Den här artikeln är den tredje i en serie om optimeringströsklar för gruppering och aggregering av data. I del 1 täckte jag den förbeställda Stream Aggregate-algoritmen. I del 2 täckte jag upp den icke-förbeställda Sort + Stream Aggregate-algoritmen. I den här delen täcker jag upp Hash Match (Aggregate) algoritmen, som jag helt enkelt kommer att referera till som Hash Aggregate. Jag ger också en sammanfattning och en jämförelse mellan de algoritmer jag tar upp i del 1, del 2 och del 3.
Jag kommer att använda samma exempeldatabas som heter PerformanceV3, som jag använde i de tidigare artiklarna i serien. Se bara till att innan du kör exemplen i artikeln kör du först följande kod för att släppa ett par onödiga index:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
De enda två indexen som ska finnas kvar i den här tabellen är idx_cl_od (klustrade med orderdate som nyckel) och PK_Orders (icke-klustrade med orderid som nyckel).
Hash Aggregate
Hash Aggregate-algoritmen organiserar grupperna i en hashtabell baserat på någon internt vald hashfunktion. Till skillnad från Stream Aggregate-algoritmen behöver den inte konsumera raderna i gruppordning. Betrakta följande fråga (vi kallar den fråga 1) som ett exempel (tvingar fram ett hashaggregat och en serieplan):
VÄLJ empid, COUNT(*) SOM siffror FRÅN dbo.Order GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Figur 1 visar planen för fråga 1.
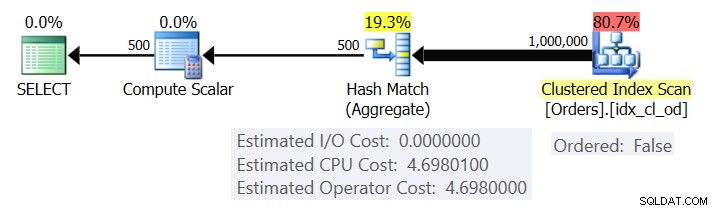
Figur 1:Plan för fråga 1
Planen skannar raderna från det klustrade indexet med hjälp av en Ordered:False-egenskap (genomsökning krävs inte för att leverera raderna ordnade av indexnyckeln). Normalt föredrar optimeraren att skanna det smalaste täckande indexet, vilket i vårt fall råkar vara det klustrade indexet. Planen bygger en hashtabell med de grupperade kolumnerna och aggregaten. Vår fråga begär en INT-typ COUNT aggregat. Planen beräknar det faktiskt som ett BIGINT-typat värde, därav Compute Scalar-operatorn, som tillämpar implicit konvertering på INT.
Microsoft delar inte offentligt de hashalgoritmer som de använder. Detta är mycket proprietär teknologi. Fortfarande, för att illustrera konceptet, låt oss anta att SQL Server använder hashfunktionen % 250 (modulo 250) för vår fråga ovan. Innan vi bearbetar några rader har vår hashtabell 250 hinkar som representerar de 250 möjliga resultaten av hashfunktionen (0 till 249). När SQL Server bearbetar varje rad tillämpar den hashfunktionen
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
Figur 2 visar tre tillstånd i hashtabellen:innan några rader bearbetas, efter att de första 5 raderna har bearbetats och efter att de första 10 raderna har bearbetats. Varje objekt i den länkade listan innehåller tupeln (empid, COUNT(*)).
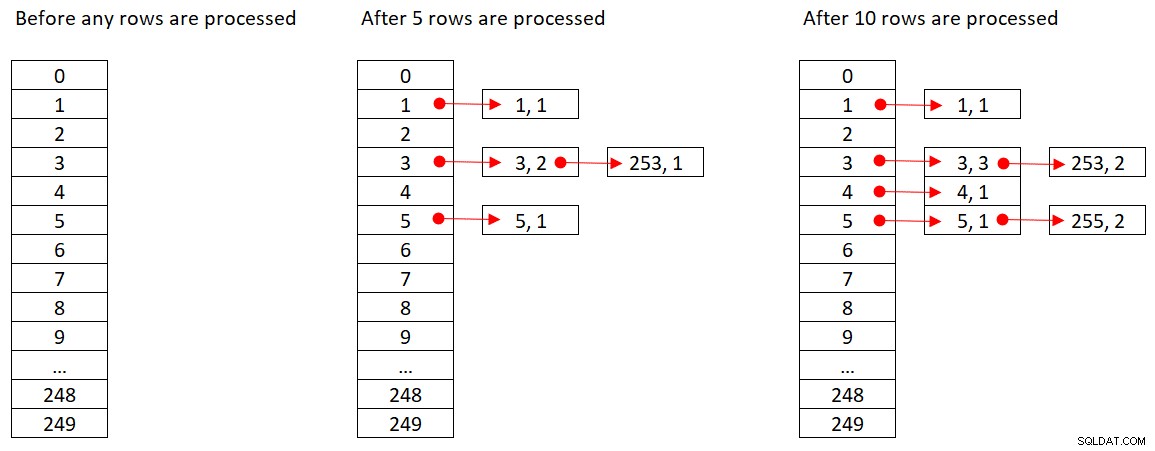
Figur 2:Hash-tabelltillstånd
När operatören Hash Aggregate slutfört att konsumera alla inmatningsrader, har hashtabellen alla grupper med det slutliga tillståndet för aggregatet.
Liksom Sorteringsoperatorn kräver Hash Aggregate-operatorn ett minnesbidrag, och om det tar slut på minne måste det spillas till tempdb; medan sortering kräver ett minnestillstånd som är proportionellt mot antalet rader som ska sorteras, kräver hashning ett minnestillstånd som är proportionellt mot antalet grupper. Så speciellt när grupperingsuppsättningen har hög densitet (litet antal grupper), kräver denna algoritm betydligt mindre minne än när explicit sortering krävs.
Tänk på följande två frågor (kalla dem Fråga 1 och Fråga 2):
VÄLJ empid, COUNT(*) SOM nummorders FRÅN dbo.Order GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); VÄLJ empid, COUNT(*) SOM siffror FRÅN dbo.Order GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
I figur 3 jämförs minnestillstånden för dessa frågor.

Figur 3:Planer för fråga 1 och fråga 2
Lägg märke till den stora skillnaden mellan minnesbidragen i de två fallen.
När det gäller Hash Aggregate-operatörens kostnad, gå tillbaka till figur 1, lägg märke till att det inte finns någon I/O-kostnad, snarare bara en CPU-kostnad. Försök sedan att omvända CPU-kostnadsformeln med liknande tekniker som de jag behandlade i de tidigare delarna i serien. De faktorer som potentiellt kan påverka operatörens kostnad är antalet inmatningsrader, antal utdatagrupper, den aggregatfunktion som används och vad du grupperar efter (gruppuppsättningens kardinalitet, datatyper som används).
Du förväntar dig att den här operatören har en startkostnad som förberedelse för att bygga hashtabellen. Du förväntar dig också att den ska skalas linjärt med avseende på antalet rader och grupper. Det är verkligen vad jag hittade. Men även om kostnaderna för både Stream Aggregate- och Sort-operatörerna inte påverkas av vad du grupperar efter, verkar det som om kostnaden för Hash Aggregate-operatören är det – både när det gäller kardinaliteten av grupperingsuppsättningen och de datatyper som används.
För att observera att gruppuppsättningens kardinalitet påverkar operatörens kostnad, kontrollera CPU-kostnaderna för Hash Aggregate-operatörerna i planerna för följande frågor (kalla dem Query 3 och Query 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); VÄLJ orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdatum) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1 );
Naturligtvis vill du försäkra dig om att det uppskattade antalet inmatningsrader och utdatagrupper är detsamma i båda fallen. De uppskattade planerna för dessa frågor visas i figur 4.
Figur 4:Planer för fråga 3 och fråga 4
Som du kan se är CPU-kostnaden för Hash Aggregate-operatorn 0,16903 när man grupperar efter en heltalskolumn och 0,174016 när man grupperar efter två heltalskolumner, med allt annat lika. Detta betyder att gruppuppsättningens kardinalitet verkligen påverkar kostnaden.
När det gäller om datatypen för det grupperade elementet påverkar kostnaden, använde jag följande frågor för att kontrollera detta (kalla dem Fråga 5, Fråga 6 och Fråga 7):
VÄLJ CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 SOM SMALLINT) OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS BIGINT) % CAST(1000) AS BIGINT) OPTION(HASH GROUP, MAXDOP 1);
Planerna för alla tre frågorna har samma uppskattade antal inmatningsrader och utdatagrupper, men de får alla olika uppskattade CPU-kostnader (0,121766, 0,16903 och 0,171716), därför påverkar den använda datatypen kostnaden.
Typen av aggregerad funktion verkar också ha en inverkan på kostnaden. Tänk till exempel på följande två frågor (kalla dem Fråga 8 och Fråga 9):
VÄLJ orderid % 1000 SOM grp, COUNT(*) SOM siffror FRÅN (SELECT TOP (20000) * FROM dbo.Orders) SOM D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Den beräknade CPU-kostnaden för Hash Aggregate i planen för Query 8 är 0,166344, och i Query 9 är 0,16903.
Det kan vara en intressant övning att försöka ta reda på exakt på vilket sätt gruppuppsättningens kardinalitet, datatyperna och den använda aggregatfunktionen påverkar kostnaden; Jag har helt enkelt inte ägnat mig åt den här aspekten av kostnadsberäkningen. Så efter att ha gjort ett val av grupperingsuppsättning och aggregeringsfunktion för din fråga, kan du ändra kostnadsformeln. Låt oss till exempel omvända CPU-kostnadsformeln för Hash Aggregate-operatorn när vi grupperar efter en enda heltalskolumn och returnerar MAX(orderdatum)-aggregatet. Formeln ska vara:
Operatörens CPU-kostnad =Med hjälp av teknikerna som jag demonstrerade i de tidigare artiklarna i serien fick jag följande omvänd konstruerade formel:
Operatörens CPU-kostnad =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Du kan kontrollera formelns riktighet med hjälp av följande frågor:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Jag får följande resultat:
numrows numgroups förutspådd kostnad beräknad kostnad------------------------------------------------------------------ ------- 100000 1000 0.703315 0.703316100000 2000 0.721023 0.721024200000 3000 1.40659 1.40659200000 6000 1.45972 1.45972500000 5000 3.44558 3.444455500000.Formeln verkar vara perfekt.
Kostnadssammanfattning och jämförelse
Nu har vi kostnadsformlerna för de tre tillgängliga strategierna:förbeställt Stream Aggregate, Sort + Stream Aggregate och Hash Aggregate. Följande tabell sammanfattar och jämför kostnadsberäkningsegenskaperna för de tre algoritmerna:
| Förbeställt strömaggregat | Sortera + Strömaggregat | Hash Aggregate | |
| Formel | @numrows * 0,0000006 + @numrows * 0,0000005 | 0,0112613 + Litet antal rader: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Stort antal rader: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @antalgrupper * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Gruppering efter enkel heltalskolumn, returnerar MAX( |
| Skalning | linjär | n log n | linjär |
| Start I/O-kostnad | inga | 0,0112613 | inga |
| Start-CPU-kostnad | inga | ~ 0,0001 | 0,017749 |
Enligt dessa formler visar figur 5 hur var och en av strategierna skalar för olika antal inmatningsrader, med ett fast antal grupper om 500 som exempel.
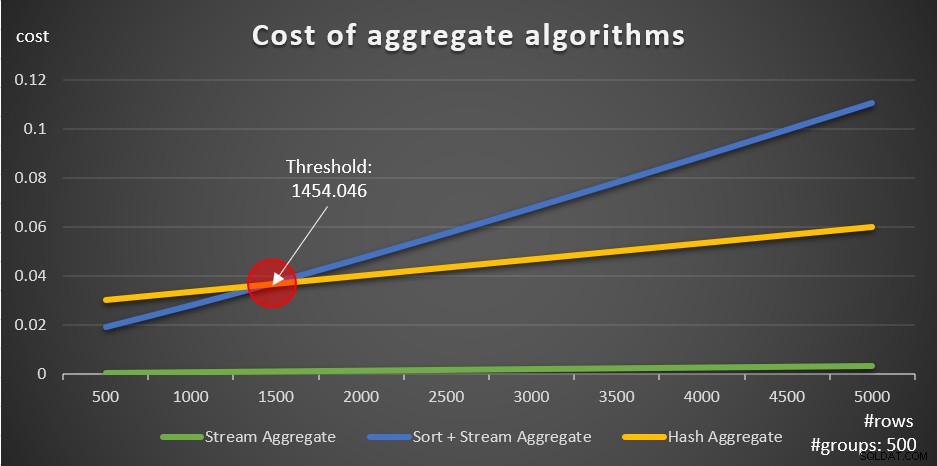
Figur 5:Kostnad för aggregerade algoritmer
Du kan tydligt se att om data är förbeställd, t.ex. i ett täckande index, är den förbeställda Stream Aggregate-strategin det bästa alternativet, oavsett hur många rader det handlar om. Anta till exempel att du behöver fråga i ordertabellen och beräkna det maximala orderdatumet för varje anställd. Du skapar följande täckande index:
SKAPA INDEX idx_eid_od PÅ dbo.Orders(empid, orderdate);
Här är fem frågor som emulerar en ordertabell med olika antal rader (10 000, 20 000, 30 000, 40 000 och 50 000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Figur 6 visar planerna för dessa frågor.
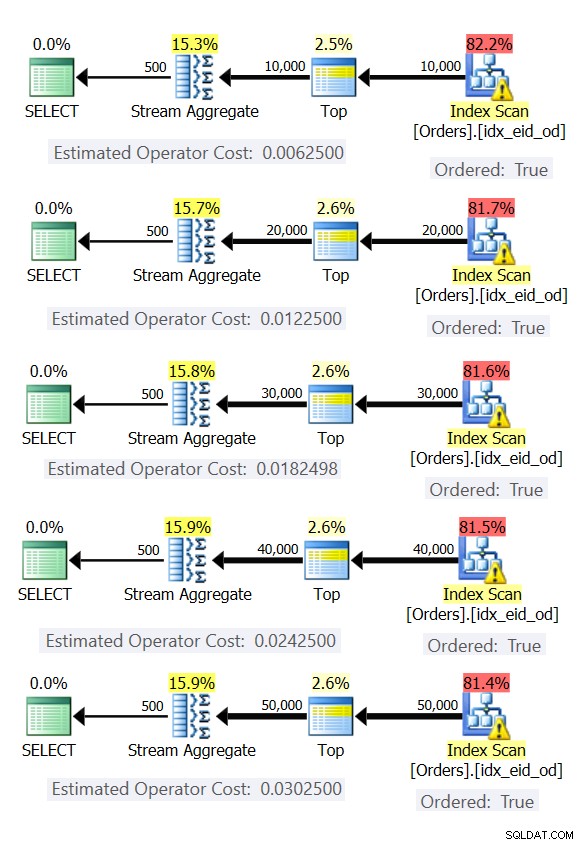
Figur 6:Planer med förbeställd Stream Aggregate-strategi
I alla fall utför planerna en beställd skanning av det täckande indexet och tillämpar Stream Aggregate-operatorn utan behov av explicit sortering.
Använd följande kod för att ta bort indexet du skapade för detta exempel:
DROP INDEX idx_eid_od ON dbo.Orders;
Det andra viktiga att notera om graferna i figur 5 är vad som händer när data inte är förbeställda. Detta händer när det inte finns något täckande index på plats, såväl som när du grupperar efter manipulerade uttryck i motsats till baskolumner. Det finns en optimeringströskel – i vårt fall på 1 454 046 rader – under vilken strategin Sort + Stream Aggregate har en lägre kostnad, och på eller över vilken Hash Aggregate-strategin har en lägre kostnad. Detta har att göra med det faktum att den förra hash en lägre startkostnad, men skalas på ett n log n sätt, medan den senare har en högre startkostnad men skalas linjärt. Detta gör den förra att föredra med ett litet antal inmatningsrader. Om våra omvända formler är korrekta bör följande två frågor (kalla dem Query 10 och Query 11) få olika planer:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Planerna för dessa frågor visas i figur 7.
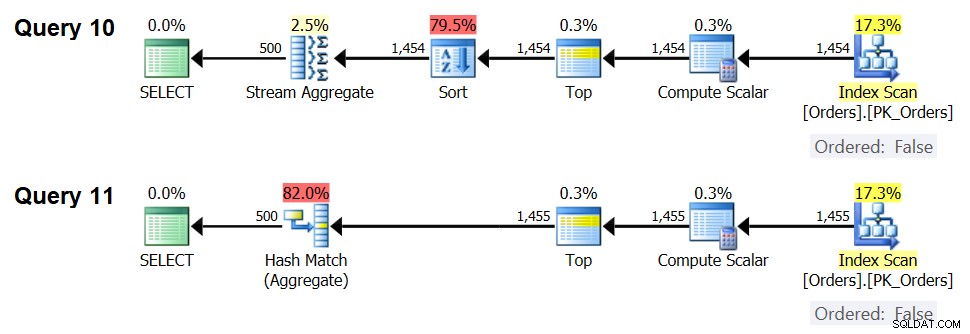
Figur 7:Planer för fråga 10 och fråga 11
Faktum är att med 1 454 inmatningsrader (under optimeringströskeln) föredrar optimeraren naturligtvis algoritmen Sortering + Stream Aggregate för fråga 10, och med 1 455 inmatningsrader (över optimeringströskeln) föredrar optimeraren naturligtvis Hash Aggregate-algoritmen för Query .
Potential för Adaptive Aggregate-operatör
En av de knepiga aspekterna av optimeringströsklar är problem med parametersniffning när man använder parameterkänsliga frågor i lagrade procedurer. Betrakta följande lagrade procedur som ett exempel:
SKAPA ELLER ÄNDRA PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS nummorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Du skapar följande optimala index för att stödja den lagrade procedurfrågan:
SKAPA INDEX idx_oid_i_eid PÅ dbo.Orders(orderid) INCLUDE(empid);
Du skapade indexet med orderid som nyckel för att stödja frågans intervallfilter och inkluderade empid för täckning. Det här är en situation där du inte riktigt kan skapa ett index som både stöder intervallfiltret och har de filtrerade raderna förbeställda av grupperingsuppsättningen. Detta innebär att optimeraren måste göra ett val mellan Sort + Stream Aggregate och Hash Aggregate-algoritmerna. Baserat på våra kostnadsformler är optimeringströskeln mellan 937 och 938 inmatningsrader (låt oss säga 937,5 rader).
Anta att du utför den lagrade proceduren första gången med ett inmatat initial order-ID som ger dig ett litet antal matchningar (under tröskeln):
EXEC dbo.EmpOrders @initialorderid =999991;
SQL Server producerar en plan som använder Sort + Stream Aggregate-algoritmen och cachar planen. Efterföljande körningar återanvänder den cachade planen, oavsett hur många rader som är inblandade. Till exempel har följande körning ett antal matchningar över optimeringströskeln:
EXEC dbo.EmpOrders @initialorderid =990001;
Ändå återanvänder den den cachade planen trots att den inte är optimal för den här exekveringen. Det är ett klassiskt parametersniffningsproblem.
SQL Server 2017 introducerar adaptiva frågebehandlingsfunktioner, som är designade för att klara sådana situationer genom att bestämma vilken strategi som ska användas under utförande av en fråga. Bland dessa förbättringar finns en Adaptive Join-operatör som under körning avgör om en Loop- eller Hash-algoritm ska aktiveras baserat på en beräknad optimeringströskel. Vår samlade historia ber om en liknande Adaptive Aggregate-operatör, som under körningen skulle göra ett val mellan en Sort + Stream Aggregate-strategi och en Hash Aggregate-strategi, baserat på en beräknad optimeringströskel. Figur 8 illustrerar en pseudoplan baserad på denna idé.
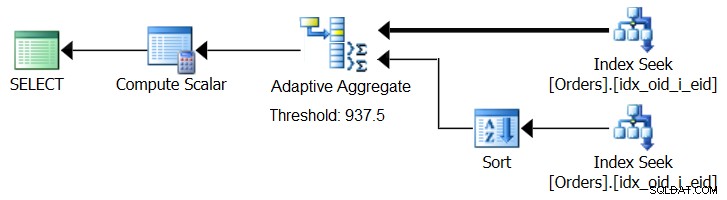
Figur 8:Pseudoplan med Adaptive Aggregate-operatör
För nu, för att få en sådan plan, måste du använda Microsoft Paint. Men eftersom konceptet med adaptiv frågebehandling är så smart och fungerar så bra, är det bara rimligt att förvänta sig att se ytterligare förbättringar på detta område i framtiden.
Kör följande kod för att ta bort indexet du skapade för det här exemplet:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Slutsats
I den här artikeln täckte jag kostnadsberäkningen och skalningen av Hash Aggregate-algoritmen och jämförde den med Stream Aggregate och Sort + Stream Aggregate-strategierna. Jag beskrev optimeringströskeln som finns mellan strategierna Sort + Stream Aggregate och Hash Aggregate. Med ett litet antal inmatningsrader är den förra att föredra och med stora nummer den senare. Jag beskrev också potentialen för att lägga till en Adaptive Aggregate-operator, liknande den redan implementerade Adaptive Join-operatorn, för att hjälpa till att hantera parametersniffningsproblem när man använder parameterkänsliga frågor. Nästa månad kommer jag att fortsätta diskussionen genom att ta upp parallellitetsöverväganden och fall som kräver omskrivningar av frågor.