I dagens värld genereras data i en exponentiell takt, så mycket att analytiker förutspår att vårt globala dataskapande kommer att öka 10 gånger till 2025. Företag samlar nu in data över alla interna system och externa källor som påverkar deras företag. och med det följer ett ständigt växande behov av att analysera data för att få insikt i hur den kan användas för att förbättra och förbättra deras affärsbeslut. Apache Zeppelin, en plattform för dataanalys och visualisering med öppen källkod, kan ta oss en lång väg mot det målet.
I den här artikeln får du lära dig hur du lägger till en anpassad tolk för MongoDB och MySQL och hur du använder den för att fråga och visualisera insamlingsdata. Låt oss först börja med en översikt över Apache Zeppelin och dess funktioner:
Vad är Apache Zeppelin?

Apache Zeppelin är en öppen källkod, webbaserad "anteckningsbok" som möjliggör interaktiv dataanalys och samarbetsdokument. Den bärbara datorn är integrerad med distribuerade, allmänna databehandlingssystem som Apache Spark (storskalig databehandling), Apache Flink (strömbearbetningsramverk) och många andra. Apache Zeppelin låter dig skapa vackra, datadrivna, interaktiva dokument med SQL, Scala, R eller Python direkt i din webbläsare.
Apache Zeppelin-funktioner
Interaktivt gränssnittApache Zeppelin har ett interaktivt gränssnitt som gör att du omedelbart kan se resultaten av dina analyser och ha en omedelbar koppling till din skapelse: |  |
|---|---|
Anteckningsböcker för webbläsareSkapa anteckningsböcker som körs i din webbläsare (både på din dator och på distans) och experimentera med olika typer av diagram för att utforska dina datamängder: |  |
IntegrationerIntegrera med många olika stora dataverktyg med öppen källkod som Apache-projekten Spark, Flink, Hive, Ignite, Lens och Tajo. |  |
Dynamiska formulär
Skapa dynamiskt inmatningsformulär direkt i din anteckningsbok.

Samarbete och delning
En mångsidig och levande utvecklargemenskap ger dig tillgång till nya datakällor som ständigt läggs till och distribueras genom deras Apache 2.0-licens för öppen källkod.

TolkApache Zeppelin-tolkkoncept gör att alla språk-/databehandlingsbackends kan anslutas till Zeppelin. För närvarande stöder Apache Zeppelin många tolkar som Apache Spark, Python, JDBC, Markdown och Shell. |  |
|---|
Låt oss nu börja skapa din anpassade tolk för MongoDB och MySQL.
Lägg till en MySQL-tolkPå Apache Zeppelin-plattformen går du till rullgardinsmenyn uppe till höger och klickar på Tolk: |  |
|---|
Här kan du hitta en lista över alla tolkar. Vi måste skapa en ny för MySQL, så klicka på knappen "Skapa" i det övre högra hörnet:

Ange ett namn som går att känna igen för tolken (t.ex. mysql), och välj grupp som JDBC: Behåll alla standardalternativ, men ange nödvändiga uppgifter och se till att en anslutning till din MySQL-server är upprättad: |  |
|---|

Vi måste också lägga till en anpassad artefakt till MySQL-anslutningen JAR så att Zeppelin vet var den ska köras från. Ladda ner kontakten här, placera den i tolk-/jdbc-mappen och ange sedan den exakta sökvägen till artefakten:

Och det är allt! För att testa vår tolk måste vi skapa en ny anteckning. Men först, låt oss ställa in vår MongoDB-tolk också.
Lägg till en MongoDB-tolk
Gå tillbaka till din tolksida och klicka på knappen "Skapa". Vi kommer att använda den här MongoDB-tolken med öppen källkod, så du måste sedan ladda ner .zip-filen och byta namn på den till .jar.
Efter det, gå till interpreters/, skapa en mongodb/-mapp och klistra in .jar i mappen.

Du har nu en ny tolkgrupp som heter mongodb. Gå till din tolksida, ange ett vänligt namn som mongodb och välj sedan mongodb under rullgardinsmenyn Tolkgrupp. Låt oss nu ange vår nyskapade ScaleGrid MongoDB-klusterinformation i "Egenskaper" som finns på sidan Klusterdetaljer under avsnittet Översikt / Maskiner. |  |
|---|

Och vi är klara! Nu är det dags att testa våra nyskapade tolkar.
Skapa en Zeppelin-anteckning
För att köra frågor som hjälper till att visualisera vår data, måste vi skapa anteckningar. Från Zeppelin-rubriken klickar du på "Anteckningsbok" och sedan på "Skapa en ny anteckning": |  |
|---|---|
Se till att anteckningsbokens rubrik visar en ansluten status som betecknas med en grön prick i det övre högra hörnet: |  |
När du skapar en anteckning visas en dialogruta där du kan ange mer information. Välj standardtolken som vår nyskapade mysql och klicka på "Skapa anteckning".

Kör frågor på anteckningen
Innan vi kan köra eventuella frågor måste vi också nämna vilken typ av tolk vi kommer att använda för vår anteckning. Vi kan göra det genom att starta vår anteckning med "%mysql". Detta kommer att berätta för Zeppelin att förvänta sig MySQL-frågor i den anteckningen. |  |
|---|
Och nu är vi redo att fråga vår databas. I det här exemplet kommer jag att använda min WordPress-installation som innehåller en typisk wp_options-tabell för att fråga och visualisera dess data.

Det fungerar! Du kan nu klicka på de olika diagrammen för att visualisera data i olika grafformat.

På samma sätt, för MongoDB, se till att du har data i MongoDB-klustret. Du kan lägga till några genom att gå till fliken Admin och köra Mongo-frågor.
Här är ett exempel på några MongoDB-data i anteckningen:
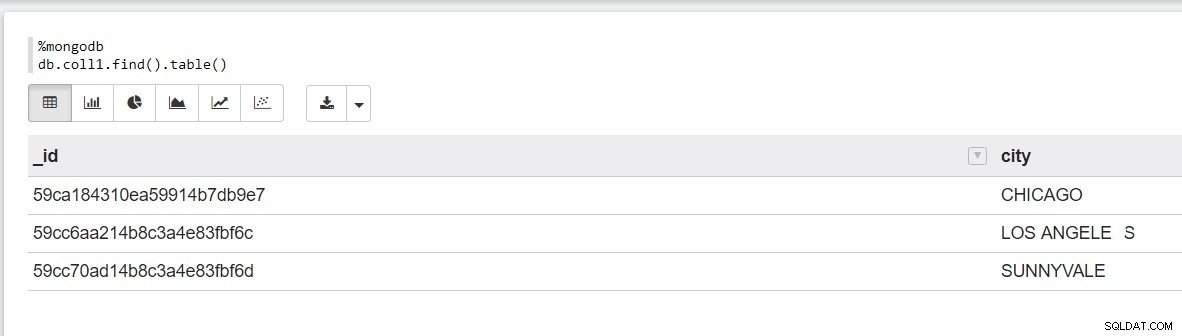
Dela länkar till dina anteckningarNu när din data är redo för visualisering och sökning kanske du vill visa upp den för ditt team. Du kan göra detta mycket enkelt genom att skapa en delbar länk till anteckningen: Denna delbara länken kommer att vara tillgänglig för alla att se, och du kan också välja att dela en länk till en specifik graf: |  |
|---|

Apache Zeppelin slutsats
Apache Zeppelin är ett oerhört användbart verktyg som låter team hantera och analysera data med många olika visualiseringsalternativ, tabeller och delbara länkar för samarbete. Här är några användbara länkar för att komma igång:
Ladda ner Apache Zeppelin
MongoDB-tolk
MySQL Connector
Du kan också utforska andra sätt att visualisera din data genom MongoDB GUI, inklusive de fyra bästa:MongoDB Compass, Robomongo, Studio 3T och MongoBooster.
Som alltid, om du bygger något fantastiskt, twittra oss om det @scalegridio
Om du behöver hjälp med hosting och hantering av Redis™*, kontakta oss på support@scalegrid.io för mer information.
