Att gå i produktion är en mycket viktig uppgift som måste vara noga genomtänkt och planerad i förväg. Vissa mindre bra beslut kan lätt korrigeras i efterhand, men andra inte. Så det är alltid bättre att lägga den extra tiden på att läsa de officiella dokumenten, böckerna och forskning som gjorts av andra tidigt, än att ångra senare. Detta är sant för de flesta datorsystemdistributioner, och PostgreSQL är inget undantag.
Initial planering av systemet
Vissa beslut måste fattas tidigt, innan systemet sätts i drift. PostgreSQL DBA måste svara på ett antal frågor:Kommer DB att köras på ren metall, virtuella datorer eller till och med containeriserade? Kommer det att köras i organisationens lokaler eller i molnet? Vilket OS kommer att användas? Kommer lagringen att vara av typ snurrande skivor eller SSD:er? För varje scenario eller beslut finns det för- och nackdelar och det slutliga samtalet kommer att göras i samarbete med intressenterna enligt organisationens krav. Traditionellt brukade folk köra PostgreSQL på ren metall, men detta har förändrats dramatiskt under de senaste åren med fler och fler molnleverantörer som erbjuder PostgreSQL som ett standardalternativ, vilket är ett tecken på den breda användningen och ett resultat av ökande popularitet för PostgreSQL. Oberoende av den specifika lösningen måste DBA säkerställa att data är säker, vilket innebär att databasen kommer att kunna överleva krascher, och detta är No1-kriteriet när man fattar beslut om hårdvara och lagring. Så detta leder oss till det första tipset!
Tips 1
Oavsett vad diskkontrollern eller disktillverkaren eller molnlagringsleverantören annonserar, bör du alltid se till att lagringen inte ljuger om fsync. När fsync återgår till OK bör data vara säker på mediet oavsett vad som händer efteråt (krasch, strömavbrott, etc.). Ett trevligt verktyg som hjälper dig att testa tillförlitligheten hos dina diskars återskrivningscache är diskchecker.pl.
Läs bara anteckningarna:https://brad.livejournal.com/2116715.html och gör testet.
Använd en maskin för att lyssna på händelser och den faktiska maskinen för att testa. Du bör se:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0i slutet av rapporten om den testade maskinen.
Den andra frågan efter tillförlitlighet bör handla om prestanda. Beslut om system (CPU, minne) brukade vara mycket viktigare eftersom det var ganska svårt att ändra dem senare. Men i dagens, i molnets era, kan vi vara mer flexibla när det gäller de system som DB körs på. Detsamma gäller för lagring, särskilt i ett systems tidiga liv och medan storlekarna fortfarande är små. När DB:n kommer förbi TB-siffran i storlek, blir det svårare och svårare att ändra grundläggande lagringsparametrar utan att behöva kopiera databasen helt - eller ännu värre, att utföra en pg_dump, pg_restore. Det andra tipset handlar om systemprestanda.
Tips 2
På samma sätt som att alltid testa tillverkarnas löften om tillförlitlighet, detsamma bör du göra om hårdvarans prestanda. Bonnie++ är det mest populära riktmärket för lagringsprestanda för Unix-liknande system. För övergripande systemtestning (CPU, minne och även lagring) är inget mer representativt än DB:s prestanda. Så det grundläggande prestandatestet på ditt nya system skulle vara att köra pgbench, den officiella PostgreSQL benchmarksviten baserad på TCP-B.
Att komma igång med pgbench är ganska enkelt, allt du behöver göra är:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Du bör alltid konsultera pgbench efter alla viktiga förändringar som du vill bedöma och jämföra resultaten.
Systemdistribution, automatisering och övervakning
När du väl går live är det mycket viktigt att ha dina huvudsystemkomponenter dokumenterade och reproducerbara, att ha automatiserade procedurer för att skapa tjänster och återkommande uppgifter och även ha verktygen för att utföra kontinuerlig övervakning.
Tips 3
Ett praktiskt sätt att börja använda PostgreSQL med alla dess avancerade företagsfunktioner är ClusterControl av Severalnines. Man kan ha ett PostgreSQL-kluster i företagsklass, bara genom att trycka några klick. ClusterControl tillhandahåller alla de ovan nämnda tjänsterna och många fler. Att ställa in ClusterControl är ganska enkelt, följ bara instruktionerna i den officiella dokumentationen. När du har förberett dina system (vanligtvis ett för att köra CC och ett för PostgreSQL för en grundläggande installation) och gjort SSH-inställningen, måste du ange de grundläggande parametrarna (IP:er, portnr, etc), och om allt går bra bör du se en utdata som följande:
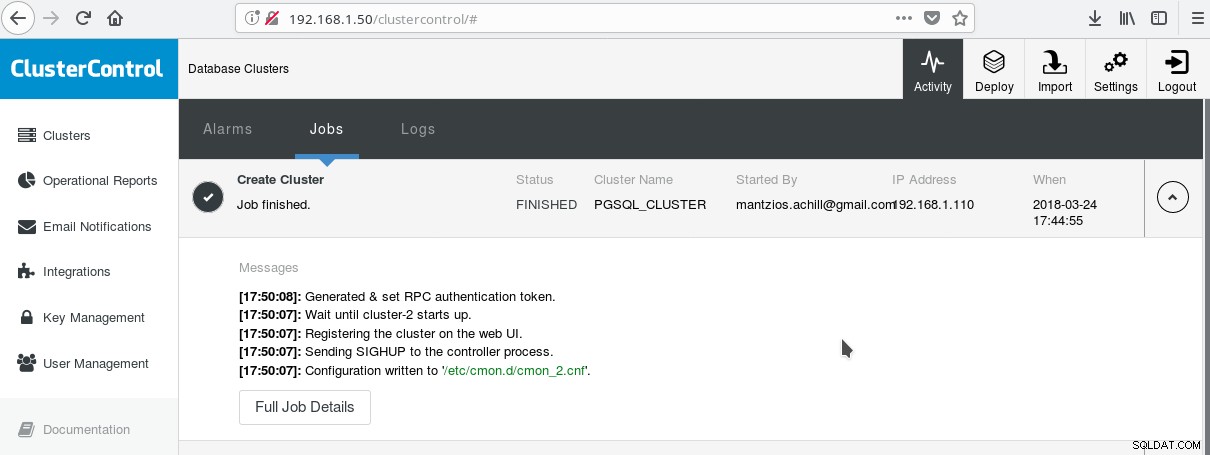
Och på huvudskärmen för kluster:
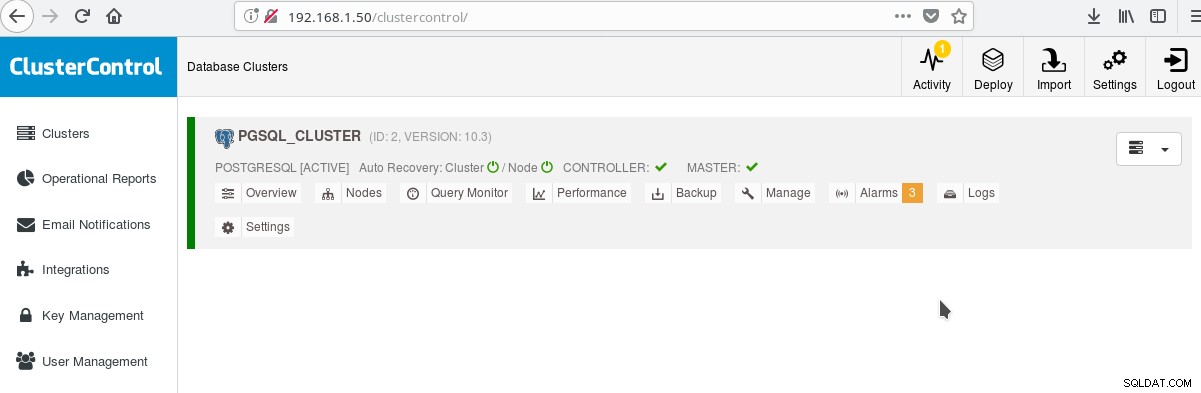
Du kan logga in på din huvudserver och börja skapa ditt schema! Naturligtvis kan du använda det kluster du just skapade som bas för att ytterligare bygga upp din infrastruktur (topologi). En allmänt bra idé är att ha en stabil serverfilsystemlayout och en slutlig konfiguration på din PostgreSQL-server och användar-/appdatabaser innan du börjar skapa kloner och standbys (slavar) baserat på din nyss skapade helt nya server.
PostgreSQL-layout, parametrar och inställningar
I klusterinitieringsfasen är det viktigaste beslutet om man ska använda datakontrollsummor på datasidor eller inte. Om du vill ha maximal datasäkerhet för dina värdefulla (framtida) data, då är det här dags att göra det. Om det finns en chans att du kanske vill ha den här funktionen i framtiden och du försummar att göra det i detta skede, kommer du inte att kunna ändra det senare (utan pg_dump/pg_restore alltså). Detta är nästa tips:
Tips 4
För att aktivera datakontrollsummor kör initdb enligt följande:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Observera att detta bör göras vid tidpunkten för tips 3 som vi beskrev ovan. Om du redan skapat klustret med ClusterControl måste du köra om pg_createcluster för hand, eftersom det inte finns något sätt att säga åt systemet eller CC att inkludera detta alternativ när detta skrivs.
Ett annat mycket viktigt steg innan du går i produktion är att planera för serverns filsystemlayout. De flesta moderna Linux-distros (åtminstone de debianbaserade) monterar allt på / men med PostgreSQL vill du normalt inte ha det. Det är fördelaktigt att ha dina tabellutrymmen på separata volymer, att ha en volym dedikerad för WAL-filerna och en annan för pg-logg. Men det viktigaste är att flytta WAL till sin egen disk. Detta för oss till nästa tips.
Tips 5
Med PostgreSQL 10 på Debian Stretch kan du flytta din WAL till en ny disk med följande kommandon (förutsatt att den nya disken heter /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlDet är oerhört viktigt att korrekt ställa in lokalen och kodningen för dina databaser. Förbise detta i den skapade fasen och du kommer att ångra detta mycket, eftersom din app/DB flyttar in i i18n, l10n-områdena. Nästa tips visar hur du gör det.
Tips 6
Du bör läsa de officiella dokumenten och bestämma dina inställningar för COLLATE och CTYPE (createdb --locale=) (ansvarig för sorteringsordning och teckenklassificering) samt charset-inställningen (createdb --encoding=). Om du anger UTF8 som kodning kommer din databas att kunna lagra flerspråkig text.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperPostgreSQL hög tillgänglighet
Eftersom PostgreSQL 9.0, när strömmande replikering blev en standardfunktion, blev det möjligt att ha en eller flera skrivskyddade heta standby-lägen, vilket möjliggör möjligheten att dirigera skrivskyddad trafik till någon av de tillgängliga slavarna. Nya planer finns för multimaster-replikering men när detta skrivs (10.3) är det bara möjligt att ha en läs-skriv-master, åtminstone i den officiella open source-produkten. För nästa tips som handlar om just detta.
Tips 7
Vi kommer att använda vår ClusterControl PGSQL_CLUSTER skapad i Tips 3. Först skapar vi en andra maskin som kommer att fungera som vår skrivskyddade slav (hot standby i PostgreSQL-terminologi). Sedan klickar vi på Lägg till replikeringsslav och väljer vår master och den nya slaven. När jobbet är klart bör du se denna utdata:
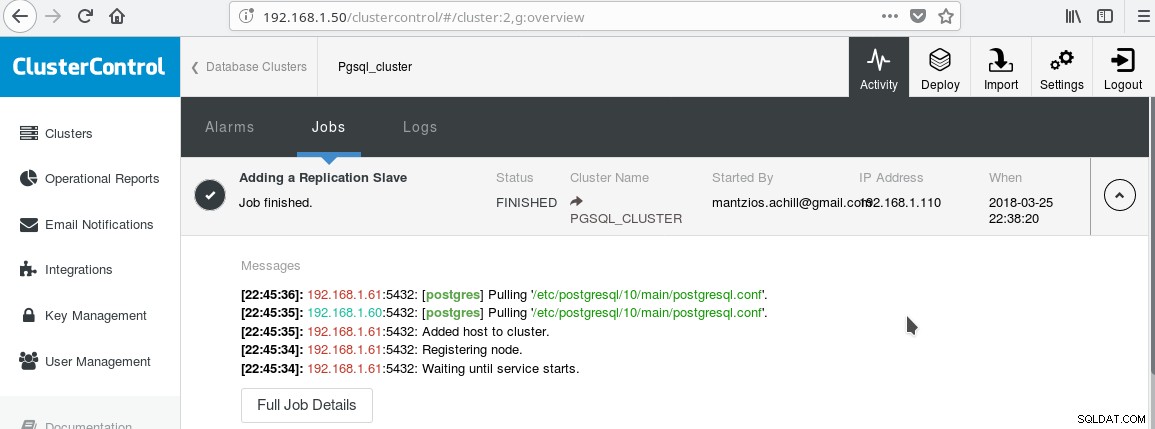
Och klustret bör nu se ut så här:
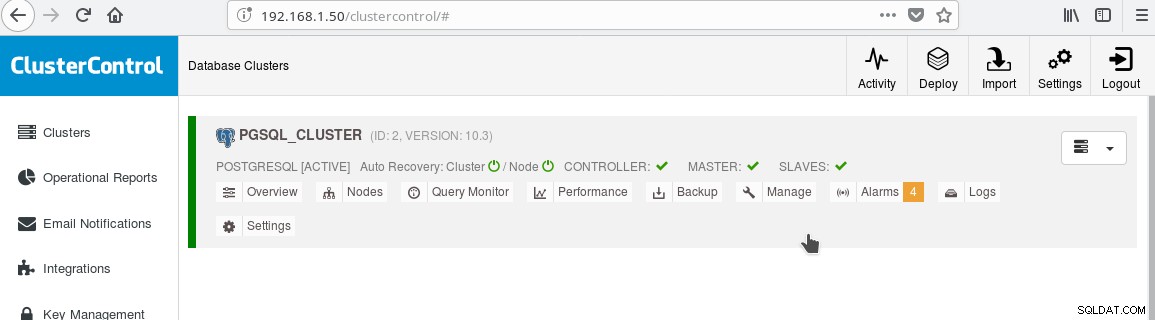
Notera den gröna "markerade" ikonen på "SLAVES"-etiketten bredvid "MASTER". Du kan verifiera att strömmande replikering fungerar genom att skapa ett databasobjekt (databas, tabell, etc) eller infoga några rader i en tabell på mastern och se ändringen i vänteläge.
Närvaron av skrivskyddat standby-läge gör det möjligt för oss att utföra lastbalansering för klienterna som gör endast urvalsfrågor mellan de två tillgängliga servrarna, mastern och slaven. Detta tar oss till tips 8.
Tips 8
Du kan aktivera lastbalansering mellan de två servrarna med HAProxy. Med ClusterControl är detta ganska enkelt att göra. Du klickar på Hantera->Load Balancer. Efter att ha valt din HAProxy-server kommer ClusterControl att installera allt åt dig:xinetd på alla instanser du angett och HAProxy på din HAProxy-designade server. När jobbet har slutförts ska du se:
Notera den gröna bocken för HAPROXY bredvid SLAVERNA. Nu kan du testa att HAProxy fungerar:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Tips 9
Förutom att konfigurera för HA och lastbalansering är det alltid fördelaktigt att ha någon form av anslutningspool framför PostgreSQL-servern. Pgpool och Pgbouncer är två projekt som kommer från PostgreSQL-communityt. Många företagsapplikationsservrar tillhandahåller också sina egna pooler. Pgbouncer har varit mycket populär på grund av sin enkelhet, hastighet och funktionen "transaktionspooling", genom vilken anslutning till servern frigörs när transaktionen avslutas, vilket gör den återanvändbar för efterföljande transaktioner som kan komma från samma session eller en annan. . Inställningen för transaktionspoolning bryter vissa sessionspoolningsfunktioner, men i allmänhet är konverteringen till en "transaktionspooling"-färdig installation enkel och nackdelarna är inte så viktiga i det allmänna fallet. En vanlig inställning är att konfigurera appserverns pool med semi-beständiga anslutningar:En ganska större pool av anslutningar per användare eller per app (som ansluter till pgbouncer) med långa inaktiva timeouts. På så sätt är anslutningstiden från appen minimal medan pgbouncer hjälper till att hålla anslutningarna till servern så få som möjligt.
En sak som med största sannolikhet kommer att vara oroande när du går live med PostgreSQL är att förstå och fixa långsamma frågor. Övervakningsverktygen som vi nämnde i den tidigare bloggen som pg_stat_statements och även skärmarna med verktyg som ClusterControl hjälper dig att identifiera och eventuellt föreslå idéer för att fixa långsamma frågor. Men när du har identifierat den långsamma frågan måste du köra EXPLAIN eller EXPLAIN ANALYZE för att se exakt vilka kostnader och tider som är involverade i frågeplanen. Nästa tips handlar om ett mycket användbart verktyg för att göra det.
Tips 10
Du måste köra din EXPLAIN ANALYZE på din databas och sedan kopiera utdata och klistra in den i depesz:s förklara analys online-verktyg och klicka på skicka. Då kommer du att se tre flikar:HTML, TEXT och STATISTIK. HTML innehåller kostnad, tid och antal loopar för varje nod i planen. Fliken STATISTIK visar statistik per nodtyp. Du bör observera kolumnen "% av sökfrågan" så att du vet exakt var din fråga lider.
När du blir mer bekant med PostgreSQL kommer du att hitta många fler tips på egen hand!