Sammankopplingen av två eller flera datamängder uttrycks oftast i T-SQL med UNION ALL klausul. Med tanke på att SQL Server-optimeraren ofta kan ordna om saker som kopplingar och aggregat för att förbättra prestandan, är det ganska rimligt att förvänta sig att SQL Server också skulle överväga att omordna sammankopplingsingångar, där detta skulle ge en fördel. Till exempel kan optimeraren överväga fördelarna med att skriva om A UNION ALL B som B UNION ALL A .
Faktum är att SQL Server-optimeraren inte gör det gör det här. Närmare bestämt fanns det ett visst begränsat stöd för omordning av sammanlänkningsindata i SQL Server-versioner upp till 2008 R2, men detta togs bort i SQL Server 2012 och har inte dykt upp igen sedan dess.
SQL Server 2008 R2
Intuitivt spelar ordningen för sammanlänkningsingångar bara roll om det finns ett radmål . Som standard optimerar SQL Server exekveringsplaner utifrån att alla kvalificerande rader kommer att returneras till klienten. När ett radmål är i kraft försöker optimeraren hitta en exekveringsplan som kommer att producera de första raderna snabbt.
Radmål kan ställas in på ett antal sätt, till exempel med TOP , en FAST n frågetips, eller genom att använda EXISTS (som till sin natur behöver hitta högst en rad). Där det inte finns något radmål (dvs. klienten kräver alla rader), spelar det generellt ingen roll i vilken ordning sammanlänkningsinmatningarna läses:Varje indata kommer att bearbetas fullständigt så småningom i alla fall.
Det begränsade stödet i versioner upp till SQL Server 2008 R2 gäller där det finns ett mål om exakt en rad . I det här specifika fallet kommer SQL Server att ordna om sammanlänkningsindata baserat på förväntad kostnad.
Detta görs inte under kostnadsbaserad optimering (som man kan förvänta sig), utan snarare som en omskrivning efter optimering i sista minuten av den normala optimeringsutgången. Detta arrangemang har fördelen att det inte ökar det kostnadsbaserade sökutrymmet för planen (potentiellt ett alternativ för varje möjlig omordning), samtidigt som det producerar en plan som är optimerad för att snabbt returnera den första raden.
Exempel
Följande exempel använder två tabeller med identiskt innehåll:En miljon rader med heltal från en till en miljon. En tabell är en hög utan några icke-klustrade index; den andra har ett unikt klustrat index:
CREATE TABLE dbo.Expensive
(
Val bigint NOT NULL
);
CREATE TABLE dbo.Cheap
(
Val bigint NOT NULL,
CONSTRAINT [PK dbo.Cheap Val]
UNIQUE CLUSTERED (Val)
);
GO
INSERT dbo.Cheap WITH (TABLOCKX)
(Val)
SELECT TOP (1000000)
Val = ROW_NUMBER() OVER (ORDER BY SV1.number)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
Val
OPTION (MAXDOP 1);
GO
INSERT dbo.Expensive WITH (TABLOCKX)
(Val)
SELECT
C.Val
FROM dbo.Cheap AS C
OPTION (MAXDOP 1); Inga radmål
Följande fråga letar efter samma rader i varje tabell och returnerar sammanlänkningen av de två uppsättningarna:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005; Utförandeplanen som skapas av frågeoptimeraren är:
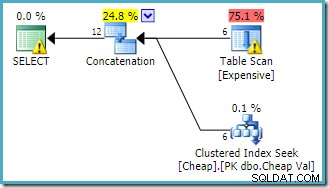
Varningen på roten SELECT operatören uppmärksammar oss på det uppenbart saknade indexet på högbordet. Varningen på Table Scan-operatören läggs till av Sentry One Plan Explorer. Det uppmärksammar oss på I/O-kostnaden för det kvarvarande predikatet som är gömt i skanningen.
Ordningen på ingångarna till Sammankopplingen spelar ingen roll här, eftersom vi inte har satt något radmål. Båda ingångarna kommer att läsas fullständigt för att returnera alla resultatrader. Av intresse (även om detta inte är garanterat) notera att ordningen på inmatningarna följer textordningen för den ursprungliga frågan. Observera också att ordningen på de slutliga resultatraderna inte heller anges, eftersom vi inte använde en ORDER BY på toppnivå klausul. Vi antar att det är avsiktligt och att den slutliga beställningen inte har någon betydelse för den aktuella uppgiften.
Om vi vänder om den skrivna ordningen för tabellerna i frågan så här:
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005; Exekveringsplanen följer ändringen och kommer först åt den klustrade tabellen (igen, detta är inte garanterat):
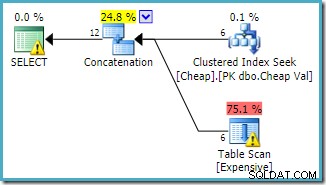
Båda frågorna kan förväntas ha samma prestandaegenskaper, eftersom de utför samma operationer, bara i en annan ordning.
Med ett radmål
Uppenbarligen kommer bristen på indexering på heaptabellen normalt att göra det dyrare att hitta specifika rader, jämfört med samma operation på den klustrade tabellen. Om vi ber optimeraren om en plan som returnerar den första raden snabbt, förväntar vi oss att SQL Server ändrar ordningen på sammanlänkningsingångarna så att den billiga klustrade tabellen konsulteras först.
Använda frågan som nämner högtabellen först och använda en FAST 1 frågetips för att ange radmålet:
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
OPTION (FAST 1); Den beräknade exekveringsplanen producerad på en instans av SQL Server 2008 R2 är:
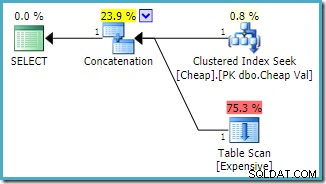
Observera att sammanlänkningsingångarna har ordnats om för att minska den uppskattade kostnaden för att returnera den första raden. Observera också att det saknade indexet och resterande I/O-varningar har försvunnit. Ingen av frågorna är av betydelse med denna planform när målet är att returnera en enda rad så snabbt som möjligt.
Samma fråga kördes på SQL Server 2016 (med endera kardinalitetsuppskattningsmodellen) är:
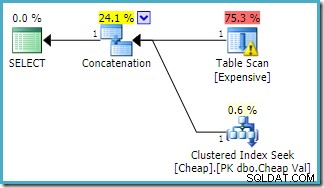
SQL Server 2016 har inte ordnat om sammanlänkningsingångarna. Plan Explorer I/O-varningen har kommit tillbaka, men tyvärr har optimeraren inte producerat en saknad indexvarning den här gången (även om den är relevant).
Allmän omordning
Som nämnts är omskrivningen efter optimering som omordnar sammankopplingsingångar endast effektiv för:
- SQL Server 2008 R2 och tidigare
- Ett radmål på exakt ett
Om vi verkligen bara vill ha en rad returnerad, snarare än en plan som är optimerad för att returnera den första raden snabbt (men som i slutändan fortfarande kommer att returnera alla rader), kan vi använda en TOP sats med en härledd tabell eller gemensamt tabelluttryck (CTE):
SELECT TOP (1)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA; På SQL Server 2008 R2 eller tidigare producerar detta den optimala omordnade inmatningsplanen:
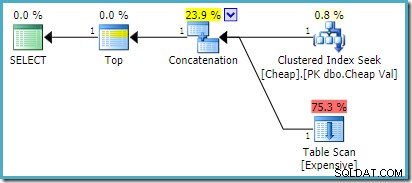
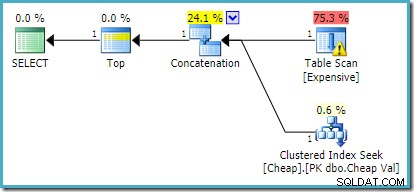
På SQL Server 2012, 2014 och 2016 sker ingen omordning efter optimering:
Om vi vill ha mer än en rad returnerad, till exempel med TOP (2) , kommer den önskade omskrivningen inte att tillämpas på SQL Server 2008 R2 även om en FAST 1 ledtråd används också. I den situationen måste vi ta till knep som att använda TOP med en variabel och en OPTIMIZE FOR tips:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed
SELECT TOP (@TopRows)
UA.Val
FROM
(
SELECT E.Val
FROM dbo.Expensive AS E
WHERE
E.Val BETWEEN 751000 AND 751005
UNION ALL
SELECT C.Val
FROM dbo.Cheap AS C
WHERE
C.Val BETWEEN 751000 AND 751005
) AS UA
OPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint Frågetipset är tillräckligt för att ställa in ett radmål på ett, medan körtidsvärdet för variabeln säkerställer att det önskade antalet rader (2) returneras.
Den faktiska exekveringsplanen på SQL Server 2008 R2 är:
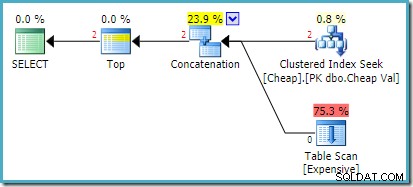
Båda raderna som returneras kommer från den omordnade sökinmatningen, och tabellsökningen utförs inte alls. Plan Explorer visar radantalet i rött eftersom uppskattningen gällde en rad (på grund av tipset) medan två rader påträffades vid körning.
Utan UNION ALL
Det här problemet är inte heller begränsat till frågor skrivna uttryckligen med UNION ALL . Andra konstruktioner som EXISTS och OR kan också resultera i att optimeraren introducerar en sammanlänkningsoperator, som kan lida av bristen på omordning av input. Det var nyligen en fråga om Database Administrators Stack Exchange med exakt detta problem. Omvandla frågan från den frågan till att använda våra exempeltabeller:
SELECT
CASE
WHEN
EXISTS
(
SELECT 1
FROM dbo.Expensive AS E
WHERE E.Val BETWEEN 751000 AND 751005
)
OR EXISTS
(
SELECT 1
FROM dbo.Cheap AS C
WHERE C.Val BETWEEN 751000 AND 751005
)
THEN 1
ELSE 0
END; Exekveringsplanen på SQL Server 2016 har heaptabellen på den första ingången:
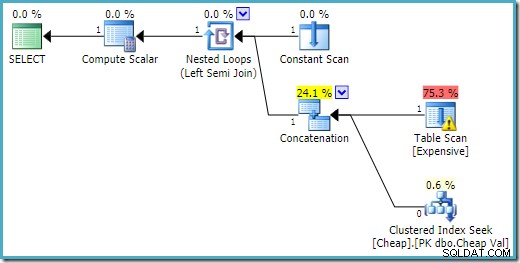
På SQL Server 2008 R2 är ordningen på ingångarna optimerad för att återspegla målet på en rad för semi-join:
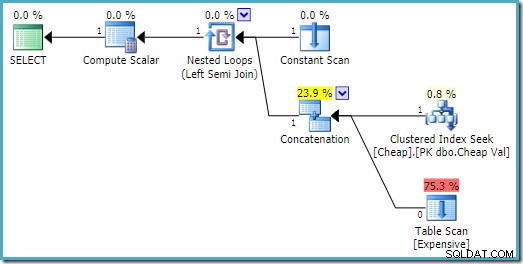
I den mer optimala planen exekveras aldrig heapskanningen.
Lösningar
I vissa fall kommer det att vara uppenbart för frågeskrivaren att en av sammankopplingsingångarna alltid kommer att vara billigare att köra än de andra. Om det stämmer är det ganska giltigt att skriva om frågan så att de billigare sammankopplingsingångarna visas först i skriftlig ordning. Detta innebär naturligtvis att frågeskrivaren måste vara medveten om denna optimeringsbegränsning och vara beredd att förlita sig på odokumenterat beteende.
En svårare fråga uppstår när kostnaden för sammankopplingsingångarna varierar med omständigheterna, kanske beroende på parametervärden. Använder OPTION (RECOMPILE) hjälper inte på SQL Server 2012 eller senare. Det alternativet kan vara till hjälp på SQL Server 2008 R2 eller tidigare, men bara om kravet på en rad mål också uppfylls.
Om det finns oro för att förlita sig på observerat beteende (frågeplans sammanlänkningsingångar som matchar frågans textordning) kan en planguide användas för att tvinga fram planformen. Där olika inmatningsorder är optimala för olika omständigheter, kan flera planguider användas, där villkoren kan kodas korrekt i förväg. Detta är dock knappast idealiskt.
Sluta tankar
SQL Server-frågeoptimeraren innehåller faktiskt en kostnadsbaserad utforskningsregel, UNIAReorderInputs , som kan generera sammanlänkningsinmatningsordervariationer och utforska alternativ under kostnadsbaserad optimering (inte som en omskrivning efter optimering i ett enda steg).
Denna regel är för närvarande inte aktiverad för allmän användning. Så vitt jag kan se, aktiveras den bara när en planguide eller USE PLAN ledtråd finns. Detta gör det möjligt för motorn att framgångsrikt tvinga fram en plan som genererades för en fråga som kvalificerade sig för omskrivning av indata-omordning, även när den aktuella frågan inte kvalificerar sig.
Min uppfattning är att denna utforskningsregel är avsiktligt begränsad till denna användning, eftersom frågor som skulle dra nytta av omordning av sammanlänkningsindata som en del av kostnadsbaserad optimering anses inte vara tillräckligt vanliga, eller kanske för att det finns en oro för att den extra ansträngningen inte skulle löna sig av. Min egen uppfattning är att omordning av indata från sammankopplingsoperatör alltid bör undersökas när ett radmål gäller.
Det är också synd att den (mer begränsade) omskrivningen efter optimering inte är effektiv i SQL Server 2012 eller senare. Detta kan ha berott på en subtil bugg, men jag kunde inte hitta något om detta i dokumentationen, kunskapsbasen eller på Connect. Jag har lagt till ett nytt Connect-objekt här.
Uppdatering 9 augusti 2017 :Detta är nu fixat under spårningsflagga 4199 för SQL Server 2014 och 2016, se KB 4023419:
FIX:Fråga med UNION ALL och ett radmål kan köras långsammare i SQL Server 2014 eller senare versioner när den jämförs med SQL Server 2008 R2