Jag håller på att städa mitt hus (för sent på sommaren för att försöka framställa det som vårstädning). Du vet, rensa garderober, gå igenom barnens leksaker och organisera källaren. Det är en smärtsam process. När vi flyttade in i vårt hus för 10 år sedan hade vi SÅ mycket plats. Nu känner jag att det finns saker överallt, och det gör det svårare att hitta det jag verkligen letar efter och det tar längre och längre tid att städa upp och organisera.
Låter detta som vilken databas du hanterar?
Många kunder som jag har arbetat med hanterar att rensa data som en eftertanke. Vid tidpunkten för implementeringen vill alla spara allt. "Vi vet aldrig när vi kan behöva det." Efter ett eller två år inser någon att det finns mycket extra saker i databasen, men nu är folk rädda för att bli av med det. "Vi måste kolla med Legal för att se om vi kan ta bort det." Men ingen kollar med Legal, eller om någon gör det går Legal tillbaka till företagsägarna för att fråga vad de ska behålla, och sedan stannar projektet av. "Vi kan inte komma till enighet om vad som kan raderas." Projektet glöms bort, och sedan två eller fyra år framåt är databasen plötsligt en terabyte, svår att hantera, och folk skyller alla prestandaproblem på databasens storlek. Du hör orden "partitionering" och "arkivdatabas" kastas runt, och ibland får du bara radera en massa data, vilket har sina egna problem.
Helst bör du bestämma din utrensningsstrategi innan implementeringen, eller inom de första sex till tolv månaderna efter start. Men eftersom vi är förbi det stadiet, låt oss titta på vilken inverkan denna extra data kan ha.
Testmetodik
För att sätta scenen tog jag en kopia av Credit-databasen och återställde den till min SQL Server 2012-instans. Jag tog bort de tre befintliga icke-klustrade indexen och lade till två av mina egna:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Jag ökade sedan antalet rader i tabellen till 14,4 miljoner, genom att infoga den ursprungliga uppsättningen rader flera gånger och ändra datumen något:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Slutligen satte jag upp en testsele för att köra en serie uttalanden mot databasen fyra gånger vardera. Påståendena är nedan:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Före varje uttalande jag körde
DBCC DROPCLEANBUFFERS; GO
för att rensa buffertpoolen. Uppenbarligen är detta inte något att utföra mot en produktionsmiljö. Jag gjorde det här för att ge en konsekvent utgångspunkt för varje test.
Efter varje exekvering ökade jag storleken på tabellen dbo.charge genom att infoga de 14,4 miljoner raderna jag började med, men jag ökade charge_dt med ett år för varje exekvering. Till exempel:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Efter tillägget av 14,4 miljoner rader körde jag om testselen. Jag upprepade detta sex gånger och lade i huvudsak till sex "år" av data. Tabellen dbo.charge började med data från 1999, och efter de upprepade inläggen innehöll data fram till 2005.
Resultat
Resultaten från avrättningarna kan ses här:
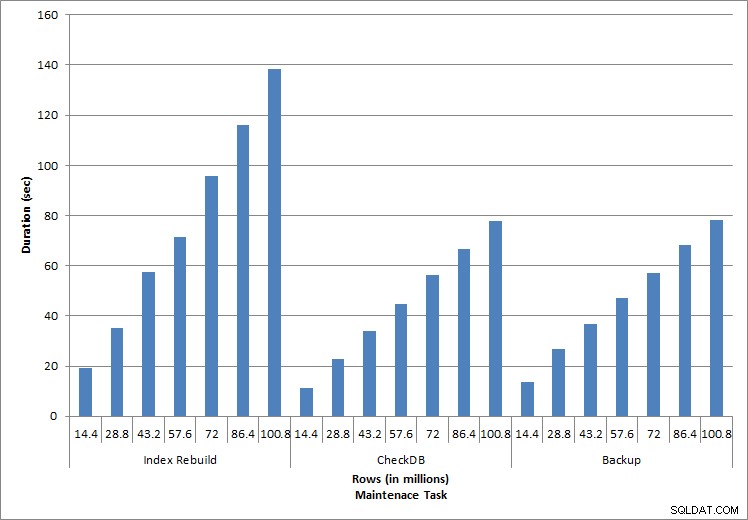
Längd för underhållsuppgifter
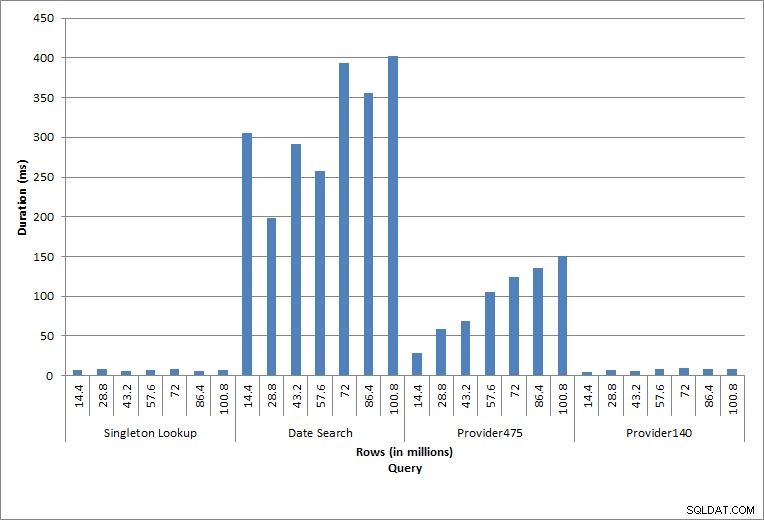
Längd för frågor
De individuella satserna som körs återspeglar typisk databasaktivitet. Indexombyggnader, integritetskontroller och säkerhetskopieringar är en del av regelbundet databasunderhåll. Frågorna mot avgiftstabellen representerar en enkel uppslagning såväl som tre varianter av intervallsökningar som är specifika för data i tabellen.
Indexrekonstruktioner, CHECKDB och säkerhetskopior
Som förväntat för underhållsuppgifterna ökade varaktigheten och IO-värdena när fler rader lades till databasen. Databasstorleken ökade med en faktor 10, och även om varaktigheterna inte ökade i samma takt sågs en konsekvent ökning. Varje underhållsuppgift tog initialt mindre än 20 sekunder att slutföra, men när fler rader lades till ökade varaktigheten för uppgifterna till nästan 1 minut och 20 sekunder för 100 miljoner rader (och till över 2 minuter för indexombyggnaden). Detta återspeglar den extra tid som SQL Server krävs för att slutföra uppgiften på grund av ytterligare data.
Singleton Lookup
Frågan mot dbo.charge för en specifik charge_no gav alltid en rad – och skulle ha producerat en rad oavsett vilket värde som används, eftersom charge_no är en unik identitet. Det finns minimal variation för denna uppslag. Eftersom rader kontinuerligt läggs till i tabellen, kan indexet öka i djupet med en eller två nivåer (mer när tabellen blir bredare), och därför läggs till ett par IO:er, men det här är en enkel uppslagning med väldigt få IO:er.
Räckviddssökningar
Frågan för ett datumintervall (charge_dt) ändrades efter varje infogning för att söka efter det senaste årets data för juli (t.ex. "2005-07-01" till "2005-07-01" för den sista uppsättningen tester), men returnerades drygt 1,2 miljoner rader varje gång. I ett verkligt scenario skulle vi inte förvänta oss att samma antal rader returneras för samma månad, år över år, och vi skulle inte heller förvänta oss att samma antal rader returneras för varje månad under ett år. Men antalet rader kan hålla sig inom samma intervall mellan månader, med små ökningar över tiden. Det finns fluktuationer i varaktigheten för den här frågan, men en granskning av IO-data som hämtats från sys.dm_io_virtual_file_stats visar konsistens i antalet läsningar.
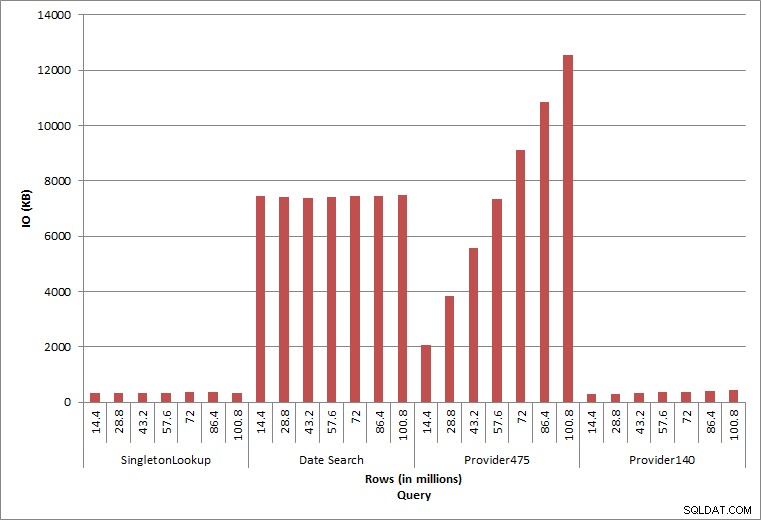
Fråga IO
De två sista frågorna, för två olika provider_no-värden, visar den verkliga effekten av att behålla data. I den inledande tabellen dbo.charge hade provider_no 475 över 126 000 rader och provider_no 140 hade över 1700 rader. För varje 14,4 miljoner rader som lades till, tillkom ungefär samma antal rader för varje provider_no. I en produktionsmiljö är denna typ av datadistribution inte ovanlig, och frågor om denna data kan fungera bra under de första åren av lösningen, men kan försämras med tiden när fler rader läggs till. Frågans varaktighet ökar med en faktor fem (från 31 ms till 153 ms) mellan den initiala och slutliga exekveringen för provider_no 475. Även om denna påverkan kanske inte verkar signifikant, notera den parallella ökningen av IO (ovan). Om detta var en fråga som kördes med hög frekvens, och/eller det fanns liknande frågor som kördes med vanlig frekvens, kan den extra belastningen läggas till och påverka den totala resursanvändningen. Tänk vidare på effekten när du arbetar med tabeller som har miljarder rader och används i frågor med komplexa kopplingar, och påverkan på dina vanliga – och extremt kritiska – underhållsuppgifter. Slutligen, ta hänsyn till återvinningstid. Din katastrofåterställningsplan bör baseras på återställningstider, och när databasen växer kommer databasen att ta längre tid att återställa i sin helhet. Om du inte regelbundet testar och tar tid för dina återställningar, kan det ta längre tid än du trodde att återhämta dig från en katastrof.
Sammanfattning
Exemplen som visas här är enkla illustrationer av vad som kan hända när en dataarkiveringsstrategi inte bestäms under databasimplementering, och det finns många andra scenarier att utforska och testa. Gamla data som sällan eller aldrig nås påverkar mer än bara utrymmet på disken. Det kan påverka frågeprestanda och varaktighet för underhållsuppgifter. Som en DBA som hanterar flera databaser på en instans kan en databas som innehåller historiska data påverka prestanda och underhållsuppgifter för andra databaser. Vidare, om rapporter körs mot historiska data, kan detta orsaka förödelse i redan upptagen OLTP-miljö.
Från början är det avgörande att livslängden för data i en databas bestäms och att en handlingsplan införs. För vissa lösningar krävs det att all data lagras för alltid. Använd i det här fallet strategier för att hålla databasens storlek hanterbar, till exempel:arkivera data till en separat tabell eller separat databas regelbundet. I händelse av att data inte behöver lagras på flera år, implementera en rensningsstrategi som tar bort data regelbundet. På det här sättet kan du slänga ut leksakerna som du inte längre leker med, kläder som inte längre passar och slumpmässigt skräp som du bara inte använder var tredje månad … snarare än en gång vart tionde år.