Över hela världen är jobbportalen ett välkänt inslag i internetlandskapet. Stora spelare som Indeed och Monster har förvandlat jobbsökande och rekrytering till en veritabel onlineindustri. Låt oss dyka in i de elementära funktionerna som utnyttjas av jobbportaler och bygga en datamodell som kan stödja dem.
Människor älskar att spara tid genom att använda tekniska innovationer; jobbportalen online är en annan version av att arbeta smartare, inte hårdare. Både arbetssökande och företag inser värdet av att söka online:de får en bättre räckvidd vid högre hastigheter och lägre kostnader.
Jobbportalbranschen är ganska stabiliserad nu, åtminstone vad gäller trafikvolymer. Jobbjägare använder dessa portaler för att hitta positioner i många branscher och går bortom IT till sektorer som teknik, försäljning, tillverkning och finansiella tjänster. Men de får hård konkurrens från sociala medier och professionella nätverkssajter som LinkedIn. Men det finns fortfarande möjligheter att utforska, som att utöka sin penetration till landsbygdsområden och mindre städer.
Så som vi sa, vi kommer att utforska detta ämne ur ett databasdesignperspektiv. Låt oss börja med att räkna upp de grundläggande förväntningarna på en jobbportal.
Vad förväntar sig människor av en jobbportal på nätet?
Både arbetsgivare och arbetssökande förväntar sig följande funktioner från en arbetsplats online:
- Människor kan registrera sig som arbetssökande, bygga sina profiler och leta efter jobb som matchar deras kompetens.
- Användare kan ladda upp sina befintliga meritförteckningar. Om de inte har ett bör de kunna fylla i ett formulär och få ett CV skapat för dem.
- Personer kan ansöka direkt till upplagda jobb.
- Företag kan registrera sig, lägga upp jobb och söka jobbsökarprofiler.
- Flera representanter från ett företag bör kunna registrera och lägga ut jobb.
- Företagets representanter kan se en lista över arbetssökande och kan kontakta dem, ta initiativ till en intervju eller utföra någon annan åtgärd relaterad till deras tjänst.
- Registrerade användare ska kunna söka efter jobb och filtrera resultaten baserat på plats, nödvändiga färdigheter, lön, erfarenhetsnivå etc.
Bygga datamodellen
Efter att ha övervägt ovanstående krav kom jag fram till tre breda funktionskategorier:
- Hantera användare – Hur portalen hanterar användare, det vill säga arbetssökande, HR-personal och oberoende eller konsulterande rekryterare. (För syftet med denna modell behandlas enskilda HR-representanter och oberoende eller konsulterande rekryterare som företag, åtminstone vad gäller hur de använder portalen.)
- Bygga profiler – Hur portalen tillåter arbetssökande och organisationer att skapa profiler och meritförteckningar.
- Lägg upp och leta upp jobb – Hur portalen underlättar processen att lägga upp, söka och söka jobb.
Låt oss titta på vart och ett av dessa områden separat.
1. Hantera användare
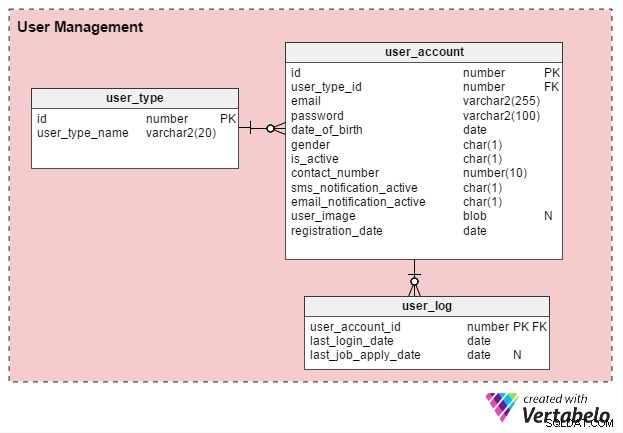
Det finns i första hand två typer av onlinejobbportalanvändare:individuella arbetssökande och HR-rekryterare (eller oberoende rekryteringskonsulter). Låt oss skapa en tabell med namnet user_type för att lagra dessa register. Till att börja med kommer det att ha två poster – ett för arbetssökande och ett för rekryterare. (Vi kan alltid skapa ytterligare posttyper efter behov.)
Användare måste registrera sig innan de kan använda portalen. user_account tabellen lagrar deras grundläggande kontouppgifter. Jag övervägde tidigare att döpa den här tabellen till "användare", men eftersom användare är ett systemdefinierat nyckelord i nästan alla databaser, föredrar jag att hålla mig till "användarkonto".
user_account tabellen har följande kolumner:
- id – Detta är både tabellens primärnyckel och en unik identifierare för varje användare. Detta ID kommer att refereras till av andra tabeller i datamodellen.
- user_type_id – Detta anger om användaren är en arbetssökande eller en rekryterare.
- e-post – Den här kolumnen innehåller användarens e-postadress. Det fungerar som ett annat användar-ID för portalen.
- lösenord – Detta lagrar ett krypterat kontolösenord (skapat av användare under registreringen).
- födelsedatum och kön – Som deras namn antyder innehåller dessa kolumner användarnas födelsedatum och kön.
- är_aktiv – Till en början skulle den här kolumnen vara "Y", men användare kan ställa in sin profil på inaktiv eller "N". Den här kolumnen lagrar deras val.
- contact_number – Det här är telefonnumret (vanligtvis mobilt) som anges vid registreringen. Användare kan ta emot SMS (text) aviseringar på detta nummer. Det kan vara samma nummer (eller inte) som den arbetssökande listar i sin profil eller CV.
- sms_notification_active och email_notification_active – Dessa kolumner lagrar användarnas preferenser när det gäller att ta emot aviseringar via text och/eller e-post.
- användarbild – Det här är ett attribut av BLOB-typ som lagrar varje användares profilbild. Eftersom den här portalen endast tillåter en profilbild per användare, är det vettigt att lagra den här.
- registreringsdatum – Den här kolumnen registrerar när användaren registrerade sig på portalen.
Vi skapar ytterligare en tabell, user_log , som lagrar ett register över användarnas senaste inloggningsdatum och deras senaste ansökningsdatum. Det finns många funktioner som kan byggas från denna kunskap. Till exempel kan vi använda denna information för att svara på frågan Söker användare X aktivt efter ett jobb ? Om så är fallet kan de erbjudas en produkt för att skapa ett effektivt CV. Användare som inte aktivt söker jobb skulle inte få ett sådant erbjudande.
2. Bygga profiler
Vi kan ytterligare dela upp det här avsnittet i två områden:företags- eller organisationsprofiler och arbetssökandeprofiler.
Företagsprofiler
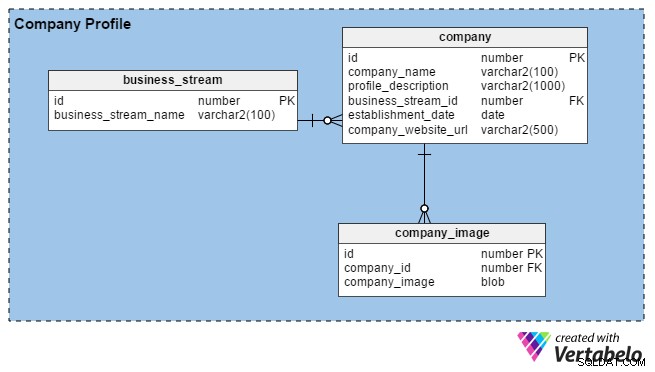
Vanligtvis bygger HR-team företagsprofiler genom att ange detaljer om deras organisation och bilder av deras kontor, byggnader etc. Deras huvudsakliga mål är att attrahera bra talanger. När rekryterare registrerar sig på portalen kan de också bygga profiler för sina företag (eller deras personliga varumärke, om de är oberoende) genom att tillhandahålla några grundläggande detaljer som hur länge de har varit i verksamheten, deras plats och deras huvudsakliga verksamhet ( t.ex. tillverkning, IT-tjänster, ekonomi, etc).
Portalen tillåter HR- och konsultrekryterare att ladda upp så många bilder som de vill (till skillnad från arbetssökande, som bara kan ladda upp en). Därför har vi skapat company_image tabell för att lagra flera bilder för varje rekryterarkonto. företags-id kolumnen i den här tabellen är en främmande nyckel som refererar till den unika identifieraren som används i company bord.
I company tabell, har vi följande kolumner:
- id – Den primära nyckeln i den här tabellen används också för att unikt identifiera företag.
- företagsnamn – Som kolumnnamnet antyder har detta det juridiska namnet på ett företag.
- profile_description – Detta innehåller en kort beskrivning av varje företag.
- business_stream_id – Den här kolumnen visar vilken affärsström ett företag tillhör. Ett olje- och gasprospekteringsföretag kan till exempel anställa IT-ingenjörer, men deras huvudsakliga verksamhet är fortfarande "Oil and Gas".
- establishment_date – Den här kolumnen berättar hur gammalt ett företag är.
- company_website_url – Detta är en obligatorisk (ej nullbar) kolumn. Den innehåller en pekare till företagets officiella webbplats så att arbetssökande kan få mer information.
Slutligen, business_stream Tabellen har bara två attribut, ett id som är den primära nyckeln för denna tabell och en beskrivning av företagets huvudsakliga affärsflöde (företagsströmsnamn ).
Jobbsökande profiler
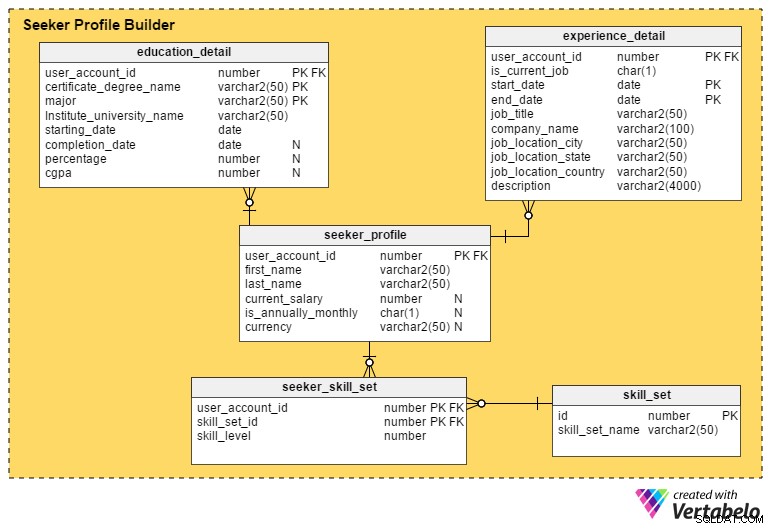
Detta är den mest kritiska delen av en jobbportal. Om inte en portal fångar så många detaljer som möjligt från arbetssökande är det svårt för rekryterare att välja ut profilerna eller kandidaterna.
seeker_profile Tabellen innehåller ytterligare detaljer som inte registrerades under registreringsprocessen. Den innehåller dessa fält:
- user_account_id – Den här kolumnen hänvisas från
user_accounttabell, och den fungerar som den primära nyckeln för denna tabell. Det säkerställer att det kommer att finnas högst en profil per arbetssökande. - förnamn och efternamn – Som namnen antyder innehåller dessa kolumner den arbetssökandes för- och efternamn.
- nuvarande_lön – Det här attributet innehåller den arbetssökandes aktuella lön. Den är nullbar eftersom folk kanske inte vill avslöja den.
- är_årlig_månad – Detta definierar om deras lön är per år eller per månad.
- valuta – Detta lagrar lönens valuta.
education_detail tabellen lagrar varje arbetssökandes utbildningshistoria, som tillhandahålls av dem. Den har en sammansatt primärnyckel som består av user_account_id , certificate_degree_name och major kolumner. Detta säkerställer att användare bara anger ett rekord för varje examen eller certifikat. Tabellen innehåller dessa attribut:
- user_account_id – Den här kolumnen hänvisas från
user_accounttabell och fungerar som primärnyckel för denna tabell. - certifikat_grad – Detta är certifikatet eller examenstypen; t.ex. gymnasiet, gymnasiet, examen, efter examen eller yrkescertifikat.
- major – Den här kolumnen innehåller huvudutbildningen för certifikatet eller examen – t.ex. en kandidatexamen med huvudämne i datavetenskap.
- institutets_universitetsnamn – Det här är institutet, skolan eller universitetet som tilldelade examen eller certifikat.
- startdatum – Detta attribut lagrar datumet då användaren antogs till ett utbildningsprogram.
- slutdatum – Detta är det datum då examen eller certifikat tilldelades. Detta attribut är dock nullbart; personer kanske fortfarande slutför sitt program medan de söker jobb, eller så kan de ha hoppat av programmet helt och hållet.
- procentandel och cgpa – Dessa kolumner lagrar betygsprocenten eller CGPA (kumulativt betygssnitt) som uppnåtts av användare i deras examen eller certifikatkurs.
experience_detail tabellen för register över användares tidigare och nuvarande yrkeserfarenhet. Den innehåller följande viktiga kolumner:
- user_account_id – Den här kolumnen hänvisas från
user_accounttabell och är den primära nyckeln för denna tabell. - är_nuvarande_jobb – Det här är en indikatorkolumn som anger användarens nuvarande jobb. Den här kolumnen spelar också en viktig roll för att härleda användarnas nuvarande positioner och hur länge de har haft sin nuvarande position.
- startdatum – Detta lagrar när en användare påbörjar ett jobb.
- slutdatum – Detta lagrar när en användare avslutar ett jobb.
- job_title – Detta innehåller information om användarens jobbroll.
- företagsnamn – Det här attributet har det relevanta företagsnamnet som är kopplat till ett jobb.
- job_location_city – Detta anger staden där jobbet fanns.
- job_location_state – Detta anger tillståndet där jobbet befann sig.
- job_location_country – Detta anger det land där jobbet fanns.
- beskrivning – Den här kolumnen lagrar information om jobbroller och ansvar, utmaningar och prestationer.
Arbetssökande kan ha flera färdigheter. För att hålla register över alla dessa färdighetsuppsättningar skapar vi tabellen seeker_skill_set . Kolumnerna är:
- user_account_id – Den här kolumnen hänvisas från
user_accounttabell och är den primära nyckeln för denna tabell. - skill_set_id – Detta ID anger vilken färdighetsuppsättning användaren besitter.
- skill_level – Detta numeriska attribut kvantifierar arbetssökandes expertis inom en viss färdighet. Ett nummer från 1 (nybörjare) till 10 (expert) anger deras erfarenhetsnivå.
Slutligen, skill_set Tabellen innehåller beskrivningar av alla färdigheter som hänvisas till i ovanstående tabells skill_set_id attribut. Den innehåller bara två kolumner, ett skill_set_name och dess relaterade id .
3. Lägga upp och leta upp jobb
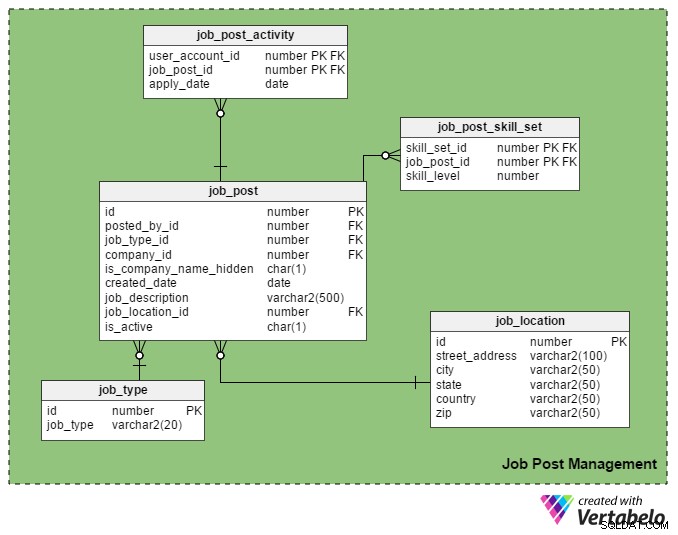
Detta är den huvudsakliga USP (Unique Selling Point) för en jobbportal. Endast registrerade rekryterare får lägga ut ett jobb på portalen och endast registrerade arbetssökande får söka till dem.
job_post tabellen är huvudtabellen i detta ämnesområde. Som du kanske gissar innehåller den detaljer om jobbinlägg. Alla andra tabeller i det här avsnittet skapas runt det och länkas till det.
- id – Det här är den primära nyckeln i denna tabell. Varje jobbtjänst tilldelas ett unikt nummer, och detta nummer hänvisas till i andra tabeller.
- posted_by_id – Den här kolumnen innehåller register_user_id av rekryteraren som har lagt ut jobbet.
- job_type_id – Den här kolumnen anger om jobbets varaktighet är permanent eller tillfällig (kontrakt).
- företags-id – Den här kolumnen lagrar företagets ID som är relaterat till jobbinlägget. Det är en referens till
companytabell. - är_företagsnamn_dold – Det här är en flaggkolumn som visar om företagets namn ska visas för arbetssökande. Rekryterare kanske föredrar att inte visa företagsnamn på sina inlägg. Istället använder de termer som "Global Automobile Company", "California-Based IT Company" och så vidare.
- skapat_datum – Detta lagrar datumet då jobbet publiceras.
- jobbbeskrivning – Detta innehåller en kort beskrivning av jobbet.
- job_location_id – Detta hänvisar till ett attribut i
job_locationtabell som lagrar jobbets faktiska plats:gatuadress, stad, stat, land och postnummer. - är_aktiv – Det här betyder om ett jobb fortfarande är ledigt. Rekryterare kan markera sina tjänster inaktiva så fort tjänsterna är tillsatta.
job_post_skill_set Tabellen lagrar information om de färdighetsuppsättningar som krävs för ett jobb. Tabellstrukturen är identisk med seeker_skill_set tabell.
Och den sista tabellen i det här avsnittet, job_post_activity tabell, innehåller uppgifter om vilka arbetssökande som söker ett jobb och när.
Vad skulle du lägga till denna onlinejobbportaldatamodell?
Dagens jobbportaler online gör mer än att tillhandahålla en plattform för att lägga upp och söka jobb. De inkluderar ofta andra professionella tjänster som:
- En personlig instrumentpanel för att hålla reda på jobbansökningar
- Realtidsuppdateringar av appar
- Video-CV-byggare
- Experttjänster för att skriva CV
- LinkedIn eller andra profilbyggare för sociala medier
- Lönerapporter över jobbroller, företag, branscher eller geografiska platser
Om vi ville bygga in dessa funktioner i vårt system, vilka ytterligare ändringar skulle vi behöva göra? Kan du tänka dig några andra måsten i en jobbportal?
Låt oss veta dina åsikter i kommentarsektionen.