I ett färskt tips beskrev jag ett scenario där en SQL Server 2016-instans verkade kämpa med kontrollpunkter. Felloggen fylldes i med ett alarmerande antal FlushCache-poster som denna:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Jag var lite förbryllad över det här problemet, eftersom systemet verkligen inte var slö - massor av kärnor, 3 TB minne och XtremIO-lagring. Och inget av dessa FlushCache-meddelanden har någonsin parats med de kontrollanta 15 sekunders I/O-varningarna i felloggen. Ändå, om du staplar ett gäng databaser med höga transaktioner där, kan kontrollpunktsbearbetningen bli ganska trög. Inte så mycket på grund av den direkta I/O, utan mer avstämning som måste göras med ett enormt antal smutsiga sidor (inte bara från begärda transaktioner) utspridda över en så stor mängd minne och potentiellt väntar på lazywritern (eftersom det bara finns en för hela instansen).
Jag gjorde en snabb "fräschning" genom att läsa några mycket värdefulla inlägg:
- Hur fungerar kontrollpunkter och vad som loggas
- Databaskontrollpunkter (SQL-server)
- Vad gör checkpoint för tempdb?
- En SQL Server DBA-myt om dagen:(15/30) checkpoint skriver bara sidor från genomförda transaktioner
- FlushCache-meddelanden kanske inte är ett verkligt IO-stopp
- Indirekt kontrollpunkt och tempdb – den goda, den dåliga och den icke eftergivande schemaläggaren
- Ändra målåterställningstiden för en databas
- Hur det fungerar:När läggs FlushCache-meddelandet till i SQL Server Error Log?
- Ändringar i SQL Server 2016 Checkpoint Beteende
- Målåterställningsintervall och indirekt kontrollpunkt – ny standard på 60 sekunder i SQL Server 2016
- SQL 2016 – Det går bara snabbare:Indirekt kontrollpunkt som standard
- SQL-server:stort RAM-minne och DB Checkpointing
Jag bestämde mig snabbt för att jag ville spåra kontrollpunkters varaktigheter för några av dessa mer besvärliga databaser, före och efter att ha ändrat deras målåterställningsintervall från 0 (det gamla sättet) till 60 sekunder (det nya sättet). Tillbaka i januari lånade jag en Extended Events-session av vännen och andra kanadensiska Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Jag markerade tiden då jag ändrade varje databas och analyserade sedan resultaten från data för utökade händelser med hjälp av en fråga som publicerades i det ursprungliga tipset. Resultaten visade att efter att ha bytt till indirekta kontrollpunkter gick varje databas från kontrollpunkter på i genomsnitt 30 sekunder till kontrollpunkter på mindre än en tiondels sekund (och mycket färre kontrollpunkter i de flesta fall också). Det finns mycket att packa upp från den här grafiken, men det här är rådata som jag använde för att presentera mitt argument (klicka för att förstora):
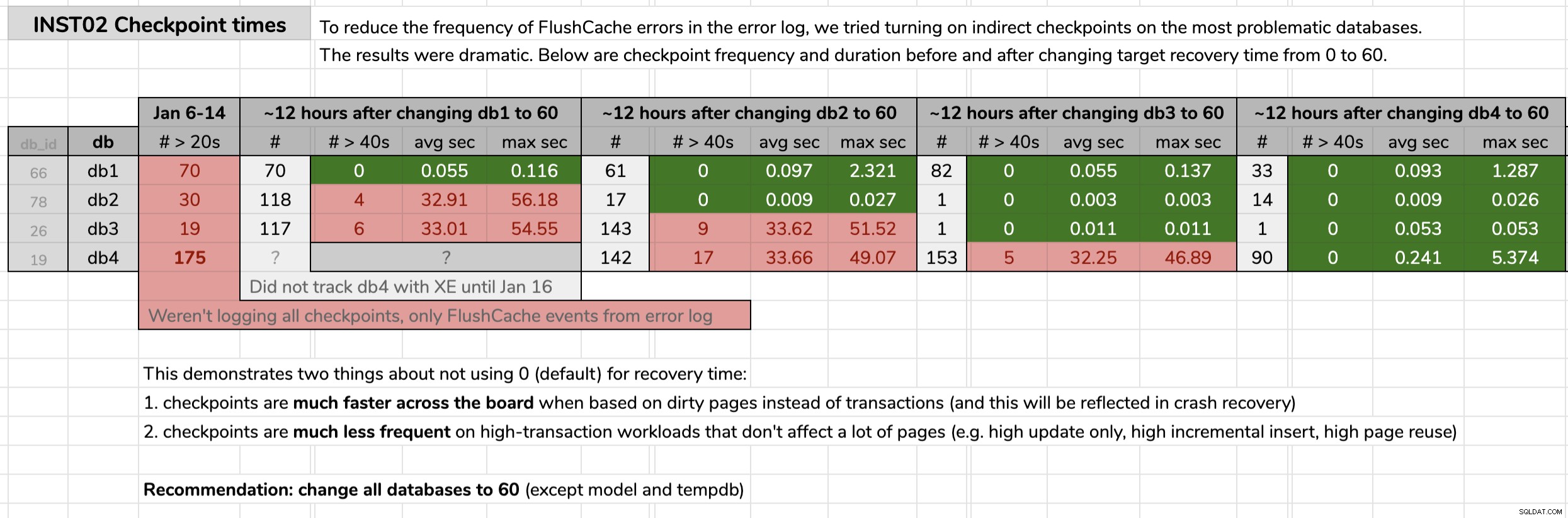 Mina bevis
Mina bevis
När jag väl bevisat mitt fall i dessa problematiska databaser fick jag grönt ljus att implementera detta i alla våra användardatabaser i hela vår miljö. I dev först, och sedan i produktion, körde jag följande via en CMS-fråga för att få en mätare för hur många databaser vi pratade om:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Några anteckningar om frågan:
database_id > 4
Jag ville inte trycka påmasteralls, och jag ville inte ändratempdbmen eftersom vi inte är på den senaste SQL Server 2017 CU (se KB #4497928 av en anledning att detalj är viktig). Det senare uteslutermodelockså, eftersom att ändra modell skulle påverkatempdbvid nästa failover/omstart. Jag kunde ha ändratmsdb, och jag kan gå tillbaka för att göra det någon gång, men mitt fokus här låg på användardatabaser.
[state] / is_read_only / is_in_standby
Vi måste se till att databaserna vi försöker ändra är online och inte skrivskyddade (jag träffade en som för närvarande var inställd på skrivskyddad, och kommer att behöva återkomma till den senare).
OUTER APPLY (...)
Vi vill begränsa våra åtgärder till databaser som antingen är primära i en AG eller inte i en AG alls (och som även måste ta hänsyn till distribuerade AG:er, där vi kan vara primära och lokala men ändå inte vara skrivbara) . Om du råkar köra kontrollen på en sekundär kan du inte åtgärda problemet där, men du bör fortfarande få en varning om det. Tack till Erik Darling för hjälpen med denna logik och Taylor Martell för motiverande förbättringar.
- Om du har instanser som kör äldre versioner som SQL Server 2008 R2 (jag hittade en!), måste du justera detta lite, eftersom
target_recovery_time_in_secondskolumnen finns inte där. Jag var tvungen att använda dynamisk SQL för att komma runt detta i ett fall, men du kan också tillfälligt flytta eller ta bort där dessa instanser hamnar i din CMS-hierarki. Du kan inte heller vara lat som jag och köra koden i Powershell istället för ett CMS-frågefönster, där du enkelt kan filtrera bort databaser med ett valfritt antal egenskaper innan du någonsin stöter på kompileringsproblem.
I produktionen fanns det 102 instanser (ungefär hälften) och totalt 1 590 databaser med den gamla inställningen. Allt fanns på SQL Server 2017, så varför var den här inställningen så utbredd? Eftersom de skapades innan indirekta kontrollpunkter blev standard i SQL Server 2016. Här är ett exempel på resultaten:
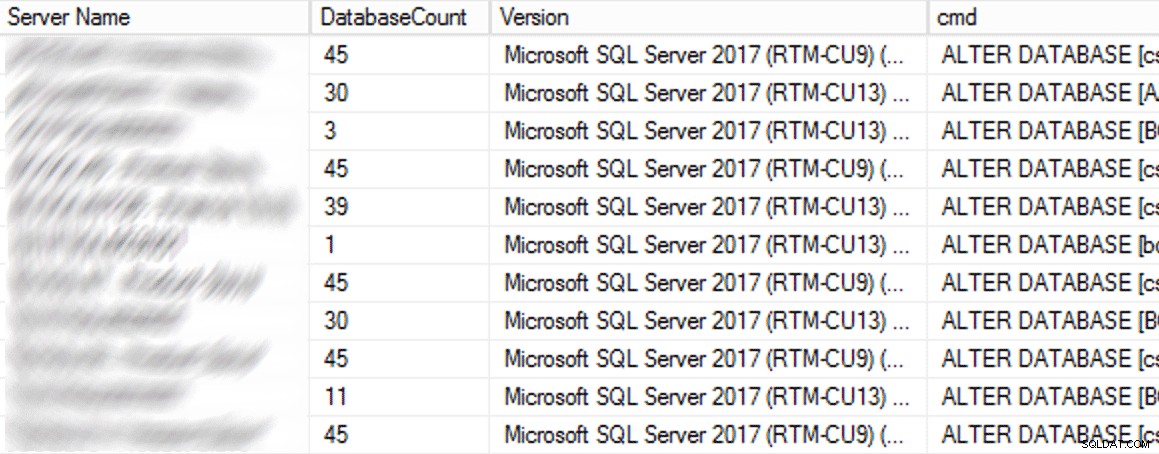 Delvis resultat från CMS-fråga.
Delvis resultat från CMS-fråga.
Sedan körde jag CMS-frågan igen, den här gången med sys.sp_executesql okommenterad. Det tog cirka 12 minuter att köra det över alla 1 590 databaser. Inom en timme fick jag redan rapporter om människor som observerade en betydande minskning av CPU:n i några av de mer trafikerade instanserna.
Jag har fortfarande mer att göra. Till exempel måste jag testa den potentiella påverkan på tempdb , och om det finns någon tyngd i vårt användningsfall till de skräckhistorier jag har hört. Och vi måste se till att 60 sekunders inställningen är en del av vår automatisering och alla förfrågningar om databasskapande, särskilt de som är skriptade eller återställda från säkerhetskopior.