[ Del 1 | Del 2 | Del 3 ]
I del 1 visade jag hur både sid- och kolumnlagringskomprimering kunde minska storleken på en 1TB-tabell med 80 % eller mer. Även om jag var imponerad av att jag kunde krympa ett bord från 1 TB till 50 GB, var jag inte särskilt nöjd med hur lång tid det tog (allt från 2 till 14 timmar). Med några tips som är nådigt lånade från folk som Joe Obbish, Lonny Niederstadt, Niko Neugebauer och andra, i det här inlägget kommer jag att försöka göra några ändringar i mitt ursprungliga försök att få bättre lastprestanda. Eftersom det vanliga kolumnbutiksindexet inte komprimerade bättre än sidkomprimering på denna datamängd , och det tog 13 timmar längre tid att komma dit, kommer jag att fokusera enbart på den mer avancerade lösningen med COLUMNSTORE_ARCHIVE komprimering.
Några av de problem som jag tror påverkade prestandan inkluderar följande:
- Dåliga val av fillayout – Jag lägger 8 filer i en filgrupp, med parallellitet men ingen (eller suboptimal) partitionering, sprejar I/O över flera filer med hänsynslöst övergivande. För att ta itu med detta kommer jag att:
- partitionera tabellen i 8 partitioner (en per kärna)
- lägg varje partitions datafil i sin egen filgrupp
- använd 8 separata processer för att koppla till varje partition
- använd arkivkomprimering på alla utom den "aktiva" partitionen
- för många små partier och suboptimal radgruppspopulation – genom att bearbeta 10 miljoner rader åt gången fyllde jag nio radgrupper med en fin, 1 048 576 rader, och sedan skulle de återstående 562 816 raderna hamna i en annan mindre radgrupp. Och alla ojämna fördelningar som lämnade en rest på <102 400 rader skulle sippra in i den mindre effektiva deltabutiksstrukturen. För att fördela rader mer enhetligt och undvika deltabutik kommer jag att:
- bearbeta så mycket av data som möjligt i exakta multiplar av 1 048 576 rader
- fördela dessa över 8 partitioner så jämnt som möjligt
- använd en batchstorlek närmare 10x -> 100 miljoner rader
- schemaläggningsstapling – även om jag inte kollade efter detta, är det möjligt att en del av avmattningen orsakades av att en schemaläggare tog på sig för mycket arbete och en annan schemaläggare inte räckte till, på grund av schemaläggarens round-robining. Nu när jag avsiktligt kommer att ladda data med 8 maxdop 1-processer istället för en maxdop 8-process, för att hålla alla schemaläggare lika upptagna, kommer jag att:
- använd en lagrad procedur som försöker balansera jämnt mellan schemaläggare (se sidorna 189-191 i SQLCAT's Guide to:Relational Engine för inspirationen bakom denna idé)
- aktivera global spårningsflagga 2467 och 2469, som varnat för i dokumentationen
- Kompressionsuppgift för kolumnlager i bakgrunden – Det var slösaktigt att låta detta köra under befolkning, eftersom jag i alla fall planerade att bygga om i slutet. Den här gången ska jag:
- inaktivera denna uppgift med global spårningsflagga 634
Jag skrotade den initiala partitionsfunktionen och schemat och byggde en ny baserad på en jämnare fördelning av data. Jag vill ha 8 partitioner för att matcha antalet kärnor och antalet datafiler, för att maximera "fattigmansparallellen" jag planerar att använda.
Först måste vi skapa en ny uppsättning filgrupper, var och en med sin egen fil:
ÄNDRA DATABAS OKopiera ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OKopiera LÄGG TILL FIL (namn =N'CCI_Part_1', storlek =250000, filnamn ='K:\Data\o_cci_p_1.mdf') TILL FILGROUP FG_CCI_Part1; -- ... 6 fler ... ÄNDRA DATABAS OCpy ADD FILEGROUP FG_CCI_Part8; ÄNDRA DATABAS OKopiera LÄGG TILL FIL (namn =N'CCI_Part_8', storlek =250000, filnamn ='K:\Data\o_cci_p_8.mdf') TILL FILGROUP FG_CCI_Part8;
Därefter tittade jag på antalet rader i tabellen:3 754 965 954. För att distribuera dessa exakt jämnt över 8 partitioner, det skulle vara 469 370 744,25 rader per partition. För att få det att fungera bra, låt oss få partitionsgränserna att rymma nästa multipel av 1 048 576 rader. Detta är 1 048 576 x 448 =469 762 048 – vilket skulle vara antalet rader vi skjuter efter i de första 7 partitionerna, vilket lämnar 466 631 618 rader i den sista partitionen. För att se den faktiska OID värden som skulle fungera som gränser för att innehålla det optimala antalet rader i varje partition, körde jag den här frågan mot den ursprungliga tabellen (eftersom det tog 25 minuter att köra lärde jag mig snabbt att dumpa dessa resultat i en separat tabell):
;WITH x AS (VÄLJ OID, rn =ROW_NUMBER() ÖVER (ORDNING EFTER OID) FRÅN dbo.tblOriginal WITH (NOLOCK))SELECT OID, PartitionID =1+(rn/((1048576*448)+1) ) INTO dbo.stage FROM x WHERE rn % (1048576*112) =0;
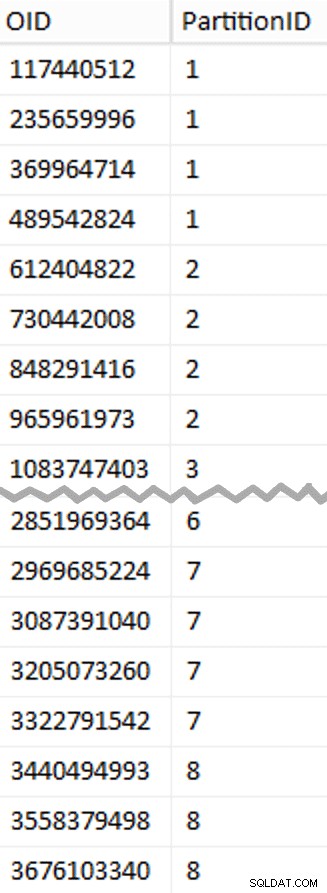 Mer att packa upp här än du kanske förväntar dig. CTE:n gör allt det tunga, eftersom den måste skanna hela tabellen på 1,14 TB och tilldela ett radnummer till varje rad . Jag vill bara returnera var
Mer att packa upp här än du kanske förväntar dig. CTE:n gör allt det tunga, eftersom den måste skanna hela tabellen på 1,14 TB och tilldela ett radnummer till varje rad . Jag vill bara returnera var (1048576*112):e rad, dock eftersom dessa är mina batchgränsrader, så det här är vad WHERE klausul gör det. Kom ihåg att jag vill dela upp arbetet i batcher närmare 100 miljoner rader åt gången, men jag vill inte heller bearbeta 469 miljoner rader i ett skott. Så förutom att dela upp data i 8 partitioner, vill jag dela upp var och en av dessa partitioner i fyra partier om 117 440 512 (1 048 576*112) rader. Varje intilliggande uppsättning av fyra partier tillhör en partition, så PartitionID I derive lägger bara till en till resultatet av det aktuella radnumret heltal dividerat med (1 048 576*448) , vilket säkerställer att gränsen alltid är i "vänster" uppsättningen. Vi lägger sedan till en till resultatet eftersom vi annars skulle hänvisa till en 0-baserad samling av partitioner, och ingen vill ha det.
Ok, det var många ord. Till höger är en bild som visar (förkortat) innehållet i scenen tabell (klicka för att visa hela resultatet och markera partitionsgränsvärden).
Vi kan sedan härleda en annan fråga från den iscensättningstabellen som visar oss min- och maxvärdena för varje batch inuti varje partition, såväl som den extra batch som inte redovisas (raderna i den ursprungliga tabellen med OID större än det högsta gränsvärdet):
;WITH x AS ( SELECT OID, PartitionID FROM dbo.stage),y AS ( SELECT PartitionID, MinID =COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1, MaxID =OID FRÅN x UNION ALLA SELECT PartitionID =8, MinID =MAX(OID)+1, MaxID =4000000000 -- lättare än att komma ihåg det verkliga maxvärdet FRÅN x)SELECT PartitionID, BatchID =ROW_NUMBER() ÖVER (PARTITION BY PartitionID ORDER BY MinID), MinID, MaxID, RowsInRange =CONVERT(int, NULL)INTO dbo.BatchQueueFROM y; -- låt oss inte lämna detta som en hög:SKAPA UNIKT CLUSTERED INDEX PK_bq PÅ dbo.BatchQueue(PartitionID, BatchID);
Dessa värden ser ut så här:
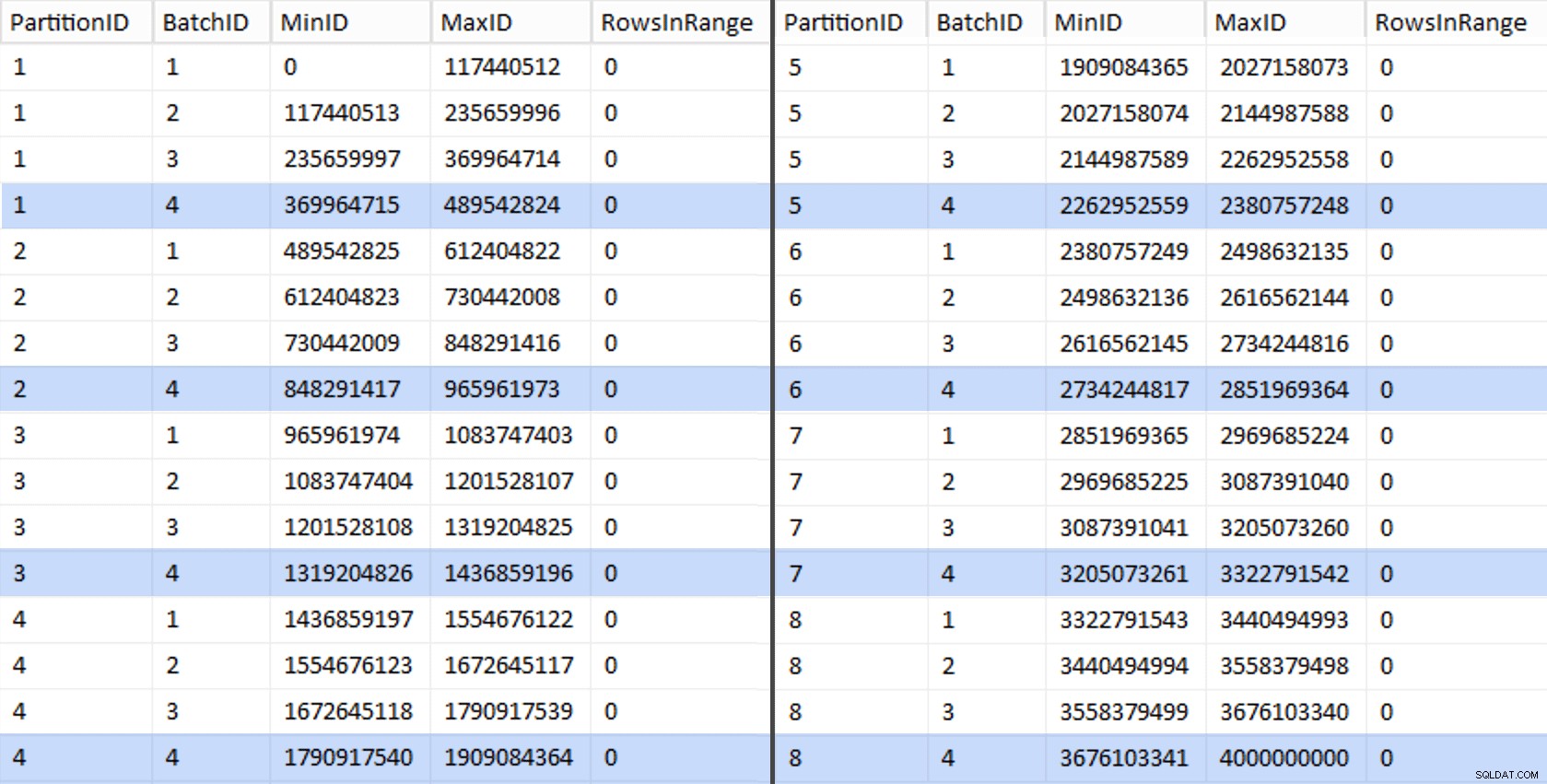
För att testa vårt arbete kan vi härleda en uppsättning frågor som uppdaterar BatchQueue med faktiska radantal från tabellen.
DECLARE @sql nvarchar(max) =N''; VÄLJ @sql +='UPPDATERA dbo.BatchQueue SET RowsInRange =( VÄLJ ANTAL(*) FRÅN dbo.tblOriginal MED (NOLOCK) WHERE CostID MELLAN ' + RTRIM(MinID) + ' OCH ' + RTRIM(MaxID) + ') WHERE MinID =' + RTRIM(MinID) + ' OCH MaxID =' + RTRIM(MaxID) + ';'FRÅN dbo.BatchQueue; EXEC sys.sp_executesql @sql;
Detta tog cirka 6 minuter på mitt system. Sedan kan du köra följande fråga för att visa att varje batch utom den allra sista kan fylla radgrupper fullt ut och inte lämna någon återstod för potentiell deltabutiksanvändning:
ÄNDRA TABELL dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Nu ser tabellen ut så här:
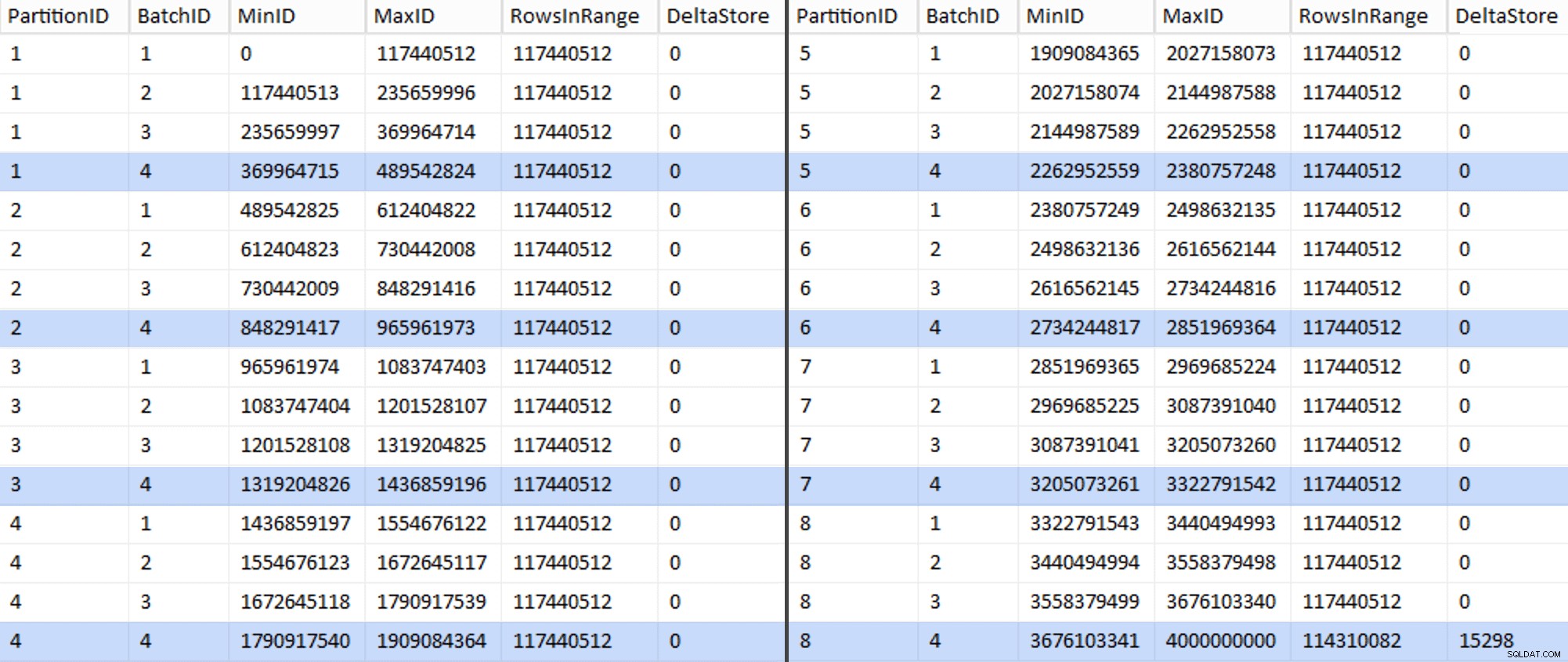
Visst har varje batch de beräknade 117 440 512 miljoner raderna, förutom den sista som, åtminstone idealiskt, kommer att innehålla vårt enda okomprimerade deltalager. Vi kan förmodligen förhindra detta också, genom att bara ändra batchstorleken något för den här partitionen så att alla fyra satser körs med samma storlek, eller genom att ändra antalet satser för att ta emot någon annan multipel av 102 400 eller 1 048 576. Eftersom det skulle kräva att man skaffar ny OID värden från bastabellen, vilket lägger till ytterligare 25 minuter plus till vår migreringsansträngning, jag tänker låta denna ena ofullkomliga partition glida — speciellt eftersom vi inte får den fulla arkivkomprimeringens fördelar av det ändå.
BatchQueue Tabellen börjar visa tecken på att vara användbar för att bearbeta våra batcher för att migrera data till vår nya, partitionerade, klustrade kolumnlagertabell. Som vi måste skapa, nu när vi känner till gränserna. Det finns bara 7 gränser, så du kan säkert göra detta manuellt, men jag gillar att få dynamisk SQL att göra mitt arbete för mig:
DECLARE @sql nvarchar(max) =N''; VÄLJ @sql =N'SKAPA PARTITIONSFUNKTION PF_OID([bigint])SOM OMRÅDE KVAR FÖR VÄRDEN ( ' + STRING_AGG(MaxID, ', ') + ');' FRÅN dbo.BatchQueue WHERE PartitionID <8 OCH BatchID =4; PRINT @sql;-- EXEC sys.sp_executesql @sql;
Resultat:
SKAPA PARTITIONSFUNKTION PF_OID([bigint])SOM OMRÅDE KVAR FÖR VÄRDEN ( 489542824, 965961973, 1436859196, 1909084364, 23807572518, 3422pre, 965961973, 965961973, 1436859196, 1909084364, 23807572518, 34328, 9122, 9922, 9922, 3922448, 23807572518;När det väl har skapats kan vi skapa vårt partitionsschema och tilldela varje efterföljande partition till dess dedikerade fil:
SKAPA PARTITIONSSCHEMA PS_OID SOM PARTITION PF_OID TILL ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8);Nu kan vi skapa tabellen och göra den redo för migrering:
CREATE TABLE dbo.tblPartitionedCCI( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar( 128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, NULL , NM4 numerisk(24,12) NULL, IN5 int NULL, NM5 numerisk(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BI6 bigint NULL, , NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- måste skapa en PK-restriktion på partitionsschemat... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) PÅ PS_OID(OID)); -- ... bara för att släppa det omedelbart...ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;GO -- ... så att vi kan ersätta det med CCI:CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part PÅ dbo.tblPartitionedCCI PÅ PS_OID(OID );GO -- bygg nu om med den komprimering vi vill ha:ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION =ALLA MED ( DATA_COMPRESSION =COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TILL 7), DATA_COMPRESSION =COLUMNSTORE (8) PARTITIONS); I del 3 kommer jag att ytterligare konfigureraBatchQueuetabell, bygga en procedur för processer för att skicka data till den nya strukturen och analysera resultaten.[ Del 1 | Del 2 | Del 3 ]