Det finns flera metoder för att titta på dåligt presterande frågor i SQL Server, särskilt Query Store, Extended Events och dynamiska hanteringsvyer (DMV). Varje alternativ har för- och nackdelar. Extended Events tillhandahåller data om individuell exekvering av frågor, medan Query Store och DMV:s samlar prestandadata. För att kunna använda Query Store och Extended Events måste du konfigurera dem i förväg – antingen aktivera Query Store för din(a) databas(er), eller ställa in en XE-session och starta den. DMV-data är alltid tillgänglig, så väldigt ofta är det den enklaste metoden för att få en snabb första titt på frågeprestanda. Det är här Glenns DMV-frågor kommer väl till pass – i hans skript har han flera frågor som du kan använda för att hitta de bästa frågorna för instansen baserat på CPU, logisk I/O och varaktighet. Att rikta in sig på de mest resurskrävande frågorna är ofta en bra början vid felsökning, men vi kan inte glömma scenariot "död med tusen snitt" - frågan eller uppsättningen av frågor som körs MYCKET ofta - kanske hundratals eller tusentals gånger per minut. Glenn har en fråga i sitt set som listar de vanligaste frågorna för en databas baserat på antalet körningar, men enligt min erfarenhet ger den dig inte en fullständig bild av din arbetsbelastning.
Den huvudsakliga DMV som används för att titta på frågeprestandamått är sys.dm_exec_query_stats. Ytterligare data specifik för lagrade procedurer (sys.dm_exec_procedure_stats), funktioner (sys.dm_exec_function_stats) och triggers (sys.dm_exec_trigger_stats) är också tillgängliga, men överväg en arbetsbelastning som inte är enbart lagrade procedurer, funktioner och utlösare. Tänk på en blandad arbetsbelastning som har vissa ad hoc-frågor, eller kanske är helt ad hoc.
Exempelscenario
Genom att låna och anpassa kod från ett tidigare inlägg, Undersöka prestandaeffekten av en adhoc-arbetsbelastning, kommer vi först att skapa två lagrade procedurer. Den första, dbo.RandomSelects, genererar och exekverar en ad hoc-sats, och den andra, dbo.SPRandomSelects, genererar och exekverar en parametriserad fråga.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Nu kommer vi att köra båda lagrade procedurerna 1000 gånger, med samma metod som beskrivs i mitt tidigare inlägg med .cmd-filer som anropar .sql-filer med följande uttalanden:
Adhoc.sql-filinnehåll:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Parameterized.sql-filinnehåll:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Exempelsyntax i .cmd-fil som anropar .sql-filen:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Om vi använder en variant av Glenns Top Worker Time-fråga för att titta på de vanligaste frågorna baserat på worker time (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
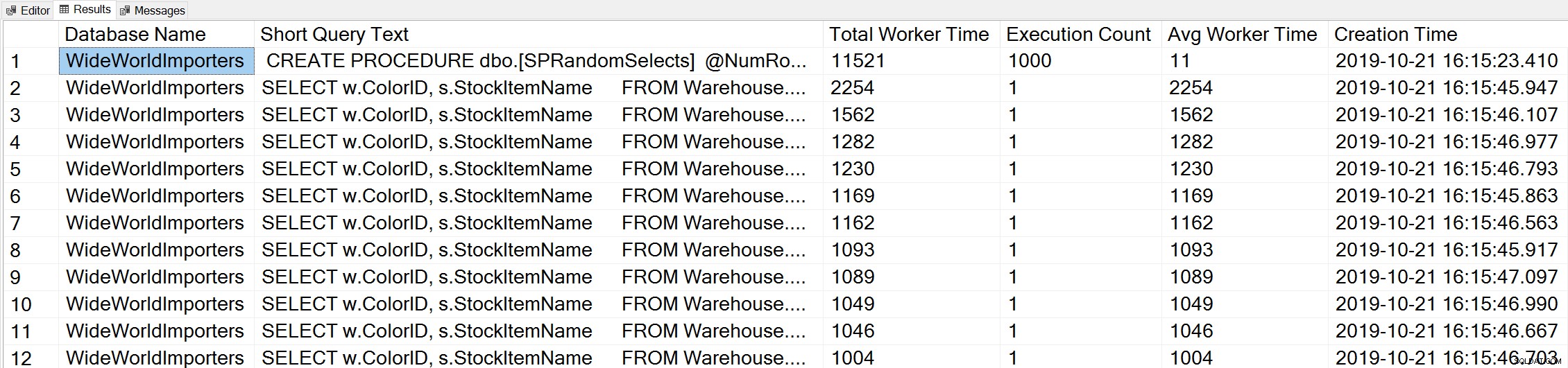
Vi ser uttalandet från vår lagrade procedur som den fråga som körs med den högsta mängden kumulativ CPU.
Om vi kör en variant av Glenns Query Execution Counts-fråga mot WideWorldImporters-databasen:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
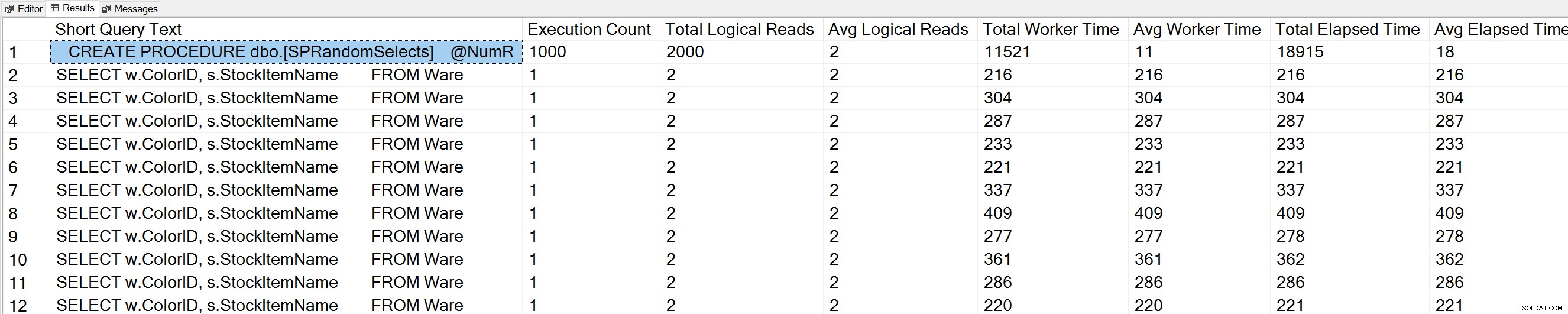
Vi ser också vår lagrade procedursats överst på listan.
Men ad hoc-frågan som vi körde, även om den har olika bokstavliga värden, var i huvudsak samma satsen körs upprepade gånger, som vi kan se genom att titta på query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
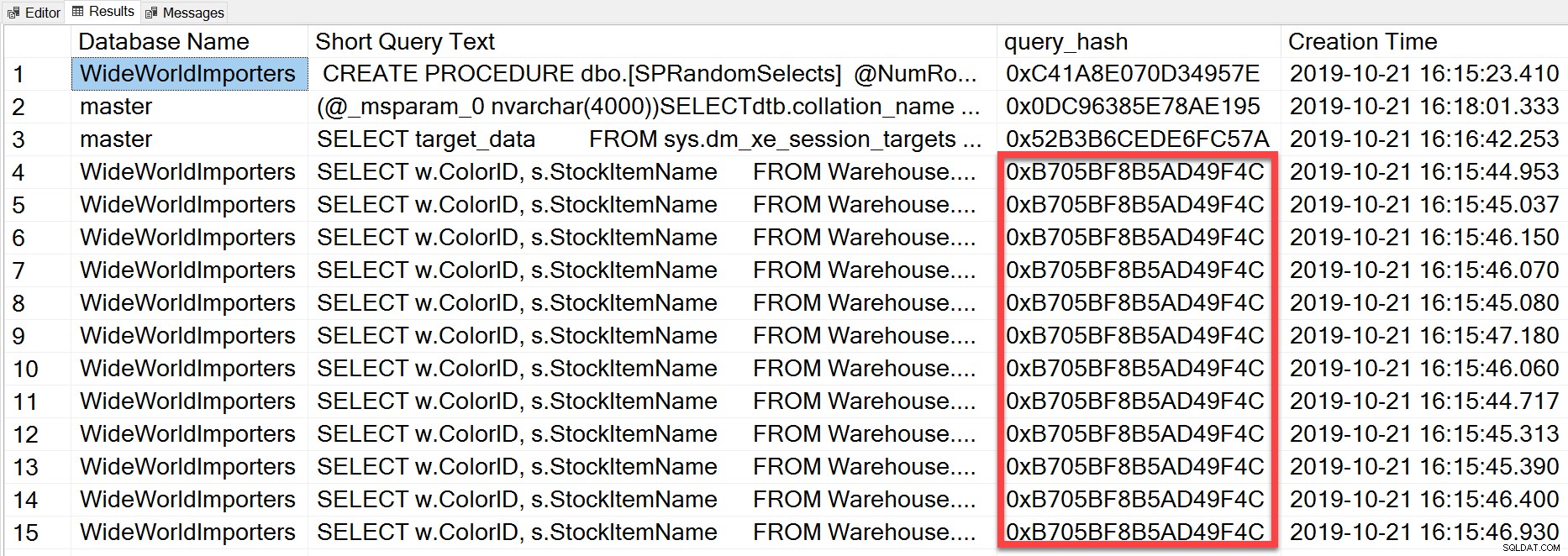
query_hash lades till i SQL Server 2008 och är baserat på trädet för de logiska operatorerna som genereras av Query Optimizer för satstexten. Frågor som har en liknande satstext som genererar samma träd av logiska operatorer kommer att ha samma query_hash, även om de bokstavliga värdena i frågepredikatet är olika. Även om de bokstavliga värdena kan vara olika, måste objekten och deras alias vara desamma, liksom frågetips och eventuellt SET-alternativen. Den lagrade proceduren RandomSelects genererar frågor med olika bokstavliga värden:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Men varje exekvering har exakt samma värde för query_hash, 0xB705BF8B5AD49F4C. För att förstå hur ofta en ad hoc-fråga – och de som är desamma när det gäller query_hash – körs, måste vi gruppera efter query_hash-ordningen på det antalet, snarare än att titta på execution_count i sys.dm_exec_query_stats (som ofta visar en värde på 1).
Om vi ändrar kontext till WideWorldImporters-databasen och letar efter toppfrågor baserat på antal körningar, där vi grupperar på query_hash, kan vi nu se både den lagrade proceduren och vår ad hoc-fråga:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Obs:sys.dm_exec_function_stats DMV lades till i SQL Server 2016. Att köra den här frågan på SQL Server 2014 och tidigare kräver att referensen till denna DMV tas bort.
Denna utdata ger en mycket mer omfattande förståelse av vilka frågor som verkligen körs oftast, eftersom den aggregeras baserat på query_hash, inte genom att bara titta på execution_count i sys.dm_exec_query_stats, som kan ha flera poster för samma query_hash när olika bokstavliga värden är Begagnade. Frågeutgången inkluderar också query_plan_hash, som kan vara annorlunda för frågor med samma query_hash. Denna ytterligare information är användbar när du utvärderar planprestanda för en fråga. I exemplet ovan har varje fråga samma query_plan_hash, 0x299275DD475C4B17, vilket visar att även med olika ingångsvärden genererar Query Optimizer samma plan – den är stabil. När flera query_plan_hash-värden finns för samma query_hash, existerar planvariabilitet. I ett scenario där samma fråga, baserat på query_hash, körs tusentals gånger, är en allmän rekommendation att parametrisera frågan. Om du kan verifiera att det inte finns någon planvariabilitet, tar parametrering av frågan bort optimerings- och kompileringstiden för varje exekvering och kan minska den totala CPU:n. I vissa scenarier kan parametrering av fem till tio ad hoc-frågor förbättra systemets prestanda som helhet.
Sammanfattning
För alla miljöer är det viktigt att förstå vilka frågor som är dyrast när det gäller resursanvändning och vilka frågor som körs oftast. Samma uppsättning frågor kan dyka upp för båda typerna av analys när du använder Glenns DMV-skript, vilket kan vara missvisande. Som sådan är det viktigt att fastställa om arbetsbelastningen mestadels är procedurmässig, mestadels ad hoc eller en mix. Även om det finns mycket dokumenterat om fördelarna med lagrade procedurer, tycker jag att blandade eller mycket ad hoc-arbetsbelastningar är mycket vanliga, särskilt med lösningar som använder objektrelationsmappare (ORM) som Entity Framework, NHibernate och LINQ till SQL. Om du är osäker på typen av arbetsbelastning för en server är det en bra början att köra ovanstående fråga för att titta på de mest körda frågorna baserade på en query_hash. När du börjar förstå arbetsbelastningen och vad som finns för både tunga och döda med tusentals nedskärningar, kan du gå vidare till att verkligen förstå resursanvändningen och vilken inverkan dessa frågor har på systemets prestanda, och rikta dina ansträngningar för att trimma.