Förra veckan publicerade jag ett inlägg som heter #BackToBasics :DATEFROMPARTS() , där jag visade hur man använder den här 2012+-funktionen för renare, sargbara datumintervallfrågor. Jag använde det för att visa att om du använder ett öppet datumpredikat och du har ett index i den relevanta datum/tid-kolumnen, kan du sluta med mycket bättre indexanvändning och lägre I/O (eller i värsta fall , samma sak, om en sökning inte kan användas av någon anledning, eller om det inte finns något lämpligt index):
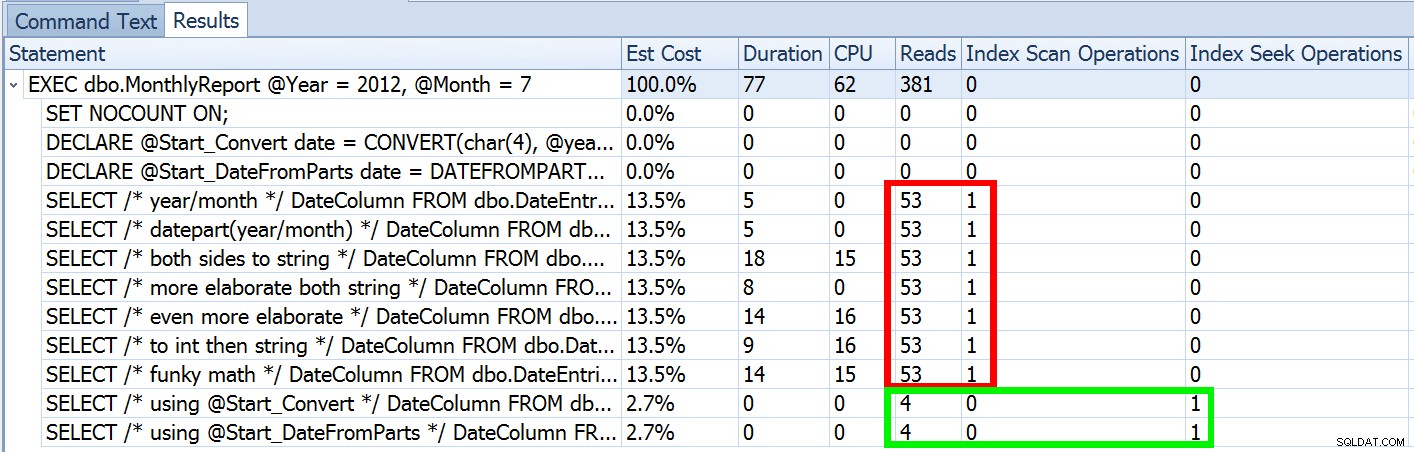
Men det är bara en del av historien (och för att vara tydlig, DATEFROMPARTS() är inte tekniskt nödvändigt för att få en sökning, det är bara renare i så fall). Om vi zoomar ut lite märker vi att våra uppskattningar är långt ifrån korrekta, en komplexitet som jag inte ville introducera i förra inlägget:
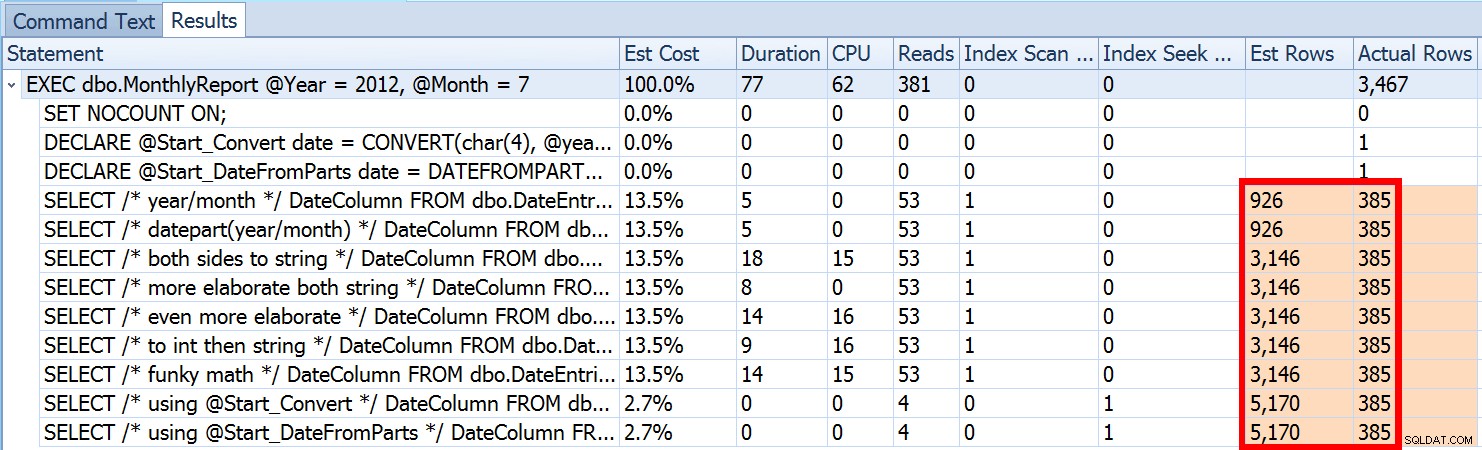
Detta är inte ovanligt för både ojämlikhetspredikat och med påtvingade skanningar. Och naturligtvis, skulle inte metoden jag föreslog ge den mest felaktiga statistiken? Här är det grundläggande tillvägagångssättet (du kan få tabellschemat, index och exempeldata från mitt tidigare inlägg):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Nu kommer felaktiga uppskattningar inte alltid att vara ett problem, men det kan orsaka problem med ineffektiva planval vid de två ytterligheterna. En enskild plan kanske inte är optimal när det valda intervallet kommer att ge en mycket liten eller mycket stor andel av tabellen eller indexet, och detta kan bli väldigt svårt för SQL Server att förutsäga när datafördelningen är ojämn. Joseph Sack beskrev de mer typiska saker som dåliga uppskattningar kan påverka i sitt inlägg, "Tio vanliga hot mot genomförandeplanens kvalitet:"
"[...] dåliga raduppskattningar kan påverka en mängd olika beslut, inklusive indexval, sökning kontra skanningsoperationer, parallell kontra seriell exekvering, val av kopplingsalgoritm, val av inre vs. yttre fysisk koppling (t.ex. build vs. sond), spoolgenerering, bokmärkessökningar kontra fullständig klustrad eller heap-tabellåtkomst, ström- eller hashaggregaturval och om en dataändring använder en bred eller smal plan."
Det finns andra också, som minnesbidrag som är för stora eller för små. Han fortsätter med att beskriva några av de vanligaste orsakerna till dåliga uppskattningar, men den primära orsaken i det här fallet saknas på hans lista:gissningar. Eftersom vi använder en lokal variabel för att ändra den inkommande int parametrar till ett enda lokalt date variabel, SQL Server vet inte vad värdet kommer att vara, så den gör standardiserade gissningar av kardinalitet baserat på hela tabellen.
Vi såg ovan att uppskattningen för mitt föreslagna tillvägagångssätt var 5 170 rader. Nu vet vi att med ett olikhetspredikat, och med SQL Server som inte känner till parametervärdena, kommer den att gissa 30 % av tabellen. 31,645 * 0.3 är inte 5 170. Inte heller 31,465 * 0.3 * 0.3 , när vi kommer ihåg att det faktiskt finns två predikat som arbetar mot samma kolumn. Så var kommer detta värde på 5 170 ifrån?
Som Paul White beskriver i sitt inlägg, "Cardinality Estimation for Multiple Predicates", använder den nya kardinalitetsuppskattaren i SQL Server 2014 exponentiell backoff, så den multiplicerar radantalet i tabellen (31 465) med selektiviteten för det första predikatet (0,3) , och multiplicerar sedan det med kvadratroten av selektiviteten för det andra predikatet (~0,547723).
31 645 * (0,3) * SQRT(0,3) ~=5 170,227Så nu kan vi se var SQL Server kom med sin uppskattning; vilka är några av metoderna vi kan använda för att göra något åt det?
- Ange datumparametrar. När det är möjligt kan du ändra applikationen så att den skickar in korrekta datumparametrar istället för separata heltalsparametrar.
- Använd en omslagsprocedur. En variant av metod #1 – till exempel om du inte kan ändra applikationen – skulle vara att skapa en andra lagrad procedur som accepterar konstruerade datumparametrar från den första.
- Använd
OPTION (RECOMPILE). Till en liten kostnad för kompilering varje gång frågan körs, tvingar detta SQL Server att optimera baserat på de värden som presenteras varje gång, istället för att optimera en enda plan för okända, första eller genomsnittliga parametervärden. (För en grundlig behandling av detta ämne, se Paul Whites "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Använd dynamisk SQL. Att ha dynamisk SQL acceptera det konstruerade
datevariabel tvingar fram korrekt parametrering (precis som om du hade anropat en lagrad procedur med ettdateparameter), men den är lite ful och svårare att underhålla.
- Bråka med tips och spårningsflaggor. Paul White berättar om några av dessa i det tidigare nämnda inlägget.
Jag tänker inte antyda att detta är en uttömmande lista, och jag tänker inte upprepa Pauls råd om tips eller spårningsflaggor, så jag fokuserar bara på att visa hur de fyra första tillvägagångssätten kan mildra problemet med dåliga uppskattningar .
1. Datumparametrar
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Omslagsprocedur
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. ALTERNATIV (OMKOMPILERA)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamisk SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Testen
Med de fyra uppsättningarna av procedurer på plats var det lätt att konstruera tester som skulle visa mig planerna och uppskattningarna som SQL Server härledde. Eftersom vissa månader är mer hektiska än andra, valde jag tre olika månader och avrättade dem alla flera gånger.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Resultatet? Varje enskild plan ger samma indexsökning, men uppskattningarna är bara korrekta över alla tre datumintervallen i OPTION (RECOMPILE) version. Resten fortsätter att använda uppskattningarna som härrör från den första uppsättningen parametrar (juli 2012), och så medan de får bättre uppskattningar för den första exekvering, kommer den uppskattningen inte nödvändigtvis att vara bättre för efterföljande exekveringar med olika parametrar (ett klassiskt fall av parametersniffning i läroboken):
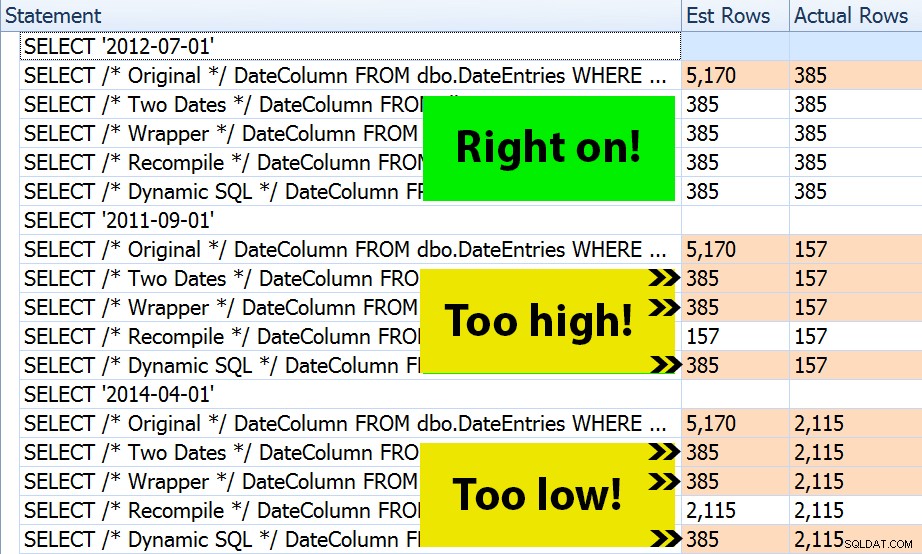
Observera att ovanstående inte är *exakt* utdata från SQL Sentry Plan Explorer – till exempel tog jag bort raderna i satsträdet som visade de yttre lagrade proceduranropen och parameterdeklarationer.
Det är upp till dig att avgöra om taktiken att kompilera varje gång är bäst för dig, eller om du behöver "fixa" något i första hand. Här slutade vi med samma planer och inga märkbara skillnader i körtidsprestandamått. Men på större tabeller, med mer skev datafördelning och större variationer i predikatvärden (tänk t.ex. en rapport som kan täcka en vecka, ett år och allt däremellan), kan det vara värt en undersökning. Och observera att du kan kombinera metoder här – till exempel kan du byta till korrekta datumparametrar *och* lägga till OPTION (RECOMPILE) , om du vill.
Slutsats
I det här specifika fallet, som är en avsiktlig förenkling, lönade sig inte ansträngningen att få de korrekta uppskattningarna riktigt – vi fick ingen annan plan, och körtidsprestandan var likvärdig. Det finns dock säkert andra fall där detta kommer att göra skillnad, och det är viktigt att känna igen uppskattningsskillnaderna och avgöra om det kan bli ett problem när din data växer och/eller din distribution skev. Tyvärr finns det inget svart-vitt svar, eftersom många variabler kommer att påverka huruvida kompileringskostnader är motiverade – som med många scenarier, IT DEPENDS™ …