Jag har länge varit en förespråkare för att välja rätt datatyp. Jag har pratat om några exempel i ett tidigare "Bad Habits"-blogginlägg, men denna helg på SQL Saturday #162 (Cambridge, Storbritannien), ämnet för användning av DATETIME som standard kom upp. I en konversation efter min presentation av T-SQL :Dåliga vanor och bästa praxis uppgav en användare att de bara använder DATETIME även om de bara behöver granularitet till minut eller dag, så är datum/tid-kolumnerna i hela företaget alltid samma datatyp. Jag föreslog att det här kunde vara slösaktigt och att konsistensen kanske inte var värt det, men idag bestämde jag mig för att ge mig ut för att bevisa min teori.
TL;DR-version
Mina tester nedan visar att det verkligen finns scenarier där du kanske vill överväga att använda en smalare datatyp istället för att hålla fast vid DATETIME överallt. Men det är viktigt att se var mina tester för detta pekade åt andra hållet, och det är också viktigt att testa dessa scenarier mot ditt schema, i din miljö, med hårdvara och data som är så sanna för produktionen som möjligt. Dina resultat kan, och kommer nästan säkert att, variera.
Destinationstabellerna
Låt oss överväga fallet där granularitet bara är viktigt för dagen (vi bryr oss inte om timmar, minuter, sekunder). För detta kunde vi välja DATETIME (som användaren föreslagit), eller SMALLDATETIME eller DATE på SQL Server 2008+. Det finns också två olika typer av data som jag ville överväga:
- Data som skulle infogas ungefär sekventiellt i realtid (t.ex. händelser som händer just nu);
- Data som skulle infogas slumpmässigt (t.ex. födelsedatum för nya medlemmar).
Jag började med 2 tabeller som följande och skapade sedan 4 till (2 för SMALLDATETIME, 2 för DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Upprepa sedan för DATE och SMALLDATETIME.
Och mitt mål var att testa batchinsättningsprestanda på dessa två olika sätt, såväl som effekten på den totala lagringsstorleken och fragmenteringen, och slutligen prestandan för intervallfrågor.
Exempeldata
För att generera några exempeldata använde jag en av mina praktiska tekniker för att generera något meningsfullt från något som inte är det:katalogvyerna. På mitt system returnerade detta 971 distinkta datum/tidsvärden (sammanlagt 1 000 000 rader) på cirka 12 sekunder:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FRÅN ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) VÄLJ DISTINCT d FROM y;
Jag placerade dessa miljoner rader i en tabell så att jag kunde simulera sekventiella/slumpmässiga infogningar med olika åtkomstmetoder för exakt samma data från tre olika sessionsfönster:
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FRÅN ( SELECT s1.[object_id] % 1000_object sys. AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Denna process tog lite längre tid att slutföra (20 sekunder). Sedan skapade jag en andra tabell för att lagra samma data men distribuerad slumpmässigt (så att jag kunde upprepa samma fördelning över alla inlägg).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Frågor för att fylla i tabellerna
Därefter skrev jag en uppsättning frågor för att fylla de andra tabellerna med denna data, med hjälp av tre frågefönster för att simulera åtminstone lite samtidighet:
WAITFOR TIME '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- beroende på metod/datatyp SELECT source_date FROM dbo.Staging[_Random] -- beroende på destination WHERE ID % 3 =<0,1,2> -- beroende på frågefönster ORDER MED ID; SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Som i mitt förra inlägg har jag förexpanderat databasen för att förhindra att någon typ av automatisk tillväxthändelser för datafiler stör resultaten. Jag inser att det inte är helt realistiskt att utföra miljonradsinfogningar i ett pass, eftersom jag inte kan förhindra loggaktivitet för en så stor transaktion från att störa, men det bör göra det konsekvent över varje metod. Med tanke på att hårdvaran jag testar med skiljer sig helt från hårdvaran du använder, bör de absoluta resultaten inte vara en viktig faktor, bara den relativa jämförelsen.
(I ett framtida test kommer jag också att prova det här med riktiga partier som kommer in från loggfiler med relativt blandade data, och använder bitar av källtabellen i loopar – jag tror att det skulle vara intressanta experiment också. Och naturligtvis lägga till komprimering i blandningen.)
Resultaten:
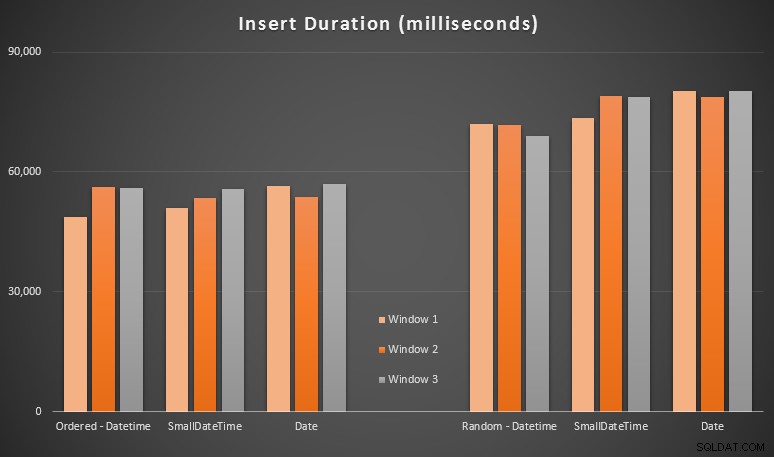
Dessa resultat var inte så överraskande för mig – infogning i slumpmässig ordning ledde till längre körtider än infogning sekventiellt, något som vi alla kan ta tillbaka till våra rötter för att förstå hur index i SQL Server fungerar och hur fler "dåliga" siddelningar kan inträffa i detta scenario (jag övervakade inte specifikt för siddelningar i den här övningen, men det är något jag kommer att överväga i framtida tester).
Jag märkte att, på den slumpmässiga sidan, de implicita omvandlingarna på inkommande data kan ha haft en inverkan på tidpunkter, eftersom de verkade lite högre än den ursprungliga DATETIME -> DATETIME skär. Så jag bestämde mig för att bygga två nya tabeller som innehåller källdata:en med DATE och en som använder SMALLDATETIME . Detta skulle simulera, till viss del, att konvertera din datatyp ordentligt innan den skickas till insert-satsen, så att en implicit konvertering inte krävs under infogningen. Här är de nya tabellerna och hur de fylldes i:
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Detta fick inte den effekt jag hoppades på – tiderna var likartade i alla fall. Så det var en vild gåsjakt.
Använt utrymme och fragmentering
Jag körde följande fråga för att avgöra hur många sidor som var reserverade för varje tabell:
SELECT name ='dbo.' + OBJECT_NAME([object_id]), pages =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDER BY sidor;
Resultaten:
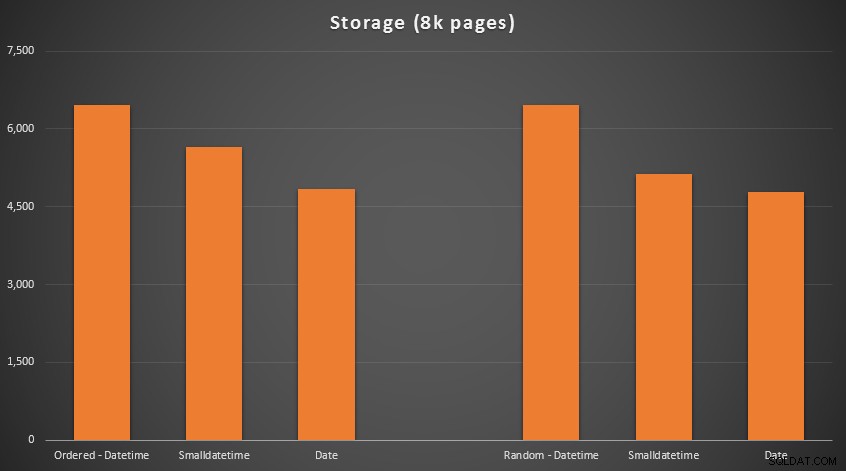
Ingen raketvetenskap här; använder en mindre datatyp, bör du använda färre sidor. Byter från DATETIME till DATE gav konsekvent en 25 % minskning av antalet använda sidor, medan SMALLDATETIME minskade kravet med 13-20%.
Nu för fragmentering och sidtäthet på de icke-klustrade indexen (det var väldigt liten skillnad för de klustrade indexen):
VÄLJ '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FRÅN sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED' index =_WELHERE'0; /pre>
Resultat:
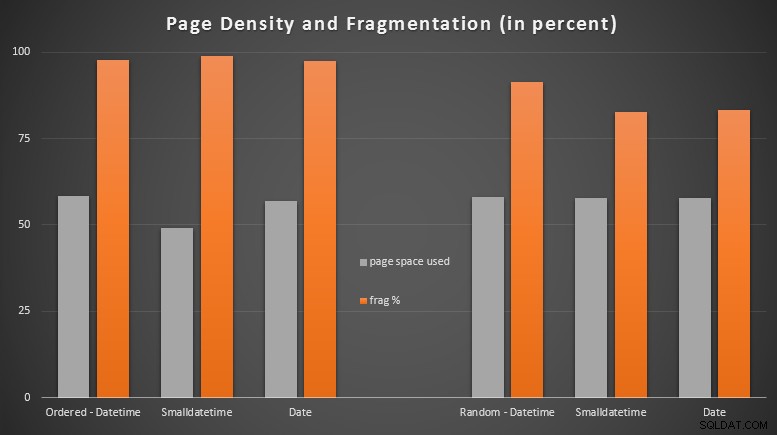
Jag blev ganska förvånad över att se den beställda datan bli nästan helt fragmenterad, medan den data som infogades slumpmässigt faktiskt slutade med något bättre sidanvändning. Jag har noterat att detta kräver ytterligare undersökning utanför omfattningen av dessa specifika tester, men det kan vara något du vill kontrollera om du har icke-klustrade index som till stor del förlitar sig på sekventiella inlägg.
[En online-ombyggnad av de icke-klustrade indexen på alla 6 tabellerna körde på 7 sekunder, vilket satte tillbaka siddensiteten till 99,5 %-intervallet och sänkte fragmenteringen till under 1 %. Men jag körde inte det förrän jag utförde frågetesterna nedan...]
Räckviddsfrågatest
Slutligen ville jag se effekten på körtider för enkla datumintervallfrågor mot de olika indexen, både med den inneboende fragmenteringen som orsakas av skrivaktivitet av OLTP-typ och på ett rent index som byggs om. Frågan i sig är ganska enkel:
VÄLJ TOP (200000) dt FRÅN dbo.{table_name} WHERE dt>='20110101' BESTÄLL EFTER dt;
Här är resultaten innan indexen byggdes om med SQL Sentry Plan Explorer:
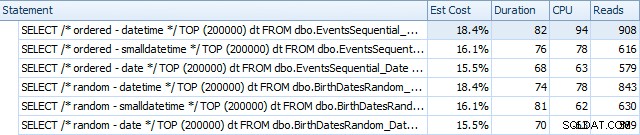
Och de skiljer sig något efter ombyggnaderna:
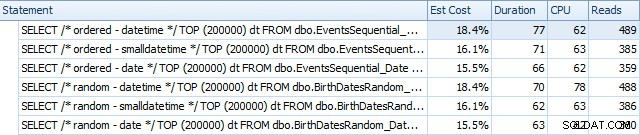
I huvudsak ser vi något högre varaktighet och läsningar för DATETIME-versionerna, men mycket liten skillnad i CPU. Och skillnaderna mellan SMALLDATETIME och DATE är försumbara i jämförelse. Alla frågorna hade förenklade frågeplaner så här:

(Sökningen är naturligtvis en beställd räckviddsskanning.)
Slutsats
Även om dessa tester visserligen är ganska tillverkade och kunde ha dragit nytta av fler permutationer, visar de ungefär vad jag förväntade mig att se:de största effekterna på detta specifika val är på utrymmet som upptas av det icke-klustrade indexet (där att välja en smalare datatyp kommer att definitivt fördel), och på den tid som krävs för att utföra infogning i godtycklig, snarare än sekventiell, ordning (där DATETIME har bara en marginell kant).
Jag skulle älska att höra dina idéer om hur man sätter datatypsval som dessa genom mer grundliga och straffande tester. Jag planerar att gå in på mer detaljer i framtida inlägg.