I den första delen av den här bloggen nämnde vi några viktiga koncept relaterade till en bra PostgreSQL-replikeringsmiljö. Låt oss nu se hur man kombinerar alla dessa saker på ett enkelt sätt med ClusterControl. För detta antar vi att du har ClusterControl installerat, men om inte kan du gå till den officiella webbplatsen eller hänvisa till den officiella dokumentationen för att installera den.
Distribuera PostgreSQL Streaming Replication
För att utföra en distribution av ett PostgreSQL-kluster från ClusterControl, välj alternativet Deploy och följ instruktionerna som visas.
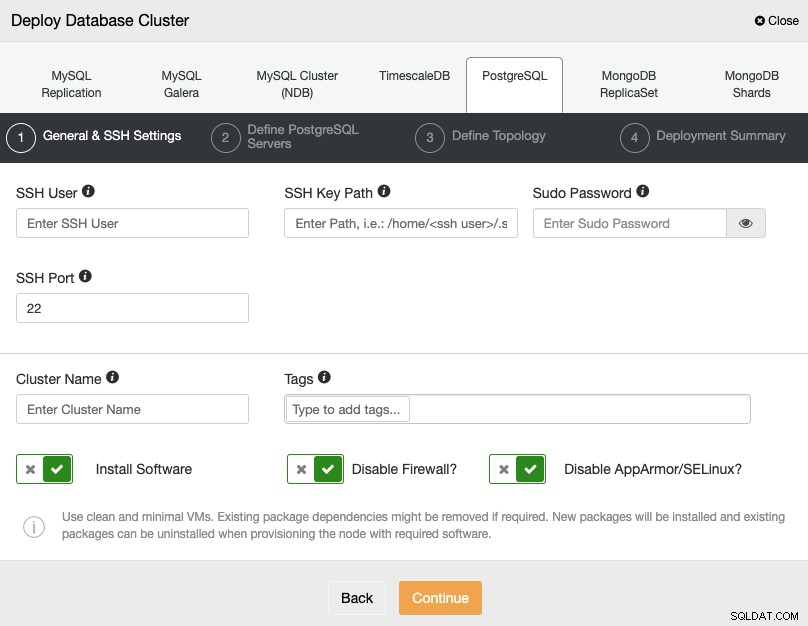
När du väljer PostgreSQL måste du ange användaren, nyckeln eller lösenordet och Port för att ansluta med SSH till dina servrar. Du kan också lägga till ett namn för ditt nya kluster och ange om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
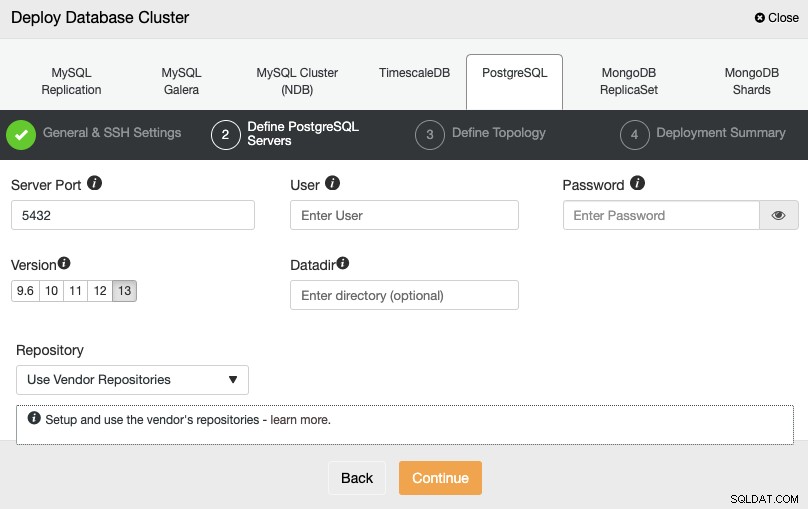
När du har ställt in SSH-åtkomstinformationen måste du definiera databasens autentiseringsuppgifter , version och datadir (valfritt). Du kan också ange vilket arkiv som ska användas.
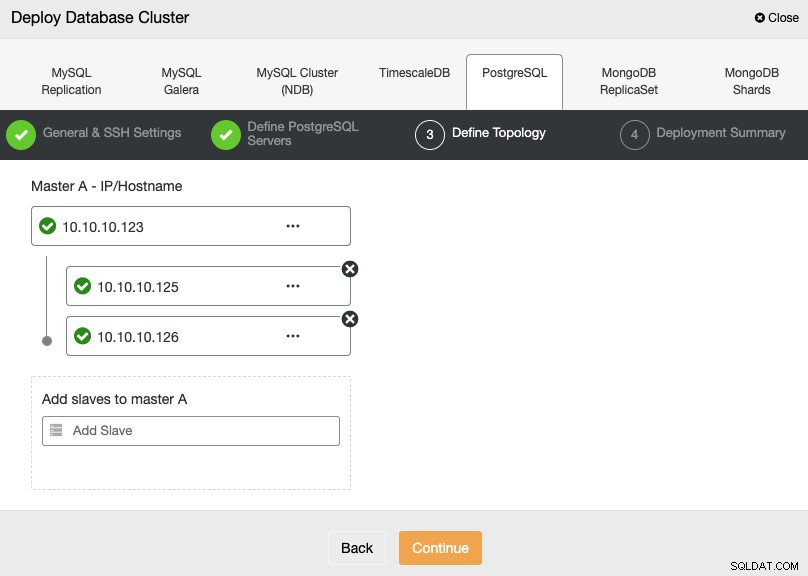
I nästa steg måste du lägga till dina servrar i klustret som du ska skapa med IP-adressen eller värdnamnet.
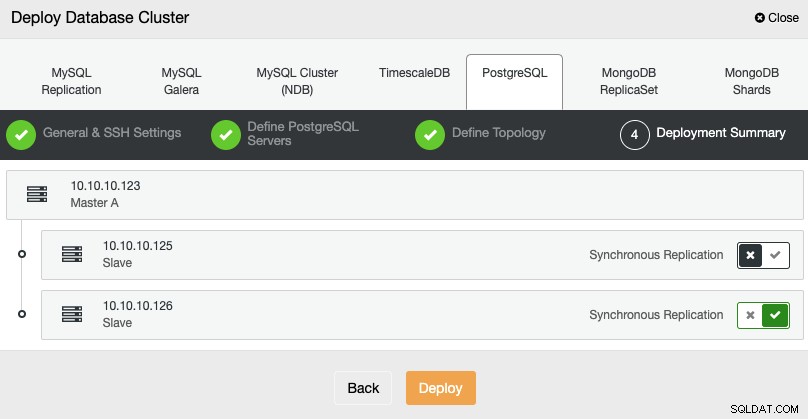
I det sista steget kan du välja om din replikering ska vara Synkron eller Asynkron, och tryck sedan bara på Deploy.
När uppgiften är klar kan du se ditt nya PostgreSQL-kluster i huvudskärmen för ClusterControl.

Nu har du skapat ditt kluster, du kan utföra flera uppgifter på det, som att lägga till en lastbalanserare (HAProxy), anslutningspooler (PgBouncer) eller en ny synkron eller asynkron replikeringsslav.
Lägga till synkrona och asynkrona replikeringsslavar
Gå till ClusterControl -> Klusteråtgärder -> Lägg till replikeringsslav.
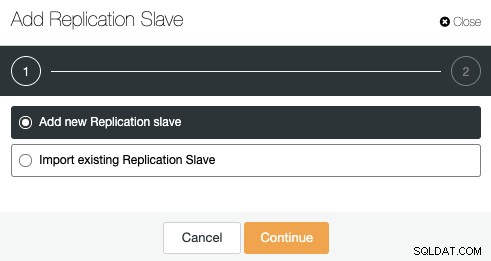
Du kan lägga till en ny replikeringsslav eller till och med importera en befintlig. Låt oss välja det första alternativet och fortsätta.
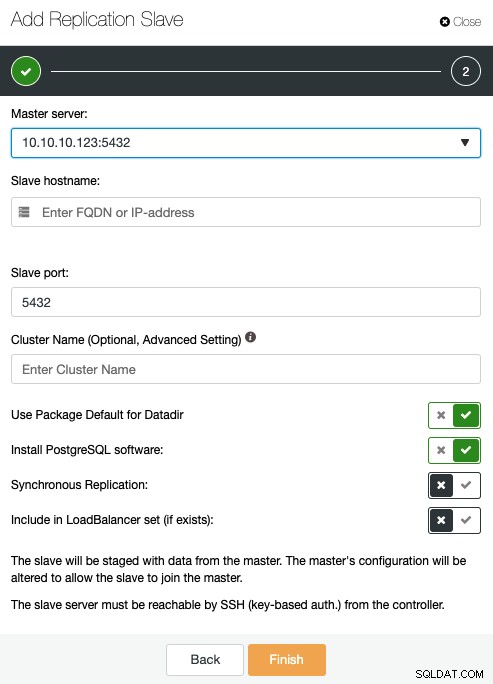
Här måste du ange huvudservern, IP-adressen eller värdnamnet för den nya replikeringsslaven, porten, och om du vill ClusterControl installera programvaran, eller inkludera denna nod i en befintlig lastbalanserare. Du kan också konfigurera replikeringen att vara synkron eller asynkron.
Nu har du ditt PostgreSQL-kluster på plats med motsvarande repliker, låt oss se hur du kan förbättra prestandan genom att lägga till en anslutningspoolare.
PgBouncer-distribution
Gå till ClusterControl -> Välj PostgreSQL Cluster -> Cluster Actions -> Add Load Balancer -> PgBouncer. Här kan du distribuera en ny PgBouncer-nod som kommer att distribueras i den valda databasnoden, eller till och med importera en befintlig PgBouncer.
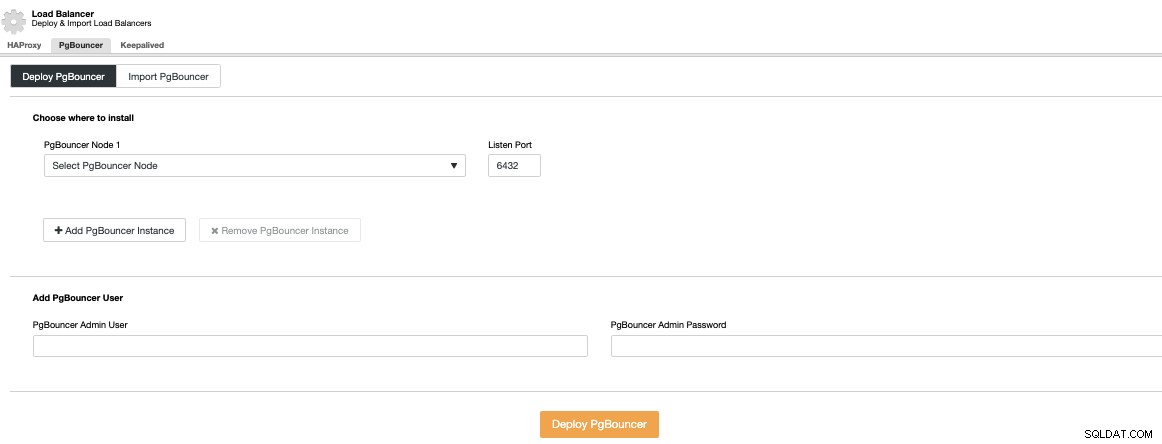
Du måste ange en IP-adress eller värdnamn, Listen-porten och PgBouncer-uppgifter. När du trycker på Deploy PgBouncer kommer ClusterControl att komma åt noden, installera och konfigurera allt utan någon manuell inblandning.
Du kan övervaka framstegen i ClusterControl-aktivitetssektionen. När den är klar måste du skapa den nya poolen. För detta, gå till ClusterControl -> Välj PostgreSQL Cluster -> Noder -> PgBouncer-noden.
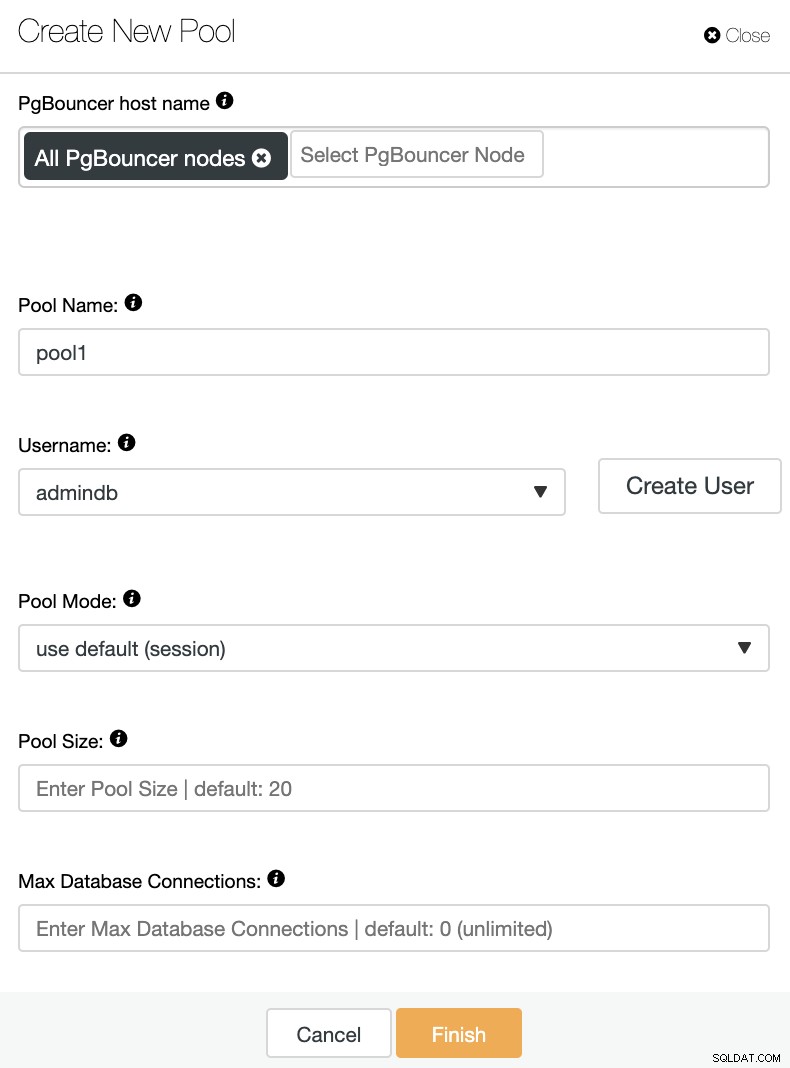
Du måste lägga till följande information:
-
PgBouncer-värdnamn:Välj nodvärdarna för att skapa anslutningspoolen.
-
Poolnamn:Pool- och databasnamn måste vara desamma.
-
Användarnamn: Välj en användare från PostgreSQL primära nod eller skapa en ny.
-
Poolläge:Det kan vara:session (standard), transaktion eller poolning av utdrag.
-
Poolstorlek:Maximal storlek på pooler för denna databas. Standardvärdet är 20.
-
Max databasanslutningar:Konfigurera ett databasomfattande maximum. Standardvärdet är 0, vilket betyder obegränsat.
Nu bör du kunna se poolen i nodsektionen.
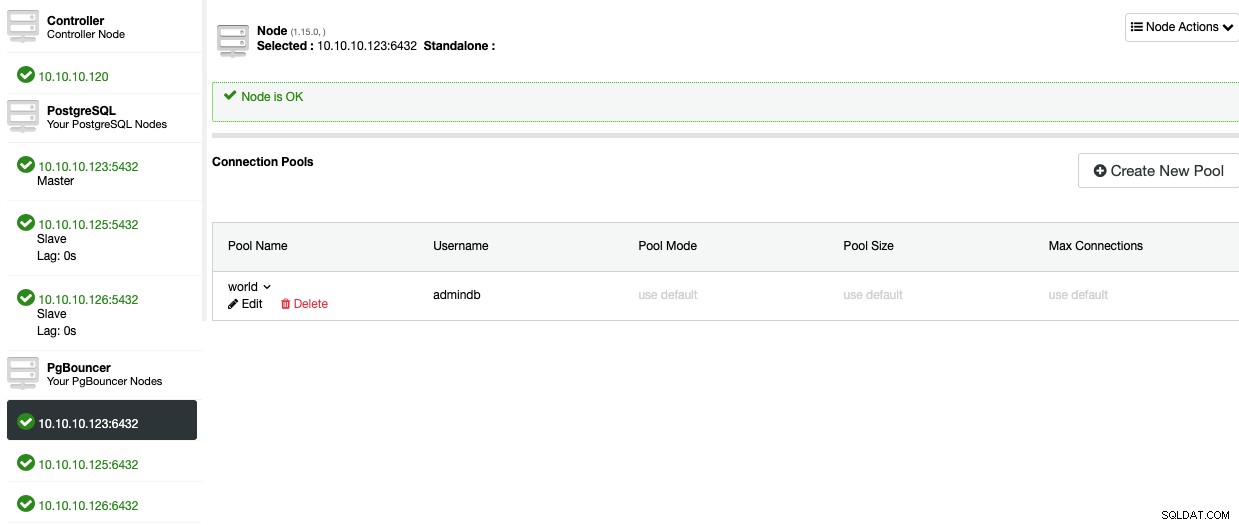
För att lägga till High Availability till din PostgreSQL-databas, låt oss se hur man distribuerar en lastbalanserare.
Load Balancer Deployment
För att utföra en distribution av lastbalanserare väljer du alternativet Lägg till lastbalanserare på menyn Cluster Actions och fyller i den begärda informationen.
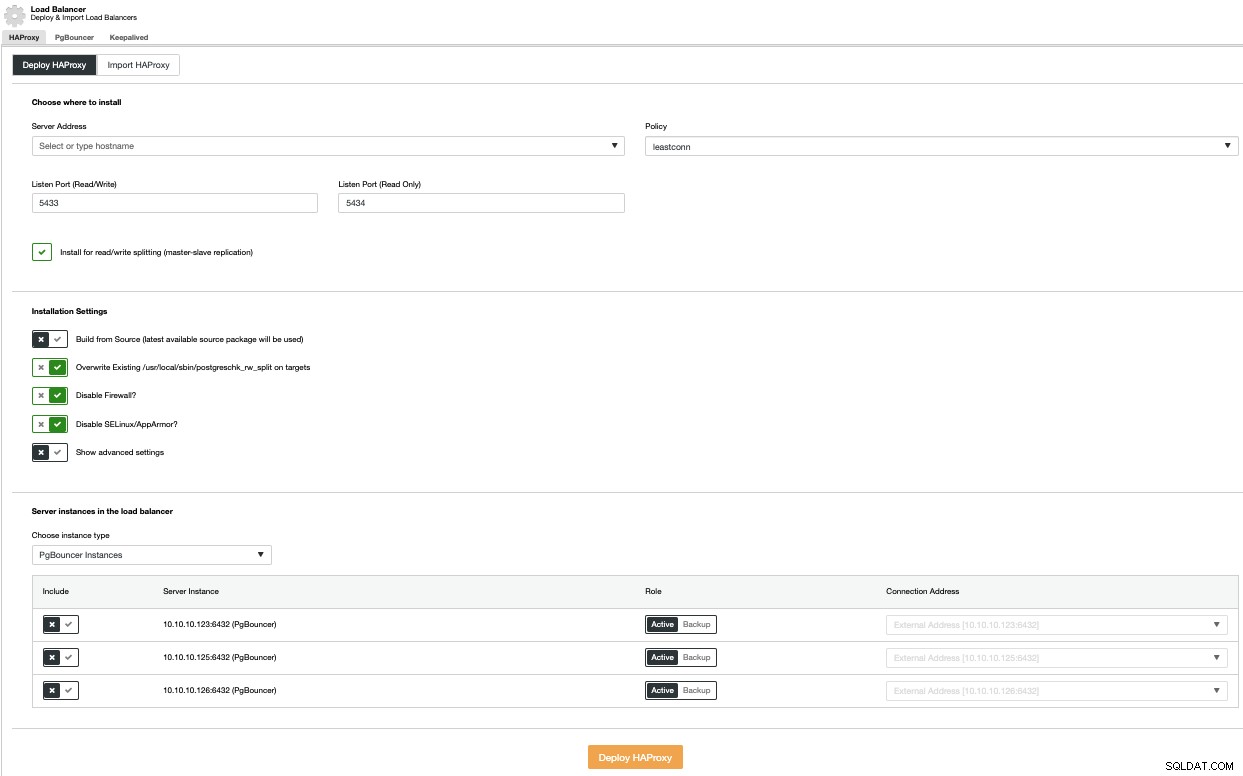
Du måste lägga till IP eller värdnamn, port, policy och noderna du ska använda. Om du använder PgBouncer kan du välja det i kombinationsrutan för instanstyp.
För att undvika en enda felpunkt bör du distribuera minst två HAProxy-noder och använda Keepalved som låter dig använda en virtuell IP-adress i din applikation som är tilldelad den aktiva HAProxy-noden. Om denna nod misslyckas kommer den virtuella IP-adressen att migreras till den sekundära belastningsutjämnaren, så att din applikation fortfarande kan fungera som vanligt.
Keelived Deployment
För att utföra en Keepalive-distribution, välj alternativet Lägg till Load Balancer i menyn Cluster Actions och gå sedan till Keepalved-fliken.
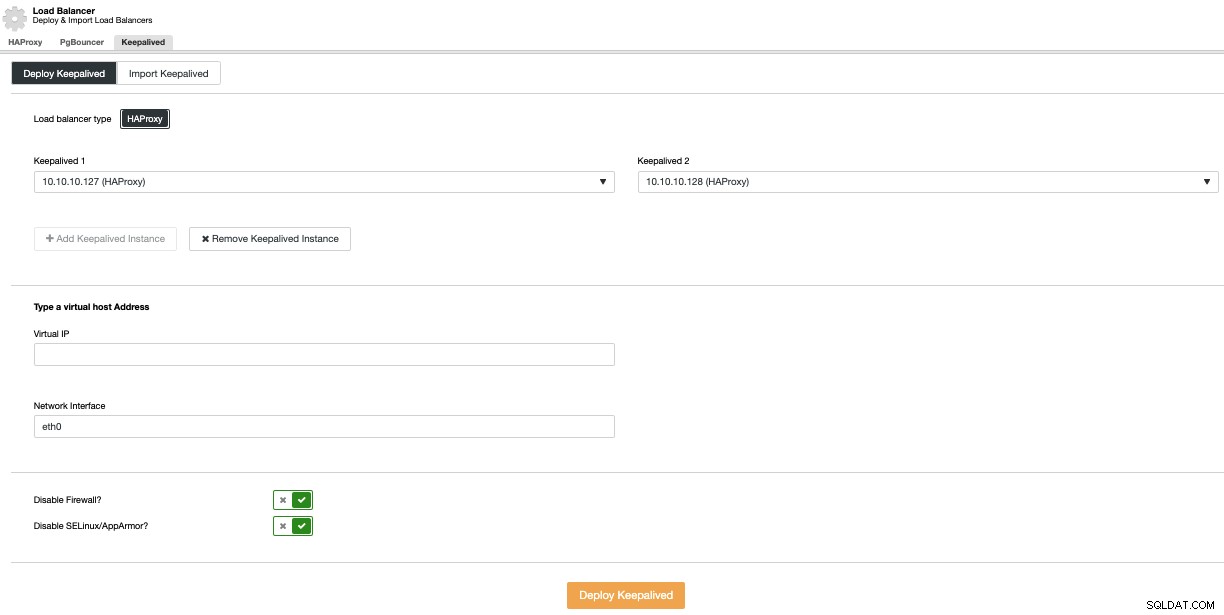
Här väljer du HAProxy-noderna och ange den virtuella IP-adressen som ska användas för att komma åt databasen (eller anslutningspoolern).
I detta ögonblick bör du ha följande topologi:
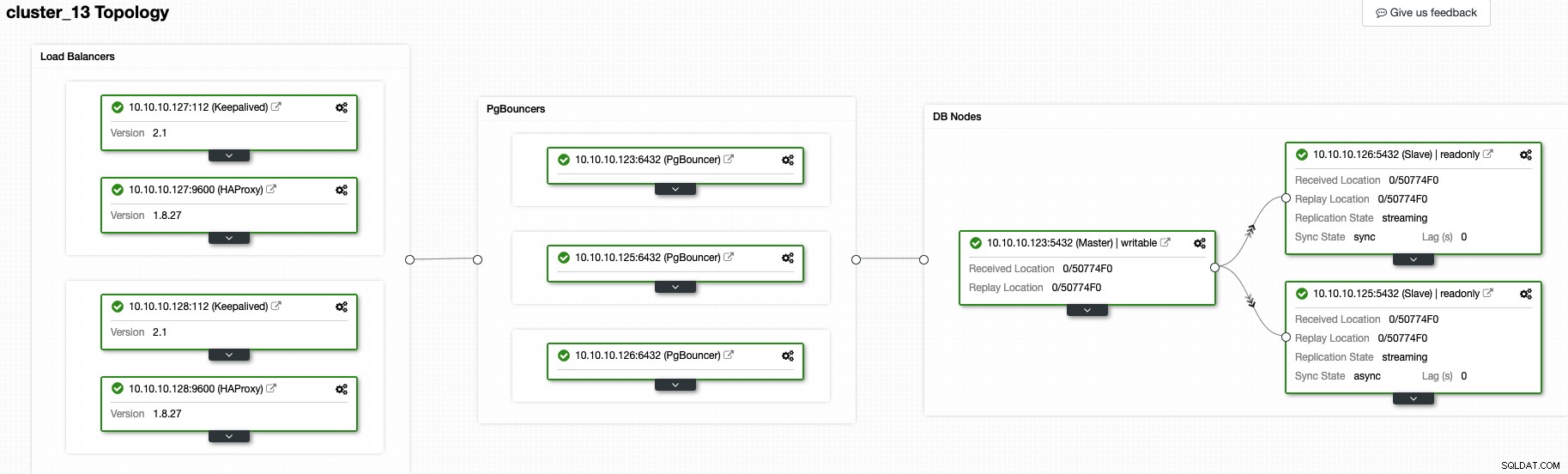
Och detta betyder:HAProxy + Keepalived -> PgBouncer -> PostgreSQL-databasnoder , det är en bra topologi för ditt PostgreSQL-kluster.
ClusterControl Autorecovery-funktion
I händelse av fel kommer ClusterControl att marknadsföra den mest avancerade standbynoden till primär samt meddela dig om problemet. Det misslyckas också över resten av standbynoden att replikera från den nya primära servern.
Som standard är HAProxy konfigurerad med två olika portar:läs-skriv och skrivskyddad. I läs- och skrivporten har du din primära databas (eller PgBouncer) nod som online och resten av noderna som offline, och i den skrivskyddade porten har du både den primära och standbynoden online.
När HAProxy upptäcker att en av dina noder inte är tillgänglig, markerar den automatiskt den som offline och tar inte hänsyn till den för att skicka trafik till den. Detektering görs av hälsokontrollskript som konfigureras av ClusterControl vid tidpunkten för distribution. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
När ClusterControl marknadsför en standby-nod, markerar HAProxy den gamla primära som offline för båda portarna och sätter den marknadsförda noden online i läs-skrivporten.
Om din aktiva HAProxy, som är tilldelad en virtuell IP-adress som dina system ansluter till, misslyckas, migrerar Keepalved denna IP-adress till din passiva HAProxy automatiskt. Det betyder att dina system sedan kan fortsätta att fungera normalt.
Slutsats
Som du kan se är det enkelt att ha en bra PostgreSQL-topologi om du använder ClusterControl och om du följer de grundläggande bästa praxiskoncepten för PostgreSQL-replikering. Naturligtvis beror den bästa miljön på arbetsbelastningen, hårdvaran, applikationen etc, men du kan använda den som ett exempel och flytta bitarna som du behöver.