
T-SQL Tuesday #78 är värd för Wendy Pastrick, och utmaningen denna månad är helt enkelt att "lära sig något nytt och blogga om det." Hennes blurb lutar mot nya funktioner i SQL Server 2016, men eftersom jag har bloggat och presenterat många av dem tänkte jag att jag skulle utforska något annat på egen hand som jag alltid har varit genuint nyfiken på.
Jag har sett flera personer som säger att en hög kan vara bättre än ett klusterindex för vissa scenarier. Jag kan inte hålla med om det. En av de intressanta anledningarna som jag har sett är dock att en RID-sökning är snabbare än en nyckelsökning. Jag är ett stort fan av klustrade index och inte ett stort fan av heaps, så jag kände att det här behövde testas.
Så, låt oss testa det!
Jag tänkte att det skulle vara bra att skapa en databas med två tabeller, identiska förutom att den ena hade en klustrad primärnyckel och den andra hade en icke-klustrad primärnyckel. Jag skulle ladda några rader i tabellen, uppdatera ett gäng rader i en slinga och välja från ett index (tvingar antingen en nyckel- eller RID-sökning).
Systemspecifikationer
Den här frågan dyker ofta upp, så för att klargöra de viktiga detaljerna om det här systemet sitter jag på en 8-kärnig virtuell dator med 32 GB RAM, uppbackad av PCIe-lagring. SQL Server-versionen är 2014 SP1 CU6, utan några speciella konfigurationsändringar eller spårningsflaggor som körs:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 apr 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) på Windows NT 6.3
Databasen
Jag skapade en databas med gott om ledigt utrymme i både data och loggfil för att förhindra att eventuella autogrow-händelser stör testerna. Jag ställer också in databasen på enkel återställning för att minimera påverkan på transaktionsloggen.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Tabellerna
Som jag sa, två tabeller, med den enda skillnaden är om primärnyckeln är klustrad.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
En tabell för att fånga körtid
Jag skulle kunna övervaka CPU och allt det där, men egentligen är nyfikenheten nästan alltid kring körtid. Så jag skapade en loggningstabell för att fånga körtiden för varje test:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Infogningstestet
Så, hur lång tid tar det att infoga 2 000 rader, 100 gånger? Jag hämtar en del ganska grundläggande data från sys.all_objects , och ta med definitionen för alla procedurer, funktioner etc.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Uppdateringstestet
För uppdateringstestet ville jag bara testa skrivhastigheten till ett klustrat index kontra en hög på ett mycket rad-för-rad-sätt. Så jag dumpade 200 slumpmässiga rader i en #temp-tabell och byggde sedan en markör runt den (tabellen #temp ser bara till att samma 200 rader uppdateras i båda versionerna av tabellen, vilket förmodligen är överdrivet).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Väljtestet
Så ovan såg du att jag skapade ett index med Name som nyckelkolumn i varje tabell; för att utvärdera kostnaden för att utföra uppslagningar för ett betydande antal rader skrev jag en fråga som tilldelar utdata till en variabel (eliminerar nätverkets I/O och klientåtergivningstid), men tvingar fram användningen av indexet:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; För den här ville jag visa några intressanta aspekter av planerna innan jag sammanställde testresultaten. Att köra dem individuellt head-to-head ger dessa jämförande mätvärden:

Varaktigheten är oväsentlig för ett enskilt uttalande, men titta på dessa läsningar. Om du använder långsam lagring är det en stor skillnad som du inte kommer att se i mindre skala och/eller på din lokala utvecklings-SSD.
Och sedan planerna som visar de två olika uppslagningarna, med hjälp av SQL Sentry Plan Explorer:

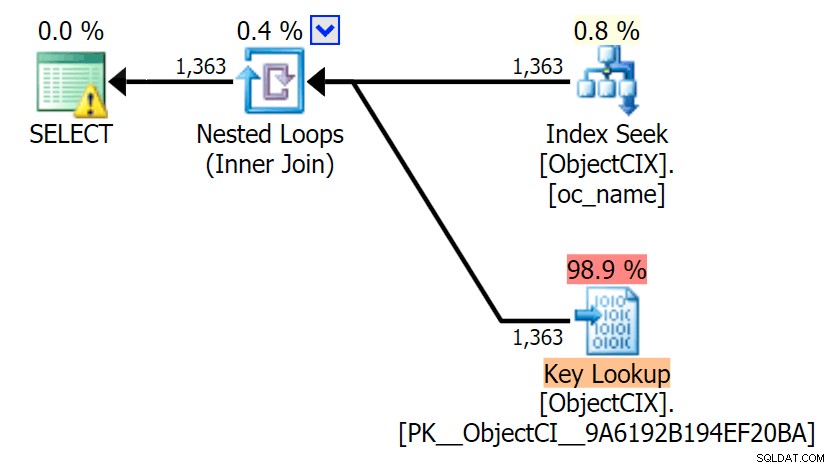
Planerna ser nästan identiska ut, och du kanske inte märker skillnaden i läsningar i SSMS om du inte spelade in Statistics I/O. Till och med de beräknade I/O-kostnaderna för de två uppslagningarna var likartade – 1,69 för nyckelsökningen och 1,59 för RID-uppslagningen. (Varningsikonen i båda planerna är för ett saknat täckande index.)
Det är intressant att notera att om vi inte tvingar fram en sökning och låter SQL Server bestämma vad den ska göra, väljer den en standardskanning i båda fallen – ingen saknad indexvarning, och titta på hur mycket närmare läsningarna är:

Optimeraren vet att en skanning blir mycket billigare än sök + uppslag i det här fallet. Jag valde en LOB-kolumn för variabeltilldelning enbart för effekt, men resultaten var liknande även med en icke-LOB-kolumn.
Testresultaten
Med tidtabellen på plats kunde jag enkelt köra testerna flera gånger (jag körde ett dussin tester) och sedan komma med medelvärden för testerna med följande fråga:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Ett enkelt stapeldiagram visar hur de jämförs:
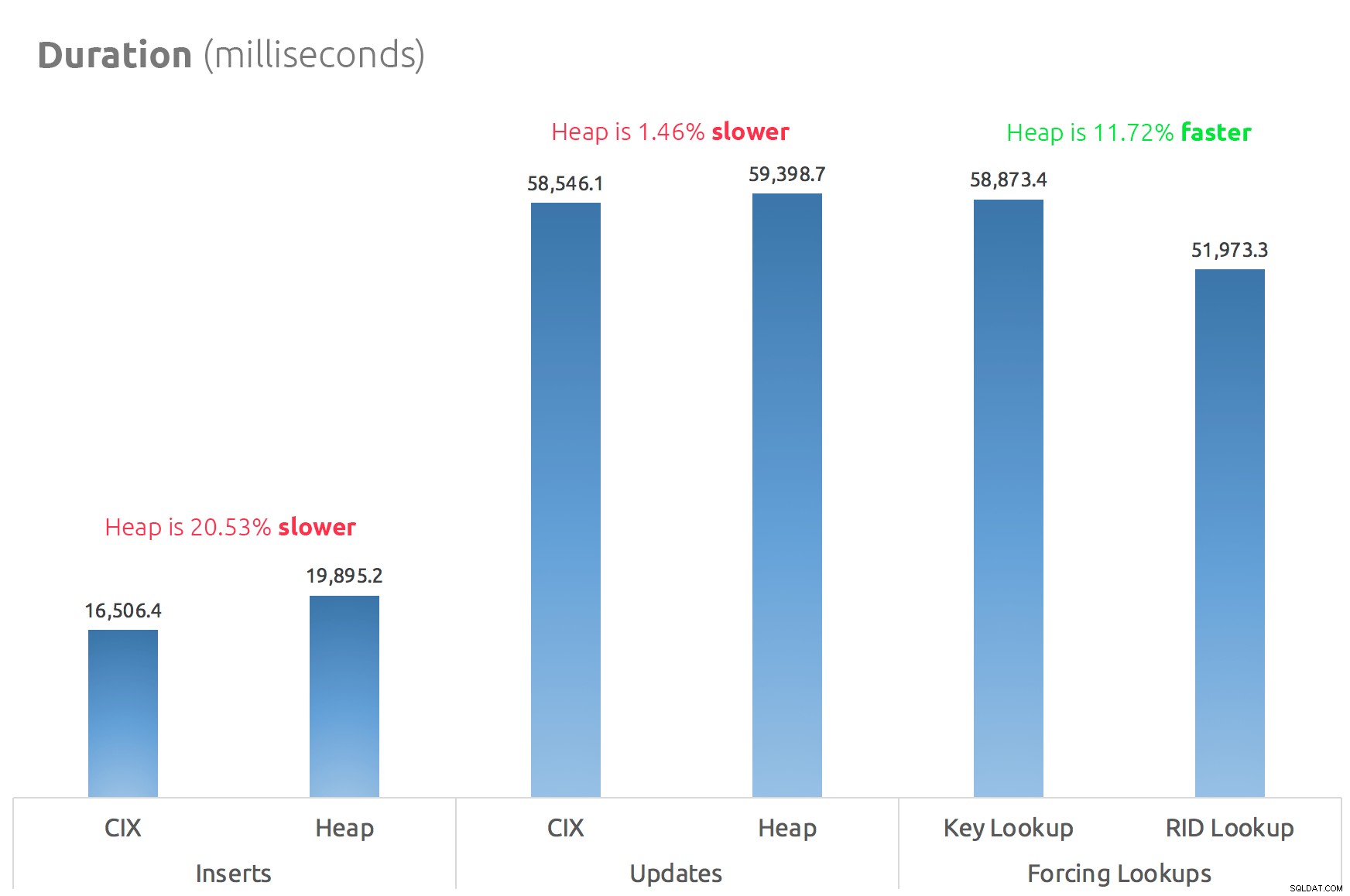
Slutsats
Så ryktena är sanna:åtminstone i det här fallet är en RID-sökning betydligt snabbare än en nyckelsökning. Att gå direkt till file:page:slot är uppenbarligen effektivare när det gäller I/O än att följa b-trädet (och om du inte är på modern lagring kan deltat vara mycket mer märkbart).
Om du vill dra nytta av det och ta med dig alla andra heap-aspekter beror på din arbetsbelastning – högen är något dyrare för skrivoperationer. Men det här är inte definitiv – detta kan variera mycket beroende på tabellstruktur, index och åtkomstmönster.
Jag testade mycket enkla saker här, och om du är på stängslet om detta, rekommenderar jag starkt att du testar din faktiska arbetsbelastning på din egen hårdvara och jämför själv (och glöm inte att testa samma arbetsbelastning där täckande index finns; du kommer förmodligen att få mycket bättre övergripande prestanda om du helt enkelt kan eliminera uppslagningar helt). Se till att mäta alla mätvärden som är viktiga för dig; bara för att jag fokuserar på varaktighet betyder det inte att det är den du behöver bry dig mest om. :-)