Gillar du att tolka strängar? Om så är fallet, är en av de oumbärliga strängfunktionerna att använda SQL SUBSTRING. Det är en av de färdigheter en utvecklare bör ha för alla språk.
Så, hur gör du?
Viktiga poäng i strängtolkning
Anta att du är ny på att analysera. Vilka viktiga punkter behöver du komma ihåg?
- Vet vilken information som är inbäddad i strängen.
- Få de exakta positionerna för varje del av information i en sträng. Du kan behöva räkna alla tecken i strängen.
- Känn till storleken eller längden på varje informationsbit i en sträng.
- Använd rätt strängfunktion som enkelt kan extrahera varje information i strängen.
Att känna till alla dessa faktorer förbereder dig för att använda SQL SUBSTRING() och skicka argument till den.
SQL SUBSTRING-syntax

Syntaxen för SQL SUBSTRING är följande:
SUBSTRING(stränguttryck, start, längd)
- stränguttryck – a bokstavlig sträng eller ett SQL-uttryck som returnerar en sträng.
- start – ett nummer där utvinningen kommer att börja. Det är också 1-baserat – det första tecknet i stränguttrycksargumentet måste börja med 1, inte 0. I SQL Server är det alltid ett positivt tal. I MySQL eller Oracle kan det dock vara positivt eller negativt. Om det är negativt börjar skanningen från slutet av strängen.
- längd – längden på tecken som ska extraheras. SQL Server kräver det. I MySQL eller Oracle är det valfritt.
4 SQL SUBSTRING exempel
1. Använda SQL SUBSTRING för att extrahera från en bokstavlig sträng
Låt oss börja med ett enkelt exempel med en bokstavlig sträng. Vi använder namnet på en känd koreansk tjejgrupp, BlackPink, och figur 1 illustrerar hur SUBSTRING kommer att fungera:

Koden nedan visar hur vi extraherar den:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Låt oss nu också inspektera resultatuppsättningen i figur 2:
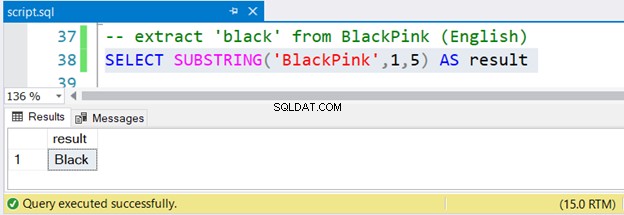
Är det inte lätt?
För att extrahera Svart från BlackPink , du börjar från position 1 och slutar på position 5. Sedan BlackPink är koreanska, låt oss ta reda på om SUBSTRING fungerar med Unicode-koreanska tecken.
(ANSVARSFRISKRIVNING :Jag kan inte prata, läsa eller skriva koreanska, så jag fick den koreanska översättningen från Wikipedia. Jag använde också Google Översätt för att se vilka tecken som motsvarar Svart och Rosa . Förlåt mig om det är fel. Ändå hoppas jag att punkten jag försöker förtydliga kommer í tvärsöver)
Låt oss ta strängen på koreanska (se figur 3). De koreanska tecknen som används översätts till BlackPink:

Se nu koden nedan. Vi kommer att extrahera två tecken som motsvarar Svart .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Lade du märke till den koreanska strängen som föregås av N ? Den använder Unicode-tecken, och SQL Servern antar NVARCHAR och bör föregås av N . Det är den enda skillnaden i den engelska versionen. Men kommer det gå bra? Se figur 4:
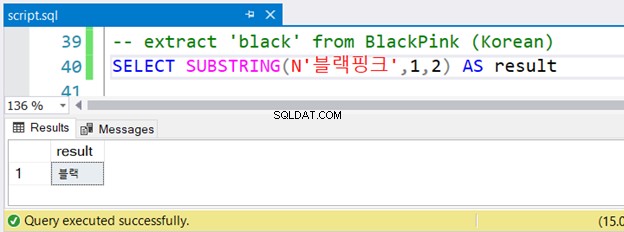
Det gick utan fel.
2. Använda SQL SUBSTRING i MySQL med ett negativt startargument
Att ha ett negativt startargument fungerar inte i SQL Server. Men vi kan ha ett exempel på detta med MySQL. Den här gången ska vi extrahera Rosa från BlackPink . Här är koden:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Låt oss nu få resultatet i figur 5:
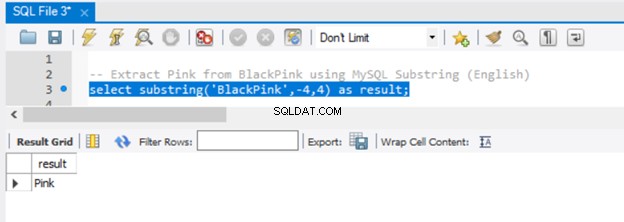
Eftersom vi skickade -4 till startparametern började extraheringen från slutet av strängen och gick 4 tecken bakåt. För att uppnå samma resultat i SQL Server, använd RIGHT()-funktionen.
Unicode-tecken fungerar också med MySQL SUBSTRING, som du kan se i figur 6:
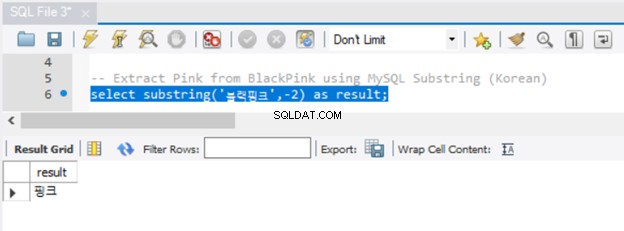
Det fungerade bra. Men märkte du att vi inte behövde föregå strängen med N? Observera också att det finns flera sätt att få en delsträng i MySQL. Du har redan sett SUBSTRING. Motsvarande funktioner i MySQL är SUBSTR() och MID().
3. Analysera delsträngar med variabla start- och längdargument
Tyvärr använder inte alla strängextraktioner fasta start- och längdargument. I ett sådant fall behöver du CHARINDEX för att få positionen för en sträng du riktar in dig på. Låt oss ta ett exempel:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
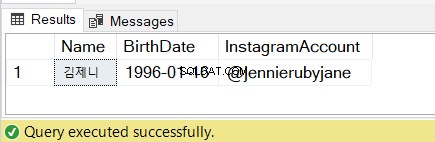
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
I koden ovan måste du extrahera ett namn på koreanska, födelsedatumet och Instagram-kontot.
Vi börjar med att definiera tre variabler för att hålla dessa delar av information. Efter det kan vi analysera strängen och tilldela resultaten till varje variabel.
Du kanske tror att det är enklare att ha fasta starter och längder. Dessutom kan vi lokalisera det genom att räkna tecknen manuellt. Men vad händer om du har massor av dessa på ett bord?
Här är vår analys:
- Det enda fasta objektet i strängen är @ karaktär i Instagram-kontot. Vi kan få dess position i strängen med CHARINDEX. Sedan använder vi den positionen för att få start och längder på resten.
- Födelsedatumet är i ett fast format med MM/dd/åååå med 10 tecken.
- För att extrahera namnet börjar vi med 1. Eftersom födelsedatumet har 10 tecken plus @ tecken, kan du komma till sluttecknet för namnet i strängen. Från positionen för @ tecken går vi 11 tecken tillbaka. SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) är vägen att gå.
- För att få födelsedatumet använder vi samma logik. Få positionen för @ tecken och flytta 10 tecken bakåt för att få födelsedatumets startvärde. 10 är en fast längd. SUBSTRING(@lineString,CHARINDEX(‘@',@lineString)-10,10) är hur man får födelsedatumet.
- Äntligen är det enkelt att skaffa ett Instagram-konto. Börja från positionen för @ tecken med CHARINDEX. Obs! 30 är gränsen för Instagram-användarnamn.
Kolla in resultaten i figur 7:
4. Använda SQL SUBSTRING i en SELECT-sats
Du kan också använda SUBSTRING i SELECT-satsen, men först måste vi ha arbetsdata. Här är koden:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Ovanstående kod utgör en lång sträng som innehåller namn, e-postadress, stad och postnummer. Vi vill också lagra det i Personkontakten bord.
Nu, låt oss ha koden för att bakåtkonstruera med SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Eftersom vi använde kolumner med fast storlek finns det inget behov av att använda CHARINDEX.
Använder du SQL SUBSTRING i en WHERE-klausul – en prestationsfälla?
Det är sant. Ingen kan hindra dig från att använda SUBSTRING i en WHERE-sats. Det är en giltig syntax. Men vad händer om det orsakar prestandaproblem?
Det är därför vi bevisar det med ett exempel och diskuterar sedan hur vi löser problemet. Men först, låt oss förbereda vår data:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Jag kan inte förstöra SalesOrderHeader bord, så jag dumpade det till ett annat bord. Sedan skapade jag SalesOrderID i de nya Försäljningsorder tabell en primärnyckel.
Nu är vi redo för frågan. Jag använder dbForge Studio för SQL Server med Frågeprofileringsläge PÅ för att analysera frågorna.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Som du ser fungerar ovanstående fråga bra. Titta nu på Query Profile Plan Diagram i figur 8:
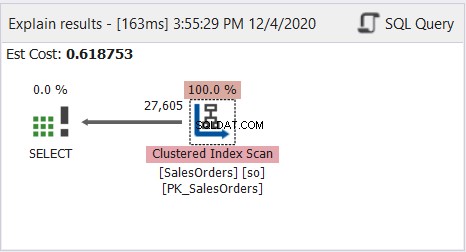
Plandiagrammet ser enkelt ut, men låt oss inspektera egenskaperna för Clustered Index Scan-noden. Vi behöver särskilt Runtime Information:
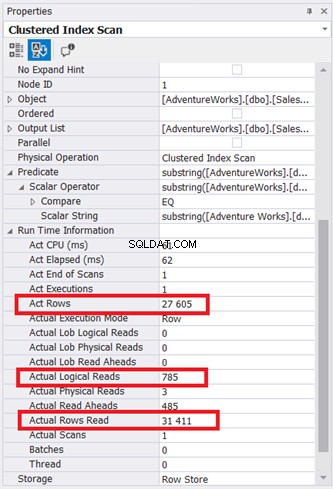
Illustration 9 visar 785 * 8KB sidor som läses av databasmotorn. Observera också att den faktiska avlästa raderna är 31 411. Det är det totala antalet rader i tabellen. Frågan returnerade dock endast 27 605 faktiska rader.
Hela tabellen lästes med det klustrade indexet som referens.
Varför?
Saken är den att SQL Server måste veta om 4030 är en delsträng av ett kontonummer. Den måste läsa och utvärdera varje post. Släng raderna som inte är lika och returnera de rader som vi behöver. Det får jobbet gjort men inte tillräckligt snabbt.
Vad kan vi göra för att det ska gå snabbare?
Undvik SUBSTRING i WHERE-satsen och uppnå samma resultat snabbare
Vad vi vill nu är att få samma resultat utan att använda SUBSTRING i WHERE-satsen. Följ stegen nedan:
- Ändra tabellen genom att lägga till en beräknad kolumn med en SUBSTRING(kontonummer, 4,4) formel. Låt oss döpa det till AccountCategory i brist på en bättre term.
- Skapa ett icke-klustrat index för den nya AccountCategory kolumn. Inkludera OrderDate , Kontonummer och Kund-ID kolumner.
Det är det.
Vi ändrar WHERE-satsen i frågan för att anpassa den nya AccountCategory kolumn:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
Det finns ingen SUBSTRING i WHERE-satsen. Låt oss nu kolla plandiagrammet:
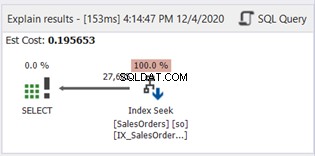
Indexsökningen har ersatts av Indexsök. Observera också att SQL Server använde det nya indexet på den beräknade kolumnen. Finns det också förändringar i logiska läsningar och faktiska rader? Se figur 11:
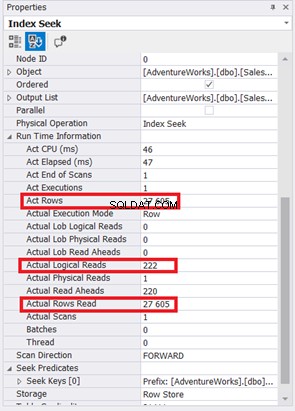
Att minska från 785 till 222 logiska läsningar är en stor förbättring, mer än tre gånger mindre än de ursprungliga logiska läsningarna. Det minimerade också faktiska rader Läs till endast de rader vi behöver.
Att använda SUBSTRING i WHERE-satsen är alltså inte bra för prestanda, och det gäller för alla andra skalärvärdena funktioner som används i WHERE-satsen.
Slutsats
- Utvecklare kan inte undvika att analysera strängar. Ett behov av det kommer att uppstå på ett eller annat sätt.
- Vid analys av strängar är det viktigt att känna till informationen i strängen, positionerna för varje informationsbit och deras storlekar eller längder.
- En av analysfunktionerna är SQL SUBSTRING. Den behöver bara strängen för att analysera, positionen för att starta extrahering och längden på strängen som ska extraheras.
- SUBSTRING kan ha olika beteenden mellan SQL-varianter som SQL Server, MySQL och Oracle.
- Du kan använda SUBSTRING med bokstavliga strängar och strängar i tabellkolumner.
- Vi använde även SUBSTRING med Unicode-tecken.
- Att använda SUBSTRING eller någon funktion med skalärt värde i WHERE-satsen kan minska frågeprestanda. Fixa detta med en indexerad beräknad kolumn.
Om du tycker att det här inlägget är användbart, dela det på dina föredragna sociala medieplattformar eller dela din kommentar nedan?