Redan 2014 startade jag en serie blogginlägg här för att prata om specifika väntetyper och vad de gör och inte betyder. Det gav mig idén att skapa de vänte- och låsbibliotek som jag underhåller (mer om dessa senare).
Om du läser det här och tänker "vad pratar han om?" då är detta inlägg för dig. Jag kommer att introducera dig för väntestatistik och förklara hur avgörande de är för felsökning av arbetsbelastningsprestanda i SQL Server.
Schemaläggning
Exekveringen av SQL Servers interna kod görs med en mekanism som kallas trådar . Varje tråd kan exekvera SQL Server-kod, och flera trådar koordineras när en fråga körs parallellt. Dessa trådar skapas när SQL Server startar, beroende på antalet processorkärnor som är tillgängliga för SQL Server att använda.
Trådar placeras på en schemaläggare när en fråga startar, med en schemaläggare per processorkärna, och flytta inte från den schemaläggaren förrän frågan är klar. En schemaläggare har tre grundläggande "delar":
- processorn , som har exakt en tråd som för närvarande exekverar kod.
- servitlistan , som har alla trådar som i princip har fastnat och väntar på att en viss resurs ska bli tillgänglig.
- Den körbara kön , som har alla trådar som kan köras men som väntar på att komma till processorn.
Trådar övergår från tillstånd 1 till 2 till 3 till 1, runt och runt tills frågan är klar.
Väntar
Ur vårt perspektiv är den mest intressanta delen av schemaläggning när en tråd måste vänta på en resurs innan den kan fortsätta. Några exempel på detta är:
- En tråd behöver läsa en sida, och sidan finns inte i minnet, så tråden utfärdar en asynkron fysisk I/O och måste sedan vänta utanför processorn tills I/O är klar.
- En tråd måste skaffa ett delningslås på en rad för att kunna läsa den, men en annan tråd har redan ett motstridigt exklusivt lås medan den uppdaterar raden.
När en tråd stöter på behovet av en resurs som den inte kan få, har den inget annat val än att stanna och vänta på att resursen blir tillgänglig (mekanismen för hur tråden meddelas om resurstillgänglighet ligger utanför den här artikelns räckvidd). När det händer gör SQL Server en anteckning om varför tråden fick vänta och detta kallas väntetypen . Några exempel på detta är:
- När en tråd väntar på att en sida ska läsas in i minnet så att den kan läsas, är väntetypen PAGEIOLATCH_SH (om tråden väntar på en sida som den kommer att ändras är väntetypen PAGEIOLATCH_EX ).
- När en tråd väntar på ett delningslås på en rad är väntetypen LCK_M_S (lås-läge-delning)
SQL Server håller också reda på hur länge tråden måste vänta. Detta kallas resursväntetiden , och är vanligtvis bara känd som väntetiden .
Väntestatistik
Den övergripande uppsättningen mätvärden för hur många trådar som har väntat på vilka resurser och hur länge i genomsnitt kallas väntestatistik . Den här informationen är extremt användbar för att felsöka arbetsbelastningsprestanda, eftersom du enkelt kan se var prestandaflaskhalsar kan finnas.
Grundidén är att SQL Server har information om varför trådar måste stanna och vänta och vad de väntar på. Så istället för att behöva gissa var du ska börja felsöka, kan noggrann analys av väntestatistik vanligtvis peka dig i en riktning att ta.
Till exempel, om majoriteten av väntan på servern är PAGEIOLATCH_SH , kan detta indikera att det finns minnestryck på servern, eller att det finns frågor som gör stora tabellsökningar istället för att använda icke-klustrade index, eller att det finns ett problem med det underliggande I/O-undersystemet, eller ett antal andra orsaker.
Det finns ett stort antal väntetyper men de flesta av dem dyker inte upp så ofta, så det finns en kärnuppsättning som du kommer att se om och om igen på dina servrar. Att förstå vad dessa betyder och hur man undersöker dem är avgörande så att du inte ger efter för vad jag kallar "knee-jerk performance tuning" och slösar tid och ansträngning på att försöka lösa ett problem som faktiskt inte är ett problem. Jag skrev en serie blogginlägg här som går in på detaljer där, och Aaron Bertrand skrev också ett sammanfattande inlägg över de 10 bästa väntestatistiken förra året.
Spårningsväntningar
Det finns flera sätt att spåra väntetider. Det enklaste är att titta på vilka väntar som sker på servern just nu, med hjälp av ett skript som undersöker sys.dm_os_waiting_tasks DMV. Du kan hitta ett skript för att göra det här, och som har automatiskt genererade webbadresser till wait-biblioteket.
Ett annat sätt är att titta på den samlade väntestatistiken för hela servern, med ett skript som undersöker sys.dm_os_wait_stats DMV. Du kan hitta ett skript för att göra det här, och som har automatiskt genererade webbadresser i wait-biblioteket. Du måste dock vara försiktig med den metoden, eftersom det kommer att visa alla väntetider som har inträffat sedan servern startade. Ett bättre sätt är att spåra väntan under små intervaller, säg en halvtimme, och ett skript för att göra det finns här.
Du kan också få väntestatistik med Server Reports-tillägget till det nya Azure Data Studio-verktyget och med Query Store från SQL Server 2017 och framåt.
Kom ihåg att du fortfarande måste förstå vad väntetyperna betyder när du har samlat in mätvärdena.
Väntarresurser
För att hjälpa till med detta, och eftersom Microsoft inte har dokumentation om hur man tolkar väntestatistik, släppte jag redan 2016 ett bibliotek av väntetyp, med detaljer om hundratals vanliga väntetyper och hur man felsöker dem. Du kan komma till biblioteket på https://www.SQLskills.com/help/waits. Och sedan 2017 skapade SentryOne ett automatiserat system för att tillhandahålla en infografik för varje sida i biblioteket som du snabbt kan använda för att se om väntetypen du är intresserad av är en riktigt vanlig sådan eller inte (se det här inlägget för detaljer) . Ett exempel på infografik finns nedan för PAGEIOLATCH_SH vänta typ:
På den horisontella axeln finns en skala (som går att växla mellan linjär och logaritmisk) för hur stor procentandel av instanserna (fjärrövervakade av SentryOne) som upplevde denna väntetid under föregående kalendermånad, och på den vertikala axeln är procentandelen tid som de instanser som upplevde det wait hade faktiskt en tråd som väntade på den väntetypen.
En annan resurs för att hjälpa dig förstå väntar är en onlinekurs som jag spelade in för Pluralsight – se här.
Åtminstone bör du läsa igenom de olika blogginläggen i avsnitten Väntestatistik och Spåra väntan ovan.
Spåra väntar med SentryOne-verktyg
SQL Sentry spårar väntan på instansnivå på dig automatiskt över tid, så att du inte behöver fånga höga väntan "på akten". Någon klagade på ett trögt system igår eftermiddag eller en rapport som tog timeout i tisdags? Inga problem. Du kan gräva ner dig i alla väntetider för vilken tidpunkt som helst eller över ett intervall, och korrelera dem med olika andra prestandamått som samlades in vid den tiden – oavsett om det är andra trender på instrumentpanelen, som backup eller databas I/O-aktivitet, hoppa till alla de bästa SQL-kommandona som kördes i samma fönster, undersöker långvarig blockering, eller använd baslinjer för att jämföra vänteprofilen med andra perioder.
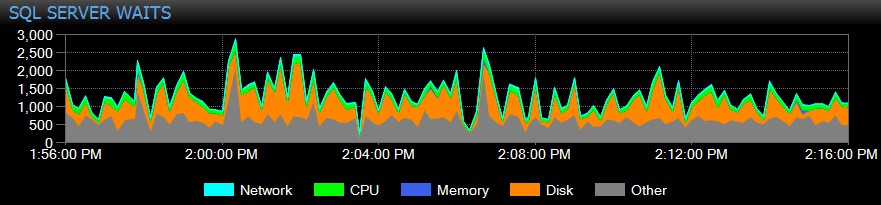
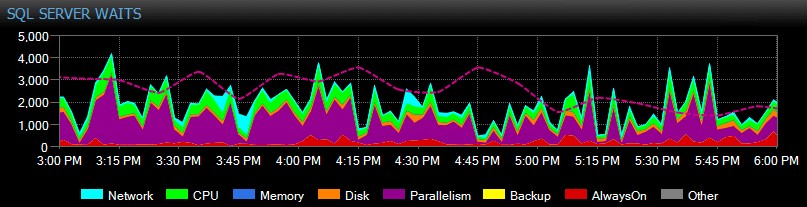
Du kan till och med anpassa väntetider som samlas in eller inte, ändra kategorierna som presenteras visuellt och bygga intelligenta varningar och/eller svar på specifika väntesituationer. Många av våra kunder använder SQL Sentry för att fokusera på verkliga prestandaproblem relaterade till väntetider, eftersom det tillåter dem att ignorera mycket av det brus som bara är normal SQL Server-trådaktivitet.
Sammanfattning
Som du kan se från informationen ovan händer alltid väntan i SQL Server, eftersom det är precis så trådschemaläggning och flertrådiga system fungerar. De är ett av de mest kraftfulla verktygen i din felsökningsverktygslåda, så om du inte redan använder dem är det dags att börja nu. Inlärningskurvan är kort och brant – när du väl har kört de olika frågorna och verktygen några gånger kommer du snabbt att få kläm på det, och sedan gäller det att läsa igenom guiderna för väntan du ser och avgöra om de är ett problem eller inte.
Lycka till med felsökningen!