Som konsult som arbetar med SQL Server blir jag många gånger ombedd att titta på en server som verkar ha prestandaproblem. Medan jag utför triage på servern ställer jag vissa frågor, såsom:vad är ditt normala CPU-användning, vad är dina genomsnittliga disklatenser, vad är ditt normala minnesutnyttjande och så vidare. Svaret är vanligtvis "vi vet inte" eller "vi samlar inte in den informationen regelbundet." Att inte ha en ny baslinje gör det mycket svårt att veta hur onormalt beteende ser ut. Om du inte vet vad normalt beteende är, hur vet du säkert om det är bättre eller sämre? Jag använder ofta uttrycken "om du inte övervakar det kan du inte mäta det" och "om du inte mäter det kan du inte hantera det."
Ur ett övervakningsperspektiv bör organisationer åtminstone övervaka för misslyckade jobb som säkerhetskopiering, indexunderhåll, DBCC CHECKDB och alla andra viktiga jobb. Det är enkelt att ställa in felmeddelanden för dessa; men du behöver också en process på plats för att se till att jobben fungerar som förväntat. Jag har sett jobb som blir hängande och aldrig slutförs. Ett felmeddelande skulle inte utlösa ett larm eftersom jobbet aldrig lyckas eller misslyckas.
Från en prestandabaslinje finns det flera nyckelmått som bör fångas. Jag har skapat en process som jag använder med klienter som fångar nyckelmått på regelbunden basis och lagrar dessa värden i en användardatabas. Min process är enkel:en dedikerad databas med lagrade procedurer som använder vanliga skript som infogar resultatuppsättningarna i tabeller. Jag har SQL Agent-jobb för att köra de lagrade procedurerna med jämna mellanrum och ett rensningsskript för att rensa data äldre än X dagar. De mätvärden jag alltid fångar inkluderar:
Sidlivslängd :PLE är förmodligen ett av de bästa sätten att mäta om ditt system är under internminnestryck. De flesta system har PLE-värden som fluktuerar under normala arbetsbelastningar. Jag gillar att trenda dessa värden för att veta vad de lägsta, genomsnittliga och högsta värdena är. Jag gillar att försöka förstå vad som fick PLE att sjunka under vissa tider på dygnet för att se om dessa processer kan ställas in. Många gånger gör någon en bordsskanning och spolar buffertpoolen. Att kunna indexera dessa frågor på rätt sätt kan hjälpa. Se bara till att du övervakar rätt PLE-räknare – se här .
CPU-användning :Att ha en baslinje för CPU-användning låter dig veta om ditt system plötsligt är under CPU-tryck. Ofta när en användare klagar på prestandaproblem, kommer de att observera att CPU ser hög ut. Till exempel, om CPU svävar runt 80 % kan de tycka att det är oroande, men om CPU var också 80 % under samma tid de föregående veckorna när inga problem rapporterades, är sannolikheten att CPU är problemet mycket låg. Trendig processor är inte bara till för att fånga när processorn ökar och håller sig på ett konsekvent högt värde. Jag har många berättelser om när jag hamnade i en konferensbro med svårighetsgrad ett eftersom det var ett problem med en ansökan. Eftersom jag var DBA bar jag hatten "Default Blame Acceptor". När applikationsteamet sa att det fanns ett problem med databasen var det upp till mig att bevisa att det inte var det, databasservern var skyldig tills oskyldig bevisats. Jag minns tydligt en incident där applikationsteamet var övertygat om att databasservern hade problem eftersom användare inte kunde ansluta. De hade läst på internet att SQL Server kunde lida av svält i trådpoolen om den vägrade anslutningar. Jag hoppade på servern och började titta på resurser och vilka processer som kördes just nu. Inom några minuter rapporterade jag tillbaka att servern i fråga var väldigt uttråkad. Baserat på vår baslinjestatistik var CPU vanligtvis 60 % och den var inaktiv runt 20 %, sidans förväntade livslängd var märkbart högre än normalt, och ingen låsning eller blockering hände, I/O såg bra ut, inga fel i några loggar och antalet sessioner var ungefär 1/3 av deras normala antal. Jag gjorde sedan kommentaren, "Det verkar som att användare inte ens når databasservern." Det fick nätverksfolkets uppmärksamhet och de insåg att en ändring de gjorde i belastningsutjämnaren inte fungerade korrekt och de fastställde att över 50 % av anslutningarna dirigerades felaktigt och inte kom till databasservern. Hade jag inte vetat vad grundlinjen var hade det tagit oss mycket längre tid att nå upplösningen.
Disk I/O :Att fånga diskmått är mycket viktigt. DMV sys.dm_io_virtual_file_stats är kumulativ sedan den senaste omstarten av servern. Att fånga dina I/O-latenser över ett tidsintervall ger dig en baslinje för vad som är normalt under den tiden. Att förlita sig på det kumulativa värdet kan ge dig skev data från aktiviteter efter kontorstid eller långa perioder där systemet varit inaktivt. Paul diskuterade det här .
Databasfilstorlekar :Att ha en inventering av dina databaser som inkluderar filstorlek, använd storlek, ledigt utrymme och mer kan hjälpa dig att förutse databasens tillväxt. Ofta blir jag ombedd att förutse hur mycket lagring som skulle behövas för en databasserver under det kommande året. Utan att känna till den veckovisa eller månatliga tillväxttrenden har jag inget sätt att på ett intelligent sätt komma fram till en siffra. När jag börjar spåra dessa värden kan jag trenda detta ordentligt. Förutom trending kunde jag också hitta när det var oväntad databastillväxt. När jag ser oväntad tillväxt och undersöker, upptäcker jag vanligtvis att någon antingen duplicerade en tabell för att göra några tester (ja, i produktion!) eller gjorde någon annan engångsprocess. Att spåra den här typen av data och att kunna svara när avvikelser uppstår hjälper till att visa att du är proaktiv och vakar över dina system.
Väntestatistik :Övervakning av väntestatistik kan hjälpa dig att börja ta reda på orsaken till vissa prestandaproblem. Många nya DBA:er blir oroliga när de först börjar undersöka väntestatistik och inte inser att väntetider alltid förekommer, och det är precis så som SQL Servers schemaläggningssystem fungerar. Det finns också en hel del väntan som kan anses vara godartade, eller för det mesta ofarliga. Paul Randal utesluter dessa mestadels ofarliga väntan i sitt populära manus för väntestatistik. Paul har också byggt ett stort bibliotek av de olika vänttyperna och låsklasser med beskrivningar och annan information om felsökning av väntan och låsningar.
Jag har dokumenterat min datainsamlingsprocess och du kan hitta koden på min blogg . Beroende på situationen och typen av problem som en kund kan ha, kanske jag också vill fånga ytterligare mätvärden. Glenn Berry bloggade om en process som han satt ihop som fångar genomsnittligt antal uppgifter, genomsnittligt antal körbara uppgifter, genomsnittligt antal väntande I/O-tal, CPU-användning i SQL Server-processen och genomsnittlig livslängd för alla NUMA-noder. En snabb internetsökning kommer att visa flera andra datainsamlingsprocesser som människor har delat, till och med SQL Server Tiger Team har en process som använder T-SQL och PowerShell.
Att använda en anpassad databas och bygga ditt eget datainsamlingspaket är en giltig lösning för att fånga en baslinje, men de flesta av oss sysslar inte med att bygga kompletta SQL Server-övervakningslösningar. Det finns mycket mer som skulle vara användbart att fånga, saker som långvariga frågor, toppfrågor och lagrade procedurer baserade på minne, I/O och CPU, dödlägen, indexfragmentering, transaktioner per sekund och mycket mer. För det rekommenderar jag alltid att kunder köper ett övervakningsverktyg från tredje part. Dessa leverantörer är specialiserade på att hålla sig uppdaterade om de senaste trenderna och funktionerna i SQL Server så att du kan fokusera din tid på att se till att SQL Server är så stabil och snabb som möjligt.
Lösningar som SQL Sentry (för SQL Server) och DB Sentry (för Azure SQL Database) fångar alla dessa mätvärden åt dig och låter dig enkelt skapa olika baslinjer. Du kan ha en normal baslinje, månadsslut, kvartalsslut och mer. Du kan sedan tillämpa baslinjen och se visuellt hur saker och ting är annorlunda. Ännu viktigare är att du kan konfigurera valfritt antal varningar för olika förhållanden och få ett meddelande när mätvärdena överskrider dina tröskelvärden.
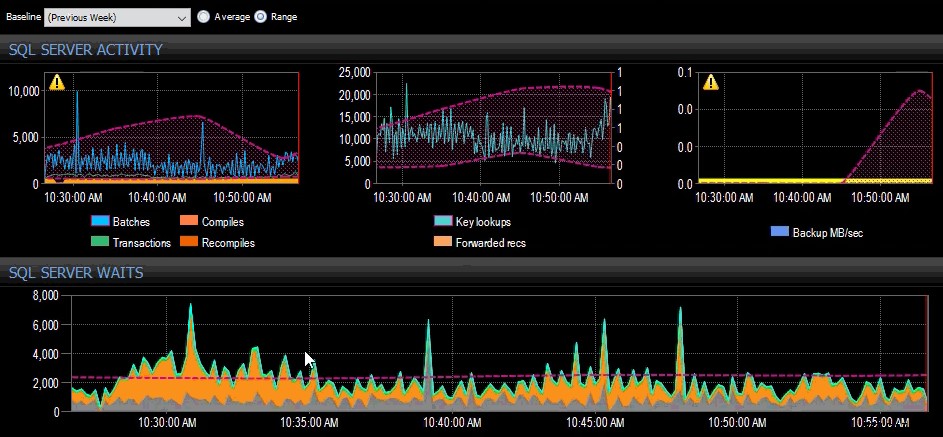 Förra veckans baslinje tillämpades på flera SQL Server-mått på SQL Sentry-instrumentpanelen.
Förra veckans baslinje tillämpades på flera SQL Server-mått på SQL Sentry-instrumentpanelen.
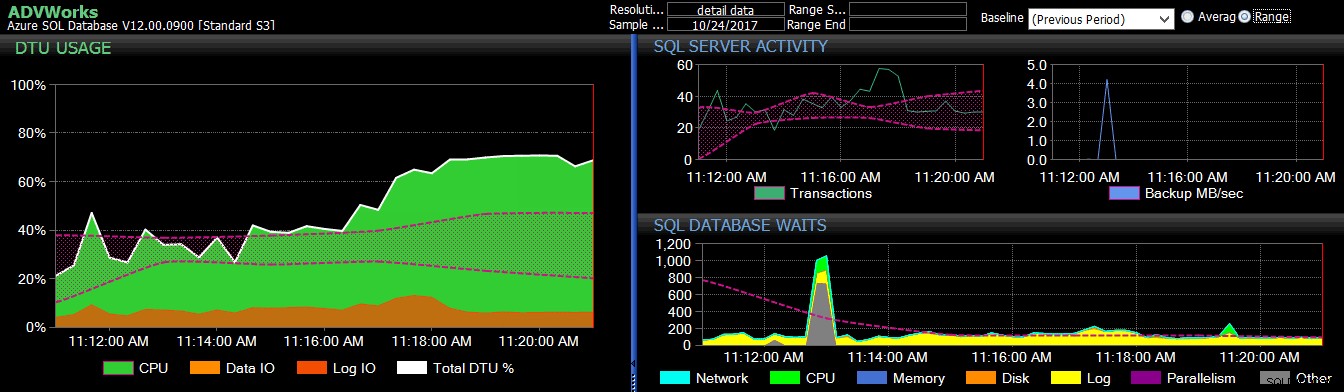 Föregående periods baslinje tillämpades på flera Azure SQL Database-mått på DB Sentry-instrumentpanelen.
Föregående periods baslinje tillämpades på flera Azure SQL Database-mått på DB Sentry-instrumentpanelen.
För mer information om baslinjer i SentryOne, se dessa inlägg på deras teamblogg eller denna 2 Minute Tuesday-video . Intresserad av att ladda ner en testversion? De har dig täckt där också .