MB data (cirka 500 000 tecken gånger 2 byte, eller 1 MB per string_type, plus rad- och indexoverhead). Inte ett stort bord, men det bör vara tillräckligt stort för att markera eventuella skillnader i prestanda mellan funktionerna.
Testen
Med funktionerna på plats och bordet ordentligt fyllt med stora snören att tugga på, kan vi äntligen köra några faktiska tester för att se hur de olika funktionerna presterar mot verklig data. För att mäta prestanda utan att ta hänsyn till nätverkskostnader använde jag SQL Sentry Plan Explorer, körde varje uppsättning tester 10 gånger, samlade in varaktighetsstatistiken och beräknade medelvärde.
Det första testet drog helt enkelt objekten från varje sträng som en uppsättning:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Resultaten visar att när strängarna blir större så lyser fördelen med CLR verkligen. I den nedre delen var resultaten blandade, men återigen borde XML-metoden ha en asterisk bredvid sig, eftersom dess användning är beroende av att förlita sig på XML-säker indata. För detta specifika användningsfall presterade tabellen Numbers genomgående sämst:
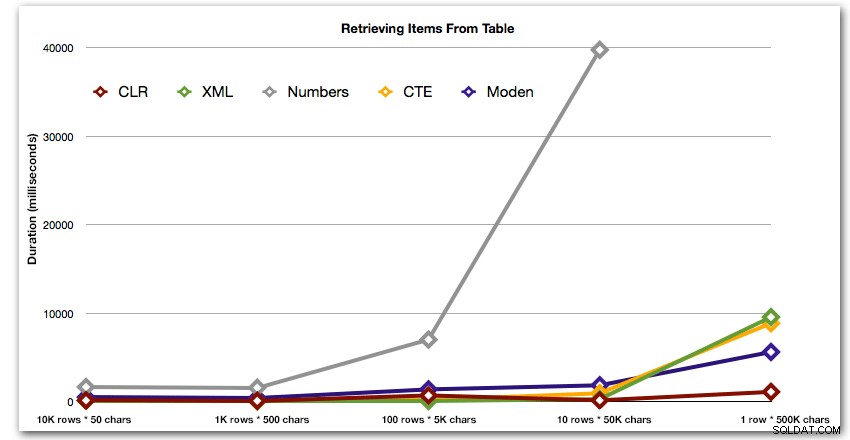
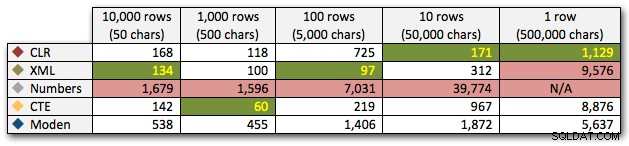
Längd, i millisekunder
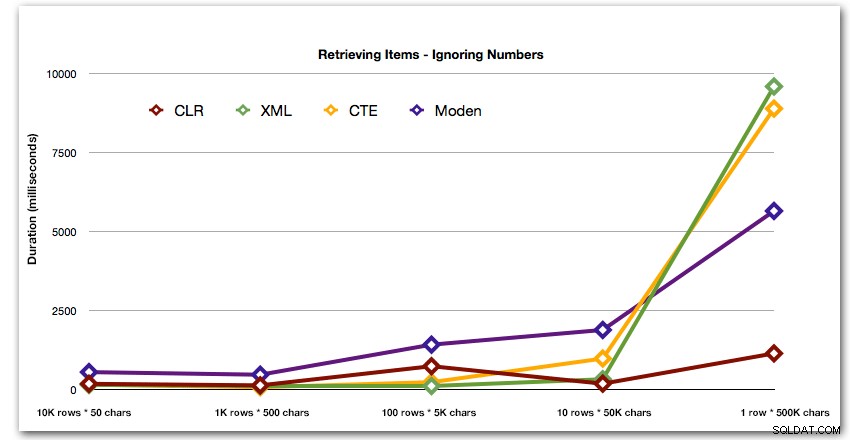
Efter den hyperboliska 40-sekundersprestandan för taltabellen mot 10 rader med 50 000 tecken, tog jag bort den från körningen för det senaste testet. För att bättre visa den relativa prestandan för de fyra bästa metoderna i det här testet har jag tagit bort Numbers-resultaten från grafen helt:
Låt oss sedan jämföra när vi utför en sökning mot det kommaseparerade värdet (t.ex. returnera raderna där en av strängarna är 'foo'). Återigen kommer vi att använda de fem funktionerna ovan, men vi kommer också att jämföra resultatet med en sökning som utförs under körning med LIKE istället för att bry sig om att splittra.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
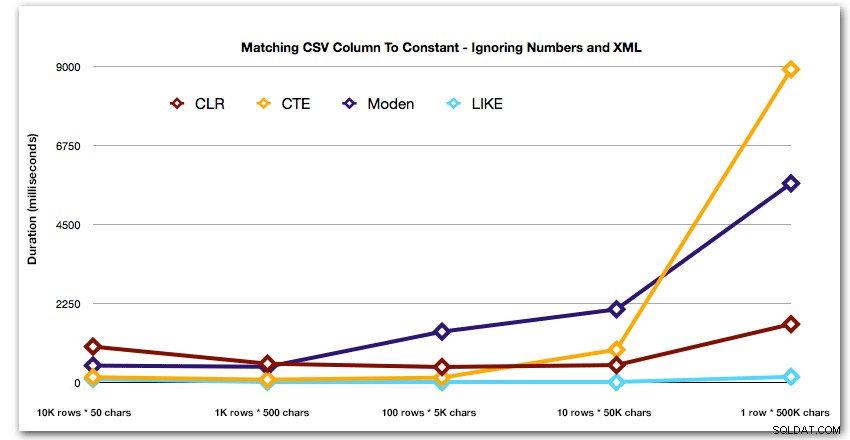
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Dessa resultat visar att, för små strängar, CLR faktiskt var den långsammaste, och att den bästa lösningen kommer att vara att utföra en skanning med LIKE, utan att bry sig om att dela upp data alls. Återigen tappade jag Numbers-tabelllösningen från den 5:e metoden, när det stod klart att dess varaktighet skulle öka exponentiellt när storleken på strängen ökade:
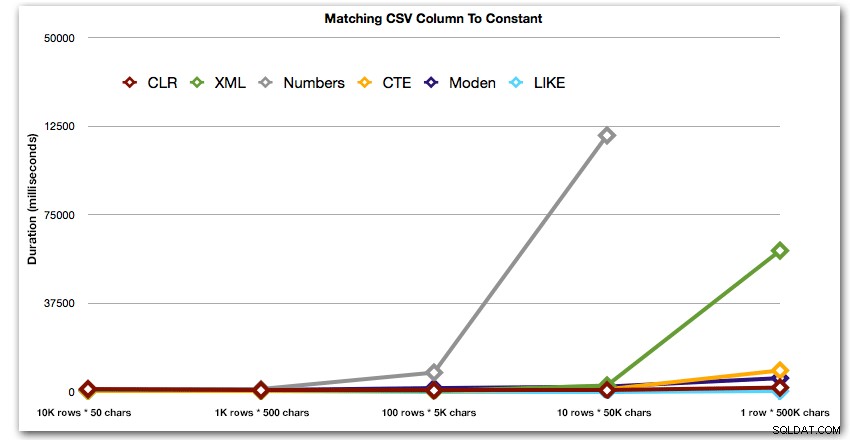
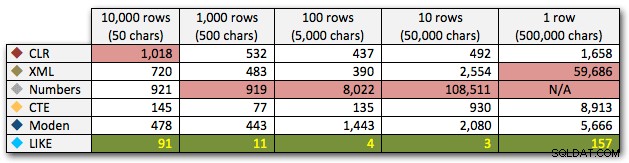
Längd, i millisekunder
Och för att bättre visa mönstren för de fyra bästa resultaten har jag tagit bort siffror och XML-lösningar från diagrammet:
Låt oss sedan titta på att replikera användningsfallet från början av det här inlägget, där vi försöker hitta alla rader i en tabell som finns i listan som skickas in. Som med data i tabellen vi skapade ovan, vi kommer att skapa strängar som varierar i längd från 50 till 500 000 tecken, lagra dem i en variabel och sedan kontrollera att en vanlig katalogvy finns i listan.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Dessa resultat visar att, för detta mönster, ser flera metoder deras varaktighet öka exponentiellt när storleken på strängen ökar. I den nedre delen håller XML bra takt med CLR, men även detta försämras snabbt. CLR är genomgående den klara vinnaren här:
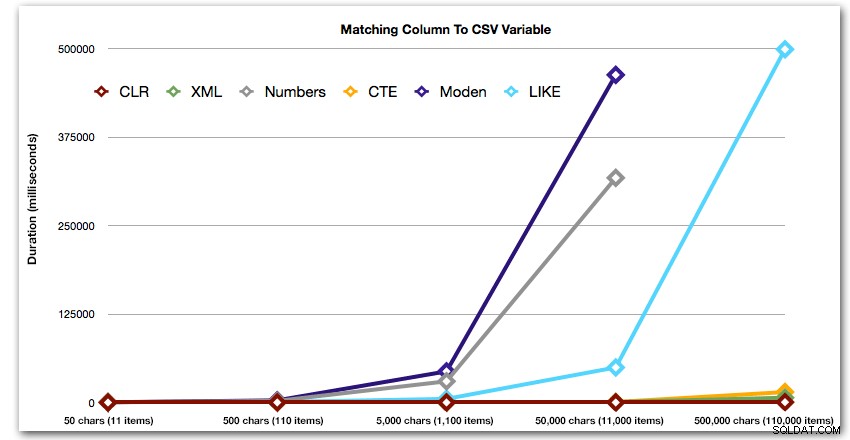
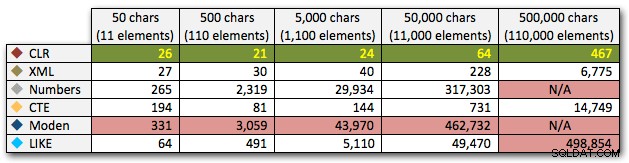
Längd, i millisekunder
Och återigen utan metoderna som exploderar uppåt vad gäller varaktighet:
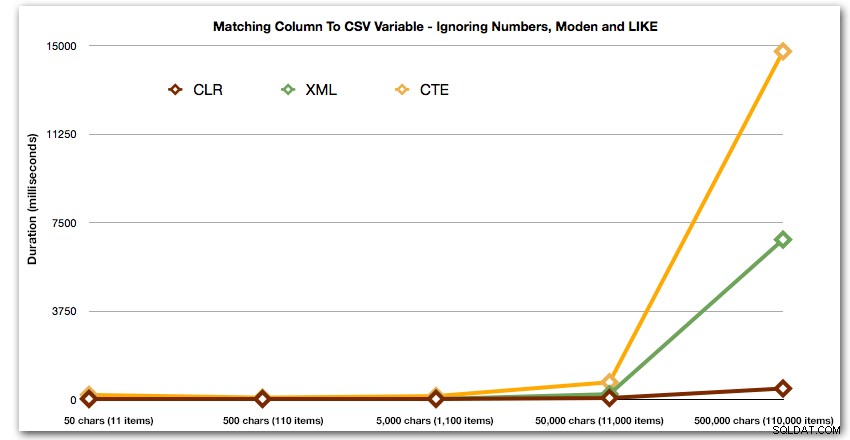
Slutligen, låt oss jämföra kostnaden för att hämta data från en enda variabel av varierande längd, och ignorera kostnaden för att läsa data från en tabell. Återigen genererar vi strängar av varierande längd, från 50 till 500 000 tecken, och returnerar sedan bara värdena som en uppsättning:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Dessa resultat visar också att CLR är ganska platt när det gäller varaktighet, hela vägen upp till 110 000 artiklar i setet, medan de andra metoderna håller hyfsat tempo tills en tid efter 11 000 artiklar:
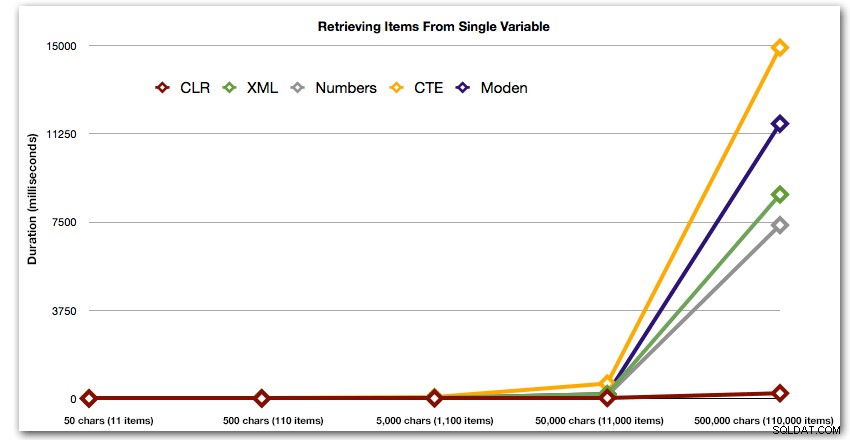
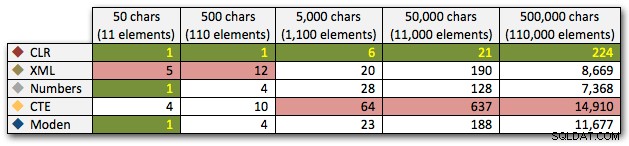
Längd, i millisekunder
Slutsats
I nästan alla fall överträffar CLR-lösningen klart de andra tillvägagångssätten – i vissa fall är det en jordskredsseger, särskilt när strängstorlekarna ökar; i några andra är det en fotofinish som kan falla åt båda hållen. I det första testet såg vi att XML och CTE presterade bättre än CLR i den låga delen, så om detta är ett typiskt användningsfall *och* du är säker på att dina strängar är i intervallet 1 – 10 000 tecken, kan en av dessa metoder vara ett bättre alternativ. Om dina strängstorlekar är mindre förutsägbara än så är CLR förmodligen fortfarande din bästa insats totalt sett – du förlorar några millisekunder i den lägre delen, men du vinner en hel del i den höga delen. Här är de val jag skulle göra, beroende på uppgiften, med andraplatsen markerad för fall där CLR inte är ett alternativ. Observera att XML är min föredragna metod endast om jag vet att inmatningen är XML-säker; dessa kanske inte nödvändigtvis är dina bästa alternativ om du har mindre tilltro till din input.
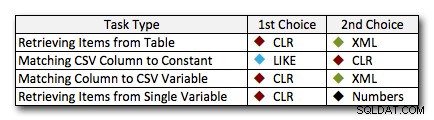
Det enda verkliga undantaget där CLR inte är mitt val överlag är fallet där du faktiskt lagrar kommaseparerade listor i en tabell och sedan hittar rader där en definierad enhet finns i den listan. I det specifika fallet skulle jag förmodligen först rekommendera att omforma och normalisera schemat på rätt sätt, så att dessa värden lagras separat, snarare än att använda det som en ursäkt för att inte använda CLR för att dela upp.
Om du inte kan använda CLR av andra skäl, finns det inte en entydig "andra plats" som avslöjas av dessa tester; mina svar ovan var baserade på övergripande skala och inte på någon specifik strängstorlek. Varje lösning här kom tvåa i minst ett scenario – så även om CLR helt klart är valet när du kan använda det, vad du bör använda när du inte kan är mer av ett "det beror på"-svar – du måste bedöma baserat på ditt användningsfall och testerna ovan (eller genom att konstruera dina egna tester) vilket alternativ är bättre för dig.
Tillägg :Ett alternativ till att dela i första hand
Ovanstående tillvägagångssätt kräver inga ändringar av dina befintliga applikationer, förutsatt att de redan sätter ihop en kommaseparerad sträng och kastar den till databasen för att hantera. Ett alternativ du bör överväga, om antingen CLR inte är ett alternativ och/eller du kan ändra applikationen/applikationerna, är att använda Table-Valued Parameters (TVP). Här är ett snabbt exempel på hur man använder en TVP i ovanstående sammanhang. Skapa först en tabelltyp med en enda strängkolumn:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Sedan kan den lagrade proceduren ta denna TVP som indata och gå med på innehållet (eller använda det på andra sätt – detta är bara ett exempel):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Nu i din C#-kod, till exempel, istället för att bygga en kommaseparerad sträng, fyll i en datatabell (eller använd vilken kompatibel samling som helst som redan innehåller din uppsättning värden):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Du kanske anser att detta är en prequel till ett uppföljande inlägg.
Detta fungerar naturligtvis inte bra med JSON och andra API:er – ganska ofta anledningen till att en kommaseparerad sträng skickas till SQL Server i första hand.