Att övervaka PostgreSQL kan ibland vara som att försöka bråka boskap i ett åskväder. Applikationer ansluter och skickar frågor så snabbt att det är svårt att se vad som händer eller till och med få en bra överblick över systemets prestanda förutom att den typiska utvecklaren klagar på "saker går långsamt, hjälp!".
I tidigare artiklar har vi diskuterat hur man kommer till källan när PostgreSQL agerar långsamt, men när källan specifikt är frågor, kanske övervakning på grundnivå inte räcker för att bedöma vad som händer i en aktiv livemiljö.
Ange pg_top, ett PostgreSQL-specifikt program för att övervaka realtidsaktivitet i en databas, samt visa grundläggande information för själva databasvärden. Ungefär som linux-kommandot 'top', tar det användaren in i en live interaktiv visning av databasaktivitet på värden, som uppdateras automatiskt i intervaller.
Installation
Installation av pg_top kan göras på de allmänt förväntade sätten:pakethanterare och källinstallation. Den senaste versionen av denna artikel är 3.7.0.
Pakethanterare
Baserat på distributionen av linux i fråga, sök efter pgtop eller pg_top i pakethanteraren, det är troligtvis tillgängligt i någon aspekt för den installerade versionen av PostgreSQL på systemet.
Red Hat-baserade distros:
# sudo yum install pg_topGentoo-baserade distributioner:
# sudo apt-get install pgtopKälla
Om så önskas kan pg_top installeras via källkod från PostgreSQL git-förvaret. Detta ger alla önskade versioner, även nyare versioner som ännu inte finns i de officiella utgåvorna.
Funktioner
När den väl har installerats fungerar pg_top som en mycket exakt realtidsvy i databasen som den övervakar och att använda kommandoraden för att köra 'pg_top' kommer att starta det interaktiva PostgreSQL-övervakningsverktyget.
Verktyget i sig kan hjälpa till att belysa alla processer som för närvarande är kopplade till databasen.
Kör pg_top
Att starta pg_top är detsamma som själva kommandot "top" i unix / linux stil, tillsammans med anslutningsinformation till databasen.
Så här kör du pg_top på en lokal databasvärd:
pg_top -h localhost -p 5432 -d severalnines -U postgresFör att köra pg_top på en fjärrvärd krävs flaggan -r eller --remote-mode, och tillägget pg_proctab installerat på själva värden:
pg_top -r -h 192.168.1.20 -p 5432 -d severalnines -U postgresVad som visas på skärmen
När vi startar pg_top ser vi en skärm med ganska mycket information.
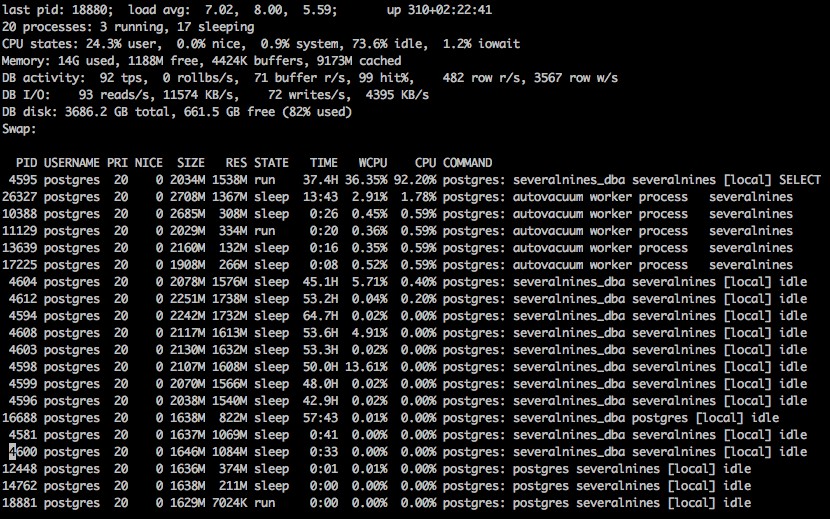 Standardutdata från pg_top på linux
Standardutdata från pg_top på linux
Belastningsmedelvärde:
Liksom standardkommandot överst, detta belastningsmedelvärde för 1, 5 och 15 minuters intervall.
Drifttid:
Den totala tid som systemet har varit online sedan den senaste omstarten.
Processer:
Det totala antalet databasprocesser anslutna, med ett antal av hur många som körs och hur många som sover.
CPU-statistik:
Statistiken för CPU:n, som visar den procentuella belastningen för användare, system och inaktiv, bra information samt iowait-procentandelar.
Minne:
Den totala mängden minne som används, ledigt, i buffertar och cachelagrat.
DB-aktivitet:
Statistiken för databasaktivitet som transaktioner per sekund, antal återställningar per sekund, buffertar som läses per sekund, buffertar träffar per sekund, antal rader lästa per sekund och rader skrivna per sekund.
DB I/O-aktivitet:
Aktiviteten för Input Output på systemet, som visar hur många läsningar och skrivningar per sekund, samt mängden läser och skrivs per sekund.
DB Disk Stats:
Den totala storleken på databasdisken, samt hur mycket ledigt utrymme.
Swap:
Informationen om swap-utrymme som används, om någon.
Processer:
En lista över processer kopplade till databasen, inklusive alla interna processer av autovakuumtyp. Listan inkluderar pid, prioritet, bra mängd, internminne som används, anslutningens tillstånd, antal CPU-sekunder som används, CPU-procent och det aktuella kommandot som processen körs.
Användbara interaktiva funktioner
Det finns en handfull interaktiva funktioner i pg_top som kan nås medan den körs. En fullständig lista kan hittas genom att ange ett ?, vilket kommer att visa en hjälpskärm med alla tillgängliga alternativ.
Planerarinformation
E - Execution Plan
Att ange E kommer att ge en uppmaning om ett process-ID för vilket en förklarande plan ska visas. Detta motsvarar att köra "EXPLAIN
A - FÖRKLARA ANALYS (UPPDATERA/RADERA säker)
Om du anger A kommer du att uppmanas att ange ett process-ID för att visa en FÖRKLARA ANALYS-plan. Detta motsvarar att köra "EXPLAIN ANALYZE
Processinformation
Q - Visa aktuell fråga för en process
Om du anger Q kommer du att få ett process-ID för att visa hela frågan.
I - Visar I/O-statistik per process (endast Linux)
Om du öppnar I växlar processlistan till en I/O-skärm, som visar varje process som läser, skriver, etc till disken.
L – Visar lås som innehas av en process
Om du anger L kommer du att uppmanas att ange ett process-ID för att visa hållna lås. Detta inkluderar databasen, tabellen, typen av lås och om låset har beviljats eller inte. Användbar när du utforskar långa processer eller väntande processer.
Relationsinformation
R - Visa statistik för användartabeller.
Om du anger R visas tabellstatistik inklusive sekventiella skanningar, indexskanningar, INFOGA, UPPDATERINGAR och DELETE, allt relevant för den senaste aktiviteten.
X - Visa användarindexstatistik
Om du anger X visar indexstatistik inklusive indexskanningar, indexläsningar och indexhämtningar, allt relevant för den senaste aktiviteten.
Sortering
Sortering av displayen kan göras genom något av följande tecken.
M - Sortera efter minnesanvändning
N - Sortera efter pid
P - Sortera efter CPU-användning
T - Sortera efter tid
Följande är poster som anges efter att du tryckt på o, vilket tillåter sortering av index-, tabell- och i/o-statistiksidor också.
o - Ange sorteringsordning (cpu, storlek, res, tid, kommando)
indexstatistik (idx_scan, idx_tup_fetch, idx_tup_read)
tabellstatistik (seq_scan, seq_tup_read, idx_scan, idx_tup_fetch, n_tup_ins, n_tup_upd, n br tup_, i de char, char / , skriver, cwrites, kommando)
Anslutning/Frågehantering
k - specificerade avlivningsprocesser
Om du anger k kommer du att få en uppmaning om en process, eller en lista över databasprocesser som ska dödas.
r - återskapa en process (endast lokal databas, endast root)
Om du anger r kommer du att få ett bra värde, följt av en lista med processer som ska ställas in på det nya nice-värdet. Detta ändrar prioriteringen av viktiga processer i systemet.
Exempel:"renice 1 7004"
Olik användning av pg_top
Reaktiv användning av pg_top
Den allmänna användningen av pg_top är det interaktiva läget, vilket gör att vi kan se vilka frågor som körs på ett system som har problem med långsamhet, köra förklara planer på dessa frågor, rensa bort viktiga frågor för att få dem att slutföra snabbare, eller döda alla frågor som orsakar stora nedgångar . I allmänhet tillåter det databasadministratören att göra mycket av samma saker som kan göras manuellt på systemet, men på ett snabbare och allt i ett alternativ.
Proaktiv användning av pg_top
Även om det inte är alltför vanligt, kan pg_top köras i "batch-läge", som kommer att visa huvudinformationen som diskuteras till standard ut, sedan avsluta. Detta kan skriptas upp för att köras med vissa intervall, sedan skickas till valfri anpassad process som önskas, analyseras och genereras av varningar baserat på vad administratören kanske vill bli varnad om. Till exempel, om belastningen på systemet blir för hög, om det finns ett värde som är högre än förväntat transaktioner per sekund, kan allt som ett kreativt program kan lista ut.
I allmänhet finns det andra verktyg för att samla in och rapportera om denna information, men att ha fler alternativ är alltid bra, och med fler verktyg tillgängliga kan de bästa alternativen hittas.
Historisk användning av pg_top
Ungefär som den tidigare användningen, proaktiv användning, kan vi skripta upp pg_top i ett batchläge för att logga ögonblicksbilder av hur databasen ser ut över tid. Detta kan vara så enkelt som att skriva den till en textfil med en tidsstämpel, eller att analysera den och lagra datumet i en relationsdatabas för att generera rapporter. Detta skulle göra det möjligt att hitta mer information efter en större incident, till exempel en databaskrasch klockan 04.00. Ju mer information tillgänglig, desto mer sannolika problem kan hittas.
Mer information
Dokumentationen för projektet är ganska begränsad, och det mesta av informationen är tillgänglig på Linuxman-sidan, hittad genom att köra 'man pg_top'. PostgreSQL-communityt kan hjälpa till med frågor eller problem genom PostgreSQL Mailing Lists, eller det officiella IRC Chatroom som finns på freenode, kanalnamn #postgresql.