Om din IT-infrastruktur körs på AWS har du förmodligen hört talas om Amazon Relational Database Service (RDS), ett enkelt sätt att konfigurera, driva och skala en relationsdatabas i molnet. Det ger kostnadseffektiv och storleksändringsbar kapacitet samtidigt som den automatiserar tidskrävande administrationsuppgifter som hårdvaruförsörjning, databasinstallation, patchning och säkerhetskopiering. Det finns ett antal databasmotorerbjudanden för RDS som MySQL, MariaDB, PostgreSQL, Microsoft SQL Server och Oracle Server.
ClusterControl 1.7.3 fungerar på samma sätt som RDS eftersom den stöder distribution, hantering, övervakning och skalning av databaskluster på AWS-plattformen. Den stöder också ett antal andra molnplattformar som Google Cloud Platform och Microsoft Azure. ClusterControl förstår databastopologin och kan utföra automatisk återställning, topologihantering och många fler avancerade funktioner för att ta kontroll över din databas.
I det här blogginlägget kommer vi att jämföra automatiska failover-tider för Amazon Aurora, Amazon RDS för MySQL och en MySQL-replikeringsinställning som distribueras och hanteras av ClusterControl. Den typ av failover som vi kommer att göra är slavbefordran i fall att mastern går ner. Det är här den mest uppdaterade slaven tar över huvudrollen i klustret för att återuppta databastjänsten.
Vårt failover-test
För att mäta failover-tiden kommer vi att köra ett enkelt MySQL-anslutningsuppdateringstest, med en loop för att räkna SQL-satsens status som ansluter till en enda databasslutpunkt. Skriptet ser ut så här:
#!/bin/bash
_host='{MYSQL ENDPOINT}'
_user='sbtest'
_pass='password'
_port=3306
j=1
while true
do
echo -n "count $j : "
num=$(od -A n -t d -N 1 /dev/urandom |tr -d ' ')
timeout 1 bash -c "mysql -u${_user} -p${_pass} -h${_host} -P${_port} --connect-timeout=1 --disable-reconnect -A -Bse \
\"UPDATE sbtest.sbtest1 SET k = $num WHERE id = 1\" > /dev/null 2> /dev/null"
if [ $? -eq 0 ]; then
echo "OK $(date)"
else
echo "Fail ---- $(date)"
fi
j=$(( $j + 1 ))
sleep 1
done
Ovanstående Bash-skript ansluter helt enkelt till en MySQL-värd och utför en uppdatering på en enda rad med en timeout på 1 sekund på både Bash- och mysql-klientkommandon. De timeoutrelaterade parametrarna krävs så att vi kan mäta stilleståndstiden i sekunder på rätt sätt eftersom mysql-klienten som standard alltid återansluter tills den når MySQL wait_timeout. Vi fyllde i en testdatauppsättning med följande kommando i förväg:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host={MYSQL HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=50 \
--table-size=100000 \
prepareSkriptet rapporterar om ovanstående fråga lyckades (OK) eller misslyckades (Fil). Exempelutgångar visas längre ner.
Failover med Amazon RDS för MySQL
I vårt test använder vi det lägsta RDS-erbjudandet med följande specifikationer:
- MySQL-version:5.7.22
- vCPU:4
- RAM:16 GB
- Lagringstyp:Provisioned IOPS (SSD)
- IOPS:1000
- Lagring:100 Gib
- Multi-AZ-replikering:Ja
Efter att Amazon RDS tillhandahåller din DB-instans kan du använda vilken standard MySQL-klientapplikation eller -verktyg som helst för att ansluta till instansen. I anslutningssträngen anger du DNS-adressen från DB-instansens slutpunkt som värdparameter och anger portnumret från DB-instansens slutpunkt som portparameter.
Enligt Amazon RDS dokumentationssida, i händelse av ett planerat eller oplanerat avbrott i din DB-instans, växlar Amazon RDS automatiskt till en standby-replika i en annan tillgänglighetszon om du har aktiverat Multi-AZ. Tiden det tar för failover att slutföras beror på databasaktiviteten och andra förhållanden när den primära DB-instansen blev otillgänglig. Failover-tider är vanligtvis 60-120 sekunder.
För att initiera en multi-AZ-failover i RDS, utförde vi en omstartoperation med "Reboot with Failover" markerad, som visas i följande skärmdump:
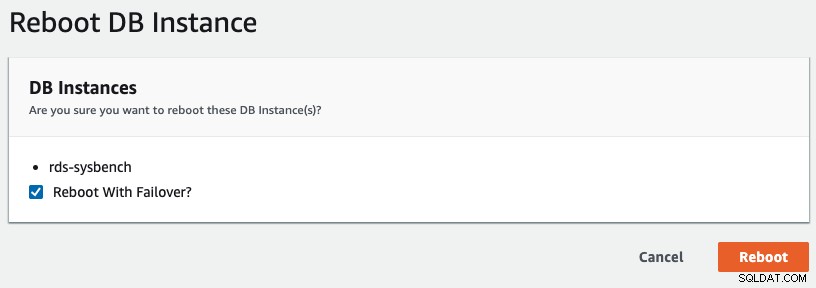
Följande är vad som observeras av vår ansökan:
...
count 30 : OK Wed Aug 28 03:41:06 UTC 2019
count 31 : OK Wed Aug 28 03:41:07 UTC 2019
count 32 : Fail ---- Wed Aug 28 03:41:09 UTC 2019
count 33 : Fail ---- Wed Aug 28 03:41:11 UTC 2019
count 34 : Fail ---- Wed Aug 28 03:41:13 UTC 2019
count 35 : Fail ---- Wed Aug 28 03:41:15 UTC 2019
count 36 : Fail ---- Wed Aug 28 03:41:17 UTC 2019
count 37 : Fail ---- Wed Aug 28 03:41:19 UTC 2019
count 38 : Fail ---- Wed Aug 28 03:41:21 UTC 2019
count 39 : Fail ---- Wed Aug 28 03:41:23 UTC 2019
count 40 : Fail ---- Wed Aug 28 03:41:25 UTC 2019
count 41 : Fail ---- Wed Aug 28 03:41:27 UTC 2019
count 42 : Fail ---- Wed Aug 28 03:41:29 UTC 2019
count 43 : Fail ---- Wed Aug 28 03:41:31 UTC 2019
count 44 : Fail ---- Wed Aug 28 03:41:33 UTC 2019
count 45 : Fail ---- Wed Aug 28 03:41:35 UTC 2019
count 46 : OK Wed Aug 28 03:41:36 UTC 2019
count 47 : OK Wed Aug 28 03:41:37 UTC 2019
...MySQL-avbrottstiden som ses av applikationssidan startade från 03:41:09 till 03:41:36 vilket är cirka 27 sekunder totalt. Från RDS-händelserna kan vi se att multi-AZ-failover bara inträffade 15 sekunder efter faktiska driftstopp:
Wed, 28 Aug 2019 03:41:24 GMT Multi-AZ instance failover started.
Wed, 28 Aug 2019 03:41:33 GMT DB instance restarted
Wed, 28 Aug 2019 03:41:59 GMT Multi-AZ instance failover completed.När den nya databasinstansen startade om runt 03:41:33 var MySQL-tjänsten tillgänglig cirka 3 sekunder senare.
Failover med Amazon Aurora för MySQL
Amazon Aurora kan betraktas som en överlägsen version av RDS, med många anmärkningsvärda funktioner som snabbare replikering med delad lagring, ingen dataförlust under failover och upp till 64 TB lagringsgräns. Amazon Aurora för MySQL är baserad på MySQL Edition med öppen källkod, men är inte öppen källkod i sig själv; det är en egenutvecklad databas med stängd källkod. Det fungerar på liknande sätt med MySQL-replikering (en och endast en master, med flera slavar) och failover hanteras automatiskt av Amazon Aurora.
Enligt Amazon Aurora FAQS, om du har en Amazon Aurora Replica, i samma eller en annan tillgänglighetszon, när du misslyckas, vänder Aurora den kanoniska namnposten (CNAME) för din DB-instans för att peka på den friska repliken, som finns i tur befordras till att bli den nya primära. Börja till slut, failover slutförs vanligtvis inom 30 sekunder.
Om du inte har en Amazon Aurora Replica (dvs. enstaka instans), kommer Aurora först att försöka skapa en ny DB-instans i samma tillgänglighetszon som den ursprungliga instansen. Om det inte går att göra det kommer Aurora att försöka skapa en ny DB-instans i en annan tillgänglighetszon. Från början till slut slutförs failover vanligtvis på mindre än 15 minuter.
Ditt program bör försöka igen databasanslutningar i händelse av anslutningsförlust.
Efter att Amazon Aurora tillhandahåller din DB-instans kommer du att få två slutpunkter, en för författaren och en för läsaren. Läsarens slutpunkt ger lastbalanserande stöd för skrivskyddade anslutningar till DB-klustret. Följande slutpunkter är hämtade från vår testinställning:
- författare - aurora-sysbench.cluster-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
- läsare - aurora-sysbench.cluster-ro-cw9j4kdnvun9.ap-southeast-1.rds.amazonaws.com
I vårt test använde vi följande Aurora-specifikationer:
- Förekomsttyp:db.r5.large
- MySQL-version:5.7.12
- vCPU:2
- RAM:16 GB
- Multi-AZ-replikering:Ja
För att utlösa en failover, välj bara writer-instansen -> Actions -> Failover, som visas i följande skärmdump:
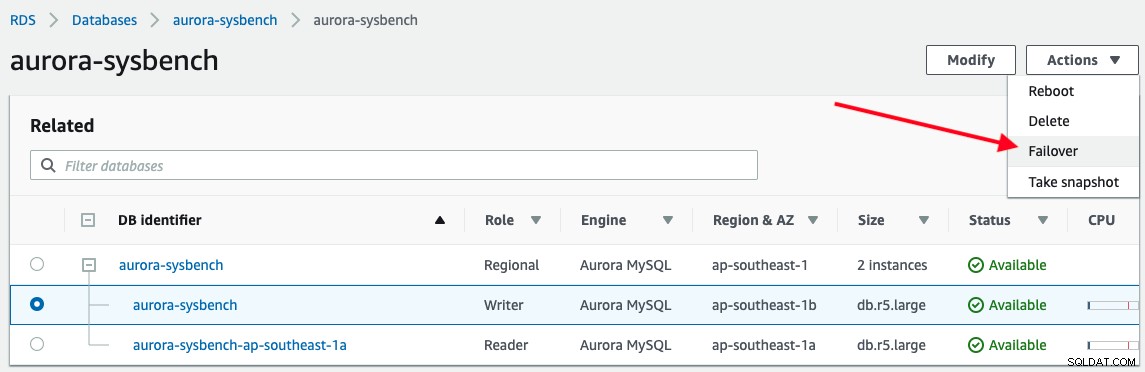
Följande utdata rapporteras av vår applikation vid anslutning till Aurora writer-slutpunkten :
...
count 37 : OK Wed Aug 28 12:35:47 UTC 2019
count 38 : OK Wed Aug 28 12:35:48 UTC 2019
count 39 : Fail ---- Wed Aug 28 12:35:49 UTC 2019
count 40 : Fail ---- Wed Aug 28 12:35:50 UTC 2019
count 41 : Fail ---- Wed Aug 28 12:35:51 UTC 2019
count 42 : Fail ---- Wed Aug 28 12:35:52 UTC 2019
count 43 : Fail ---- Wed Aug 28 12:35:53 UTC 2019
count 44 : Fail ---- Wed Aug 28 12:35:54 UTC 2019
count 45 : Fail ---- Wed Aug 28 12:35:55 UTC 2019
count 46 : OK Wed Aug 28 12:35:56 UTC 2019
count 47 : OK Wed Aug 28 12:35:57 UTC 2019
...Databasens driftstopp startade kl. 12:35:49 till 12:35:56 med totalt 7 sekunder. Det är ganska imponerande.
När man tittar på databashändelsen från Auroras hanteringskonsol, hände bara dessa två händelser:
Wed, 28 Aug 2019 12:35:50 GMT A new writer was promoted. Restarting database as a reader.
Wed, 28 Aug 2019 12:35:55 GMT DB instance restartedDet tar inte mycket tid för Aurora att befordra en slav till att bli en herre, och degradera mästaren till att bli en slav. Observera att alla Aurora-repliker delar samma underliggande volym med den primära instansen och det betyder att replikering kan utföras på millisekunder eftersom uppdateringar gjorda av den primära instansen är omedelbart tillgängliga för alla Aurora-repliker. Därför har den minimal replikeringsfördröjning (Amazon påstod sig vara 100 millisekunder och mindre). Detta kommer att avsevärt minska hälsokontrolltiden och förbättra återhämtningstiden avsevärt.
Failover med ClusterControl
I det här exemplet imiterar vi en liknande installation med Amazon RDS med hjälp av m5.xlarge-instanser, med en ProxySQL däremellan för att automatisera failover från applikation med en enda slutpunktsåtkomst precis som RDS. Följande diagram illustrerar vår arkitektur:
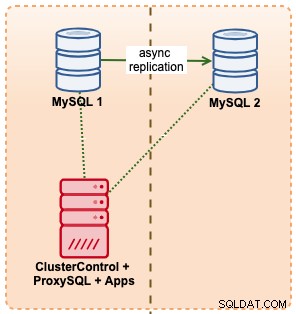
Eftersom vi har direkt åtkomst till databasinstanserna skulle vi utlösa en automatisk failover genom att helt enkelt döda MySQL-processen på den aktiva mastern:
$ kill -9 $(pidof mysqld)Ovanstående kommando utlöste en automatisk återställning inuti ClusterControl:
[11:08:49]: Job Completed.
[11:08:44]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: 10.15.3.141:3306: Flushing logs to update 'SHOW SLAVE HOSTS'
[11:08:39]: Failover Complete. New master is 10.15.3.141:3306.
[11:08:39]: Attaching slaves to new master.
[11:08:39]: 10.15.3.141:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.
[11:08:39]: 10.15.3.141:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:39]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:39]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: 10.15.3.141:3306: Setting read_only=OFF and super_read_only=OFF.
[11:08:38]: 10.15.3.141:3306: Successfully stopped slave.
[11:08:38]: 10.15.3.141:3306: Stopping slave.
[11:08:38]: Stopping slaves.
[11:08:38]: 10.15.3.141:3306: Completed preparations of candidate.
[11:08:38]: 10.15.3.141:3306: Applied 0 transactions. Remaining: .
[11:08:38]: 10.15.3.141:3306: waiting up to 4294967295 seconds before timing out.
[11:08:38]: 10.15.3.141:3306: Checking if the candidate has relay log to apply.
[11:08:38]: 10.15.3.141:3306: preparing candidate.
[11:08:38]: No errant transactions found.
[11:08:38]: 10.15.3.141:3306: Skipping, same as slave 10.15.3.141:3306
[11:08:38]: Checking for errant transactions.
[11:08:37]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Can't connect to MySQL server on '10.15.3.69' (115)
[11:08:37]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:37]: 10.15.3.69:3306: Failed to CREATE USER rpl_user. Error: 10.15.3.69:3306: Query failed: Can't connect to MySQL server on '10.15.3.69' (115).
[11:08:36]: 10.15.3.69:3306: Creating user 'rpl_user'@'10.15.3.141.
[11:08:36]: 10.15.3.141:3306: Executing GRANT REPLICATION SLAVE 'rpl_user'@'10.15.3.69'.
[11:08:36]: 10.15.3.141:3306: Creating user 'rpl_user'@'10.15.3.69.
[11:08:36]: 10.15.3.141:3306: Elected as the new Master.
[11:08:36]: 10.15.3.141:3306: Slave lag is 0 seconds.
[11:08:36]: 10.15.3.141:3306 to slave list
[11:08:36]: 10.15.3.141:3306: Checking if slave can be used as a candidate.
[11:08:33]: 10.15.3.69:3306: Trying to shutdown the failed master if it is up.
[11:08:32]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:31]: 10.15.3.141:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.69:3306: Setting read_only=ON and super_read_only=ON.
[11:08:30]: 10.15.3.141:3306: ioerrno=2003 io running 0
[11:08:30]: Checking 10.15.3.141:3306
[11:08:30]: 10.15.3.69:3306: REPL_UNDEFINED
[11:08:30]: 10.15.3.69:3306
[11:08:30]: Failover to a new Master.
Job spec: Failover to a new Master.Medan från vår testapplikationssynpunkt inträffade stilleståndstiden vid följande tidpunkt vid anslutning till ProxySQL-värdport 6033:
...
count 1 : OK Wed Aug 28 11:08:24 UTC 2019
count 2 : OK Wed Aug 28 11:08:25 UTC 2019
count 3 : OK Wed Aug 28 11:08:26 UTC 2019
count 4 : Fail ---- Wed Aug 28 11:08:28 UTC 2019
count 5 : Fail ---- Wed Aug 28 11:08:30 UTC 2019
count 6 : Fail ---- Wed Aug 28 11:08:32 UTC 2019
count 7 : Fail ---- Wed Aug 28 11:08:34 UTC 2019
count 8 : Fail ---- Wed Aug 28 11:08:36 UTC 2019
count 9 : Fail ---- Wed Aug 28 11:08:38 UTC 2019
count 10 : OK Wed Aug 28 11:08:39 UTC 2019
count 11 : OK Wed Aug 28 11:08:40 UTC 2019
...Genom att titta på både återställningsjobbhändelserna och utdata från vår applikation var MySQL-databasnoden nere 4 sekunder innan klusteråterställningsjobbet startar, från 11:08:28 till 11:08:39, med en total nedtid för MySQL på 11 sekunder . En av de mest imponerande sakerna med ClusterControl är att du kan spåra återställningens framsteg på vilken åtgärd som vidtas och utförs av ClusterControl under failover. Det ger en nivå av transparens som du inte kommer att kunna få med några databaserbjudanden från molnleverantörer.
För MySQL/MariaDB/PostgreSQL-replikering låter ClusterControl dig ha en mer finkornig mot dina databaser med stöd av följande avancerade konfiguration och parametrar:
- Master-master replikeringstopologihantering
- Kedjereplikeringstopologihantering
- Topologivisare
- Vitlista/svartlista slavar som ska befordras som master
- Felaktig transaktionskontroll
- Före/posta, framgångsrika/misslyckade failover/switchover-händelser krok med externt skript
- Automatisk återuppbyggnadsslav vid fel
- Skala ut slav från befintlig säkerhetskopia
översikt över underskottstid
När det gäller failover-tid är Amazon RDS Aurora för MySQL den klara vinnaren med 7 sekunder , följt av ClusterControl 11 sekunder och Amazon RDS för MySQL med 27 sekunder .
Observera att detta bara är ett enkelt test, med en klient och en transaktion per sekund för att mäta den snabbaste återhämtningstiden. Stora transaktioner eller en lång återställningsprocess kan öka failover-tiden, t.ex. kan långa transaktioner ta lång tid att rulla tillbaka när MySQL stängs av.