Introduktion
Att lagra data är en sak; lagra meningsfull, användbar, rätt data är en helt annan. Även om mening och nytta i sig är subjektiva egenskaper, kan åtminstone korrekthet definieras logiskt och framtvingas. Typer säkerställer redan att siffror är siffror och datum är datum, men kan inte garantera att vikt eller avstånd är positiva siffror eller förhindrar att datumintervall överlappar. Tuppel-, tabell- och databasbegränsningar tillämpar regler på data som lagras och avvisar värden eller kombinationer av värden som inte klarar samlingen.
Restriktioner gör inte andra indatavalideringstekniker värdelösa på något sätt, även när de testar samma påståenden. Tid som ägnas åt att försöka och misslyckas med att lagra ogiltiga data är bortkastad tid. Överträdelsemeddelanden, som assert i system och applikationsprogrammeringsspråk, avslöjar bara det första problemet med den första kandidatposten mycket mer detaljerat än någon som inte omedelbart är involverad i databasens behov. Men när det gäller uppgifternas riktighet är begränsningar lag, på gott och ont; allt annat är råd.
På Tuples:Not Null, Default och Check
Icke-null-begränsningar är den enklaste kategorin. En tupel måste ha ett värde för det begränsade attributet, eller uttryckt på annat sätt, uppsättningen tillåtna värden för kolumnen inkluderar inte längre den tomma uppsättningen. Inget värde betyder ingen tupel:infogningen eller uppdateringen avvisas.
Att skydda mot nollvärden är lika enkelt som att förklara column_name COLUMN_TYPE NOT NULL i CREATE TABLE eller ADD COLUMN . Nullvärden orsakar hela kategorier av problem mellan databasen och slutanvändare, så att reflexmässigt definiera icke-null-begränsningar på en kolumn utan en god anledning att tillåta nollvärden är en bra vana att börja använda.
Tillhandahållande av ett standardvärde om inget anges (genom att utelämna eller en explicit NULL). ) i en infogning eller uppdatering anses inte alltid vara en begränsning, eftersom kandidatposter ändras och lagras istället för att avvisas. I många DBMS kan standardvärden genereras av en funktion, även om MySQL inte tillåter användardefinierade funktioner för detta ändamål.
Alla andra valideringsregel som bara beror på värdena inom en enda tupel kan implementeras som en CHECK begränsning. På sätt och vis NOT NULL i sig är en förkortning för CHECK (column_name IS NOT NULL); felmeddelandet mottaget i strid gör den största skillnaden. CHECK , dock kan tillämpa och framtvinga sanningen av vilket booleskt predikat som helst över en enda tupel. Till exempel bör en tabell som lagrar geografiska platser CHECK (latitude >= -90 AND latitude < 90) , och på liknande sätt för longitud mellan -180 och 180 - eller, om tillgängligt, använd och validera en GEOGRAPHY datatyp.
På tabeller:Unik och uteslutning
Begränsningar på tabellnivå testar varandra. I en unik begränsning kan endast en post ha en given uppsättning värden för de begränsade kolumnerna. Nullbarhet kan orsaka problem här, eftersom NULL är aldrig lika med något annat, upp till och inklusive NULL sig. En unik begränsning på (batman, robin) tillåter därför oändliga kopior av vilken Robinless Batman som helst.
Exkluderingsbegränsningar stöds endast i PostgreSQL och DB2, men fyller en mycket användbar nisch:de kan förhindra överlappningar. Ange de begränsade fälten och de operationer som var och en ska utvärderas med, och en ny post kommer bara att accepteras om ingen befintlig post jämförs med varje fält och operation. Till exempel ett schedules Tabell kan konfigureras för att avvisa konflikter:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Upprätta operationer som PostgreSQL:s ON CONFLICT sats eller MySQL:s ON DUPLICATE KEY UPDATE använd en begränsning på tabellnivå för att upptäcka konflikter. Och som icke-null-begränsningar kan uttryckas som CHECK begränsningar, en unik begränsning kan uttryckas som en uteslutningsbegränsning för jämlikhet.
Den primära nyckeln
Unika begränsningar har ett särskilt användbart specialfall. Med en ytterligare icke-null-begränsning på den eller de unika kolumnerna, kan varje post i tabellen identifieras enskilt med sina värden för de begränsade kolumnerna, som gemensamt kallas en nyckel . Flera kandidatnycklar kan samexistera i en tabell, till exempel users fortfarande ibland att ha distinkt unik och icke-null email s och username s; men att deklarera en primärnyckel fastställer ett enda kriterium enligt vilket poster är offentligt och exklusivt kända. Vissa RDBMS:er organiserar till och med rader på sidor med primärnyckeln, för detta ändamål kallade ett klustrade index , för att göra sökning med primärnyckelvärden så snabb som möjligt.
Det finns två typer av primärnyckel. En naturlig nyckel definieras på en kolumn eller kolumner som "naturligt" ingår i tabellens data, medan en surrogatnyckel eller syntetisk nyckel uppfinns enbart i syfte att bli nyckeln. Naturliga nycklar kräver omsorg -- fler saker kan förändras än vad databasdesigner ofta ger upphov till, från namn till numreringsscheman. En uppslagstabell som innehåller lands- och regionnamn kan använda sina respektive ISO 3166-koder som en säker naturlig primärnyckel, men en users tabell med en naturlig nyckel baserad på föränderliga värden som namn eller e-postadresser skapar problem. När du är osäker, skapa en surrogatnyckel.
Om en naturlig nyckel sträcker sig över flera kolumner, bör en surrogatnyckel alltid åtminstone övervägas eftersom flerkolumnsnycklar kräver mer ansträngning att hantera. Om de naturliga nyckelfärgerna däremot passar, bör kolumner ordnas i ökande specificitet precis som de är i index:landskod då regionskod, snarare än tvärtom.
Surrogatnyckeln har historiskt sett varit en enda heltalskolumn, eller BIGINT där miljarder så småningom kommer att tilldelas. Relationsdatabaser kan automatiskt fylla surrogatnycklar med nästa heltal i en serie, en funktion som brukar kallas SERIAL eller IDENTITY .
En autoinkrementerande numerisk räknare är inte utan nackdelar:att lägga till poster med förgenererade nycklar kan orsaka konflikter, och om sekventiella värden exponeras för användare är det lätt för dem att gissa vilka andra giltiga nycklar kan vara. Universellt unika identifierare, eller UUID, undviker dessa svagheter och har blivit ett vanligt val för surrogatnycklar, även om de också är mycket större på sidan än ett enkelt nummer. Typerna v1 (MAC-adressbaserad) och v4 (pseudoslumpmässig) UUID används oftast.
I databasen:främmande nycklar
Relationsdatabaser implementerar endast en klass av flertabellsbegränsningar,
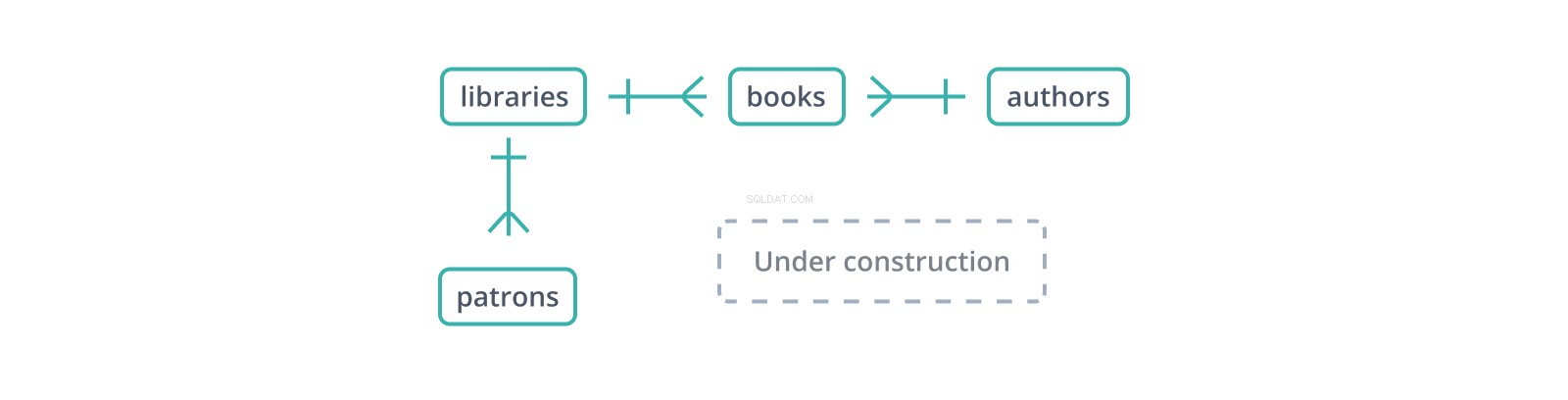
Detta informella "entity-relationship diagram" eller ERD visar början på ett schema för en databas med bibliotek och deras samlingar och beskyddare. Varje kant representerar ett förhållande mellan de tabeller den ansluter. Den | glyf anger en enda post på sin sida, medan "kråkfot"-glyfen representerar flera:ett bibliotek rymmer många böcker och har många besökare.
En främmande nyckel är en kopia av en annan tabells primärnyckel, kolumn för kolumn (en punkt till förmån för surrogatnycklar:endast en kolumn att kopiera och referera), med värden som länkar poster i den här tabellen till "överordnade" poster i den. I schemat ovan, books tabellen upprätthåller ett library_id främmande nyckel till libraries , som innehåller böcker och ett author_id till authors , som skriver dem. Men vad händer om en bok infogas med ett author_id som inte finns i authors ?
Om den främmande nyckeln inte är begränsad -- dvs det är bara en annan kolumn eller kolumner -- kan en bok ha en författare som inte finns. Det här är ett problem:om någon försöker följa länken mellan books och authors , de hamnar ingenstans. Om authors.author_id är ett seriellt heltal, finns det också möjligheten att ingen märker det förrän det falska author_id tilldelas så småningom, och du slutar med en viss kopia av Don Quijote tillskrivs först ingen känd och sedan till Pierre Menard, med Miguel Cervantes ingenstans att hitta.
Att begränsa den främmande nyckeln kan inte förhindra att en bok tillskrivs felaktigt om det felaktiga author_id peka på en befintlig post i authors , så andra kontroller och tester förblir viktiga. Men uppsättningen av befintliga främmande nyckelvärden är nästan alltid en liten delmängd av den möjliga främmande nyckel-värden, så främmande nyckel-begränsningar kommer att fånga och förhindra de flesta felaktiga värden. Med en främmande nyckel-begränsning, Quixote med en icke-existerande författare kommer att avvisas istället för att spelas in.
Är det här "Relational" i "Relational Database" kommer ifrån?
Främmande nycklar skapar relationer mellan tabeller, men tabeller som vi känner dem är matematiskt relationer bland uppsättningarna av möjliga värden för varje attribut. En enkel tuppel relaterar ett värde för kolumn A till ett värde för kolumn B och framåt. E.F. Codds originaltidning använder "relationell" i denna mening.
Detta har inte orsakat något slut på förvirring och kommer sannolikt att fortsätta att göra det i evighet.
För vissa korrekta värden
Det finns många fler sätt på vilka uppgifter kan vara felaktiga än vad som tas upp här. Begränsningar hjälper, men även de är bara så flexibla; många vanliga intra-tabellspecifikationer, som en gräns på två eller högre för antalet gånger ett värde tillåts visas i en kolumn, kan endast tillämpas med utlösare.
Men det finns också sätt på vilka själva strukturen i en tabell kan leda till inkonsekvenser. För att förhindra dessa måste vi samla både primära och främmande nycklar, inte bara för att definiera och validera utan för att normalisera relationerna mellan tabeller. Först har vi dock knappt skrapat på ytan av hur relationerna mellan tabeller definierar strukturen för själva databasen.