Analyserar nyckelpopulationsfrågan lite mer
I del 3 av vår ODBC-spårningsserie kommer vi att ta ytterligare en inblick i Access-hanteringsnycklar för ODBC-länkade tabeller och hur den sorterar och grupperar SELECT-frågorna. I den föregående artikeln lärde vi oss hur en rekorduppsättning av dynaset-typ faktiskt är två separata frågor där den första frågan endast hämtar nycklarna till den ODBC-länkade tabellen som sedan används för att fylla i data. I den här artikeln kommer vi att studera lite mer om hur Access hanterar nycklarna och hur det sluter sig till vad som är nyckeln att använda för en ODBC-länkad tabell bland med konsekvenserna den har. Vi börjar med sorteringen.
Lägga till en sortering i frågan
Du såg i föregående artikel att vi började med en enkel SELECT utan någon särskild ordning. Du såg också hur Access först hämtade CityID och använd resultatet av den första frågan för att sedan fylla i de efterföljande frågorna för att ge användaren sken av att vara snabb när en stor postuppsättning öppnas. Om du någonsin har upplevt en situation där du lägger till en sortering eller gruppering i en fråga, går det plötsligt långsamt, kommer detta att förklara varför.
Låt oss lägga till en sortering på StateProvinceID i en Access-fråga:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Om vi nu spårar ODBC SQL bör vi se utdata:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Om du jämför med spåret från föregående artikel kan du se att de är desamma förutom den första frågan. Access placerar sorteringen i den första frågan där den använder för att hämta nycklarna. Det är vettigt eftersom genom att genomdriva sorteringen på nycklarna den använder för att gå igenom posterna, kommer Access garanterat att ha en en till en överensstämmelse mellan en posts ordinarie position och hur den ska sorteras. Den fyller sedan i posterna på exakt samma sätt. Den enda skillnaden är sekvensen av nycklar den använder för att fylla i de andra frågorna.
Låt oss överväga vad som händer när vi lägger till en GROUP BY genom att räkna på städerna per stat:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Spårning ska matas ut:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Du kanske också har märkt att frågan nu öppnas långsamt, och även om den kan vara inställd som en postuppsättning av dynasettyp, valde Access att ignorera detta och i princip behandla den som en postuppsättning av typen snapshot. Detta är vettigt eftersom frågan inte går att uppdatera och eftersom du inte riktigt kan navigera till en godtycklig position i en fråga som denna. Du måste alltså vänta tills alla rader har hämtats innan du kan bläddra fritt. StateProvinceID kan inte användas för att hitta en post eftersom det skulle finnas flera poster i Cities tabell. Även om jag använde en GROUP BY i det här exemplet behöver det inte vara en gruppering som gör att Access använder en postuppsättning av snapshottyp istället. Använder DISTINCT till exempel skulle ha samma effekt. En användbar tumregel för att förutsäga om Access kommer att använda postuppsättning av dynaset-typ är att fråga om en given rad i den resulterande postuppsättningen mappar tillbaka till exakt en rad i ODBC-datakällan. Om så inte är fallet kommer Access att använda ögonblicksbildbeteende även om frågan var tänkt att använda dynaset. Följaktligen, bara för att standarden är en postuppsättning av dynaset-typ, garanterar det inte att den faktiskt kommer att vara en postuppsättning av dynaset-typ. Det är bara en förfrågan , inte ett krav.
Bestämma nyckeln som ska användas för att välja
Du kanske har märkt i den tidigare spårade SQL-koden i både denna och tidigare artiklar, Access använde CityID som nyckeln. Den kolumnen hämtades i den första frågan och användes sedan i efterföljande förberedda frågor. Men hur vet Access vilken/vilka kolumner i en länkad tabell den borde använda? Den första böjelsen skulle vara att säga att den söker efter en primärnyckel och använder den. Det skulle dock vara felaktigt. Faktum är att Access-databasmotorn kommer att använda ODBC:s SQLStatistics funktion under länkningen eller återlänkningen av tabellen för att undersöka vilka index som finns tillgängliga. Denna funktion kommer att returnera en resultatuppsättning med en rad för varje kolumn som deltar i ett index för alla index. Denna resultatuppsättning är alltid sorterad och enligt konvention kommer den alltid att sortera klustrade index, hashade index och sedan andra indextyper. Inom varje indextyp kommer indexen att sorteras efter deras namn i alfabetisk ordning. Access-databasmotorn kommer att välja det första unika indexet den hittar även om det inte är den faktiska primärnyckeln. För att bevisa detta kommer vi att skapa en fånig tabell med några udda index:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Om vi sedan fyller i tabellen med en del data och länkar till den i Access och öppnar en databladsvy på den länkade tabellen kommer vi att se detta i spårad ODBC SQL. För korthetens skull ingår bara de två första kommandona.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Eftersom
OtherStuff deltar i ett klustrat index, det kom före den faktiska primärnyckeln och valdes därför av Access-databasmotorn för att användas i dynaset-typ recordset för att välja en enskild rad. Det är också trots att det unika klustrade indexets namn skulle ha kommit efter det primära indexets namn. En taktik för att tvinga Access-databasmotorn att välja ett visst index för en tabell skulle vara att ändra dess typ eller byta namn på namnet så att det sorteras alfabetiskt inom indextypens grupp. I fallet med SQL Server är primärnycklar vanligtvis klustrade, och det kan bara finnas ett klustrat index så det är en lycklig slump att det vanligtvis är rätt index för Access-databasmotorn att använda. Men om SQL Server-databasen innehåller tabeller med icke-klustrade primärnycklar och det finns ett klustrat unikt index som kanske inte är det optimala valet. I de fall det inte finns några klustrade index alls kan du påverka vilka unika index som används genom att namnge indexet så att det sorterar före andra index. Det kan vara till hjälp med annan RDBMS-programvara där det inte är praktiskt eller möjligt att skapa ett klustrat index för primärnyckeln. Index på åtkomstsidan för länkad SQL-vy eller tabell utan index
När du länkar till en SQL-vy eller en SQL-tabell som inte har några index eller primärnyckel definierade, kommer det inte att finnas några index tillgängliga för Access-databasmotorn att använda. Om du har använt länkad tabellhanterare för att länka en tabell eller en SQL-vy utan index kan du ha sett en dialogruta så här:
 Om vi väljer
Om vi väljer ID , slutför länkningen, öppna den länkade tabellen i designvyn och sedan indexdialogrutan, bör vi se detta:
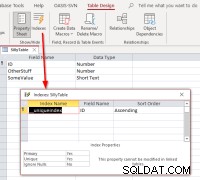 Den visar att tabellen har ett index som heter
Den visar att tabellen har ett index som heter __uniqueindex men det finns inte i den ursprungliga datakällan. Vad är det som händer? Svaret är att Access skapade en åtkomstsida index för dess användning för att hjälpa till att identifiera vilka som kan användas som postidentifierare för sådana tabeller eller vyer. Om du råkar länka om tabellerna programmässigt istället för att använda Linked Table Manager, kommer du att tycka att det är nödvändigt att replikera beteendet för att göra sådana länkade tabeller uppdateringsbara. Detta kan göras genom att köra ett Access SQL-kommando:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Du kan till exempel använda
CurrentDb.Execute för att köra Access SQL för att skapa indexet på den länkade tabellen. Du bör dock inte köra den som en genomkopplingsfråga eftersom indexet faktiskt inte skapas på servern. Det är bara för Accesss fördelar att tillåta uppdatering av den länkade tabellen. Det är värt att notera att Access endast tillåter exakt ett index för en sådan länkad tabell och endast om den inte redan har index. Icke desto mindre kan du se att användning av en SQL-vy kan vara ett önskvärt alternativ i fall där databasdesignen inte tillåter dig att använda klustrade index och du inte vill pilla med indexets namn för att övertala Access-databasmotorn att använda detta index, inte det indexet. Du kan uttryckligen kontrollera indexet och kolumnerna det ska inkludera när du länkar SQL-vyn.
Slutsatser
Från tidigare artikel såg vi att en rekorduppsättning av dynaset-typ vanligtvis ger 2 frågor. Den första frågan handlar vanligtvis om att fylla i Vi tittade närmare på hur Access hanterar populationen av nycklar som den kommer att använda för en dynaset-typ postuppsättning. Vi såg hur Access faktiskt kommer att konvertera all sortering från den ursprungliga Access-frågan och sedan använda den i nyckelpopulationsfrågan. Vi såg att ordningen av nyckelpopulationsfrågan direkt påverkar hur data i postuppsättningen kommer att sorteras och presenteras för användaren. Detta gör det möjligt för användaren att göra saker som att hoppa till en post som är obefintlig baserat på listans ordningsposition.
Vi såg då att gruppering och andra SQL-operationer som förhindrar en-en-mappning mellan den returnerade raden och den ursprungliga raden kommer att göra att Access behandlar Access-frågan som om den var en postuppsättning av snapshot-typ trots att den begärde en dynaset-typ postuppsättning.
Vi tittade sedan på hur Access bestämmer nyckeln som ska användas för att hantera uppdateringar med en ODBC-länkad tabell. Tvärtemot vad vi kan förvänta oss, kommer den inte nödvändigtvis att välja den primära nyckeln i tabellen utan snarare det första unika index som den hittar, beroende på typen av index och namnet på indexet. Vi diskuterade strategier för att säkerställa att Access kommer att välja rätt unika index. Vi tittade på SQL-vy som normalt inte har några index och diskuterade en metod för oss att informera Access om hur man nyckel en SQL-vy eller en tabell som inte har någon primärnyckel, vilket ger oss mer kontroll över hur Access kommer att hantera uppdateringarna för dessa ODBC länkade tabeller.
I nästa artikel kommer vi att titta på hur Access faktiskt utför uppdateringar av data när användare gör ändringar via Access-frågan eller postkällan.
Våra åtkomstexperter finns tillgängliga för att hjälpa dig. Ring oss på 773-809-5456 eller maila oss på sales@itimpact.com.