Detta är en del av en SQL Server Internals Problematic Operators-serie. Se till att läsa Kalens första inlägg och andra inlägg om detta ämne.
SQL Server har funnits i över 30 år och jag har arbetat med SQL Server nästan lika länge. Jag har sett många förändringar under åren (och decennier!) och versioner av denna otroliga produkt. I dessa inlägg kommer jag att dela med mig av hur jag ser på några av funktionerna eller aspekterna av SQL Server, ibland tillsammans med lite historiskt perspektiv.
Förra gången pratade jag om att hasha i en SQL Server-frågeplan som en potentiellt problematisk operatör i SQL-serverdiagnostik. Hashing används ofta för kopplingar och aggregering när det inte finns något användbart index. Och precis som skanningar (som jag pratade om i det första inlägget i den här serien) finns det tillfällen då hash faktiskt är ett bättre val än alternativen. För hash joins är ett av alternativen LOOP JOIN, som jag också berättade om förra gången.
I det här inlägget kommer jag att berätta om ett annat alternativ för hash. De flesta av alternativen till hash kräver att data sorteras, så antingen måste planen inkludera en SORT-operatör eller så måste den nödvändiga informationen redan vara sorterad på grund av befintliga index.
Olika typer av kopplingar för SQL Server Diagnostics
För JOIN-operationer är den vanligaste och mest användbara typen av JOIN en LOOP JOIN. Jag beskrev algoritmen för en LOOP JOIN i föregående inlägg. Även om själva data inte behöver sorteras för en LOOP JOIN, gör närvaron av ett index på den inre tabellen sammanfogningen mycket mer effektiv och som du borde veta, innebär närvaron av ett index viss sortering. Medan ett klustrat index sorterar själva data, sorterar ett icke-klustrat index indexnyckelkolumnerna. Faktum är att i de flesta fall, utan indexet, kommer SQL Servers optimerare att välja att använda HASH JOIN-algoritmen. Vi såg detta i exemplet förra gången, att utan index valdes HASH JOIN, och med index fick vi en LOOP JOIN.
Den tredje typen av join är en MERGE JOIN. Denna algoritm fungerar på två redan sorterade datamängder. Om vi försöker kombinera (eller JOIN) två uppsättningar data som redan är sorterade, tar det bara ett enda pass genom varje uppsättning för att hitta de matchande raderna. Här är pseudokoden för sammanslagningsalgoritmen:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Även om MERGE JOIN är en mycket effektiv algoritm, kräver den att båda indatauppsättningarna sorteras efter join-nyckeln, vilket vanligtvis innebär att ha ett klustrat index på join-nyckeln för båda tabellerna. Eftersom du bara får ett klustrat index per tabell, kanske det inte är det bästa övergripande valet för klustringsnyckel att välja kolumnen för klustrade nyckel bara för att tillåta MERGE JOINS.
Så vanligtvis rekommenderar jag inte att du försöker bygga index bara i syfte att MERGE JOINS, men om du får en MERGE JOIN på grund av redan befintliga index, är det vanligtvis bra. Förutom att kräva att båda indatauppsättningarna sorteras, kräver MERGE JOIN också att minst en av datamängderna har unika värden för sammanfogningsnyckeln.
Låt oss titta på ett exempel. Först återskapar vi Rubrikerna och Detaljer tabeller:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Titta sedan på planen för en sammanfogning mellan dessa tabeller:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Här är planen:

Observera att även med ett klustrat index på båda tabellerna får vi en HASH JOIN. Vi kan bygga om ett av indexen så att det blir UNIKT. I det här fallet måste det vara indexet på Rubrikerna tabell, eftersom det är den enda som har unika värden för SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Kör nu frågan igen och lägg märke till att planen fungerar som en MERGE JOIN.

Dessa planer tjänar på att ha uppgifterna redan sorterade i ett index, eftersom exekveringsplanen kan dra fördel av sorteringen. Men ibland måste SQL Server göra sortering som en del av sin frågekörning. Du kan ibland se en SORT-operatör dyka upp i en plan även om du inte ber om sorterad utdata. Om SQL Server anser att en MERGE JOIN kan vara ett bra alternativ, men en av tabellerna inte har det lämpliga klustrade indexet och den är tillräckligt liten för att göra sorteringen mycket billig, kan en SORTERING utföras för att låta MERGE JOIN vara används.
Men vanligtvis dyker SORT-operatorn upp i frågor där vi har bett om sorterad data med ORDER BY, som i följande exempel.
SELECT * FROM Details
ORDER BY ProductID;
GO

Det klustrade indexet skannas (vilket är samma sak som att skanna tabellen) och sedan sorteras raderna enligt önskemål.
Hantera redan sorterat klustrade index
Men vad händer om data redan är sorterade i ett klustrade index och frågan innehåller en ORDER BY i kolumnen med klustrade nyckel? I exemplet ovan byggde vi ett klustrat index på SalesOrderID i tabellen Detaljer. Titta på följande två frågor:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Om vi kör dessa frågor tillsammans, visar Quest Spotlight Tuning Pack Analysis Window att de två planerna har samma kostnad; var och en är 50 % av det totala. Så vad är egentligen skillnaden mellan dem?
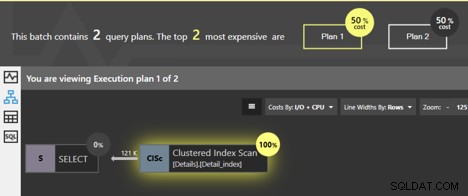
Båda frågorna skannar det klustrade indexet och SQL Server vet att om sidorna på bladnivån följs i ordning, kommer data att komma tillbaka i klustrad nyckelordning. Ingen ytterligare sortering behöver göras, så ingen SORT-operatör läggs till i planen. Men det ÄR en skillnad. Vi kan klicka på Clustered Index Scan-operatören och kommer att få lite detaljerad information.
Titta först på den detaljerade informationen för den första planen, för frågan utan ORDER BY.

Detaljerna berättar att egenskapen "Beställd" är falsk. Här finns inget krav på att uppgifterna ska returneras i sorterad ordning. Det visar sig att i de flesta fall är det enklaste sättet att hämta informationen att följa sidorna i det klustrade indexet, så att data kommer att returneras i ordning, men det finns ingen garanti. Vad egenskapen False betyder är att det inte finns något krav på att SQL Server följer de ordnade sidorna för att returnera resultatet. Det finns faktiskt andra sätt som SQL Server kan få alla rader för tabellen, utan att följa det klustrade indexet. Om SQL Server under körningen väljer att använda en annan metod för att hämta raderna, skulle vi inte se ordnade resultat.
För den andra frågan ser detaljerna ut så här:
 Eftersom frågan inkluderade en ORDER BY, FINNS det ett krav att data returneras i sorterad ordning och SQL Server kommer att följa sidorna i det klustrade indexet, i ordning.
Eftersom frågan inkluderade en ORDER BY, FINNS det ett krav att data returneras i sorterad ordning och SQL Server kommer att följa sidorna i det klustrade indexet, i ordning.
Det viktigaste att komma ihåg här är att INGEN garanti för sorterad data om du inte inkluderar ORDER BY i din fråga. Bara för att du har ett klusterindex finns det fortfarande ingen garanti! Även om du varenda gång förra året som du körde frågan, fick informationen tillbaka i ordning utan BESTÄLLNING AV, finns det ingen garanti för att du kommer att fortsätta att få tillbaka uppgifterna i ordning. Att använda ORDER BY är det enda sättet att garantera i vilken ordning dina resultat returneras.
Tips för att använda sorteringsoperationer
Så, är en SORTERING en operation som bör undvikas i SQL-serverdiagnostik? Precis som skanningar och hashoperationer är svaret naturligtvis "det beror på". Sortering kan bli mycket dyrt, särskilt på stora datamängder. Korrekt indexering hjälper SQL Server att undvika att utföra SORT-operationer eftersom ett index i princip betyder att din data är försorterad. Men indexering kommer med en kostnad. Det finns lagringskostnad, förutom underhållskostnad, för varje index. Om din data är kraftigt uppdaterad måste du hålla antalet index till ett minimum.
Om du upptäcker att några av dina långsamma frågor visar SORT-operationer i sina planer, och om dessa SORT:er är bland de dyraste operatörerna i planen, kan du överväga att bygga index som tillåter SQL Server att undvika sorteringen. Men du måste göra grundliga tester för att säkerställa att de ytterligare indexen inte saktar ner andra frågor som är avgörande för din övergripande applikationsprestanda.