En av nyckelaspekterna med hög tillgänglighet är förmågan att snabbt reagera på fel. Det är inte ovanligt att manuellt hantera databaser och låta övervakningsprogramvara hålla ett öga på databasens hälsa. Vid fel skickar övervakningsmjukvaran en varning till jourhavande personal. Det betyder att någon potentiellt kan behöva vakna upp, komma till en dator och logga in i system och titta på loggar - det vill säga att det tar ganska lång tid innan saneringen kan påbörjas. Helst bör hela processen automatiseras.
I den här bloggen kommer vi att titta på hur man distribuerar ett helautomatiskt system som upptäcker när den primära databasen misslyckas och initierar failover-procedurer genom att främja en sekundär databas. Vi kommer att använda ClusterControl för att utföra automatisk failover av Moodle PostgreSQL-databasen.
Fördel med automatisk failover
- Mindre tid att återställa databastjänsten
- Högre systemupptid
- Mindre beroende av DBA eller administratör som ställer in hög tillgänglighet för databasen
Arkitektur
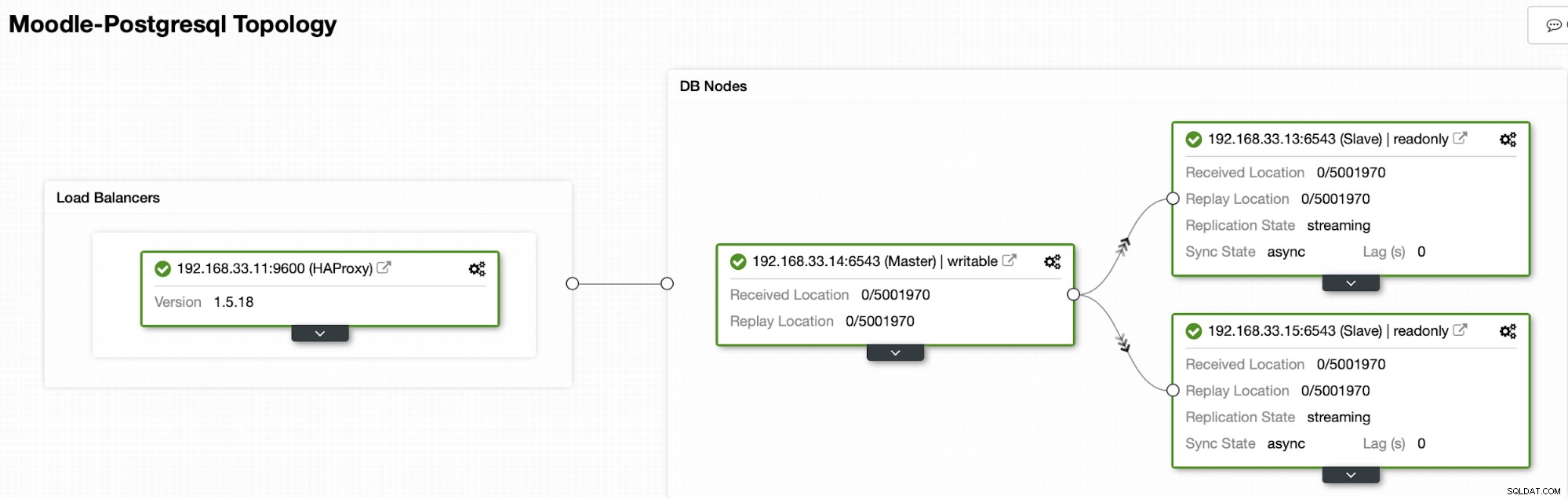
För närvarande har vi en Postgres primära server och två sekundära servrar under HAProxy load balancer som skickar Moodle-trafiken till den primära PostgreSQL-noden. Klusteråterställning och automatisk nodåterställning i ClusterControl är de viktiga inställningarna för att utföra den automatiska failover-processen.

Kontrollera vilken server som ska failover till
ClusterControl erbjuder vitlistning och svartlistning av en uppsättning servrar som du vill delta i failover, eller utesluta som en kandidat.
Det finns två variabler du kan ställa in i cmon-konfigurationen,
- replication_failover_whitelist :den innehåller en lista över IP:er eller värdnamn för sekundära servrar som bör användas som potentiella primära kandidater. Om denna variabel är inställd kommer endast dessa värdar att beaktas.
- replication_failover_blacklist :den innehåller en lista över värdar som aldrig kommer att betraktas som en primär kandidat. Du kan använda den för att lista sekundära servrar som används för säkerhetskopiering eller analytiska frågor. Om hårdvaran varierar mellan sekundära servrar, kanske du vill sätta här de servrar som använder långsammare hårdvara.
Automatisk failover-process
Steg 1
Vi har börjat ladda data på den primära servern (192.168.33.14) med hjälp av sysbench-verktyget.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Steg 2
Vi kommer att stoppa Postgres primära server (192.168.33.14). I ClusterControl är parametern (enable_cluster_autorecovery) aktiverad så att den kommer att främja nästa lämpliga primära.
# service postgresql-12 stopSteg 3
ClusterControl upptäcker fel i den primära och främjar en sekundär med de senaste uppgifterna som en ny primär. Det fungerar också på resten av de sekundära servrarna för att få dem att replikera från den nya primära.

I vårt fall är (192.168.33.13) en ny primär server och sekundära servrar replikerar nu från denna nya primära server. Nu dirigerar HAProxy databastrafiken från Moodle-servrarna till den senaste primära servern.
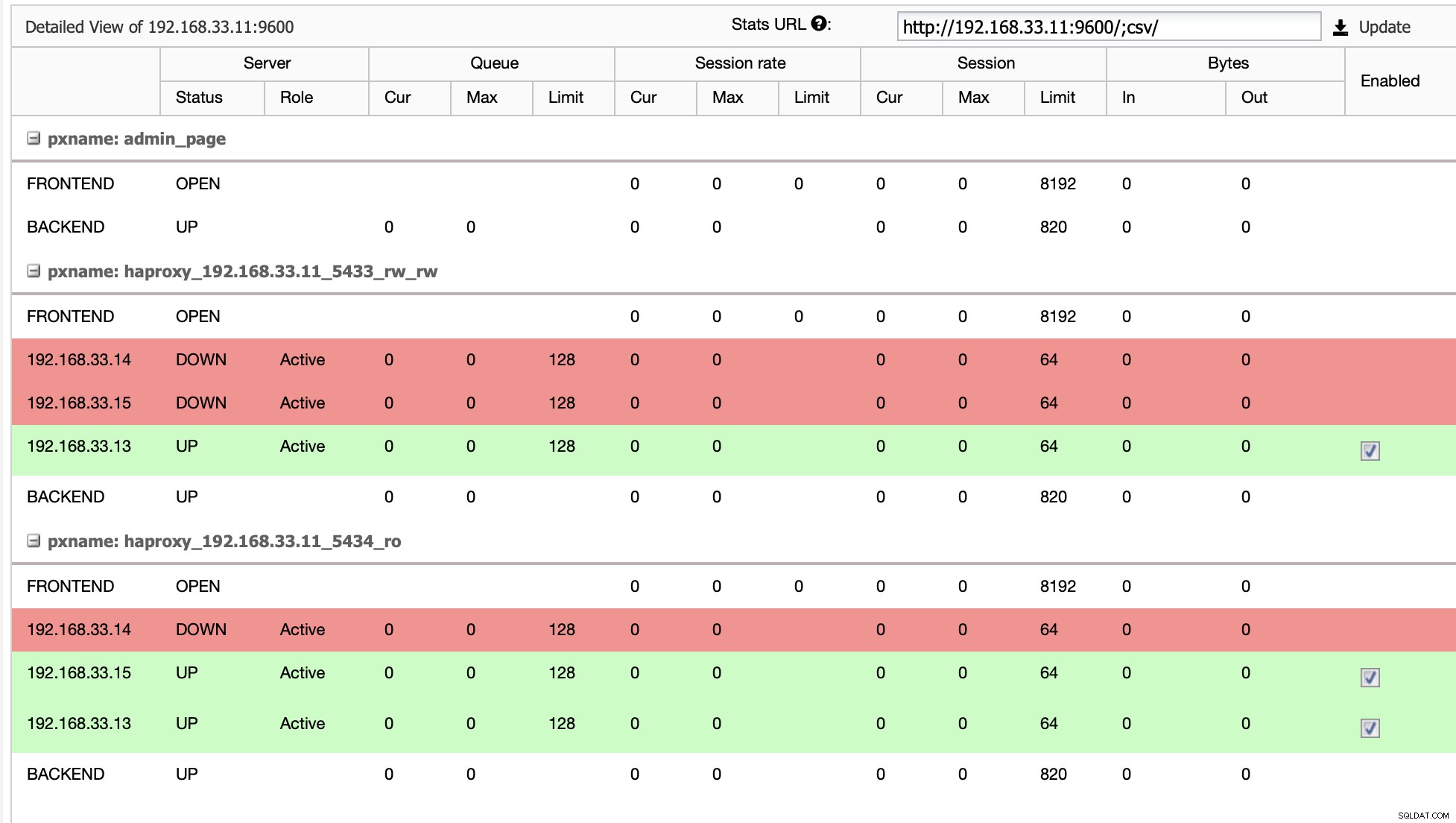
Från (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Från (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Aktuell topologi
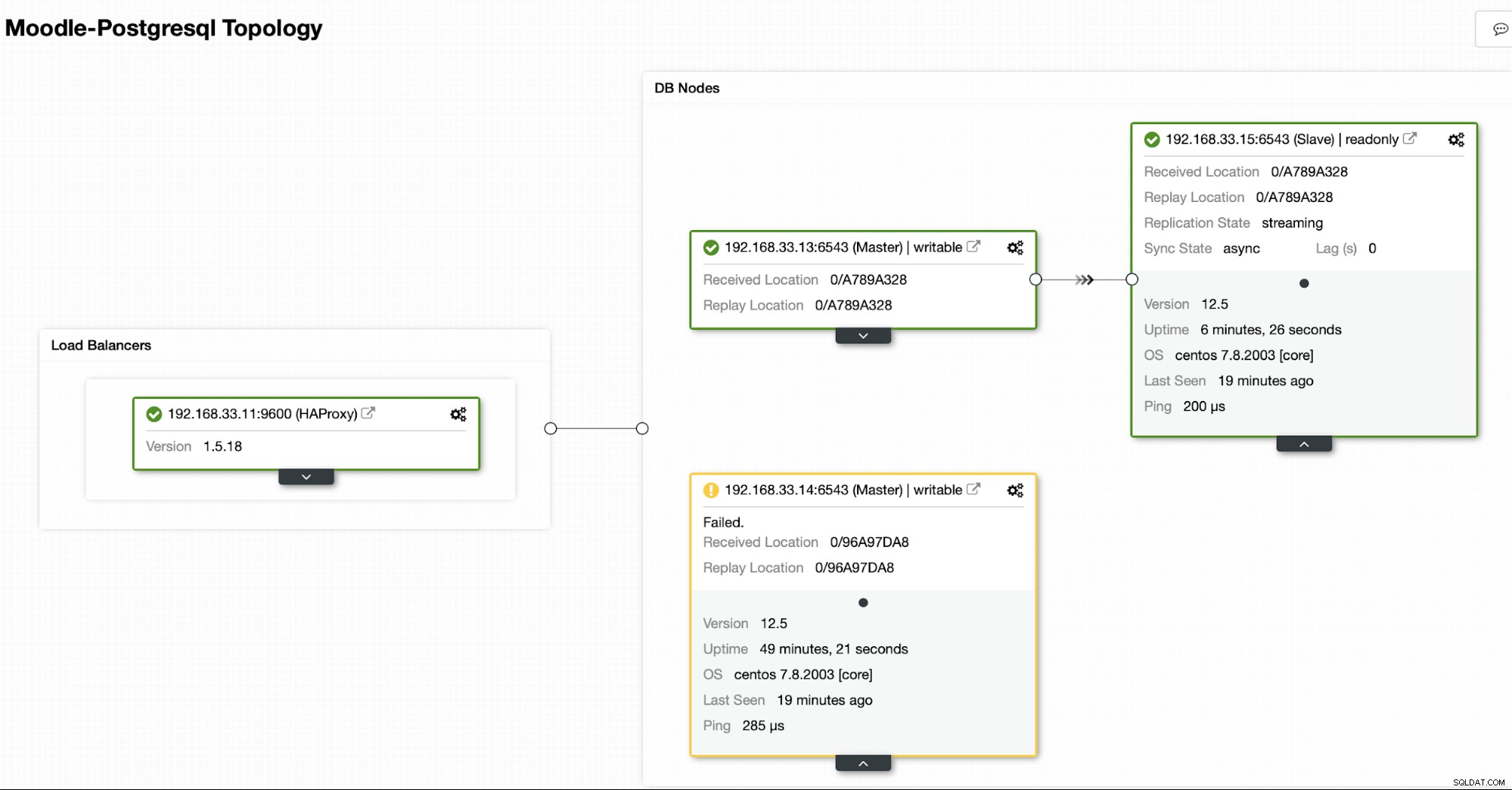
När HAProxy upptäcker att en av våra noder, antingen primär eller replik, är inte tillgänglig, den markerar den automatiskt som offline. HAProxy skickar ingen trafik från Moodle-appen till den. Denna kontroll görs av hälsokontrollskript som är konfigurerade av ClusterControl vid tidpunkten för distributionen.
När ClusterControl marknadsför en replikserver till primär, markerar vår HAProxy den gamla primära som offline och lägger den marknadsförda noden online.
När den gamla primära är online igen, synkroniseras den inte automatiskt till den nya primära servern. Vi måste släppa tillbaka det i topologin, och det kan göras via ClusterControl-gränssnittet. Detta kommer att undvika risken för dataförlust eller inkonsekvens, om vi vill undersöka varför den servern misslyckades i första hand.
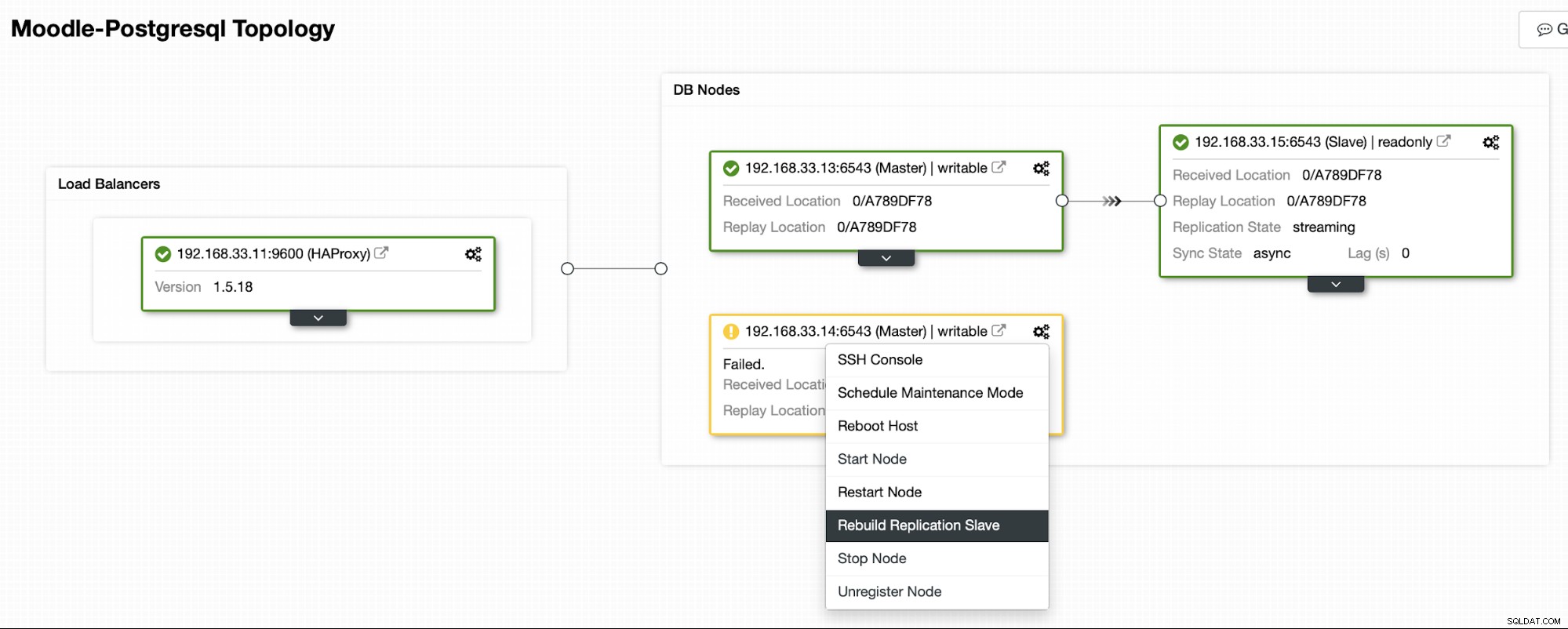
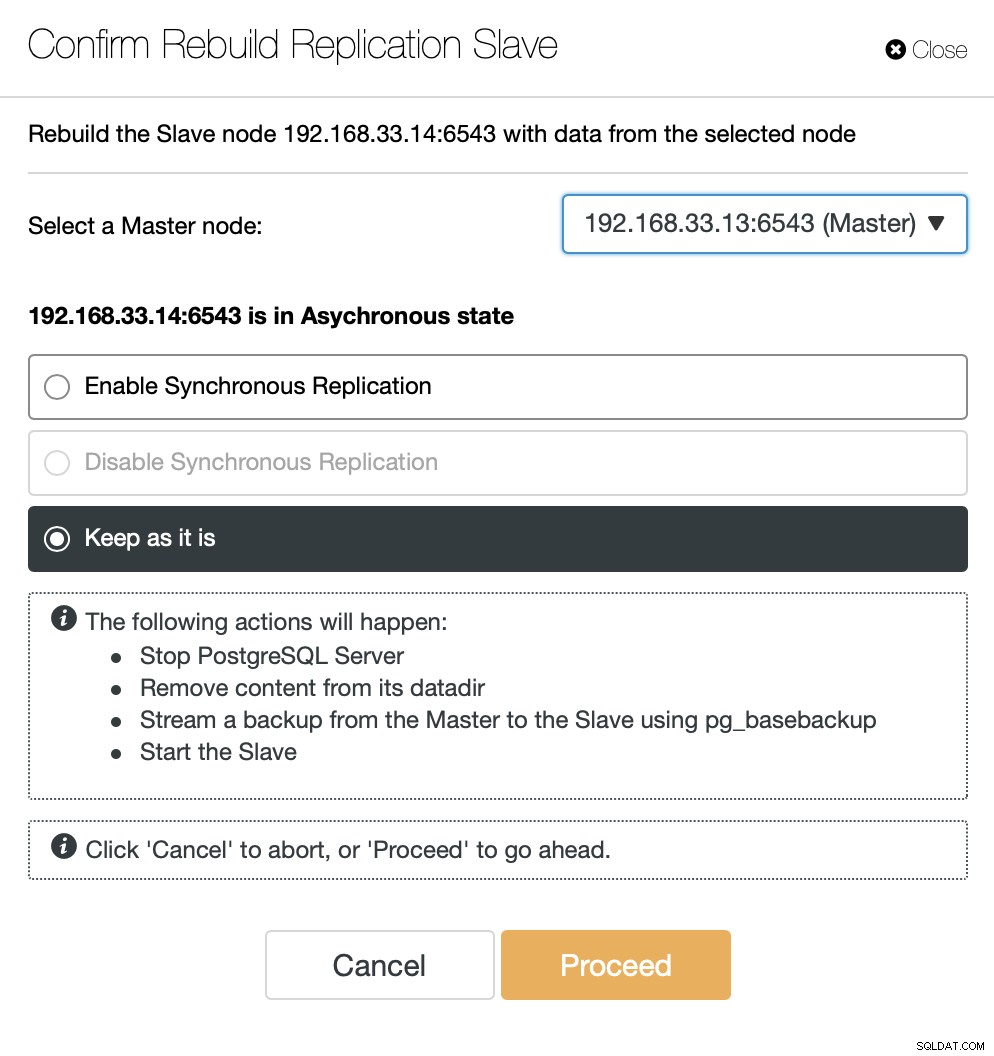
ClusterControl kommer att strömma säkerhetskopiering från den nya primära servern och konfigurera replikeringen.
Slutsats
Automatisk failover är en viktig del av alla Moodles produktionsdatabas. Det kan minska driftstopp när en server går ner, men också när man utför vanliga underhållsuppgifter eller migrering. Det är viktigt att få det rätt, eftersom det är viktigt för failover-mjukvaran att fatta rätt beslut.