Jag nämnde kort att batchlägesdata normaliseras i min senaste artikel Batch Mode Bitmaps i SQL Server. All data i en batch representeras av ett värde på åtta byte i just detta normaliserade format, oavsett den underliggande datatypen.
Det uttalandet väcker utan tvekan en del frågor, inte minst om hur data med en längd mycket större än åtta byte möjligen kan lagras på det sättet. Den här artikeln utforskar den normaliserade representationen av batchdata, förklarar varför inte alla datatyper på åtta byte får plats inom 64 bitar, och visar ett exempel på hur allt detta påverkar prestanda i batchläge.
Demo
Jag ska börja med ett exempel som visar att batchdataformat gör en viktig skillnad för en exekveringsplan. Du behöver SQL Server 2016 (eller senare) och Developer Edition (eller motsvarande) för att återskapa resultaten som visas här.
Det första vi behöver är en tabell med bigint nummer från 1 till 102 400 inklusive. Dessa siffror kommer att användas för att fylla i en kolumnlagertabell inom kort (antalet rader är det minsta som krävs för att få ett enda komprimerat segment).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Lyckad sammanlagd pushdown
Följande skript använder siffertabellen för att skapa en annan tabell som innehåller samma siffror förskjuten med ett specifikt värde. Den här tabellen använder kolumnlager för sin primära lagring för att producera batchlägeskörning senare.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Kör följande testfrågor mot den nya columnstore-tabellen:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Tillägget i SUM är att undvika översvämning. Du kan hoppa över WHERE klausuler (för att undvika en trivial plan) om du kör SQL Server 2017.
Alla dessa frågor drar nytta av sammanlagd pushdown. Summan beräknas vid Columnstore Index Scan snarare än batchläget Hash Aggregate operatör. Planer efter utförande visar noll rader som sänds ut av skanningen. Alla 102 400 rader var "lokalt aggregerade".
SUM planen visas nedan som ett exempel:

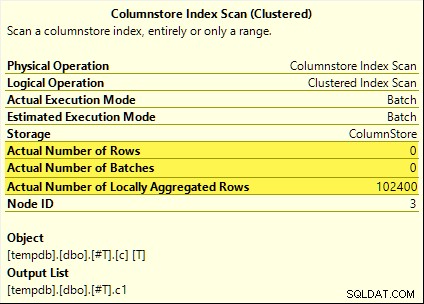
Mislyckad sammanlagd pushdown
Släpp nu och återskapa kolumnarkivets testtabell med förskjutningen minskad med en:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Kör exakt samma samlade pushdown-testfrågor som tidigare:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Den här gången bara COUNT_BIG aggregate uppnår aggregerad pushdown (endast SQL Server 2017). MAX och SUM aggregat gör det inte. Här är den nya SUM plan för jämförelse med den från det första testet:

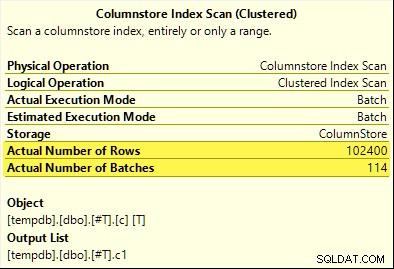
Alla 102 400 rader (i 114 batcher) sänds ut av Columnstore Index Scan , bearbetad av Compute Scalar , och skickas till Hash Aggregate .
Varför skillnaden? Allt vi gjorde var att kompensera intervallet för nummer som lagrats i kolumnlagringstabellen med ett!
Förklaring
Jag nämnde i inledningen att inte alla åtta-byte datatyper får plats i 64 bitar. Detta faktum är viktigt eftersom många kolumnlagrings- och batchlägesprestandaoptimeringar bara fungerar med data som är 64 bitar stora. Aggregerad pushdown är en av dessa saker. Det finns många fler prestandafunktioner (inte alla dokumenterade) som fungerar bäst (eller alls) bara när data ryms i 64 bitar.
I vårt specifika exempel är sammanlagd pushdown inaktiverad för ett columnstore-segment när det innehåller även ett datavärde som inte får plats i 64 bitar. SQL Server kan bestämma detta från metadata för lägsta och högsta värde som är associerade med varje segment utan att kontrollera all data. Varje segment utvärderas separat.
Aggregerad pushdown fungerar fortfarande för COUNT_BIG aggregeras endast i det andra testet. Detta är en optimering som lagts till någon gång i SQL Server 2017 (mina tester kördes på CU16). Det är logiskt att inte inaktivera aggregerad pushdown när vi bara räknar rader och inte gör något med de specifika datavärdena. Jag kunde inte hitta någon dokumentation för denna förbättring, men det är inte så ovanligt nuförtiden.
Som en sidoanteckning märkte jag att SQL Server 2017 CU16 möjliggör sammanlagd pushdown för de tidigare ej stödda datatyperna real , float , datetimeoffset och numeric med mer precision än 18 — när data ryms i 64 bitar. Detta är också odokumenterat i skrivande stund.
Ok, men varför?
Du kanske ställer den mycket rimliga frågan:Varför fungerar en uppsättning bigint testvärden passar tydligen i 64 bitar men det andra inte?
Om du gissade att orsaken var relaterad till NULL , ge dig själv en bock. Även om testtabellkolumnen är definierad som NOT NULL , använder SQL Server samma normaliserade datalayout för bigint om uppgifterna tillåter nollor eller inte. Det finns anledningar till detta, som jag kommer att packa upp bit för bit.
Låt mig börja med några observationer:
- Varje kolumnvärde i en batch lagras i exakt åtta byte (64 bitar) oavsett den underliggande datatypen. Denna layout med fast storlek gör allt enklare och snabbare. Batchlägesutförande handlar om hastighet.
- En batch är 64 kB stor och innehåller mellan 64 och 900 rader, beroende på antalet kolumner som projiceras. Detta är vettigt med tanke på att kolumndatastorlekarna är fixerade till 64 bitar. Fler kolumner betyder att färre rader får plats i varje 64KB batch.
- Alla SQL Server-datatyper får inte plats i 64 bitar, inte ens i princip. En lång sträng (för att ta ett exempel) kanske inte ens får plats i en hel 64KB batch (om det var tillåtet), än mindre en enda 64-bitars post.
SQL Server löser det sista problemet genom att lagra en 8-byte referens till data större än 64 bitar. Det "stora" datavärdet lagras någon annanstans i minnet. Du kan kalla detta arrangemang "off-row" eller "out-of-batch" lagring. Internt kallas det djupa data .
Nu kan datatyper på åtta byte inte rymmas i 64 bitar när de är nullbara. Ta bigint NULL till exempel . Dataintervallet som inte är null kan kräva hela 64 bitar, och vi behöver fortfarande en bit till för att indikera null eller inte.
Lösa problemen
Den kreativa och effektiva lösningen på dessa utmaningar är att reservera den lägsta signifikanta biten (LSB) av 64-bitarsvärdet som en flagga. Flaggan indikerar in-batch datalagring när LSB är ren (ställ till noll). När LSB är inställd (till en) kan det betyda en av två saker:
- Värdet är null; eller
- Värdet lagras off-batch (det är djupdata).
Dessa två fall särskiljs av tillståndet för de återstående 63 bitarna. När de är alla noll , värdet är NULL . Annars är "värdet" en pekare till djupa data lagrade någon annanstans.
När det ses som ett heltal innebär inställning av LSB att pekare till djupa data alltid är udda tal. Nollor representeras av det (udda) talet 1 (alla andra bitar är noll). In-batch-data representeras av jämnt siffror eftersom LSB är noll.
Detta gör inte innebär att SQL Server bara kan lagra jämna nummer inom en batch! Det betyder bara att den normaliserade representationen av de underliggande kolumnvärdena kommer alltid att ha en noll LSB när de lagras "in-batch". Detta kommer att bli mer vettigt på ett ögonblick.
Satsdatanormalisering
Normalisering utförs på olika sätt, beroende på den underliggande datatypen. För bigint processen är:
- Om data är null , lagra värdet 1 (endast LSB set).
- Om värdet kan representeras i 63 bitar , flytta alla bitarna ett ställe till vänster och nollställ LSB. När man ser på värdet som ett heltal betyder det fördubbling värdet. Till exempel
bigintvärde 1 är normaliserat till värdet 2. I binärt format är det sju byte helt noll följt av00000010. LSB som är noll indikerar att detta är data lagrad inline. När SQL Server behöver det ursprungliga värdet, skiftar den 64-bitarsvärdet med en position åt höger (kastar bort LSB-flaggan). - Om värdet inte kan representeras i 63 bitar, värdet lagras off-batch som djupdata . In-batch-pekaren har LSB-inställningen (gör det till ett udda nummer).
Processen att testa om en bigint värdet får plats i 63 bitar är:
- Lagra den råa*
bigintvärde i 64-bitars processorregisterr8. - Lagra dubbla värdet av
r8i registretrax. - Skift bitarna i
raxen plats till höger. - Testa om värdena i
raxochr8är lika.
* Observera att råvärdet inte kan bestämmas tillförlitligt för alla datatyper genom en T-SQL-konvertering till en binär typ. T-SQL-resultatet kan ha en annan byteordning och kan även innehålla metadata t.ex. time bråkdelssekundprecision.
Om testet i steg 4 godkänns vet vi att värdet kan fördubblas och sedan halveras inom 64 bitar – och det ursprungliga värdet bevaras.
Ett reducerat intervall
Resultatet av allt detta är att intervallet bigint värden som kan lagras i batch är minskade med en bit (eftersom LSB inte är tillgänglig). Följande intervall för bigint värden kommer att lagras off-batch som djupa data :
- -4,611,686,018,427,387,905 till -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 till +9,223,372,036,854,775,807
I gengäld för att acceptera att dessa bigint intervallbegränsningar, normalisering tillåter SQL Server att lagra (de flesta) bigint värden, nollvärden och djupa datareferenser i-batch . Detta är mycket enklare och mer utrymmeseffektivt än att ha separata strukturer för nollbarhet och djupa datareferenser. Det gör också att bearbeta batchdata med SIMD-processorinstruktioner mycket enklare.
Normalisering av andra datatyper
SQL Server innehåller normalisering kod för var och en av de datatyper som stöds av körning av batchläge. Varje rutin är optimerad för att hantera den inkommande binära layouten effektivt och för att bara skapa djupa data när det behövs. Normalisering resulterar alltid i att LSB reserveras för att indikera noll- eller djupdata, men layouten för de återstående 63 bitarna varierar per datatyp.
Alltid i batch
Normaliserade data för följande datatyper lagras alltid i batch eftersom de aldrig behöver mer än 63 bitar:
datetime(n)– skalas om internt tilltime(7)datetime2(n)– skalas om internt tilldatetime2(7)integersmallinttinyintbit– användertinyintimplementering.smalldatetimedatetimerealfloatsmallmoney
Det beror på
Följande datatyper kan lagras in-batch- eller djupdata beroende på datavärdet:
bigint– som beskrivits tidigare.money– samma intervall i batch sombigintmen dividerat med 10 000.numeric/decimal– 18 decimalsiffror eller färre i batch oavsett av deklarerad precision. Till exempeldecimal(38,9)värde -999999999.999999999 kan representeras som 8-byte heltal -9999999999999999999 (f21f494c589c0001hex), som kan dubblas till -19999999999999999998 (e43e9298b1380002hex) reversibelt inom 64 bitar. SQL Server vet var decimaltecknet går från datatypskalan.datetimeoffset(n)– in-batch om körtidsvärdet kommer att passa in idatetimeoffset(2)oavsett av deklarerad bråksekunders precision.timestamp– internt format skiljer sig från displayen. Till exempel entimestampvisas från T-SQL som0x000000000099449Arepresenteras internt som9a449900 00000000(i hex). Detta värde lagras som djupdata eftersom det inte ryms i 64-bitar när det dubbleras (vänsterskiftat en bit).
Alltid djup data
Följande lagras alltid som djupdata (förutom null) :
uniqueidentifiervarbinary(n)– inklusive(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameinklusive(max)– dessa typer kan också använda en ordbok (när den är tillgänglig).text/ntext/image/xml– användervarbinary(n)implementering.
För att vara tydlig, noll för alla batch-mode-kompatibla datatyper lagras i batch som specialvärdet "one".
Slutliga tankar
Du kan förvänta dig att göra det bästa av de tillgängliga kolumnlagrings- och batchlägesoptimeringarna när du använder datatyper och värden som ryms i 64 bitar. Du kommer också att ha störst chans att dra nytta av inkrementella produktförbättringar över tid, till exempel de senaste förbättringarna av aggregerad pushdown som noteras i huvudtexten. Alla prestandafördelar kommer inte att vara så synliga i genomförandeplaner, eller ens dokumenterade. Ändå kan skillnaderna vara extremt betydande.
Jag bör också nämna att data normaliseras när en rad-lägesexekveringsplanoperatör tillhandahåller data till en batch-mode-förälder, eller när en non-columnstore-skanning producerar batcher (batch-läge på rowstore). Det finns en osynlig rad-till-batch-adapter som anropar lämplig normaliseringsrutin för varje kolumnvärde innan det läggs till i batchen. Att undvika datatyper med komplicerad normalisering och djup datalagring kan ge prestandafördelar även här.