Den här artikeln är den sjätte delen i en serie om tabelluttryck. Förra månaden i del 5 täckte jag den logiska behandlingen av icke-rekursiva CTE. Den här månaden täcker jag den logiska behandlingen av rekursiva CTE. Jag beskriver T-SQL:s stöd för rekursiva CTE:er, såväl som standardelement som ännu inte stöds av T-SQL. Jag tillhandahåller logiskt likvärdiga T-SQL-lösningar för de element som inte stöds.
Exempel på data
För exempeldata använder jag en tabell som heter Anställda, som innehåller en hierarki av anställda. Kolumnen empid representerar anställd-ID för den underordnade (den underordnade noden), och mgrid-kolumnen representerar chefens anställd-ID (föräldernoden). Använd följande kod för att skapa och fylla i tabellen Employees i tempdb-databasen:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary); Observera att roten till medarbetarhierarkin – VD:n – har en NULL i kolumnen mgrid. Alla övriga anställda har en chef, så deras mgrid-kolumn är inställd på anställd-ID för deras chef.
Figur 1 har en grafisk skildring av anställdshierarkin, som visar anställds namn, ID och dess plats i hierarkin.
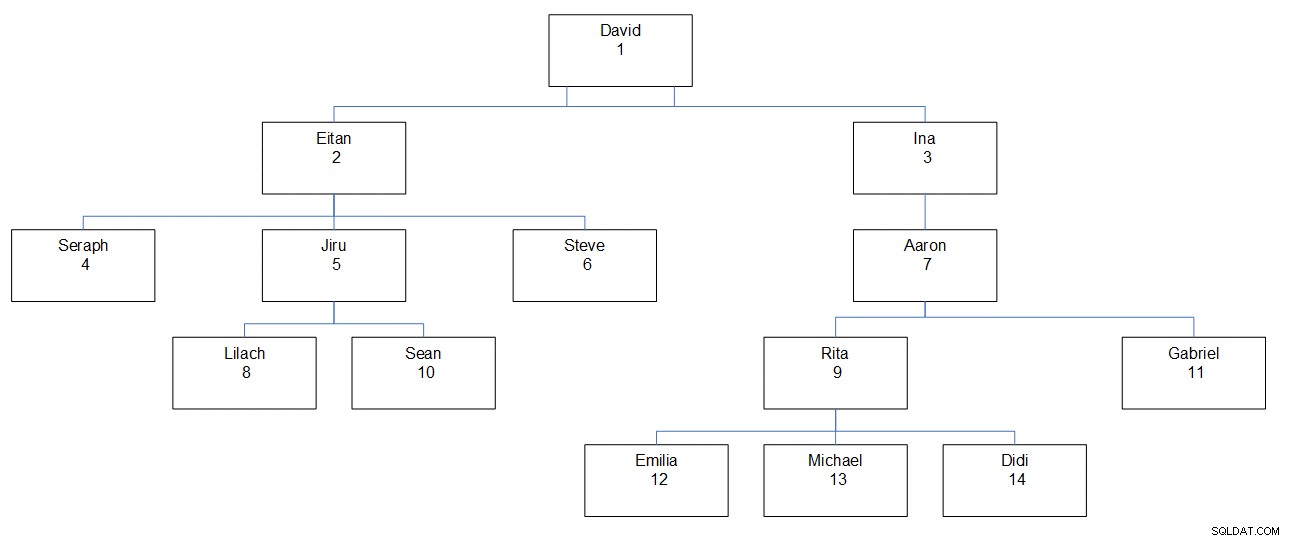 Figur 1:Anställdshierarki
Figur 1:Anställdshierarki
Rekursiva CTE
Rekursiva CTE har många användningsfall. En klassisk användningskategori har att göra med hantering av grafstrukturer, som vår medarbetarhierarki. Uppgifter som involverar grafer kräver ofta att man korsar vägar med godtyckliga längder. Till exempel, givet medarbetar-ID för någon chef, returnera den ingående anställde, såväl som alla underordnade till den ingående anställde på alla nivåer; d.v.s. direkta och indirekta underordnade. Om du hade en känd liten gräns för antalet nivåer som du kan behöva följa (graden på grafen), kan du använda en fråga med en koppling per nivå av underordnade. Men om graden av grafen är potentiellt hög blir det någon gång opraktiskt att skriva en fråga med många kopplingar. Ett annat alternativ är att använda imperativ iterativ kod, men sådana lösningar brukar vara långa. Det är här rekursiva CTE:er verkligen lyser – de gör att du kan använda deklarativa, koncisa och intuitiva lösningar.
Jag börjar med grunderna i rekursiva CTE innan jag kommer till de mer intressanta sakerna där jag täcker sökning och cykling.
Kom ihåg att syntaxen för en fråga mot en CTE är följande:
MEDAS
(
)
Här visar jag en CTE definierad med hjälp av WITH-satsen, men som du vet kan du definiera flera CTE:er separerade med kommatecken.
I vanliga, icke-rekursiva CTE:er baseras det inre tabelluttrycket på en fråga som endast utvärderas en gång. I rekursiva CTE:er baseras det inre tabelluttrycket på vanligtvis två frågor som kallas medlemmar , även om du kan ha fler än två för att hantera vissa speciella behov. Medlemmarna separeras vanligtvis av en UNION ALL-operatör för att indikera att deras resultat är enhetliga.
En medlem kan vara en ankarmedlem —vilket betyder att det bara utvärderas en gång; eller det kan vara en rekursiv medlem — vilket betyder att det utvärderas upprepade gånger, tills det returnerar en tom resultatuppsättning. Här är syntaxen för en fråga mot en rekursiv CTE som är baserad på en ankarmedlem och en rekursiv medlem:
MEDAS
(
UNION ALLA
)
Det som gör en medlem rekursiv är att ha en referens till CTE-namnet. Denna referens representerar den senaste exekveringens resultatuppsättning. I den första exekveringen av den rekursiva medlemmen representerar referensen till CTE-namnet ankarmedlemmens resultatuppsättning. I den N:e exekveringen, där N> 1, representerar referensen till CTE-namnet resultatuppsättningen av (N – 1) exekveringen av den rekursiva medlemmen. Som nämnts, när den rekursiva medlemmen returnerar en tom uppsättning, exekveras den inte igen. En hänvisning till CTE-namnet i den yttre frågan representerar de förenade resultatuppsättningarna av den enda exekveringen av ankarmedlemmen och alla exekveringen av den rekursiva medlemmen.
Följande kod implementerar den ovannämnda uppgiften att returnera underträdet av anställda för en given ingångshanterare, och skickar medarbetar-ID 3 som rotanställd i detta exempel:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Ankarfrågan exekveras endast en gång, och returnerar raden för den ingående rotanställda (anställd 3 i vårt fall).
Den rekursiva frågan förenar uppsättningen anställda från den tidigare nivån – representerad av referensen till CTE-namnet, alias som M för chefer – med deras direkta underordnade från tabellen Anställda, alias som S för underordnade. Join-predikatet är S.mgrid =M.empid, vilket betyder att den underordnades mgrid-värde är lika med chefens empid-värde. Den rekursiva frågan exekveras fyra gånger enligt följande:
- Returnera underordnade till anställd 3; output:anställd 7
- Returnera underordnade till anställd 7; output:anställda 9 och 11
- Returnera underordnade till anställda 9 och 11; utgång:12, 13 och 14
- Returnera underordnade till anställda 12, 13 och 14; output:tom set; rekursionen stannar
Referensen till CTE-namnet i den yttre frågan representerar de enhetliga resultaten av den enda exekveringen av ankarfrågan (anställd 3) med resultaten av alla exekveringar av den rekursiva frågan (anställda 7, 9, 11, 12, 13 och 14). Denna kod genererar följande utdata:
empid mgrid empname ------ ------ -------- 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi
Ett vanligt problem i programmeringslösningar är skenande kod som oändliga loopar som vanligtvis orsakas av en bugg. Med rekursiva CTE:er kan en bugg leda till att den rekursiva medlemmen körs på startbanan. Anta till exempel att du i vår lösning för att returnera underordnade till en ingående anställd hade en bugg i den rekursiva medlemmens join-predikat. Istället för att använda ON S.mgrid =M.empid, använde du ON S.mgrid =S.mgrid, så här:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C; Med tanke på minst en anställd med ett icke-null manager-ID som finns i tabellen, kommer exekveringen av den rekursiva medlemmen att fortsätta att returnera ett icke-tomt resultat. Kom ihåg att det implicita uppsägningsvillkoret för den rekursiva medlemmen är när dess exekvering returnerar en tom resultatuppsättning. Om den returnerar en icke-tom resultatuppsättning, kör SQL Server den igen. Du inser att om SQL Server inte hade en mekanism för att begränsa de rekursiva körningarna, skulle den bara fortsätta att köra den rekursiva medlemmen upprepade gånger för alltid. Som en säkerhetsåtgärd stöder T-SQL ett MAXRECURSION-frågealternativ som begränsar det maximalt tillåtna antalet exekveringar av den rekursiva medlemmen. Som standard är denna gräns inställd på 100, men du kan ändra den till valfritt icke-negativt SMALLINT-värde, där 0 representerar ingen gräns. Att sätta den maximala rekursionsgränsen till ett positivt värde N innebär att N + 1 försök att utföra den rekursiva medlemmen avbryts med ett fel. Att till exempel köra ovanstående buggykod som den är innebär att du litar på standardgränsen för max rekursion på 100, så 101-körningen av den rekursiva medlemmen misslyckas:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Level 16, State 1, Line 121
Utdraget avslutades. Den maximala rekursionen 100 har uttömts innan uttalandet slutförts.
Säg att i din organisation är det säkert att anta att medarbetarhierarkin inte kommer att överstiga 6 ledningsnivåer. Du kan minska den maximala rekursionsgränsen från 100 till ett mycket mindre antal, till exempel 10 för att vara på den säkra sidan, så här:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10); Om det nu finns en bugg som resulterar i en körning av den rekursiva medlemmen, kommer den att upptäckas vid 11 försök att köra den rekursiva medlemmen istället för vid 101 exekvering:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Level 16, State 1, Line 149
Utdraget avslutades. Den maximala rekursionen 10 har uttömts innan uttalandet slutförts.
Det är viktigt att notera att maxrekursionsgränsen främst bör användas som en säkerhetsåtgärd för att avbryta exekveringen av buggy runaway-kod. Kom ihåg att när gränsen överskrids avbryts exekveringen av koden med ett fel. Du bör inte använda det här alternativet för att begränsa antalet nivåer att besöka i filtreringssyfte. Du vill inte att ett fel ska genereras när det inte finns några problem med koden.
I filtreringssyfte kan du begränsa antalet nivåer som ska besökas programmatiskt. Du definierar en kolumn som heter lvl som spårar nivånumret för den nuvarande anställde jämfört med den ingående rotanställda. I ankarfrågan ställer du in lvl-kolumnen till konstanten 0. I den rekursiva frågan ställer du in den till chefens lvl-värde plus 1. För att filtrera så många nivåer under ingångsroten som @maxlevel, lägg till predikatet M.lvl <@ maxlevel till ON-satsen i den rekursiva frågan. Till exempel returnerar följande kod anställd 3 och två nivåer av underordnade till anställd 3:
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C; Den här frågan genererar följande utdata:
empid mgrid empname lvl ------ ------ -------- ---- 3 1 Ina 0 7 3 Aaron 1 9 7 Rita 2 11 7 Gabriel 2
Standard SEARCH och CYCLE satser
ISO/IEC SQL-standarden definierar två mycket kraftfulla alternativ för rekursiva CTE:er. En är en sats som kallas SEARCH som styr den rekursiva sökordningen, och en annan är en sats som heter CYCLE som identifierar cykler i de korsade banorna. Här är standardsyntaxen för de två satserna:
7.18Funktion
Ange genereringen av ordnings- och cykeldetekteringsinformation i resultatet av rekursiva frågeuttryck.
Format
AS
SÖK
DEPTH FIRST BY
CYKEL
STANDARD
I skrivande stund stöder inte T-SQL dessa alternativ, men i följande länkar kan du hitta förfrågningar om funktionsförbättringar som ber om att de ska inkluderas i T-SQL i framtiden och rösta på dem:
- Lägg till stöd för ISO/IEC SQL SEARCH-sats till rekursiva CTE:er i T-SQL
- Lägg till stöd för ISO/IEC SQL CYCLE-sats till rekursiva CTE:er i T-SQL
I följande avsnitt kommer jag att beskriva de två standardalternativen och även tillhandahålla logiskt likvärdiga alternativa lösningar som för närvarande är tillgängliga i T-SQL.
SÖK-sats
Standardsatsen SEARCH definierar den rekursiva sökordningen som BREADTH FIRST eller DEPTH FIRST med en eller flera specificerade ordningskolumner, och skapar en ny sekvenskolumn med ordningspositionerna för de besökta noderna. Du anger BREADTH FIRST för att söka först över varje nivå (bredd) och sedan nedåt i nivåerna (djup). Du anger DEPTH FIRST för att söka först ner (djup) och sedan tvärs över (bredd).
Du anger SEARCH-satsen precis före den yttre frågan.
Jag börjar med ett exempel för bredd första rekursiva sökordning. Kom bara ihåg att den här funktionen inte är tillgänglig i T-SQL, så du kommer inte att kunna köra de exempel som använder standardklausulerna i SQL Server eller Azure SQL Database. Följande kod returnerar underträdet för anställd 1, ber om en bredd första sökorder efter empid, skapar en sekvenskolumn som kallas seqbreadth med ordningspositionerna för de besökta noderna:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth; Här är den önskade utmatningen av denna kod:
empid mgrid empname seqbreadth ------ ------ -------- ----------- 1 NULL David 1 2 1 Eitan 2 3 1 Ina 3 4 2 Seraph 4 5 2 Jiru 5 6 2 Steve 6 7 3 Aaron 7 8 5 Lilach 8 9 7 Rita 9 10 5 Sean 10 11 7 Gabriel 11 12 9 Emilia 12 13 9 Michael 13 14 9 Didi 14
Bli inte förvirrad av det faktum att seqbreadth-värdena verkar vara identiska med empid-värdena. Det är bara en slump som ett resultat av det sätt som jag manuellt tilldelade empid-värdena i exempeldata som jag skapade.
Figur 2 har en grafisk skildring av anställdshierarkin, med en prickad linje som visar bredden i första ordningen i vilken noderna söktes. Empid-värdena visas precis under de anställdas namn, och de tilldelade seqbreadth-värdena visas i det nedre vänstra hörnet av varje ruta.
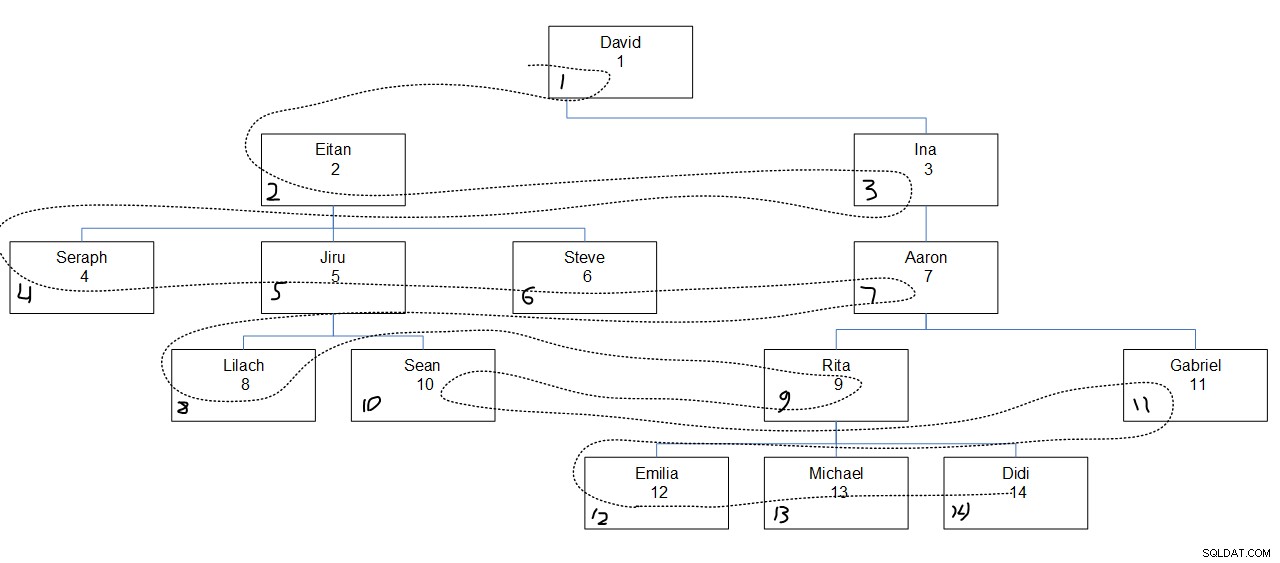 Figur 2:Sökbredden först
Figur 2:Sökbredden först
Vad som är intressant att notera här är att inom varje nivå söks noderna baserat på den specificerade kolumnordningen (empid i vårt fall) oavsett nodens moderförening. Lägg till exempel märke till att på den fjärde nivån nås Lilach först, Rita andra, Sean tredje och Gabriel sist. Det beror på att bland alla anställda på den fjärde nivån är det deras ordning baserat på deras empidvärden. Det är inte som att Lilach och Sean ska genomsökas i följd eftersom de är direkta underordnade till samma chef, Jiru.
Det är ganska enkelt att komma med en T-SQL-lösning som ger den logiska motsvarigheten till standardalternativet SAERCH DEPTH FIRST. Du skapar en kolumn som heter lvl som jag visade tidigare för att spåra nodens nivå med avseende på roten (0 för den första nivån, 1 för den andra, och så vidare). Sedan beräknar du den önskade resultatsekvenskolumnen i den yttre frågan med hjälp av en ROW_NUMBER-funktion. Som fönsterordning anger du först lvl och sedan önskad beställningskolumn (empid i vårt fall). Här är den fullständiga lösningens kod:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth; Låt oss sedan undersöka sökordern DEPTH FIRST. Enligt standarden ska följande kod returnera underträdet för anställd 1, fråga efter en djup första sökorder efter empid, skapa en sekvenskolumn som kallas seqdepth med ordningspositionerna för de sökta noderna:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth; Följande är den önskade utmatningen av denna kod:
empid mgrid empname seqdepth ------ ------ -------- --------- 1 NULL David 1 2 1 Eitan 2 4 2 Seraph 3 5 2 Jiru 4 8 5 Lilach 5 10 5 Sean 6 6 2 Steve 7 3 1 Ina 8 7 3 Aaron 9 9 7 Rita 10 12 9 Emilia 11 13 9 Michael 12 14 9 Didi 13 11 7 Gabriel 14
När man tittar på den önskade frågeutgången är det förmodligen svårt att ta reda på varför sekvensvärdena tilldelades som de var. Bild 3 borde hjälpa. Den har en grafisk skildring av de anställdas hierarki, med en prickad linje som reflekterar djupets första sökorder, med de tilldelade sekvensvärdena i det nedre vänstra hörnet av varje ruta.
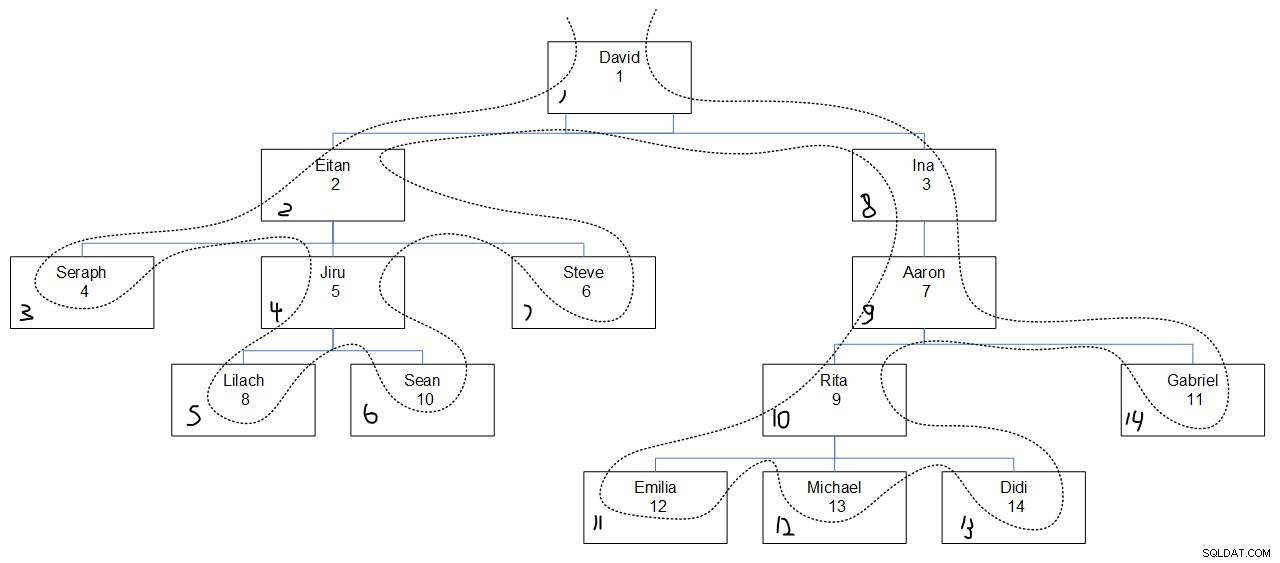 Figur 3:Sökdjup först
Figur 3:Sökdjup först
Att komma med en T-SQL-lösning som ger den logiska motsvarigheten till standardalternativet SEARCH DEPTH FIRST är lite knepigt, men ändå genomförbart. Jag kommer att beskriva lösningen i två steg.
I steg 1 beräknar du för varje nod en binär sorteringsväg som är gjord av ett segment per förfader till noden, där varje segment återspeglar sorteringspositionen för förfadern bland sina syskon. Du bygger den här vägen på samma sätt som du beräknar lvl-kolumnen. Det vill säga, börja med en tom binär sträng för rotnoden i ankarfrågan. Sedan, i den rekursiva frågan, sammanfogar du förälderns sökväg med nodens sorteringsposition bland syskon efter att du konverterat den till ett binärt segment. Du använder funktionen ROW_NUMBER för att beräkna positionen, partitionerad av föräldern (mgrid i vårt fall) och ordnad efter den relevanta ordningskolumnen (empid i vårt fall). Du konverterar radnumret till ett binärt värde av tillräcklig storlek beroende på det maximala antalet direkta barn som en förälder kan ha i din graf. BINARY(1) stöder upp till 255 barn per förälder, BINARY(2) stöder 65 535, BINARY(3):16 777 215, BINARY(4):4 294 967 295. I en rekursiv CTE måste motsvarande kolumner i ankaret och de rekursiva frågorna vara av samma typ och storlek , så se till att konvertera sorteringsvägen till ett binärt värde av samma storlek i båda.
Här är koden som implementerar steg 1 i vår lösning (förutsatt att BINARY(1) räcker per segment, vilket innebär att du inte har fler än 255 direkta underordnade per chef):
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C; Denna kod genererar följande utdata:
empid mgrid empname sortpath ------ ------ -------- ----------- 1 NULL David 0x 2 1 Eitan 0x01 3 1 Ina 0x02 7 3 Aaron 0x0201 9 7 Rita 0x020101 11 7 Gabriel 0x020102 12 9 Emilia 0x02010101 13 9 Michael 0x02010102 14 9 Didi 0x02010103 4 2 Seraph 0x0101 5 2 Jiru 0x0102 6 2 Steve 0x0103 8 5 Lilach 0x010201 10 5 Sean 0x010202
Observera att jag använde en tom binär sträng som sorteringsväg för rotnoden för det enda underträdet som vi frågar här. Om ankarmedlemmen potentiellt kan returnera flera underträdrötter, börja helt enkelt med ett segment som är baserat på en ROW_NUMBER-beräkning i ankarfrågan, på samma sätt som du beräknar den i den rekursiva frågan. I ett sådant fall blir din sorteringsväg ett segment längre.
Vad som återstår att göra i steg 2, är att skapa den önskade resultatets sek-djupskolumnen genom att beräkna radnummer som är sorterade efter sorteringsväg i den yttre frågan, som så
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth; Denna lösning är den logiska motsvarigheten till att använda standardalternativet SEARCH DEPTH FIRST som visats tidigare tillsammans med dess önskade utdata.
När du väl har en sekvenskolumn som återspeglar djupets första sökordning (seqdepth i vårt fall), med bara lite mer ansträngning kan du skapa en mycket snygg visuell skildring av hierarkin. Du kommer också att behöva den tidigare nämnda lvl-kolumnen. Du beställer den yttre frågan efter sekvenskolumnen. Du returnerar något attribut som du vill använda för att representera noden (säg, empname i vårt fall), med prefix av någon sträng (säg ' | ') replikerade lvl gånger. Här är den fullständiga koden för att uppnå en sådan visuell skildring:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth; Denna kod genererar följande utdata:
empid seqdepth emp ------ --------- -------------------- 1 1 David 2 2 | Eitan 4 3 | | Seraph 5 4 | | Jiru 8 5 | | | Lilach 10 6 | | | Sean 6 7 | | Steve 3 8 | Ina 7 9 | | Aaron 9 10 | | | Rita 12 11 | | | | Emilia 13 12 | | | | Michael 14 13 | | | | Didi 11 14 | | | Gabriel
Det är ganska coolt!
CYCLE-sats
Grafstrukturer kan ha cykler. Dessa cykler kan vara giltiga eller ogiltiga. Ett exempel på giltiga cykler är en graf som representerar motorvägar och vägar som förbinder städer och städer. Det är vad som kallas en cyklisk graf . Omvänt är det inte meningen att en graf som representerar en anställdshierarki som i vårt fall har cykler. Det är vad som kallas en acyklisk Graf. Anta dock att du på grund av någon felaktig uppdatering får en cykel oavsiktligt. Anta till exempel att du av misstag uppdaterar chefs-ID för VD (anställd 1) till anställd 14 genom att köra följande kod:
UPDATE Employees SET mgrid = 14 WHERE empid = 1;
Du har nu en ogiltig cykel i medarbetarhierarkin.
Oavsett om cykler är giltiga eller ogiltiga, när du korsar grafstrukturen, vill du verkligen inte fortsätta att följa en cyklisk väg upprepade gånger. I båda fallen vill du sluta följa en väg när en icke-första förekomst av samma nod hittas, och markera en sådan väg som cyklisk.
Så vad händer när du frågar en graf som har cykler med hjälp av en rekursiv fråga, utan någon mekanism på plats för att upptäcka dessa? Detta beror på genomförandet. I SQL Server kommer du någon gång att nå den maximala rekursionsgränsen och din fråga kommer att avbrytas. Om du till exempel antar att du körde ovanstående uppdatering som introducerade cykeln, prova att köra följande rekursiva fråga för att identifiera underträdet för anställd 1:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Eftersom den här koden inte anger en explicit maxrekursionsgräns, antas standardgränsen på 100. SQL Server avbryter exekveringen av denna kod innan den är klar och genererar ett fel:
empid mgrid empname ------ ------ -------- 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron ...Msg 530, Level 16, State 1, Line 432
Utdraget avslutades. Den maximala rekursionen 100 har uttömts innan uttalandet slutförts.
SQL-standarden definierar en sats som kallas CYCLE för rekursiva CTE:er, vilket gör att du kan hantera cykler i din graf. Du anger denna sats precis före den yttre frågan. Om en SEARCH-sats också finns anger du den först och sedan CYCLE-satsen. Här är syntaxen för CYCLE-satsen:
CYKLASTÄLL in
ANVÄNDER
Detekteringen av en cykel baseras på den specificerade cykelkolumnlistan . Till exempel, i vår medarbetarhierarki, skulle du förmodligen vilja använda empid-kolumnen för detta ändamål. När samma empidvärde visas för andra gången detekteras en cykel, och frågan följer inte en sådan väg längre. Du anger en ny cykelmarkeringskolumn som kommer att indikera om en cykel hittades eller inte, och dina egna värden som cykelmärket och icke-cykelmärke värden. De kan till exempel vara 1 och 0 eller "Ja" och "Nej", eller andra värden du väljer. I USING-satsen anger du ett nytt matriskolumnnamn som kommer att hålla sökvägen för noder som hittats hittills.
Så här skulle du hantera en förfrågan för underordnade till någon ingående rotanställd, med förmågan att detektera cykler baserat på empid-kolumnen, vilket indikerar 1 i cykelmarkeringskolumnen när en cykel detekteras, och 0 annars:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C; Här är den önskade utmatningen av denna kod:
empid mgrid empname cycle ------ ------ -------- ------ 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
T-SQL stöder för närvarande inte CYCLE-satsen, men det finns en lösning som ger en logisk motsvarighet. Det handlar om tre steg. Kom ihåg att du tidigare byggde en binär sorteringsväg för att hantera den rekursiva sökordningen. På liknande sätt, som det första steget i lösningen, bygger du en teckensträngsbaserad förfädersväg gjord av nod-ID:n (anställda-ID:n i vårt fall) för förfäderna som leder till den aktuella noden, inklusive den aktuella noden. Du vill ha separatorer mellan nod-ID:n, inklusive en i början och en i slutet.
Här är koden för att bygga en sådan förfäders väg:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C; Den här koden genererar följande utdata, som fortfarande följer cykliska vägar och avbryter därför innan den är klar när den maximala rekursionsgränsen har överskridits:
empid mgrid empname ancpath ------ ------ -------- ------------------- 1 14 David .1. 2 1 Eitan .1.2. 3 1 Ina .1.3. 7 3 Aaron .1.3.7. 9 7 Rita .1.3.7.9. 11 7 Gabriel .1.3.7.11. 12 9 Emilia .1.3.7.9.12. 13 9 Michael .1.3.7.9.13. 14 9 Didi .1.3.7.9.14. 1 14 David .1.3.7.9.14.1. 2 1 Eitan .1.3.7.9.14.1.2. 3 1 Ina .1.3.7.9.14.1.3. 7 3 Aaron .1.3.7.9.14.1.3.7. ...Msg 530, Level 16, State 1, Line 492
Utdraget avslutades. Den maximala rekursionen 100 har uttömts innan uttalandet slutförts.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C; This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle ------ ------ -------- ------------------- ------ 1 14 David .1. 0 2 1 Eitan .1.2. 0 3 1 Ina .1.3. 0 7 3 Aaron .1.3.7. 0 9 7 Rita .1.3.7.9. 0 11 7 Gabriel .1.3.7.11. 0 12 9 Emilia .1.3.7.9.12. 0 13 9 Michael .1.3.7.9.13. 0 14 9 Didi .1.3.7.9.14. 0 1 14 David .1.3.7.9.14.1. 1 2 1 Eitan .1.3.7.9.14.1.2. 0 3 1 Ina .1.3.7.9.14.1.3. 1 7 3 Aaron .1.3.7.9.14.1.3.7. 1 ...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C; This code runs to completion, and generates the following output:
empid mgrid empname cycle ------ ------ -------- ----------- 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid = NULL WHERE empid = 1;
Run the recursive query and you will find that there are no cycles present.
Slutsats
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.