NULL-hantering är en av de svårare aspekterna av datamodellering och datamanipulation med SQL. Låt oss börja med att ett försök att förklara exakt vad en NULL är är inte trivialt i och för sig. Även bland personer som har bra koll på relationsteori och SQL kommer du att höra mycket starka åsikter både för och emot att använda NULLs i din databas. Gilla dem eller inte, som databasutövare måste du ofta ta itu med dem, och med tanke på att NULL lägger till komplexitet till din SQL-kodskrivning, är det en bra idé att göra det till en prioritet att förstå dem väl. På så sätt kan du undvika onödiga buggar och fallgropar.
Den här artikeln är den första i en serie om NULL-komplexitet. Jag börjar med täckning av vad NULL är och hur de beter sig i jämförelser. Jag täcker sedan in NULL behandlingsinkonsekvenser i olika språkelement. Slutligen tar jag upp saknade standardfunktioner relaterade till NULL-hantering i T-SQL och föreslår alternativ som är tillgängliga i T-SQL.
Det mesta av täckningen är relevant för alla plattformar som implementerar en dialekt av SQL, men i vissa fall nämner jag aspekter som är specifika för T-SQL.
I mina exempel kommer jag att använda en exempeldatabas som heter TSQLV5. Du kan hitta skriptet som skapar och fyller denna databas här, och dess ER-diagram här.
NULL som markör för ett saknat värde
Låt oss börja med att förstå vad NULL är. I SQL är en NULL en markör, eller en platshållare, för ett saknat värde. Det är SQLs försök att representera i din databas en verklighet där ett visst attributvärde ibland finns och ibland saknas. Anta till exempel att du behöver lagra personaldata i en tabell för anställda. Du har attribut för förnamn, mellannamn och efternamn. Attributen förnamn och efternamn är obligatoriska, och därför definierar du dem som att de inte tillåter NULL. Attributet mellannamn är valfritt, och därför definierar du det som att tillåta NULL.
Om du undrar vad relationsmodellen har att säga om saknade värden, så trodde modellens skapare Edgar F. Codd på dem. Faktum är att han till och med gjorde en skillnad mellan två typer av saknade värden:Missing But Applicable (A-Values markör) och Missing But Inapplicable (I-Values markör). Om vi tar attributet mellannamn som exempel, i ett fall där en anställd har ett mellannamn, men av integritetsskäl väljer att inte dela informationen, skulle du använda A-Values-markören. I ett fall där en anställd inte har ett mellannamn alls skulle du använda I-Values-markören. Här kan samma attribut ibland vara relevant och närvarande, ibland Saknas men tillämplig och ibland Saknas men inte tillämplig. Andra fall skulle kunna vara tydligare och stödja endast en typ av saknade värden. Anta till exempel att du har en ordertabell med ett attribut som kallas shippeddate som innehåller beställningens leveransdatum. En beställning som har skickats kommer alltid att ha ett aktuellt och relevant leveransdatum. Det enda fallet för att inte ha ett känt leveransdatum skulle vara för beställningar som inte har skickats ännu. Så här måste antingen ett relevant shippeddate-värde finnas eller så ska I-Values-markören användas.
Utformarna av SQL valde att inte gå in på skillnaden mellan tillämpliga och otillämpliga saknade värden, och försåg oss med NULL som en markör för alla typer av saknade värden. För det mesta var SQL designad för att anta att NULLs representerar den typ av saknat värde som saknas men tillämpligt. Följaktligen, särskilt när din användning av NULL är som en platshållare för ett otillämpligt värde, kanske standard SQL NULL-hantering inte är den som du uppfattar som korrekt. Ibland måste du lägga till explicit NULL-hanteringslogik för att få den behandling som du anser vara den rätta för dig.
Som en bästa praxis, om du vet att ett attribut inte är tänkt att tillåta NULL, se till att du upprätthåller det med en NOT NULL-begränsning som en del av kolumndefinitionen. Det finns ett par viktiga skäl till detta. En anledning är att om du inte upprätthåller detta, vid ett eller annat tillfälle, kommer NULLs dit. Det kan vara resultatet av en bugg i programmet eller import av dålig data. Genom att använda en begränsning vet du att NULLs aldrig kommer att nå bordet. En annan anledning är att optimeraren utvärderar begränsningar som NOT NULL för bättre optimering, för att undvika onödigt arbete med att leta efter NULL och för att möjliggöra vissa transformationsregler.
Jämförelser som involverar NULL
Det finns en del knepigheter i SQL:s utvärdering av predikat när NULLs är inblandade. Jag kommer först att täcka jämförelser som involverar konstanter. Senare kommer jag att ta upp jämförelser som involverar variabler, parametrar och kolumner.
När du använder predikat som jämför operander i frågeelement som WHERE, ON och HAVING, beror de möjliga resultaten av jämförelsen på om någon av operanderna kan vara en NULL. Om du med säkerhet vet att ingen av operanderna kan vara en NULL, kommer predikatets utfall alltid att vara antingen SANT eller FALSKT. Detta är vad som kallas den tvåvärdiga predikatlogiken, eller kort och gott, helt enkelt tvåvärdig logik. Detta är till exempel fallet när du jämför en kolumn som är definierad som att den inte tillåter NULLs med någon annan icke-NULL-operand.
Om någon av operanderna i jämförelsen kan vara en NULL, t.ex. en kolumn som tillåter NULLs, med hjälp av operatorer för både likhet (=) och olikhet (<>,>, <,>=, <=, etc.), är du nu utlämnad till trevärdig predikatslogik. Om de två operanderna i en given jämförelse råkar vara icke-NULL-värden, får du fortfarande antingen TRUE eller FALSE som resultat. Men om någon av operanderna är NULL får du ett tredje logiskt värde som heter UNKNOWN. Observera att det är fallet även när man jämför två NULLs. Behandlingen av TRUE och FALSE av de flesta delar av SQL är ganska intuitiv. Behandlingen av OKÄND är inte alltid så intuitiv. Dessutom hanterar olika delar av SQL det OKÄNDA fallet på olika sätt, vilket jag kommer att förklara i detalj senare i artikeln under "NOLL behandlingsinkonsekvenser."
Anta som ett exempel att du behöver fråga tabellen Sales.Orders i TSQLV5-exempeldatabasen och returnera beställningar som skickades den 2 januari 2019. Du använder följande fråga:
ANVÄND TSQLV5; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate ='20190102';
Det är tydligt att filterpredikatet utvärderas till TRUE för rader där leveransdatumet är 2 januari 2019, och att dessa rader bör returneras. Det är också tydligt att predikatet utvärderas till FALSK för rader där leveransdatumet finns, men inte är den 2 januari 2019, och att dessa rader bör kasseras. Men hur är det med rader med NULL-leveransdatum? Kom ihåg att både likhetsbaserade predikat och ojämlikhetsbaserade predikat returnerar OKÄND om någon av operanderna är NULL. WHERE-filtret är utformat för att kassera sådana rader. Du måste komma ihåg att WHERE-filtret returnerar rader för vilka filterpredikatet utvärderas till TRUE, och förkastar rader för vilka predikatet utvärderas till FALSE eller OKÄNT.
Den här frågan genererar följande utdata:
orderid shippeddate------------ -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Anta att du behöver returnera beställningar som inte skickades den 2 januari 2019. För dig är det tänkt att beställningar som ännu inte har skickats inkluderas i utdata. Du använder en fråga som liknar den förra och negerar bara predikatet, som så:
VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate ='20190102');
Den här frågan returnerar följande utdata:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(806 rader påverkade)
Utdata exkluderar naturligtvis raderna med leveransdatum 2 januari 2019, men exkluderar också rader med NULL leveransdatum. Vad som kan vara kontraintuitivt här är vad som händer när du använder NOT-operatorn för att negera ett predikat som utvärderas till OKÄNT. Uppenbarligen är INTE SANT FALSKT och INTE SANT är SANT. EJ OKÄNT förblir dock OKÄNT. SQLs logik bakom denna design är att om du inte vet om en proposition är sann, så vet du inte heller om propositionen inte är sann. Detta innebär att när du använder likhets- och olikhetsoperatorer i filterpredikatet, returnerar varken de positiva eller de negativa formerna av predikatet raderna med NULL.
Det här exemplet är ganska enkelt. Det finns knepigare fall med delfrågor. Det finns ett vanligt fel när du använder NOT IN-predikatet med en underfråga, när underfrågan returnerar en NULL bland de returnerade värdena. Frågan returnerar alltid ett tomt resultat. Anledningen är att den positiva formen av predikatet (IN-delen) returnerar ett TRUE när det yttre värdet hittas, och OKÄNT när det inte hittas på grund av jämförelsen med NULL. Då returnerar negationen av predikatet med NOT-operatorn alltid FALSKT respektive OKÄNT - aldrig ett SANT. Jag täcker denna bugg i detalj i T-SQL-buggar, fallgropar och bästa praxis – delfrågor, inklusive föreslagna lösningar, optimeringsöverväganden och bästa praxis. Om du inte redan är bekant med denna klassiska bugg, se till att du kollar den här artikeln eftersom buggen är ganska vanlig och det finns enkla åtgärder du kan vidta för att undvika det.
Tillbaka till vårt behov, vad sägs om att försöka returnera beställningar med ett leveransdatum som är annorlunda än 2 januari 2019, med hjälp av en annan än (<>) operatör:
VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102';
Tyvärr ger både likhets- och ojämlikhetsoperatorerna OKÄNDA när någon av operanderna är NULL, så den här frågan genererar följande utdata som den föregående frågan, exklusive NULL:erna:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(806 rader påverkade)
För att isolera frågan om jämförelser med NULL-värden som ger OKÄNDA genom att använda likhet, olikhet och negation av de två typerna av operatorer, returnerar alla följande frågor en tom resultatuppsättning:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =NULL; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate =NULL); VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> NULL; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate <> NULL);
Enligt SQL ska du inte kontrollera om något är lika med en NULL eller annorlunda än en NULL, snarare om något är en NULL eller inte är en NULL, med hjälp av specialoperatorerna IS NULL respektive IS NOT NULL. Dessa operatorer använder logik med två värden och returnerar alltid antingen TRUE eller FALSE. Använd till exempel IS NULL-operatören för att returnera olevererade beställningar, som så:
VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NULL;
Den här frågan genererar följande utdata:
orderid shippeddate----------- -----------11008 NULL11019 NULL11039 NULL...(21 rader påverkade)
Använd IS NOT NULL-operatören för att returnera skickade beställningar, som så:
VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NOT NULL;
Den här frågan genererar följande utdata:
orderid shippeddate------------ -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(809 rader påverkade)
Använd följande kod för att returnera beställningar som har skickats på ett annat datum än 2 januari 2019, samt ej skickade beställningar:
VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102' ELLER shippeddate IS NULL;
Den här frågan genererar följande utdata:
orderid shippeddate------------ -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110250 2017-07-12 ...11050 2019-05-0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(827 rader påverkade)
I en senare del av serien tar jag upp standardfunktioner för NULL-behandling som för närvarande saknas i T-SQL, inklusive DISTINCT-predikatet , som har potential att förenkla NULL-hanteringen en hel del.
Jämförelser med variabler, parametrar och kolumner
Föregående avsnitt fokuserade på predikat som jämför en kolumn med en konstant. I verkligheten kommer du dock oftast att jämföra en kolumn med variabler/parametrar eller med andra kolumner. Sådana jämförelser innebär ytterligare komplexitet.
Ur en NULL-hanteringssynpunkt behandlas variabler och parametrar på samma sätt. Jag kommer att använda variabler i mina exempel, men de punkter jag gör om deras hantering är lika relevanta för parametrar.
Tänk på följande grundläggande fråga (jag kallar det fråga 1), som filtrerar beställningar som skickades ett visst datum:
DECLARE @dt AS DATE ='20190212'; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Jag använder en variabel i det här exemplet och initierar den med ett exempeldatum, men det här kunde lika gärna ha varit en parameteriserad fråga i en lagrad procedur eller en användardefinierad funktion.
Den här frågans körning genererar följande utdata:
orderid shippeddate------------ -----------10865 2019-02-1210866 2019-02-1210876 2019-02-1210878 2019-02-1210879 2019- 02-12
Planen för fråga 1 visas i figur 1.
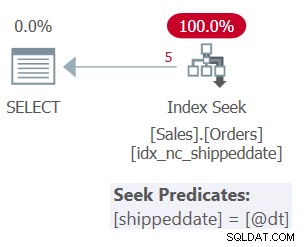 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Tabellen har ett täckande index för att stödja denna fråga. Indexet kallas idx_nc_shippeddate, och det definieras med nyckellistan (shippeddate, orderid). Frågans filterpredikat uttrycks som ett sökargument (SARG) , vilket betyder att det gör det möjligt för optimeraren att överväga att tillämpa en sökoperation i det stödjande indexet och gå direkt till intervallet av kvalificerade rader. Det som gör filterpredikatet SARGable är att det använder en operator som representerar ett på varandra följande intervall av kvalificerade rader i indexet, och att det inte tillämpar manipulation på den filtrerade kolumnen. Planen du får är den optimala planen för den här frågan.
Men vad händer om du vill tillåta användare att be om olevererade beställningar? Sådana beställningar har ett NULL leveransdatum. Här är ett försök att skicka en NULL som inmatningsdatum:
DECLARE @dt SOM DATUM =NULL; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Som du redan vet producerar ett predikat som använder en likhetsoperator OKÄNT när någon av operanderna är en NULL. Följaktligen returnerar denna fråga ett tomt resultat:
orderid shippeddate----------- -----------(0 rader påverkade)
Även om T-SQL stöder en IS NULL-operator, stöder den inte en explicit IS
DECLARE @dt SOM DATUM =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
Den här frågan genererar korrekt utdata:
orderid shippeddate----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL(21 rader påverkade)
Men planen för denna fråga, som visas i figur 2, är inte optimal.
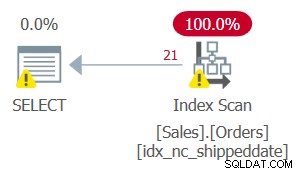 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
Eftersom du tillämpade manipulation på den filtrerade kolumnen anses filterpredikatet inte längre vara ett SARG. Indexet täcker fortfarande, så det kan användas; men istället för att använda en sökning i indexet som går direkt till intervallet av kvalificerade rader, skannas hela indexbladet. Anta att bordet hade 50 000 000 beställningar, med endast 1 000 obesände beställningar. Den här planen skulle skanna alla 50 000 000 rader istället för att göra en sökning som går direkt till de kvalificerande 1 000 raderna.
En form av ett filterpredikat som både har den korrekta betydelsen som vi är ute efter och anses vara ett sökargument är (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Här är en fråga som använder detta SARGable-predikat (vi kallar det fråga 3):
DECLARE @dt SOM DATUM =NULL; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL));
Planen för denna fråga visas i figur 3.
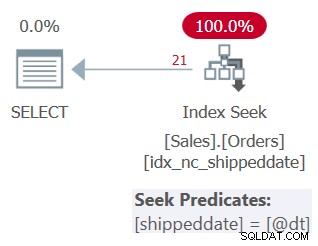 Figur 3:Plan för fråga 3
Figur 3:Plan för fråga 3
Som du kan se tillämpar planen en sökning i stödindexet. Seek-predikatet säger shippeddate =@dt, men det är internt utformat för att hantera NULLs precis som icke-NULL-värden för jämförelsens skull.
Denna lösning anses generellt vara rimlig. Det är standard, optimalt och korrekt. Dess största nackdel är att det är mångsidigt. Vad händer om du hade flera filterpredikat baserade på NULL-kolumner? Du skulle snabbt sluta med en lång och krånglig WHERE-klausul. Och det blir mycket värre när du behöver skriva ett filterpredikat som involverar en NULLbar kolumn som letar efter rader där kolumnen är annorlunda än indataparametern. Predikatet blir då:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
Man ser tydligt behovet av en mer elegant lösning som är både kortfattad och optimal. Tyvärr tar vissa till en icke-standardlösning där du stänger av sessionsalternativet ANSI_NULLS. Det här alternativet gör att SQL Server använder icke-standardiserad hantering av likhetsoperatorerna (=) och skiljer sig från (<>) med logik med två värden istället för logik med tre värden, och behandlar NULL-värden precis som icke-NULL-värden för jämförelsesyften. Det är åtminstone fallet så länge som en av operanderna är en parameter/variabel eller en bokstavlig.
Kör följande kod för att stänga av alternativet ANSI_NULLS i sessionen:
STÄLL AV ANSI_NULLS;
Kör följande fråga med ett enkelt likhetsbaserat predikat:
DECLARE @dt SOM DATUM =NULL; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Denna fråga returnerar de 21 ej skickade beställningarna. Du får samma plan som tidigare i figur 3, som visar en sökning i indexet.
Kör följande kod för att växla tillbaka till standardbeteende där ANSI_NULLS är på:
STÄLL PÅ ANSI_NULLS;
Att förlita sig på sådant icke-standardiserat beteende avråds starkt. Dokumentationen anger också att stödet för detta alternativ kommer att tas bort i någon framtida version av SQL Server. Dessutom inser många inte att det här alternativet bara är tillämpligt när åtminstone en av operanderna är en parameter/variabel eller en konstant, även om dokumentationen är ganska tydlig om det. Det gäller inte när man jämför två kolumner som i en sammanfogning.
Så hur hanterar du joins som involverar NULLable join-kolumner om du vill få en matchning när de två sidorna är NULLs? Som ett exempel, använd följande kod för att skapa och fylla i tabellerna T1 och T2:
SLIP TABELL OM FINNS dbo.T1, dbo.T2;GO SKAPA TABELL dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) INTE NULL, BEGRÄNSNING UNQ_T1 UNIK CLUSTERED(k1, k1, k1, k1, k3)); SKAPA TABELL dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) INTE NULL, BEGRÄNSNING UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VÄRDEN (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C') ,(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VÄRDEN (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Koden skapar täckande index på båda tabellerna för att stödja en join baserat på join-nycklarna (k1, k2, k3) på båda sidor.
Använd följande kod för att uppdatera kardinalitetsstatistiken, blåsa upp siffrorna så att optimeraren skulle tro att du har att göra med större tabeller:
UPPDATERA STATISTIK dbo.T1(UNQ_T1) MED ROWCOUNT =1000000;UPPDATERA STATISTIK dbo.T2(UNQ_T2) MED ROWCOUNT =1000000;
Använd följande kod i ett försök att sammanfoga de två tabellerna med enkla likhetsbaserade predikat:
VÄLJ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRÅN dbo.T1 INNER JOIN dbo.T2 PÅ T1.k1 =T2.k1 OCH T1.k2 =T2.k2 OCH T1. k3 =T2.k3;
Precis som med tidigare filtreringsexempel ger jämförelser mellan NULL-värden som använder en likhetsoperator OKÄNT, vilket resulterar i icke-matchningar. Den här frågan genererar en tom utdata:
k1 K2 K3 val1 val2------------ ----------- ---------- ---------- ----------(0 rader påverkade)
Om du använder ISNULL eller COALESCE som i ett tidigare filtreringsexempel, att ersätta en NULL med ett värde som normalt inte kan visas i data på båda sidor, resulterar det i en korrekt fråga (jag kallar den här frågan Fråga 4):
VÄLJ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRÅN dbo.T1 INNER JOIN dbo.T2 ON ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -2147483648 ) AND ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) AND ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483648);
Den här frågan genererar följande utdata:
k1 K2 K3 val1 val2------------ ----------- ---------- ---------- - ----------0 NULL NULL C I0 NULL 1 F K
Men precis som att manipulera en filtrerad kolumn bryter filterpredikatets SARGability, förhindrar manipulation av en join-kolumn möjligheten att förlita sig på indexordning. Detta kan ses i planen för denna fråga som visas i figur 4.
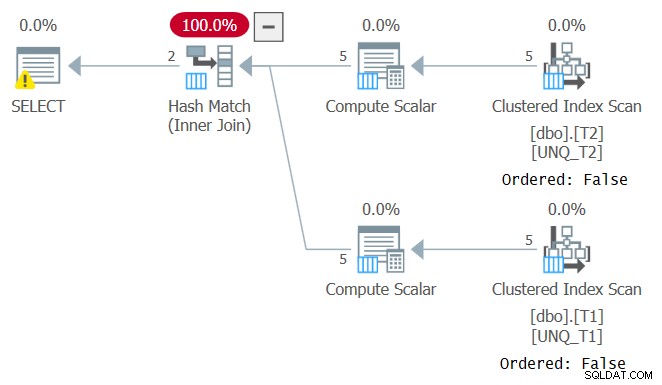 Figur 4:Plan för fråga 4
Figur 4:Plan för fråga 4
En optimal plan för den här frågan är en som tillämpar ordnade skanningar av de två täckande indexen följt av en sammanfogningsalgoritm, utan någon explicit sortering. Optimeraren valde en annan plan eftersom den inte kunde förlita sig på indexordning. Om du försöker tvinga fram en Merge Join-algoritm med INNER MERGE JOIN, kommer planen fortfarande att förlita sig på oordnade genomsökningar av indexen, följt av explicit sortering. Prova!
Naturligtvis kan du använda de långa predikaten som liknar SARGable-predikaten som visats tidigare för filtreringsuppgifter:
VÄLJ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRÅN dbo.T1 INNER JOIN dbo.T2 PÅ (T1.k1 =T2.k1 ELLER (T1.k1 ÄR NULL OCH T2. K1 ÄR NULL)) OCH (T1.k2 =T2.k2 ELLER (T1.k2 ÄR NULL OCH T2.K2 ÄR NULL)) OCH (T1.k3 =T2.k3 OR (T1.k3 ÄR NULL OCH T2.K3 ÄR NULL));
Denna fråga ger det önskade resultatet och gör det möjligt för optimeraren att förlita sig på indexordning. Vår förhoppning är dock att hitta en lösning som är både optimal och kortfattad.
Det finns en föga känd elegant och koncis teknik som du kan använda i både kopplingar och filter, både för att identifiera matchningar och för att identifiera icke-matchningar. Denna teknik upptäcktes och dokumenterades redan för flera år sedan, till exempel i Paul Whites utmärkta skrivning Undocumented Query Plans:Equality Comparisons från 2011. Men av någon anledning verkar det som att många fortfarande inte är medvetna om det, och tyvärr slutar använda suboptimala, långa och icke-standardiserade lösningar. Den förtjänar verkligen mer exponering och kärlek.
Tekniken bygger på det faktum att setoperatorer som INTERSECT och EXCEPT använder en distinkthetsbaserad jämförelsemetod när de jämför värden, och inte en jämlikhets- eller ojämlikhetsbaserad jämförelsemetod.
Se vår sammanfogningsuppgift som ett exempel. Om vi inte behövde returnera andra kolumner än join-nycklarna, skulle vi ha använt en enkel fråga (jag kallar den fråga 5) med en INTERSECT-operator, som så:
VÄLJ k1, k2, k3 FRÅN dbo.T1INTERSECTSELECT k1, k2, k3 FRÅN dbo.T2;
Den här frågan genererar följande utdata:
k1 k2 k3----------- ----------- ----------0 NULL NULL0 NULL 1
Planen för den här frågan visas i figur 5, vilket bekräftar att optimeraren kunde förlita sig på indexordning och använda en sammanfogningsalgoritm.
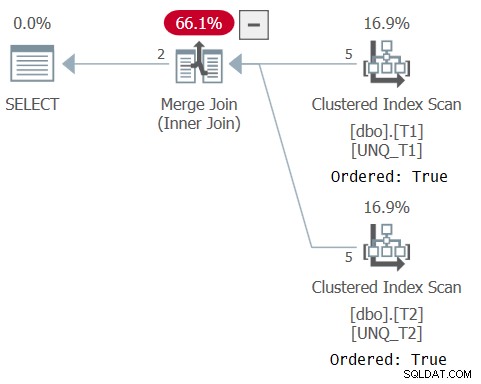 Figur 5:Plan för fråga 5
Figur 5:Plan för fråga 5
Som Paul noterar i sin artikel använder XML-planen för setoperatorn en implicit IS-jämförelseoperator (CompareOp="IS" ) i motsats till EQ-jämförelseoperatorn som används i en normal join (CompareOp="EQ" ). Problemet med en lösning som enbart förlitar sig på en uppsättningsoperatör är att den begränsar dig till att endast returnera de kolumner som du jämför. Vad vi verkligen behöver är en sorts hybrid mellan en join- och en setoperator, vilket gör att du kan jämföra en delmängd av elementen samtidigt som du returnerar ytterligare sådana som en join gör, och använda distinkthetsbaserad jämförelse (IS) som en setoperator gör. Detta kan uppnås genom att använda en join som den yttre konstruktionen och ett EXISTS-predikat i joinens ON-sats baserat på en fråga med en INTERSECT-operator som jämför join-nycklarna från de två sidorna, som så (jag kommer att referera till den här lösningen som Query 6):
VÄLJ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FRÅN dbo.T1 INNER JOIN dbo.T2 PÅ FINNS(VÄLJ T1.k1, T1.k2, T1.k3 SKÄRSA VÄLJ T2. k1, T2.k2, T2.k3);
INTERSECT-operatören arbetar på två frågor, som var och en bildar en uppsättning av en rad baserat på kopplingsnycklarna från vardera sidan. När de två raderna är lika, returnerar INTERSECT-frågan en rad; predikatet EXISTS returnerar TRUE, vilket resulterar i en matchning. När de två raderna inte är samma, returnerar INTERSECT-frågan en tom uppsättning; EXISTS-predikatet returnerar FALSE, vilket resulterar i en icke-matchning.
Denna lösning genererar önskad utdata:
k1 K2 K3 val1 val2------------ ----------- ---------- ---------- - ----------0 NULL NULL C I0 NULL 1 F K
Planen för denna fråga visas i figur 6, vilket bekräftar att optimeraren kunde förlita sig på indexordning.
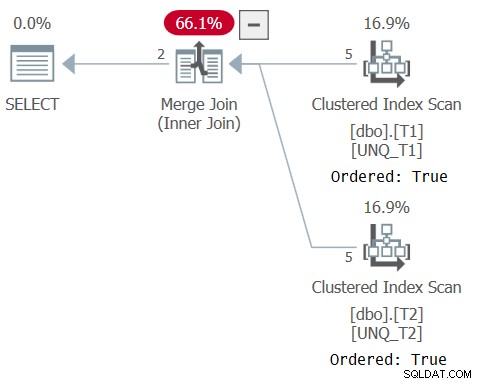 Figur 6:Plan för fråga 6
Figur 6:Plan för fråga 6
Du kan använda en liknande konstruktion som ett filterpredikat som involverar en kolumn och en parameter/variabel för att leta efter matchningar baserat på distinkthet, som så:
DECLARE @dt SOM DATUM =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Planen är densamma som den som visas tidigare i figur 3.
Du kan också negera predikatet för att leta efter icke-matchningar, som så:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Den här frågan genererar följande utdata:
orderid shippeddate------------ -----------11008 NULL11019 NULL11039 NULL...10847 2019-02-1010856 2019-02-1010871 2019-02-1010867 2019-02-1110874 2019-02-1110870 2019-02-1310884 2019-02-1310840 2019-02-1610887 2019-02-16...(825)Alternativt kan du använda ett positivt predikat, men ersätt INTERSECT med EXCEPT, så här:
DECLARE @dt AS DATE ='20190212'; VÄLJ orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);Observera att planerna i de två fallen kan vara olika, så se till att experimentera åt båda hållen med stora mängder data.
Slutsats
NULL lägger till sin andel av komplexiteten till din SQL-kodskrivning. Du vill alltid tänka på potentialen för närvaron av NULLs i data, och se till att du använder rätt frågekonstruktioner och lägga till relevant logik i dina lösningar för att hantera NULLs korrekt. Att ignorera dem är ett säkert sätt att sluta med buggar i din kod. Den här månaden fokuserade jag på vad NULL är och hur de hanteras i jämförelser som involverar konstanter, variabler, parametrar och kolumner. Nästa månad kommer jag att fortsätta bevakningen genom att diskutera NULL-behandlingsinkonsekvenser i olika språkelement och saknade standardfunktioner för NULL-hantering.